ACTalker:开源多模态说话人视频生成框架,精准驱动面部表情与唇形同步
一、ACTalker是什么
ACTalker 是由香港科技大学、腾讯、清华大学联合研发的端到端说话人头像(Talking Head)视频生成框架,基于视频扩散模型构建,主打多信号协同控制能力。该框架可通过音频、面部表情等多模态信号,精准驱动生成音画高度同步、表情自然逼真的虚拟人像视频,解决传统数字人生成中动作冲突、唇形错位、身份漂移等痛点,是当前说话人视频生成领域的标杆性开源方案。
二、功能特色
1. 多信号灵活控制
单信号驱动:仅输入音频生成匹配唇形与表情的视频,或仅输入表情参数生成对应面部动画。
多信号组合驱动:支持音频+表情、音频+头部姿态等组合输入,不同信号独立控制面部不同区域(如音频控嘴部、表情控眉眼),无动作冲突。
动态门控调节:推理时可手动开启/关闭各信号通道,灵活调整驱动权重,适配不同风格需求。
2. 高质量视频生成
超自然表情与动作:生成视频面部表情细腻、头部运动自然,眨眼、嘴角微动等细节还原度高。
精准音画同步:在CelebV-HQ数据集上实现Sync-C=5.317、Sync-D=7.869的同步精度,唇形与音频完全对齐。
身份一致性强:全程保留输入人像的身份特征,无明显面部扭曲或身份漂移问题。
3. 高效轻量化推理
并行Mamba架构:采用选择性状态空间模型,相比传统Transformer,算力消耗降低、推理速度提升,兼顾效率与效果。
低显存需求:基础推理仅需8GB显存,支持本地部署,无需高端算力支持。
4. 多场景适配能力
支持2D人像、真人照片、卡通形象等多种输入类型。
输出视频适配虚拟主播、数字人直播、短视频配音、智能客服等多元场景。

三、技术细节
1. 核心架构:并行Mamba+门控融合
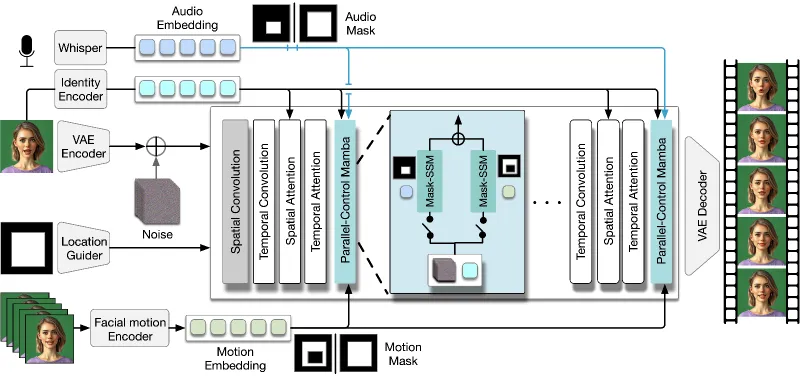
ACTalker 核心采用并行Mamba结构,整体分为多模态编码分支、特征融合模块、视频扩散解码器三部分,架构逻辑清晰、模块化程度高。
输入(音频/表情/人像) ↓ 多模态编码分支(并行Mamba) ├─ 音频分支:提取梅尔频谱特征→时序建模 ├─ 表情分支:提取3D面部表情参数→空间建模 └─ 人像分支:提取身份特征→身份编码 ↓ 动态门控融合模块(信号权重调节) ↓ 视频扩散解码器(生成高清视频帧) ↓ 输出:同步说话人视频
2. 关键技术突破
并行Mamba结构:多分支并行处理不同驱动信号,每个分支独立用Mamba捕捉时序/空间特征,避免信号干扰,同时提升长序列建模能力。
动态门控机制:训练时随机丢弃部分信号通道,增强模型鲁棒性;推理时可手动控制各通道开关,灵活调整信号优先级。
区域化控制策略:将面部划分为嘴部、眉眼、下颌等区域,不同驱动信号精准控制对应区域,确保动作自然协调。
扩散模型优化:采用时间步自适应调度,提升视频帧生成质量,减少模糊、抖动等问题。
3. 核心技术指标
| 指标类型 | 具体指标 | 数值表现 |
|---|---|---|
| 音频同步 | Sync-C(唇形同步) | 5.317(最优) |
| 音频同步 | Sync-D(动态同步) | 7.869(最优) |
| 视频质量 | FVD-Inc(视频流畅度) | 232.374(最优) |
| 身份保留 | CSIM(身份相似度) | 0.92+(高保真) |
四、应用场景
1. 虚拟主播与数字人直播
快速生成24小时在线虚拟主播,适配新闻播报、带货直播、知识科普等场景,无需真人出镜、低成本高效益。
2. 短视频内容创作
老照片活化:上传历史照片+配音,生成会说话的动态回忆视频。
短视频配音:为无口型视频匹配自然唇形,适配解说、访谈类内容。
3. 智能客服与虚拟助手
生成高共情虚拟客服,实现语音交互时表情同步反馈,提升用户沟通体验,适配金融、政务、电商等领域。
4. 教育与培训
制作虚拟讲师视频,支持多语言配音+精准表情同步,适配在线课程、企业培训等场景,降低内容制作成本。
5. 影视与娱乐
快速生成虚拟角色说话片段,适配短视频短剧、动画配音、虚拟偶像互动等场景。

五、使用方法
1. 环境准备
(1)硬件要求
最低:NVIDIA GPU(8GB显存)、16GB内存、50GB存储
推荐:NVIDIA RTX 3090/4090、32GB内存、100GB+高速存储
(2)软件依赖
# 创建虚拟环境 conda create -n actalker python=3.9 conda activate actalker # 安装核心依赖 pip install torch==2.0.1 torchvision==0.15.2 pip install mamba-ssm==1.0.1 pip install diffusers==0.18.2 transformers==4.28.1 pip install opencv-python==4.7.0.72 ffmpeg-python==0.2.0
2. 项目部署
# 克隆仓库 git clone https://github.com/harlanhong/ACTalker.git cd ACTalker # 下载预训练权重(自动脚本) python download_weights.py # 启动WebUI(可视化界面) python app.py # 启动命令行模式 python inference.py --config configs/infer.yaml
3. 快速生成流程
输入准备:上传1张清晰正面人像(照片/卡通图)、1段10-60秒音频(中文/英文均可)。
参数设置:选择驱动模式(仅音频/音频+表情)、输出分辨率(512×512/768×768)、帧率(25fps/30fps)。
生成视频:点击“生成”,等待1-3分钟(视硬件配置),生成后自动预览并保存。
4. 高级使用(自定义表情驱动)
准备表情参数文件(JSON格式,含3D面部关键点坐标)。
命令行指定表情输入:
python inference.py --audio input/audio.wav --image input/portrait.jpg --expression input/expr.json
六、竞品对比
选取行业主流的SadTalker、OmniTalker与ACTalker对比,核心维度如下:
1. 核心对比表
| 对比维度 | ACTalker(港科大/腾讯/清华) | SadTalker(西安交大) | OmniTalker(阿里通义) |
|---|---|---|---|
| 核心架构 | 并行Mamba+动态门控 | 3DMM+条件VAE | Thinker-Talker双模块+TMRoPE |
| 驱动信号 | 音频/表情/组合(多区域分控) | 仅音频(单信号驱动) | 文本/音频/视频(多模态输入) |
| 唇形同步精度 | Sync-C=5.317(极高) | 中等(易出现唇形错位) | 高(误差±40ms) |
| 面部表情丰富度 | 高(眉眼/嘴角/下颌精细化) | 中等(表情单一、头部动作僵硬) | 高(但易丢失身份细节) |
| 身份一致性 | 极强(全程保留特征) | 强(轻微扭曲) | 中等(高动态下易漂移) |
| 推理速度 | 快(Mamba轻量化) | 中等 | 快(流式生成,2秒响应) |
| 显存需求 | 8GB(最低) | 6GB(最低) | 10GB+(最低) |
| 开源状态 | 完全开源(GitHub) | 完全开源(GitHub) | 闭源(仅在线体验) |
| 核心优势 | 多信号分控、同步精度高、开源 | 部署简单、低显存、易上手 | 多模态输入、实时交互、商用稳定 |
2. 核心差异总结
ACTalker:主打多信号精准控制+极致同步精度,开源且性能均衡,适合技术玩家与商用二次开发。
SadTalker:主打轻量化+易部署,仅支持音频驱动,适合个人简单创作,表情细节较弱。
OmniTalker:主打多模态输入+实时交互,闭源商用,适合企业级直播场景,显存需求高。
七、常见问题解答
Q:生成视频唇形与音频不同步怎么办?
A:优先检查音频质量,确保无背景噪音、采样率为16kHz;其次在参数设置中调高“唇形同步权重”,降低头部运动幅度;最后更新预训练权重至最新版,修复同步算法bug。
Q:生成视频面部扭曲、身份丢失如何解决?
A:输入人像需为正面清晰无遮挡照片,避免侧脸、模糊、强美颜图片;推理时选择“身份保护模式”,降低表情驱动强度;使用更高分辨率输入(512×512以上)。
Q:部署时出现CUDA out of memory报错?
A:降低输出分辨率至512×512、关闭“高清细节增强”功能;使用RTX 3090及以上显卡,或切换至CPU模式(速度较慢);关闭后台占用显存的程序。
Q:支持中文/英文以外的小语种音频吗?
A:支持,但小语种同步精度略低于中英;建议使用16kHz采样率、清晰无口音的音频;可通过微调模型适配特定语种,官方提供微调教程。
Q:可以生成长时间(5分钟以上)视频吗?
A:支持,但长视频易出现轻微抖动;建议分段生成(每段1-2分钟)后拼接;开启“长序列稳定模式”,减少帧间抖动。
Q:是否支持商用?需要授权吗?
A:完全开源,免费商用,无需授权;但禁止用于违法、侵权、换脸等违规场景;二次开发需注明原项目来源。
八、相关链接
项目GitHub仓库:https://github.com/harlanhong/ACTalker
项目主页:https://harlanhong.github.io/publications/actalker/index.html
技术论文(arXiv):https://arxiv.org/abs/2504.02542
九、总结
ACTalker 是一款由港科大、腾讯、清华联合打造的开源多模态说话人视频生成框架,凭借并行Mamba架构、动态门控融合、多信号分控等核心技术,实现了音画高度同步、表情细腻自然、身份稳定一致的生成效果。相比SadTalker、OmniTalker等竞品,ACTalker 兼顾性能、灵活性与开源友好性,适配虚拟主播、短视频创作、智能客服等多元场景,为数字人内容创作提供了低成本、高性能的技术方案。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/actalker.html





