AI Toolkit:Ostris 开源的扩散模型训练工具,兼顾易用性与功能完整性
一、AI Toolkit是什么
AI Toolkit是由Ostris团队开源的全能型扩散模型训练套件,其核心定位是为消费级硬件用户提供低成本、高易用性的图像与视频扩散模型训练解决方案。不同于专业级AI训练工具对高性能服务器的依赖,AI Toolkit在设计之初就兼顾了普通PC的硬件适配性,同时保留了工业级模型训练的核心功能。
该项目采用Python作为核心开发语言,支持图形用户界面(GUI)和命令行界面(CLI)两种操作模式,既满足了新手用户的可视化操作需求,也适配了资深开发者的自动化脚本调用场景。项目的核心愿景是“让所有用户都能轻松定制专属扩散模型”,因此在功能集成上追求“一站式覆盖”,从基础的模型训练、参数调优,到进阶的扩展插件开发、多平台部署,都提供了完整的工具链支持。截至目前,AI Toolkit已获得GitHub社区大量关注,同时得到Replicate、Hugging Face等知名AI平台的赞助支持,成为消费级AI模型训练领域的热门开源项目。
二、功能特色
AI Toolkit的功能体系围绕“易用性”“全功能”“跨平台”三大核心原则构建,其特色功能可分为基础训练功能、界面交互功能、部署扩展功能三大类,具体如下:
2.1 基础训练功能:覆盖图像与视频扩散模型全流程
作为扩散模型训练套件,AI Toolkit的核心能力集中在模型训练与定制环节,其亮点功能包括:
多类型扩散模型支持:不仅支持主流的图像扩散模型(如SD系列、FLUX系列),还适配了视频扩散模型的训练需求,实现了“图像-视频”模型训练的一体化支持,用户无需切换工具即可完成多模态模型的定制。
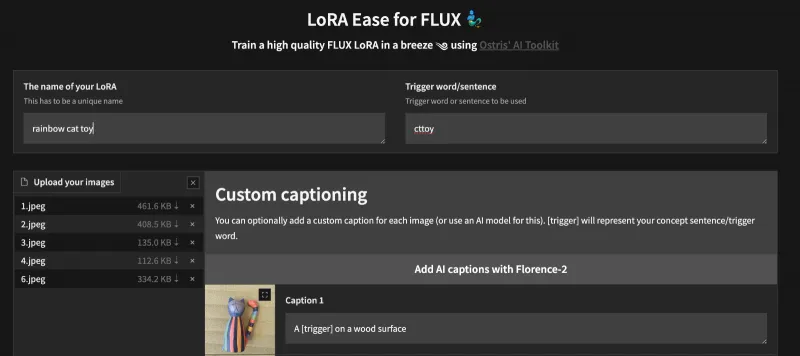
LoRA轻量化训练:内置FLUX_1_dev_LoRA等热门轻量化训练模块,用户可基于预训练大模型快速训练专属LoRA权重,既降低了显存占用(消费级显卡即可运行),又能精准实现风格迁移、人物定制等个性化需求,且提供了配套的Jupyter Notebook示例(如
FLUX_1_dev_LoRA_Training.ipynb),新手可快速上手。灵活的参数配置:通过
config/文件夹提供多套示例配置文件,用户可自定义学习率、训练步数、批次大小等核心参数,同时支持训练过程中的断点续训,避免因硬件故障或操作中断导致的训练失效。
2.2 界面交互功能:双界面适配不同用户群体
AI Toolkit打破了“专业工具只能用命令行”的壁垒,提供了多样化的交互方式:
图形界面(GUI):通过
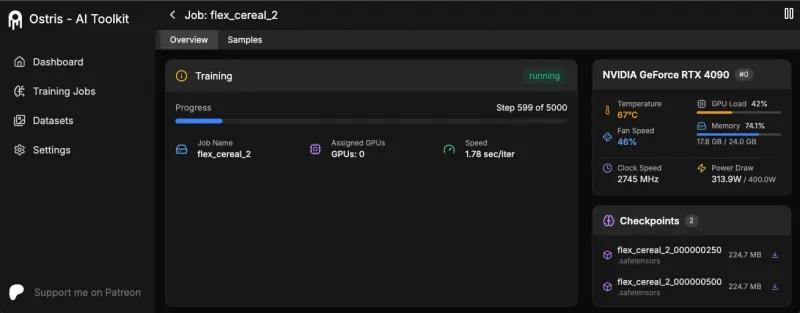
flux_train_ui.py等文件实现可视化操作,界面包含训练参数设置面板、训练进度监控模块、模型结果预览窗口等,用户无需编写代码,仅通过鼠标点击即可完成模型训练全流程,尤其适合零基础的AI爱好者。命令行界面(CLI):支持通过
run.py等脚本进行命令行调用,开发者可将训练流程集成到自动化脚本中,实现批量训练、定时训练等高级需求,同时命令行模式的资源占用更低,适合对性能有极致要求的场景。Web界面支持:通过
ui/文件夹的前端代码实现Web端访问,用户可在局域网内通过浏览器远程控制训练进程,解决了单台设备操作的空间限制,且前端依赖axios等轻量库,加载速度快、交互流畅。
2.3 部署扩展功能:便捷的环境配置与功能拓展
为降低使用门槛和提升扩展性,AI Toolkit提供了完善的部署与扩展工具:
Docker一键部署:内置
Dockerfile和docker-compose.yml文件,用户可通过Docker快速构建隔离的训练环境,无需手动配置Python依赖、CUDA版本等,避免了“环境不兼容”的常见问题,同时支持跨Windows、Linux、macOS多系统部署。插件扩展体系:设计了
extensions/(自定义扩展)和extensions_built_in/(内置扩展)双文件夹结构,用户可通过编写简单的Python插件实现功能拓展,如自定义数据预处理逻辑、新增模型评估指标等,且项目提供了扩展开发示例,降低了二次开发的门槛。多平台适配:支持与Replicate、Hugging Face等平台的联动,训练完成的模型可便捷地导出至这些平台进行部署和分享,实现“训练-部署-分发”的全链路打通。
2.4 功能对比:AI Toolkit与同类工具的核心差异
为更直观地体现AI Toolkit的优势,以下将其与两款同类开源工具进行对比:
| 功能特性 | AI Toolkit | 工具A(专业级训练套件) | 工具B(轻量型训练工具) |
|---|---|---|---|
| 硬件适配性 | 支持消费级显卡(10GB显存起步) | 需专业服务器(24GB以上显存) | 仅支持入门级模型(无视频训练) |
| 操作界面 | GUI/CLI/Web三界面 | 仅CLI界面 | 仅简易GUI界面 |
| 模型支持范围 | 图像+视频扩散模型 | 仅图像扩散模型 | 仅轻量图像模型 |
| 扩展插件体系 | 完善的插件开发框架 | 无扩展功能 | 有限的自定义选项 |
| 部署方式 | Docker/本地/云端多方式 | 仅本地部署 | 仅本地部署 |
三、技术细节
AI Toolkit的技术架构围绕“轻量化”“模块化”“高兼容性”三大目标设计,其核心技术细节可从核心模块、关键技术实现、依赖体系三个维度解析:
3.1 核心模块架构
项目的代码结构采用清晰的模块化设计,各文件夹分工明确,具体如下:
核心工具库(toolkit/):这是项目的技术核心,包含了扩散模型训练的底层逻辑,如旋转位置嵌入(Rotary Positional Embedding)的实现、LoRA权重融合算法、数据加载与预处理模块等。该文件夹的代码经过高度封装,既保证了功能的稳定性,又方便开发者进行二次调用。
运行入口模块:
run.py是CLI模式的核心入口,负责解析命令行参数、启动训练进程;run_modal.py适配云端部署场景,可将训练任务迁移至Modal平台;flux_train_ui.py则是GUI界面的启动文件,集成了PyQt等可视化库实现界面渲染。配置管理模块(config/):存放各类模型的训练配置文件,配置格式采用YAML,兼具可读性和灵活性,用户可通过修改配置文件调整模型结构、训练策略等,无需改动核心代码。
前端界面模块(ui/):包含Web界面的前端代码,采用HTML+CSS+JavaScript构建,通过axios库实现前后端数据交互,同时集成了进度条、预览窗口等组件,提升用户交互体验。
示例笔记本(notebooks/):提供Jupyter Notebook格式的教程,以
FLUX_1_dev_LoRA_Training.ipynb为例,该笔记本包含了从环境配置、数据准备到训练启动、结果验证的全流程代码,且每一步都配有详细注释,是新手学习的最佳入口。
3.2 关键技术实现
AI Toolkit在技术层面的核心亮点是对消费级硬件的适配和先进模型组件的集成,具体包括:
旋转位置嵌入(Rotary Positional Embedding):在
toolkit/模块中实现了该技术,其核心作用是提升模型对长序列数据的理解能力,尤其在视频扩散模型训练中,可有效捕捉帧间的时序关联,让生成的视频更流畅、逻辑更连贯。相较于传统的位置编码方式,旋转位置嵌入无需额外的参数学习,且显存占用更低,更适合消费级硬件。LoRA训练优化:针对FLUX等大模型的LoRA训练进行了专项优化,采用了低秩矩阵分解技术,将大模型的全量参数训练转化为低秩矩阵的微调,显存占用可降低70%以上。例如,训练FLUX_1_dev的LoRA权重时,仅需10GB左右的显存,普通的RTX 3060/3070显卡即可胜任,而传统全量微调则需要24GB以上的专业显卡。
分布式训练支持:虽然主打消费级硬件,但AI Toolkit也预留了分布式训练接口,支持多块显卡的并行训练,用户可通过修改配置文件开启多GPU模式,进一步提升训练效率,兼顾了个人用户和小型工作室的需求。
3.3 依赖体系
AI Toolkit的Python依赖分为核心依赖和可选依赖,以下是关键依赖的作用和版本要求:
| 依赖库 | 核心作用 | 最低版本要求 | 可选/必选 |
|---|---|---|---|
| PyTorch | 模型训练的底层深度学习框架 | 2.0.0 | 必选 |
| Transformers | 加载预训练扩散模型的权重和结构 | 4.30.0 | 必选 |
| Diffusers | 扩散模型的训练与推理工具链 | 0.20.0 | 必选 |
| PyQt5 | GUI界面的可视化渲染 | 5.15.0 | 可选(仅GUI模式) |
| Axios(前端) | Web界面的前后端数据交互 | 1.4.0 | 可选(仅Web模式) |
| Docker相关工具 | 容器化部署的环境支撑 | 20.10.0 | 可选(仅Docker部署) |
四、应用场景
AI Toolkit的功能特性决定了其应用场景覆盖个人爱好者、小型工作室、AI开发者等多个群体,具体可分为以下五类:
4.1 个人AI爱好者的模型定制
对于普通AI爱好者而言,AI Toolkit的低硬件门槛和可视化界面是核心优势:
风格迁移定制:用户可收集特定风格的图片(如动漫、油画、复古胶片)作为训练数据,通过LoRA轻量化训练,快速得到专属风格的扩散模型,生成符合个人审美的图像内容,无需依赖商用AI工具的付费会员。
人物/物品专属模型:可基于家人、宠物的照片训练LoRA权重,实现指定人物/物品的精准生成,用于制作个性化海报、纪念相册等,且训练过程简单,新手可在1-2小时内完成一次基础训练。
4.2 小型创意工作室的内容生产
小型设计、自媒体工作室往往面临“专业工具成本高、商用平台受限多”的问题,AI Toolkit可成为其核心生产力工具:
视频内容定制:通过视频扩散模型训练,工作室可定制符合账号风格的视频生成模型,用于批量生产短视频素材,如科普类动画、产品宣传短片等,且支持帧间逻辑优化,生成的视频无需大量后期剪辑。
多风格素材储备:可针对不同客户的需求,训练多套风格化LoRA权重,形成素材库,接单时可快速切换模型,提升交付效率,同时避免了商用平台的版权和风格限制。
4.3 AI开发者的技术验证
对于AI领域的开发者和研究者,AI Toolkit的模块化架构和底层技术实现具有重要的实验价值:
新算法原型验证:开发者可基于
toolkit/的核心模块,快速集成新的扩散算法或位置编码技术,验证算法的有效性,且无需从零搭建训练框架,节省开发时间。硬件适配测试:可利用AI Toolkit的消费级硬件适配能力,测试新模型在低显存设备上的运行效果,为模型的轻量化优化提供数据支撑,尤其适合面向个人用户的AI产品开发。
4.4 教育领域的AI实践教学
在高校或培训机构的AI相关课程中,AI Toolkit可作为理想的实践工具:
扩散模型原理教学:通过
notebooks/中的示例笔记本,学生可直观了解扩散模型的训练流程、LoRA的底层逻辑,将理论知识转化为实操能力,且无需昂贵的硬件设备,实验室普通PC即可完成教学实践。毕业设计与竞赛:学生可基于AI Toolkit进行定制化开发,如新增特定的模型评估指标、开发行业专属的扩展插件,用于毕业设计或AI创新竞赛,提升项目的实用性和创新性。
4.5 开源社区的模型共建
AI Toolkit的开源属性和多平台联动能力,使其成为开源社区模型共建的重要载体:
模型权重分享:用户可将训练好的LoRA权重或完整模型导出至Hugging Face Hub,供全球开发者使用,同时可通过Replicate平台实现模型的云端部署,让无硬件条件的用户也能体验定制模型。
扩展插件贡献:开发者可将自研的扩展插件提交至项目的
extensions/文件夹,丰富项目的功能生态,形成“用户共建、成果共享”的开源氛围。
五、使用方法
AI Toolkit提供了多种使用方式,以下分别介绍本地部署、Docker部署、GUI模式、CLI模式的详细步骤,兼顾不同用户的操作习惯:
5.1 环境准备(本地部署)
硬件要求:
显卡:NVIDIA显卡(支持CUDA,显存≥10GB,推荐RTX 3060及以上);
内存:≥16GB(建议32GB);
存储空间:≥50GB(用于存放预训练模型和训练数据)。
软件要求:
操作系统:Windows 10/11、Linux(Ubuntu 20.04+)、macOS(需支持Metal加速);
Python版本:3.10-3.11(推荐3.10,兼容性最佳);
CUDA版本:11.7-12.1(需与PyTorch版本匹配)。
依赖安装:
克隆仓库:
git clone https://github.com/ostris/ai-toolkit.git;进入仓库目录:
cd ai-toolkit;安装核心依赖:
pip install -r requirements.txt;如需GUI界面,额外安装PyQt5:
pip install pyqt5。
5.2 Docker部署(推荐新手)
Docker部署可跳过复杂的环境配置,步骤如下:
安装Docker:参考Docker官方文档,完成Docker和Docker Compose的安装;
构建镜像:在仓库目录执行
docker-compose build,自动构建训练环境;启动容器:执行
docker-compose up,容器启动后可通过Web界面(默认端口8000)访问工具;停止容器:执行
docker-compose down,如需保留数据,可提前配置数据卷映射。
5.3 GUI模式操作(零基础友好)
启动GUI界面:在仓库目录执行
python flux_train_ui.py,等待界面加载完成;配置训练参数:
选择预训练模型:在“模型选择”面板选择FLUX、SD等模型,支持本地模型和Hugging Face远程模型加载;
设置训练数据:上传本地图片/视频数据集,或填写数据集路径;
调整LoRA参数:设置LoRA的秩(Rank)、学习率、训练步数等,新手可直接使用默认配置;
启动训练:点击“开始训练”按钮,界面将实时显示训练进度、显存占用、损失值变化;
查看结果:训练完成后,可在“结果预览”面板查看生成的示例图像/视频,同时模型权重会自动保存至
output/文件夹。
5.4 CLI模式操作(开发者适用)
编写配置文件:复制
config/文件夹中的示例配置,修改数据集路径、模型路径、训练参数等;启动训练:执行命令
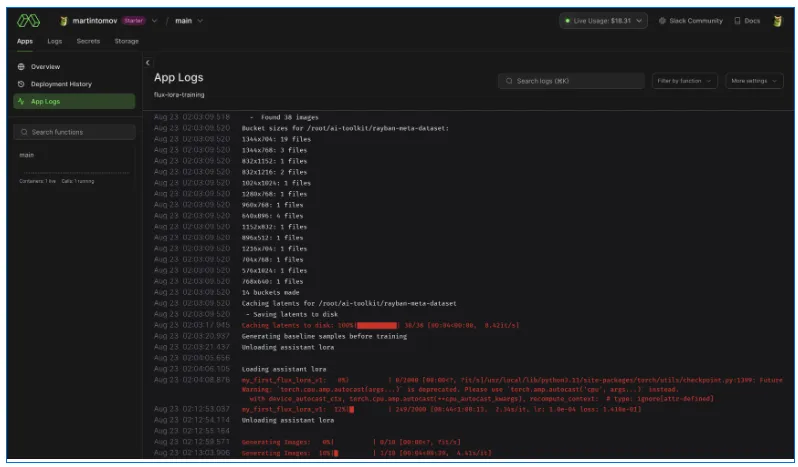
python run.py --config config/flux_lora_config.yaml,其中flux_lora_config.yaml为自定义配置文件;监控训练:可通过TensorBoard监控训练过程(需提前安装TensorBoard:
pip install tensorboard),执行tensorboard --logdir=logs即可查看损失曲线、生成样本等;导出模型:训练完成后,在
output/文件夹获取训练好的权重,可直接用于Diffusers等框架的推理。
5.5 示例笔记本使用(学习专用)
启动Jupyter Notebook:在仓库目录执行
jupyter notebook notebooks/FLUX_1_dev_LoRA_Training.ipynb;逐行运行代码:按照笔记本中的步骤,依次完成环境检查、数据加载、模型初始化、训练启动、结果验证,每一步都有详细注释,可边运行边理解原理;
修改参数测试:可尝试调整学习率、训练步数等参数,观察对训练结果的影响,加深对模型训练的理解。
六、常见问题解答
问题1:安装依赖时出现“CUDA版本不兼容”的报错?
解答:首先确认PyTorch版本与CUDA版本的匹配性,可通过nvcc --version查看本地CUDA版本,然后前往PyTorch官网获取对应版本的安装命令(如pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118),避免手动安装导致的版本冲突。
问题2:Docker启动后无法访问Web界面?
解答:检查容器端口是否映射成功,默认配置为8000端口,可执行docker ps查看端口映射状态;若端口被占用,可修改docker-compose.yml中的端口配置(如将8000:8000改为8001:8000),同时确保防火墙已放行对应端口。
问题3:训练时出现“显存不足”的报错?
解答:可通过以下方式降低显存占用:① 启用LoRA轻量化训练(而非全量微调);② 减小批次大小(batch_size),建议设置为1或2;③ 启用梯度累积(gradient accumulation),在配置文件中增加gradient_accumulation_steps: 4等参数;④ 降低模型精度(如使用FP16混合精度训练),在配置文件中开启mixed_precision: fp16。
问题4:训练过程中断后无法续训?
解答:AI Toolkit默认支持断点续训,只需确保配置文件中的resume_from_checkpoint参数设置为latest,重启训练命令即可从最近的检查点恢复,无需重新开始。若仍无法续训,可手动删除logs/文件夹中的损坏检查点,或重新指定有效的检查点路径。
问题5:训练的LoRA模型生成结果风格不明显?
解答:可能是训练数据不足或参数设置不当,解决方案:① 增加训练数据量(建议至少50张风格统一的图片);② 提高训练步数(延长训练时间);③ 调整LoRA的秩(Rank),秩值越高,风格拟合能力越强(但显存占用会增加);④ 增大学习率(可尝试将学习率从1e-4调整为2e-4)。
问题6:生成的视频存在帧间卡顿或逻辑混乱?
解答:这是视频扩散模型训练的常见问题,可通过以下方式优化:① 启用旋转位置嵌入功能(在配置文件中开启rotary_pos_emb: True);② 增加视频数据集的帧长和数量,提升模型对时序的理解;③ 降低生成时的采样步数,平衡生成速度和流畅度。
七、相关链接
八、总结
AI Toolkit是一款面向消费级硬件的全能型扩散模型训练套件,由Ostris团队开源并维护,其核心优势在于兼顾了易用性与功能完整性,既提供了GUI、Web等可视化操作界面,满足零基础用户的需求,又保留了CLI命令行模式和模块化底层架构,适配资深开发者的定制化和自动化需求。该工具支持图像与视频类扩散模型的训练,尤其在LoRA轻量化训练和旋转位置嵌入技术上有专项优化,可在10GB显存的消费级显卡上实现高效训练,同时提供Docker一键部署、扩展插件开发、多平台模型联动等便捷功能,其应用场景覆盖个人爱好者的个性化定制、小型工作室的内容生产、开发者的技术验证、教育领域的实践教学以及开源社区的模型共建等多个维度。此外,项目拥有完善的文档教程、示例笔记本和社区支持,同时接受多方赞助保障持续迭代,为不同层次的用户提供了从模型训练到部署分发的全链路AI工具支持,是消费级扩散模型训练领域不可多得的开源解决方案。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/ai-toolkit.html





