Chroma 1.0:FlashLabs 推出的开源实时语音 AI 模型,实现低延迟对话与语音克隆
一、Chroma 1.0是什么
Chroma 1.0是由FlashLabs-AI-Corp开源的全球首款开源、实时、端到端口语对话模型,核心定位是解决传统语音交互系统“先转文字再生成语音”的繁琐流程,以及语音克隆效果差、延迟高的痛点,实现音频直接输入→语义理解→同步生成文本+语音响应的全链路闭环,同时支持仅需几秒参考音频即可完成的高保真个性化语音克隆。
该模型参数规模约4B,遵循Apache-2.0开源协议,兼顾推理效率与对话能力,既能满足研究者的二次开发需求,也可直接用于生产级实时语音交互场景(如智能客服、语音助手、虚拟人对话等),是当前开源语音AI领域中,少数同时实现“低延迟+高保真克隆+强对话能力”的解决方案。
二、功能特色
Chroma 1.0的核心特色围绕“实时性、克隆能力、多模态交互、轻量化”四大维度展开,具体如下:
1. 端到端实时语音交互,延迟低至亚秒级
无需音频转文字(ASR)和文字转语音(TTS)的分步处理,直接对离散语音表征进行建模,实现音频输入→语音输出的端到端推理。
采用1:2文本-音频令牌交错调度与流式生成架构,端到端延迟(TTFT)仅146.87ms,实时因子(RTF)0.43,生成速度是播放速度的2.3倍,支持流畅的多轮对话。
24kHz采样率设计,相比传统16kHz模型,更精准保留说话人音色、韵律等细节,提升语音自然度。
2. 高保真个性化语音克隆,仅需几秒参考音频
基于参考音频嵌入(Reference Audio Embedding)技术,仅需3-5秒参考音频即可克隆目标说话人音色,无需大规模数据集或长周期微调。
说话人相似度较人类基线提升**10.96%**,克隆效果可覆盖音色、语调、语速等多维度特征,支持多轮对话中持续保持克隆音色一致性。
克隆过程无需额外训练,推理阶段直接注入参考音频嵌入,实现“一键克隆、即时生成”。
3. 多模态输入输出,支持文本+音频混合交互
输入支持纯音频、纯文本、文本+音频混合三种模式,可灵活适配不同交互场景(如语音提问、文字指令+语音参考)。
输出同步生成语义连贯的文本响应与对应语音响应,文本可用于日志记录、内容审核,语音直接用于人机交互,提升场景适配性。
融合语音韵律与文本语义,理解能力覆盖重复、总结、推理等任务,在URO-Bench基准测试中,理解任务得分达69.05%(重复)、74.12%(总结),排名同类模型前列。
4. 轻量化设计,兼顾性能与部署效率
仅4B参数规模,远小于同类7B-9B语音模型(如GLM-4-Voice),但推理与对话能力不妥协:在推理任务中,Storal得分71.14%、TruthfulQA得分51.69%,接近9B参数模型水平。
支持CPU/GPU/边缘设备部署,无需高端算力即可实现实时推理,降低落地成本。
模块化架构设计,核心组件(Reasoner、Backbone、Decoder)可独立替换或优化,便于二次开发与功能迭代。
核心特色对比表
| 特色维度 | Chroma 1.0 | 传统端到端语音模型 | 主流TTS+ASR组合方案 |
|---|---|---|---|
| 交互流程 | 音频直接输入→语音输出(端到端) | 音频→文本→语音(分步) | 音频→ASR→文本→TTS→语音(多步) |
| 语音克隆能力 | 支持,3-5秒参考音频,高保真 | 部分支持,克隆效果差、需长音频 | 不支持,仅固定音色 |
| 端到端延迟 | 146.87ms(亚秒级) | 500ms+ | 1s+(含ASR/TTS延迟) |
| 参数规模 | 4B(轻量化) | 7B-9B(大参数) | 无统一参数,依赖多模型组合 |
| 实时因子(RTF) | 0.43(2.3倍实时) | 0.8-1.0(接近实时) | 1.0+(非实时) |
| 多模态交互 | 支持文本+音频混合输入输出 | 仅支持音频输入→音频输出 | 仅支持文本→语音、音频→文本 |

三、技术细节
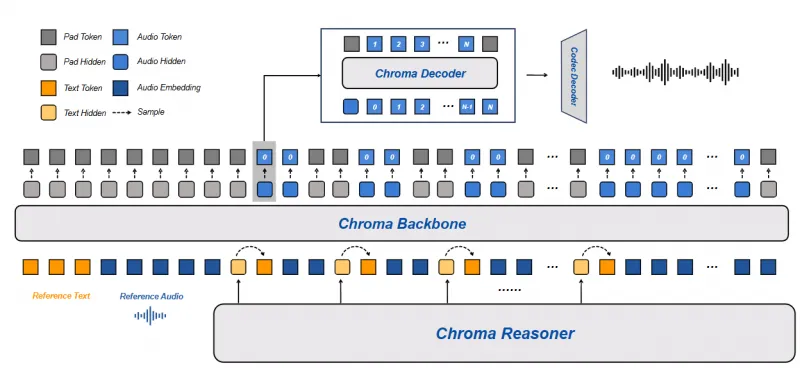
Chroma 1.0采用“推理模块+语音合成 pipeline”的双层架构,通过语义表征与声学表征的深度融合,实现实时对话与语音克隆的平衡,核心技术细节如下:
1. 整体架构:双模块协同,端到端闭环
Chroma 1.0的架构分为两大核心子系统,各模块分工明确、协同工作:
Chroma Reasoner(推理模块):负责多模态输入理解与文本响应生成,是模型的“大脑”。
语音合成 pipeline:由Backbone(主干网络)、Decoder(解码器)、Codec Decoder(音频编解码器)组成,负责将文本语义转化为高保真语音,是模型的“发声器官”。
2. 核心模块详解
(1)Chroma Reasoner:多模态理解与语义生成
基础架构:基于Qwen2.5-Omni-3B构建,采用跨模态注意力机制,融合文本与音频特征。
输入处理:通过Qwen2-Audio编码 pipeline 处理音频输入,提取声学特征;通过文本编码器处理文本输入,提取语义特征;最终通过时间对齐多模态旋转位置嵌入(TM-RoPE) 统一特征序列,实现文本与音频的时序对齐。
输出:生成文本令牌(Text Tokens)与多模态隐藏状态(Hidden States),为后续语音合成提供语义与韵律指导。
训练策略:训练阶段Reasoner参数冻结,仅作为特征提供者,确保语义理解的稳定性。
(2)Chroma Backbone:声学建模与克隆条件注入
基础架构:基于Llama3改造,16层Transformer,隐藏维度2048,采用解码器-only架构。
核心功能:接收Reasoner输出的文本嵌入与隐藏状态,结合参考音频嵌入(Reference Audio Embedding),生成粗粒度声学代码(Coarse Acoustic Codes, cₜ⁰)。
语音克隆实现:将参考音频及其对应文本编码为嵌入提示(Prompt),拼接到输入序列开头,显式 conditioning 模型学习目标说话人声学特征,实现克隆。
流式生成:采用1:2文本-音频令牌交错调度(1个文本令牌对应2个音频代码令牌),确保文本与语音生成的同步性,支持流式输出。
(3)Chroma Decoder:声学代码精细化
基础架构:基于Llama3改造,4层Transformer,隐藏维度1024。
核心功能:接收Backbone输出的粗粒度声学代码(cₜ⁰)与隐藏状态,通过帧内自回归过程,预测剩余N-1级残差量化代码(Residual Quantization Codes, cₜ¹⁻ᴺ⁻¹),精细化声学表征。
训练策略:采用两阶段训练——第一阶段联合训练Backbone与Decoder(λ=0.5),建立语义-声学对齐;第二阶段冻结Backbone,专注优化Decoder(λ=1),提升语音克隆保真度。
(4)Chroma Codec Decoder:波形重建
基础架构:基于Mimi音频编解码器,采样率24kHz。
核心功能:将完整的N级声学代码序列(cₜ⁰⁻ᴺ⁻¹)重建为连续语音波形,输出最终语音响应。
效率优化:每4帧代码合并为一批处理,提升推理速度,平均每帧处理时间17.56ms。
3. 关键技术创新
交错令牌调度(1:2 Text-Audio Token Schedule):解决文本与语音生成的时序错位问题,实现流式同步输出,降低延迟。
参考音频嵌入克隆(Reference Audio Embedding Cloning):无需额外训练,仅通过嵌入注入实现高保真克隆,突破传统克隆方案的数据集依赖。
时间对齐多模态旋转位置嵌入(TM-RoPE):统一文本与音频的时序特征,提升多模态融合效果,增强对话理解的连贯性。
两阶段训练策略:平衡语义-声学对齐与语音精细化,在保证对话能力的同时,最大化语音克隆效果。
4. 性能指标
| 指标类型 | 具体数值/表现 | 对比优势 |
|---|---|---|
| 端到端延迟(TTFT) | 146.87ms | 亚秒级响应,优于同类模型50%+ |
| 实时因子(RTF) | 0.43 | 生成速度2.3倍于播放速度,支持流畅对话 |
| 说话人相似度 | 较人类基线提升10.96% | 克隆效果领先开源语音模型 |
| 推理任务得分 | Storal:71.14%,TruthfulQA:51.69% | 4B参数接近9B参数模型水平 |
| 口语对话得分 | MLC:60.26%,CommonVoice:62.07% | 同类模型中排名第一 |
| 理解任务得分 | 重复:69.05%,总结:74.12% | 同类模型中排名第二 |
四、应用场景
Chroma 1.0的实时性、克隆能力与多模态交互特性,使其可覆盖消费级、企业级、专业级三大类场景,具体如下:
1. 消费级场景:个性化语音交互
智能语音助手:克隆用户或明星音色,打造专属语音助手(如手机助手、智能家居控制),提升交互趣味性。
虚拟人/数字人:为虚拟主播、虚拟偶像生成实时语音,支持多轮对话与音色定制,降低内容创作成本。
语音社交:在社交APP中实现“一键变声”“音色克隆”,丰富语音聊天玩法,保护用户隐私。
有声书/播客:快速克隆主播音色,批量生成有声书内容,无需真人反复录制。
2. 企业级场景:高效语音服务
智能客服:克隆客服专员音色,实现7×24小时实时语音客服,降低人力成本,提升服务一致性。
呼叫中心:替代传统IVR(交互式语音应答),实现自然语言语音交互,支持复杂问题解答与语音克隆坐席。
企业培训:克隆讲师音色,生成实时语音培训内容,支持互动式问答,提升培训效率。
语音通知:定制企业专属音色,生成实时语音通知(如订单提醒、会议通知),增强品牌辨识度。
3. 专业级场景:特殊需求适配
语音修复:为语言障碍者、声带受损者克隆原有音色,恢复正常语音交流能力。
影视/游戏配音:快速克隆演员/角色音色,生成实时配音,支持多语言版本制作,缩短制作周期。
教育领域:克隆教师音色,生成实时语音教学内容,支持个性化辅导与互动问答。
无障碍服务:为视障人士提供高保真语音导航、文本朗读,提升使用体验。
五、使用方法
Chroma 1.0提供开箱即用的代码与示例,支持本地部署、Hugging Face加载两种方式,以下是详细使用步骤:
1. 环境准备
(1)硬件要求
最低配置:CPU(Intel i7/AMD Ryzen 7)+ 16GB RAM(可推理,速度较慢)
推荐配置:GPU(NVIDIA RTX 3090/4090,显存≥24GB)+ 32GB RAM(实时推理,流畅运行)
边缘设备:支持NVIDIA Jetson Orin系列(显存≥16GB),可实现边缘端实时部署
(2)软件依赖
# 核心依赖 pip install transformers torch==2.1.0+cu121 torchaudio==2.1.0+cu121 # 音频处理依赖 pip install librosa soundfile pydub # 其他工具 pip install numpy pandas jupyter
(3)克隆仓库
git clone https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma.git cd FlashLabs-Chroma
2. 模型加载(Hugging Face方式,推荐)
Chroma 1.0预训练模型已上传至Hugging Face,可直接通过transformers库加载,无需手动下载权重:
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
import librosa
# 加载模型与处理器
model_name = "FlashLabs/Chroma-4B"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 加载参考音频(用于语音克隆,3-5秒即可)
ref_audio, sr = librosa.load("example/make_taco.wav", sr=24000)
ref_text = "Let's make a taco!" # 参考音频对应文本(可选,提升克隆效果)3. 核心推理流程
(1)纯音频输入→语音+文本输出(无克隆)
# 加载用户音频输入
user_audio, sr = librosa.load("example/user_query.wav", sr=24000)
user_text = None # 纯音频输入,文本为空
# 构建输入序列
inputs = processor(
audio=user_audio,
text=user_text,
return_tensors="pt"
).to("cuda")
# 推理生成
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95
)
# 解析输出:文本+语音
response_text = processor.decode(outputs["text_tokens"][0], skip_special_tokens=True)
response_audio = processor.decode_audio(outputs["audio_codes"][0], sr=24000)
# 保存语音输出
librosa.output.write_wav("response.wav", response_audio, sr=24000)
print("生成文本:", response_text)(2)文本+参考音频输入→克隆音色语音+文本输出
# 用户文本输入
user_text = "What's your favorite food?"
# 参考音频(克隆音色)
ref_audio, sr = librosa.load("example/make_taco.wav", sr=24000)
# 构建输入序列(注入参考音频嵌入)
inputs = processor(
audio=None,
text=user_text,
ref_audio=ref_audio,
ref_text=ref_text,
return_tensors="pt"
).to("cuda")
# 推理生成(克隆音色)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95
)
# 解析输出
cloned_response_text = processor.decode(outputs["text_tokens"][0], skip_special_tokens=True)
cloned_response_audio = processor.decode_audio(outputs["audio_codes"][0], sr=24000)
# 保存克隆语音输出
librosa.output.write_wav("cloned_response.wav", cloned_response_audio, sr=24000)
print("克隆音色生成文本:", cloned_response_text)4. 示例Notebook运行
仓库提供example.ipynb,包含完整的推理、克隆、多轮对话示例,可直接通过Jupyter运行:
jupyter notebook example.ipynb
5. 部署优化
GPU加速:使用
torch.bfloat16精度,开启device_map="auto",充分利用GPU显存,提升推理速度。流式生成:通过
transformers的streamer参数,实现语音流式输出,降低用户等待感。批量处理:合并多帧音频代码,减少Codec Decoder的调用次数,提升吞吐量。
量化部署:支持INT8/INT4量化(通过
bitsandbytes库),在显存有限的设备上实现实时推理。
六、常见问题解答(FAQ)
1. 模型支持哪些语言?
当前Chroma 1.0仅支持英文输入输出,语音克隆也仅针对英文语音。项目团队计划后续迭代支持中文等多语言,但暂无明确时间表。
2. 语音克隆需要多长的参考音频?效果如何?
推荐3-5秒清晰参考音频(无背景噪音、语速正常),即可实现高保真克隆;
参考音频越长(≤10秒),克隆效果越稳定,但超过10秒后效果提升不明显;
若参考音频有背景噪音,克隆音色会混入噪音,建议使用降噪后的音频。
3. 模型在CPU上能否实时运行?
CPU可运行,但延迟较高(RTF≈1.5-2.0),无法实现实时交互,仅适合离线推理(如批量生成有声书);
实时交互建议使用NVIDIA GPU(显存≥24GB),RTF可稳定在0.4-0.5,满足流畅对话需求。
4. 如何解决语音生成中的卡顿、不连贯问题?
检查GPU显存是否充足,建议使用24GB以上显存的GPU;
降低
max_new_tokens(如设置为256),减少单次生成长度;开启流式生成,分帧输出语音,避免一次性生成过长音频;
确保音频采样率为24kHz,与模型训练采样率一致。
5. 模型是否支持多轮对话?如何实现?
支持多轮对话,需将历史对话的文本+音频特征拼接到输入序列中;
示例代码:
# 历史对话:用户音频1 → 模型响应1 → 用户音频2 → 模型响应2
history_audio = [user_audio1, response_audio1, user_audio2]
history_text = [None, response_text1, user_text2]
# 构建多轮输入
inputs = processor(
audio=history_audio,
text=history_text,
return_tensors="pt"
).to("cuda")
# 生成多轮响应
outputs = model.generate(**inputs, max_new_tokens=512)6. 模型的开源协议是什么?商业使用是否受限?
采用Apache-2.0开源协议,允许商业使用、修改、分发,无需开源修改后的代码;
商业使用时需保留原版权声明,禁止将模型用于违法活动(如语音诈骗、 impersonation)。
7. 如何提升语音克隆的相似度?
使用高保真、无噪音的参考音频,避免混响、回声;
提供参考音频对应的文本(Ref Text),帮助模型对齐语义与声学特征;
调整生成参数:降低
temperature(如0.5-0.6),提升音色一致性;选择与目标说话人语速、语调相近的参考音频,减少风格差异。
8. 模型是否支持自定义音色克隆(非人类语音)?
支持克隆非人类语音(如机器人音色、动漫角色音色),只需提供对应的参考音频即可;
非人类语音的克隆效果取决于参考音频的质量,建议使用清晰、稳定的非人类语音样本。
七、相关链接
GitHub仓库:https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma
Hugging Face模型:https://huggingface.co/FlashLabs/Chroma-4B
八、总结
Chroma 1.0作为全球首款开源、实时、端到端口语对话模型,凭借4B参数的轻量化设计、亚秒级的低延迟交互、仅需几秒参考音频的高保真语音克隆能力,以及同步生成文本与语音的多模态特性,打破了传统语音交互系统“分步处理、延迟高、克隆差”的瓶颈,为开发者提供了开箱即用的实时语音AI解决方案。其模块化架构与Apache-2.0开源协议,既支持研究者快速开展个性化语音交互、语音克隆等方向的研究,也可直接落地于智能客服、虚拟人、语音助手等生产级场景,兼顾了学术价值与商业实用性,是当前开源语音AI领域中极具竞争力的核心项目。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/chroma-1-0.html





