DataAgent:开源AI数据智能体,自然语言对话式智能数据分析工具
一、DataAgent 是什么
DataAgent(全称:Spring AI Alibaba DataAgent) 是由 Spring AI Alibaba 生态推出的开源企业级AI数据智能体,主打自然语言转SQL(NL2SQL)能力,也被称作AI虚拟数据分析师。项目基于 Spring Boot、Spring AI Alibaba 技术栈构建,面向企业业务人员、数据分析人员、开发人员设计,彻底降低数据查询、数据分析、数据报表生成的技术门槛。
传统数据使用场景中,业务人员想要查询数据库数据、做统计分析,必须依赖技术人员编写 SQL 语句,沟通成本高、响应效率低、上手难度大。DataAgent 依托大语言模型、智能体框架、检索增强生成(RAG)等技术,实现自然语言对话式数据交互。用户仅需使用日常口语描述数据需求,系统就能自动解析语义、生成合规SQL、执行查询、返回结果,同时支持数据可视化、问题反思纠错、多轮对话分析等能力。
该项目遵循 Apache 2.0 开源协议,可免费商用、二次开发与私有化部署,完美适配国内主流大模型、数据库、向量数据库,是面向政企、中小微企业的一站式智能数据分析解决方案。
二、功能特色
DataAgent 围绕数据查询、智能分析、流程管控、扩展集成四大方向打造核心能力,功能覆盖从基础数据检索到复杂业务分析全流程,核心特色如下:
自然语言转SQL(NL2SQL)核心能力
支持中文自然语言自动解析,将口语化数据需求转化为标准可执行 SQL,兼容单表查询、多表联查、分组统计、排序筛选、聚合计算等常见数据库操作,无需人工编写代码。智能反思与错误自愈
内置 ReAct 智能体反思机制,当生成的 SQL 执行报错、语义与需求不符时,智能体可自动识别问题、回溯上下文、修正 SQL 语句,多次重试直至得到正确结果,大幅提升查询成功率。检索增强生成(RAG)知识库联动
支持接入向量数据库,将数据表结构、业务术语、数据字典、历史查询案例构建为专属知识库。大模型结合知识库生成 SQL,有效规避字段理解错误、表名混淆、业务语义偏差等问题。多轮对话连续分析
支持上下文记忆,可承接多轮递进式数据提问。例如先查询月度销售额,再基于结果追问区域占比、同比数据,全程无需重复描述基础条件。多数据源兼容
主流关系型数据库全覆盖,同时支持灵活扩展数据源类型,满足企业多库并存的复杂数据环境。可视化报表与分析报告生成
数据查询完成后,可自动将原始数据转换为图表展示,并根据分析结果生成文字版数据分析报告,直接交付业务使用。灵活的流程人工介入
生产环境中支持人工审核环节,关键SQL、高权限数据查询可设置人工确认步骤,兼顾智能化与数据安全、权限管控。全生态模型适配
原生兼容通义千问、DeepSeek、主流开源大模型、海外主流大模型等,用户可根据自身部署环境、成本预算自由切换模型。模块化架构,易集成扩展
项目采用分层模块化设计,拆分核心能力模块、管理模块、公共工具模块,支持嵌入现有业务系统、OA平台、BI平台,实现能力复用。

三、技术细节
3.1 整体技术栈
项目基于 Java 生态开发,后端主体框架稳定成熟,配套中间件、组件均为企业生产级技术,完整技术栈如下:
基础框架:Spring Boot 、Spring AI Alibaba
运行环境:JDK 17 及以上
构建工具:Apache Maven 3.6+
智能体范式:ReAct 智能体架构(思考+行动闭环)
核心AI能力:NL2SQL、RAG 检索增强、上下文记忆、反思纠错
数据存储:MySQL 5.7+(元数据、配置、日志存储)
向量数据库:内置内存向量库,兼容 Elasticsearch、PGVector、Milvus 等主流向量库
接口文档:内置 Swagger 接口文档,便于接口调试与二次开发
前端技术:Node.js 生态,独立前端工程,默认端口 3000
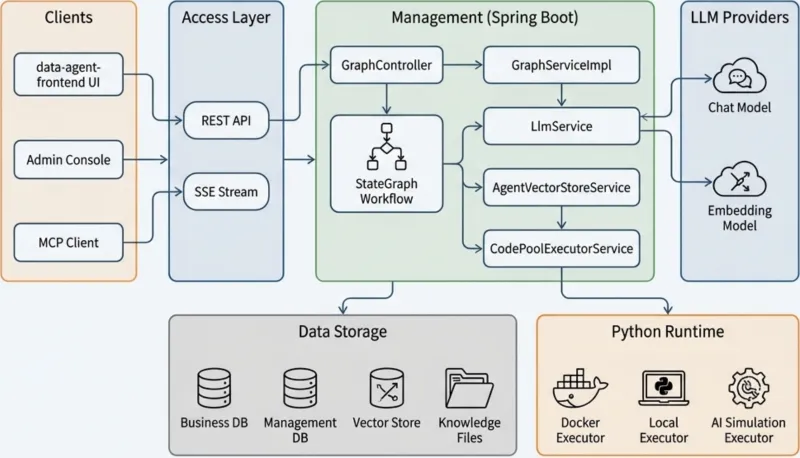
3.2 项目代码结构
项目采用模块化拆分,代码解耦度高,便于维护、单独编译与功能裁剪,整体目录结构如下:
spring-ai-alibaba-dataagent/ ├── spring-ai-alibaba-data-agent-management # 管理端Web应用,独立可启动,提供可视化操作页面 ├── spring-ai-alibaba-data-agent-chat # 核心业务模块,承载对话、NL2SQL、智能体逻辑,供外部集成 └── spring-ai-alibaba-data-agent-common # 公共依赖、工具类、常量、通用配置,全模块共享
management:面向终端用户的可视化操作平台,包含数据源配置、模型配置、对话页面、查询记录管理等功能,是本地测试、正式使用的主要入口。chat:核心能力层,封装智能体、SQL生成、RAG检索、多轮对话等核心逻辑,无独立启动入口,以依赖包形式被其他模块引用。common:通用工具、异常处理、实体类、全局配置,统一规范项目基础能力。
3.3 核心执行流程
DataAgent 完整执行链路遵循 「用户提问→语义解析→知识库检索→SQL生成→执行校验→反思修正→结果输出」 闭环:
用户在前端输入自然语言数据需求;
系统调用大模型解析用户语义,提取查询条件、统计维度、目标数据表等关键信息;
RAG 模块检索向量知识库,匹配数据表结构、字段释义、业务规则等内容,补充上下文;
ReAct 智能体结合语义与知识库信息,生成标准 SQL 语句;
系统连接目标数据库执行 SQL,捕获执行结果或报错信息;
若执行失败、结果不符合预期,触发反思纠错机制,分析错误原因并重新生成SQL;
最终将查询数据、图表、分析报告返回前端展示,同时保存查询记录。
3.4 部署相关配置
后端服务默认端口:8065,接口文档访问地址:
http://localhost:8065/swagger-ui.html前端页面默认端口:3000
部署方式:支持 IDE 本地启动、Maven 打包部署、Docker Compose 容器化一键部署,适配传统服务器、云服务器、容器集群等多种环境。
四、应用场景
DataAgent 面向企业数字化、数据分析、业务运营、技术研发等多类场景,落地范围广泛,核心应用场景分类如下:
4.1 企业内部自助数据分析
业务运营、市场、销售、行政等非技术人员,无需学习 SQL,通过自然语言自主查询业务数据,例如销量统计、用户数据、订单报表、考勤数据等,大幅减少对开发、运维人员的依赖。
4.2 数据中台 & BI 平台能力增强
将 DataAgent 集成至企业现有数据中台、BI 系统,为传统数据平台增加自然语言交互入口,升级传统可视化报表为智能对话式数据分析。
4.3 政企单位政务数据查询
政务、事业单位内部数据体量庞大、数据表繁多,借助 DataAgent 降低基层人员数据使用门槛,提升政务数据调取、统计、汇总的工作效率。
4.4 中小微企业轻量化数据分析
中小团队无专职数据分析师、DBA,使用 DataAgent 搭建轻量化智能数据分析平台,低成本实现数据自助查询与简单分析。
4.5 软件开发 & 测试辅助
开发、测试人员可通过自然语言快速查询测试库、业务库数据,快速校验功能逻辑、排查数据异常,提升研发与测试效率。
4.6 教育教学场景
高校、培训机构用于大数据、人工智能、数据库相关教学演示,直观展示 NL2SQL、AI 智能体、RAG 等前沿技术落地效果。
五、使用方法
5.1 前置环境准备
安装 JDK 17 并配置环境变量,确保 Java 环境正常运行;
安装 Maven 3.6 及以上版本,配置 Maven 镜像源;
部署 **MySQL 5.7+**,创建专属数据库,用于存储项目元数据、配置信息、操作日志;
准备可用大模型 API Key(通义千问、DeepSeek 等均可),保证网络可正常调用模型接口。
5.2 项目启动步骤
拉取项目代码至本地,使用 IDEA、Eclipse 等开发工具导入 Maven 项目;
进入
spring-ai-alibaba-data-agent-management模块,修改配置文件,配置 MySQL 连接地址、账号、密码、数据库名、大模型接口地址与密钥;执行 Maven 依赖下载,等待所有依赖包加载完成;
启动管理端主程序,后端服务默认监听 8065 端口;
进入前端工程,安装依赖并启动前端服务,前端默认监听 3000 端口。
5.3 基础功能使用
浏览器访问
http://localhost:3000进入 DataAgent 首页;数据源配置:添加需要分析的业务数据库,填写数据库地址、账号、密码、库名,完成数据源连接测试;
模型配置:选择已接入的大模型,填写接口密钥、请求参数,完成模型连通性校验;
知识库配置(可选):上传数据表结构、数据字典,构建专属向量知识库,提升 SQL 准确率;
对话查询:在对话输入框中,使用中文描述数据需求,例如“查询本月所有订单总金额”,发送后系统自动完成解析、查询并返回结果、图表与分析报告;
多轮对话:基于上一轮结果继续追问,系统保留上下文,实现连续数据分析。
六、竞品对比
选取目前市面上主流的开源/商用 NL2SQL 类智能数据分析产品,从产品形态、开源属性、技术架构、部署难度、生态适配、适用场景六个维度进行对比,直观展示 DataAgent 差异化优势。
| 对比维度 | Spring AI Alibaba DataAgent | 开源 NL2SQL 框架 Chat2DB | 商用智能数据分析平台 帆软AI数据分析 |
|---|---|---|---|
| 产品形态 | 企业级AI数据智能体,自带完整前后端、管理后台、对话界面 | 轻量化开源NL2SQL工具,以命令行+简易Web为主 | 商用一体化BI平台,AI分析为附加功能 |
| 开源属性 | Apache 2.0 开源,支持免费商用、二次开发、私有化部署 | 开源协议宽松,可私有化部署 | 闭源商用,按版本/节点收费,无源码 |
| 技术架构 | Spring Boot + Spring AI Alibaba + ReAct智能体 + RAG | 轻量化Python架构,主打轻量化NL2SQL | 自研商用架构,闭源技术体系 |
| 部署难度 | 中等,基于Java生态,容器化一键部署,适配企业运维习惯 | 低,Python环境依赖少,快速启动 | 高,商用平台需专业实施部署 |
| 生态适配 | 深度适配国内大模型、国产数据库、向量库,Java生态兼容性强 | 适配主流大模型,数据库兼容广,Java生态集成较弱 | 仅适配自身BI体系,模型接入受限 |
| 适用场景 | 企业自研系统集成、Java技术栈团队、私有化智能数据分析 | 个人测试、小型团队临时数据查询、Python技术栈 | 大型企业全套BI可视化+数据分析,预算充足团队 |
总结差异:DataAgent 最大优势是深度贴合国内 Java 企业生态,兼顾开源自由、智能体全能力与企业级管控能力,是 Java 技术栈团队搭建自有AI数据分析平台的最优选择;Chat2DB 胜在轻量化,适合快速试用;商用BI平台功能全面但成本高、无法二次定制。
七、常见问题解答
Q:DataAgent 最低需要什么版本的 JDK?
A:项目强制要求 JDK 17 及以上版本,低版本 JDK 会出现依赖报错、程序无法启动等问题,部署前请务必升级运行环境。
Q:项目启动后前端页面无法访问是什么原因?
A:首先检查前端服务是否正常启动,确认 3000 端口未被其他程序占用;其次检查后端 8065 端口状态,前后端服务必须全部正常运行;最后核对前后端接口地址配置是否一致,跨域配置是否开启。
Q:自然语言提问后,系统生成SQL但数据库执行失败怎么办?
A:首先查看报错日志,判断是表名、字段名错误还是查询权限不足。若为语义解析错误,建议完善 RAG 知识库,补充数据表结构与业务说明;若为权限问题,为数据库账号分配对应表的查询权限。同时项目自带反思纠错功能,可等待系统自动重试修正。
Q:DataAgent 支持哪些类型的数据库?
A:原生支持 MySQL 等主流关系型数据库,基于 JDBC 标准协议开发,理论上可兼容所有支持 JDBC 连接的关系型数据库,非原生数据库可通过扩展驱动实现适配。
Q:是否可以脱离公网,在内网纯离线环境部署使用?
A:纯离线环境下,需部署本地私有化大模型与本地向量数据库,同时提前下载所有 Maven、前端依赖包,关闭公网模型接口调用,配置本地模型地址,即可实现内网离线运行。
Q:能否将 DataAgent 集成到公司现有的业务系统中?
A:可以。项目采用模块化设计,核心能力封装在 chat 模块中,同时提供完整 Swagger 接口文档,业务系统可通过 HTTP 接口调用数据查询、对话分析等能力,快速完成功能嵌入。
Q:RAG 知识库是否必须配置?不配置可以正常使用吗?
A:RAG 知识库为可选功能,不配置也能正常使用基础 NL2SQL 能力。但缺少知识库会导致复杂业务场景下 SQL 生成准确率下降,企业正式使用建议配置专属知识库。
八、相关链接
九、总结
Spring AI Alibaba DataAgent 是一款立足 Java 企业生态、面向国内市场打造的开源AI数据智能体,以自然语言转SQL为核心,融合 ReAct 智能体、检索增强生成、自动纠错、多轮对话等前沿AI技术,一站式解决企业数据查询门槛高、沟通成本大、分析效率低等痛点。项目架构模块化、部署灵活、生态兼容性强,不仅可以作为独立的智能数据分析平台使用,还能轻松集成至数据中台、BI系统、各类业务平台中,同时依托开源协议赋予用户高度的自主定制与私有化部署能力。无论是企业业务人员自助分析数据、技术团队拓展系统AI能力,还是小型团队搭建轻量化数据工具,该项目都具备极高的实用价值与落地价值,是当下 Java 生态中优质的开源NL2SQL智能体解决方案。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/dataagent.html