HeartMuLa:开源多语言音乐基础模型,一站式实现音乐生成与音文处理
一、HeartMuLa是什么
HeartMuLa是一套开源的多语言音乐基础模型项目,核心目标是构建全链路的音乐生成与音视频文本处理能力,为开发者、研究者和普通用户提供开箱即用的音乐AI工具集。它并非单一模型,而是由四大核心模型组成的生态体系,以Apache 2.0协议完全开源,是首个能在学术级数据和GPU资源下,复现Suno级商业音乐生成效果的开源项目。
简单来说,HeartMuLa就像一位“全能音乐AI助手”:你给它一段歌词、几个风格标签,它就能生成完整的歌曲;你给它一段音乐,它能精准提取歌词;你想找匹配“轻快、海边、爵士”描述的音乐,它能帮你快速检索;甚至它还能把音乐压缩成小体积文件,还能高保真还原。更重要的是,它原生支持中英日韩西等多语种,不用额外翻译适配,就能用母语创作音乐,彻底打破了音乐生成的语言壁垒。
在长期由闭源产品主导的AI音乐领域,HeartMuLa的出现意义重大——它把原本只有商业公司能掌握的高质量音乐生成技术,开放给所有开发者和创作者,降低了音乐AI的开发与使用门槛,让每个人都能轻松拥有“专属音乐创作能力”。
二、功能特色
HeartMuLa的核心竞争力在于全链路覆盖+多语言适配+高可控性+开源友好,四大核心功能模块各司其职又能协同工作,同时具备多项独特亮点,具体如下:
(一)核心功能
多语言可控音乐生成
支持基于歌词、风格标签、情绪描述等文本输入,生成完整的歌曲(包含旋律、伴奏、人声),原生适配英语、中文、日语、韩语、西班牙语5大语种,后续还将扩展更多语种。生成的音乐结构完整,能区分主歌、副歌、桥段等段落,贴合歌词的韵律和情感。高保真音乐编解码
核心组件HeartCodec是12.5Hz的音乐编解码器,能将原始音频压缩成低维度的token序列,同时保证重建音频的高保真度,压缩比高且音质损失极小,既节省存储和传输成本,又能为音乐生成模型提供高效的输入输出载体。精准音乐歌词转录
基于Whisper模型微调的HeartTranscriptor,专门针对音乐场景优化,能从带伴奏、有噪声的音乐音频中,精准提取歌词内容,支持多语种歌词识别,解决了传统语音转录模型在音乐场景下准确率低的问题。音文跨模态对齐与检索
HeartCLAP构建了音乐音频与文本描述的统一嵌入空间,实现“文字描述→匹配音乐”“音乐→生成文本标签”的双向能力,支持跨模态音乐检索、音乐标签自动生成,为音乐内容管理和推荐提供技术支撑。
(二)独特亮点
学术级资源实现商业级性能
这是HeartMuLa最核心的突破——它仅用学术规模的训练数据和GPU资源,就实现了与Suno比肩的音乐生成效果,7B版本在音乐性、音频保真度、内容可控性三大核心指标上,完全达到商业级标准,打破了“高质量音乐生成必须依赖海量商业数据和超算资源”的认知。强化学习优化的极致可控性
2026年1月23日发布的HeartMuLa-RL-oss-3B版本,通过近端策略优化(PPO)强化学习技术,大幅提升了音乐生成的可控性。用户可以通过细粒度的风格标签(如“华语流行、钢琴伴奏、慢板、伤感”)、乐器指定、节奏要求等,精准控制音乐的生成结果,告别“生成结果不可控、与预期偏差大”的痛点。全开源无门槛,生态友好
项目代码、所有预训练模型权重均采用Apache 2.0开源协议,允许商业使用、二次开发和修改,无任何使用限制。同时,社区已贡献ComfyUI自定义节点,让非编程用户也能通过可视化界面使用核心功能,进一步降低了使用门槛。原生多语言支持,非翻译适配
与多数开源音乐模型“先训练英文再翻译适配其他语种”不同,HeartMuLa采用多语种并行训练的方式,原生支持中英日韩西等语种,生成的音乐能贴合不同语言的韵律特点(比如中文的四声韵律、日语的节拍特点),避免了翻译后生成的音乐“生硬、不自然”的问题。模块化设计,灵活组合使用
四大核心模型相互独立又可协同工作:开发者可以单独使用HeartCodec做音频压缩,用HeartTranscriptor做歌词转录,也可以组合使用“HeartCodec+HeartMuLa”做音乐生成,“HeartCLAP+HeartMuLa”做基于文本描述的音乐生成,满足不同场景的定制化需求。

三、技术细节
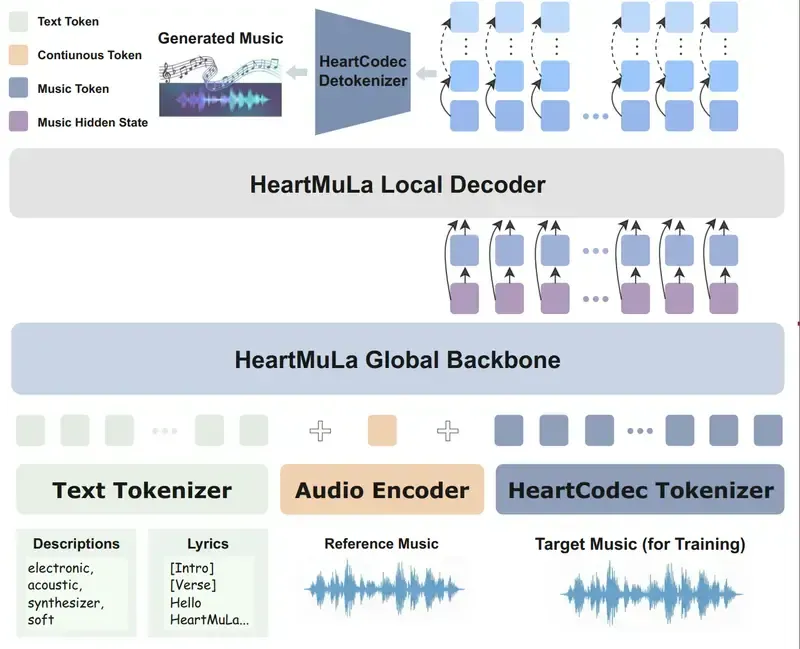
HeartMuLa的技术架构围绕“全链路音乐AI能力”设计,采用“核心模型层+工具层+示例层”的三层架构,核心原理基于Transformer、对比学习、强化学习等主流AI技术,技术栈以Python和PyTorch为核心,兼顾性能与易用性。
(一)整体技术架构
| 层级 | 核心内容 | 作用 |
|---|---|---|
| 核心模型层 | HeartMuLa、HeartCodec、HeartTranscriptor、HeartCLAP | 提供音乐生成、编解码、转录、对齐四大核心能力 |
| 工具层 | 模型加载工具、推理加速工具、数据预处理工具 | 简化模型使用流程,优化推理性能 |
| 示例层 | 音乐生成、歌词转录、音文检索示例脚本 | 提供开箱即用的实操案例,帮助用户快速上手 |
(二)核心模型原理
HeartMuLa:音乐生成的“核心大脑”
HeartMuLa是基于Transformer架构的音乐语言模型,本质是“文本→音乐token”的序列生成模型。其核心原理是:先通过HeartCodec将原始音频转换成低维度的token序列(相当于把音乐“数字化”),再将用户输入的文本(歌词、标签)进行编码,最后通过Transformer的自注意力机制,学习文本与音乐token之间的映射关系,生成对应的音乐token序列,最终通过HeartCodec解码成可播放的音频。为了提升可控性,项目团队在3B版本的基础上,引入了PPO强化学习:先通过监督学习让模型学会基础的音乐生成,再通过人工标注的“音乐质量评分”“可控性评分”作为奖励信号,让模型不断优化生成策略,最终实现“用户输入什么,就生成什么”的精准控制。
HeartCodec:音乐的“高清压缩器”
HeartCodec是基于神经编解码技术的音乐压缩模型,核心原理是变分自编码器(VAE)+ 残差量化(RVQ)。它先通过编码器将原始音频(采样率44.1kHz)压缩成12.5Hz的低帧率token序列,再通过解码器将token序列还原成原始音频。与传统音频编码(如MP3、AAC)相比,HeartCodec的优势在于:一是专为音乐优化,对旋律、和声、人声等音乐核心元素的重建保真度更高;二是压缩后的token序列更适合作为AI模型的输入,能大幅降低音乐生成模型的计算量;三是12.5Hz的帧率平衡了压缩比和音质,既节省存储,又保证了音乐的完整性。
HeartTranscriptor:音乐歌词的“精准速记员”
HeartTranscriptor基于OpenAI的Whisper模型微调,核心优化点是音乐场景适配。传统Whisper模型主要针对语音场景优化,在音乐场景下,容易被伴奏、和声、节奏等干扰,导致歌词识别准确率低。项目团队通过收集海量多语种音乐音频-歌词对数据,对Whisper进行微调:一是加入音乐噪声抑制模块,过滤伴奏等干扰信号;二是优化语言模型,适配音乐歌词的韵律和句式特点;三是针对不同语种的发音规则,进行专项优化,最终实现了在音乐场景下的高准确率歌词转录。
HeartCLAP:音文之间的“翻译官”
HeartCLAP基于对比学习(Contrastive Learning)技术,核心原理是构建音乐音频-文本描述的统一嵌入空间。它通过大量的“音乐音频+对应文本标签”数据进行训练,让模型学会将语义相近的文本(如“轻快的爵士”“海边的轻音乐”)和对应的音乐音频,映射到嵌入空间中相近的位置,而语义无关的文本和音频则映射到较远的位置。基于这一原理,HeartCLAP实现了两大核心能力:一是文本→音乐检索,输入文本描述,就能找到嵌入空间中最匹配的音乐;二是音乐→文本生成,输入音乐音频,就能生成对应的风格、情绪、乐器等标签,为音乐内容的自动化管理提供支撑。
(三)关键技术栈
核心框架:Python 3.10+、PyTorch 2.0+
模型架构:Transformer、VAE、RVQ、Whisper、对比学习、PPO强化学习
工具库:Hugging Face Transformers、Accelerate、Torchaudio、Librosa
部署工具:Hugging Face Hub、ModelScope、ComfyUI
数据处理:音频预处理(重采样、降噪)、文本预处理(分词、多语言编码)
(四)核心模型版本对比
| 模型版本 | 参数规模 | 发布时间 | 核心特性 | 可控性 | 性能表现 |
|---|---|---|---|---|---|
| HeartMuLa-oss-3B | 3B | 2026.01.14 | 基础多语言音乐生成,支持歌词/标签输入 | 基础标签/歌词控制 | 音乐性、保真度良好,满足基础创作需求 |
| HeartMuLa-RL-oss-3B | 3B | 2026.01.23 | 强化学习优化,支持细粒度风格/乐器/节奏控制 | 极高,可精准匹配用户预期 | 媲美Suno基础版,生成音乐的可控性大幅提升 |
| HeartMuLa-oss-7B | 7B | 待发布 | 更大参数量,更强音乐理解与生成能力,支持更复杂的音乐结构 | 极致可控,支持自定义编曲、多段落衔接 | 全面对标Suno旗舰版,音乐性和复杂度达到商业顶级水平 |
| HeartCodec-oss | - | 2026.01.14/2026.01.23 | 12.5Hz音乐编解码,20260123版本优化解码质量 | - | 高保真重建,压缩比高,适配音乐生成模型 |
| HeartTranscriptor-oss | - | 2026.01.14 | 基于Whisper微调,多语种音乐歌词转录 | - | 音乐场景下准确率远超通用语音转录模型 |
| HeartCLAP-oss | - | 2026.01.14 | 音文跨模态对齐,支持音乐检索与标签生成 | - | 音文匹配准确率高,适配多语种描述 |
四、应用场景
HeartMuLa的全链路音乐AI能力,覆盖了开发者、研究者、普通用户三大角色,以及音乐创作、内容创作、教育、娱乐、工具开发五大行业,具体应用场景如下:
(一)按角色划分
开发者
快速集成音乐生成能力:将HeartMuLa的API或模型集成到自己的应用中,比如音乐APP、短视频工具、游戏、播客平台,为用户提供“一键生成配乐”“AI写歌”等功能。
开发定制化音乐工具:基于模块化设计,单独使用HeartCodec做音频压缩服务,HeartTranscriptor做歌词转录工具,HeartCLAP做音乐检索引擎,打造垂直领域的音乐AI产品。
二次开发与优化:基于开源权重,针对特定语种(如粤语、法语)、特定曲风(如国风、电子)进行微调,打造更贴合细分场景的音乐生成模型。
研究者
音乐AI基础研究:以HeartMuLa为基线模型,开展音乐生成、音文对齐、多模态学习等方向的研究,比如探索更高效的音乐编解码技术、更精准的强化学习奖励函数、跨语言音乐生成的迁移学习方法。
学术验证与复现:基于项目提供的代码和权重,复现Suno级音乐生成效果,验证“学术级资源实现商业级性能”的结论,为音乐AI领域的研究提供参考。
跨领域研究:结合计算机视觉、自然语言处理,开展“视频→配乐”“文本→音乐视频”等跨模态研究,拓展音乐AI的应用边界。
普通用户
零基础音乐创作:无需懂乐理、会乐器,通过输入歌词和风格标签,就能生成专属歌曲,适合独立音乐人、音乐爱好者创作demo,或普通人记录生活、创作生日礼物。
内容创作配乐:短视频博主、播客主播、自媒体作者,可快速生成匹配内容风格的背景音乐,避免版权纠纷,提升内容质量。
音乐学习与娱乐:语言学习者通过多语种音乐,提升语言听力和语感;音乐爱好者通过歌词转录功能,学习歌曲歌词;通过音文检索功能,发现更多符合自己口味的音乐。
(二)按行业划分
音乐创作行业
独立音乐人:快速生成歌曲demo,节省编曲、录音时间,专注于歌词和旋律创作;针对不同语种的市场,生成多语种歌曲,拓展海外受众。
音乐工作室:批量生成配乐、背景音乐,降低制作成本;基于HeartCLAP的标签生成能力,对音乐库进行自动化分类和管理。
内容创作行业
短视频/直播:生成专属BGM,避免版权问题;根据视频内容的情绪、风格,生成匹配的音乐,提升视频感染力。
播客/有声书:生成片头、片尾音乐,或背景轻音乐,提升内容的听觉体验。
广告/宣传片:快速生成贴合广告主题的音乐,缩短制作周期,降低制作成本。
教育行业
语言教育:通过多语种音乐生成,制作语言学习素材,让学生在听歌中学习单词、语法和发音;通过歌词转录功能,辅助学生进行听力训练。
音乐教育:为音乐初学者生成简单的旋律、伴奏,帮助其理解乐理知识;通过对比生成的音乐和专业音乐,提升学生的音乐鉴赏能力。
娱乐行业
游戏开发:为游戏生成场景音乐、战斗音乐、剧情音乐,根据游戏场景的变化,动态生成匹配的音乐,提升游戏沉浸感。
互动娱乐:开发AI音乐创作互动游戏,让用户参与音乐生成过程,比如“输入一句话,生成一首专属歌曲”。
音乐社交:打造音乐创作社交平台,用户可分享自己生成的音乐,或基于他人的歌词进行二次创作,形成音乐创作社区。
工具开发行业
音乐工具:开发歌词转录APP、音乐压缩工具、音乐检索工具,为音乐爱好者和从业者提供实用工具。
版权服务:基于HeartCLAP的音文对齐能力,开发音乐版权检索工具,快速识别侵权音乐,保护版权方权益。
五、使用方法
HeartMuLa的部署和使用非常简单,支持本地部署和云端部署,以下是从零开始的本地快速上手指南,涵盖环境准备、安装、权重下载、运行示例全流程,即使是编程新手也能轻松上手。
(一)环境准备
系统要求:Windows 10+/macOS 12+/Linux(Ubuntu 20.04+)
Python版本:推荐Python 3.10(3.9-3.11均可)
硬件要求:
最低配置:CPU(Intel i5/AMD R5以上)+ 16GB内存(仅支持CPU推理,速度慢)
推荐配置:NVIDIA GPU(RTX 3090/4090及以上)+ 24GB显存(支持GPU推理,速度快,可运行3B模型)
7B模型(待发布):需NVIDIA GPU(RTX A100及以上)+ 40GB+显存
(二)安装步骤
克隆项目代码
打开终端(Windows用CMD/PowerShell,macOS/Linux用Terminal),执行以下命令克隆GitHub仓库:
git clone https://github.com/HeartMuLa/heartlib.git cd heartlib
创建虚拟环境(推荐)
为避免依赖冲突,建议使用conda创建虚拟环境:
# 安装conda(若已安装可跳过) # 下载Miniconda:https://docs.conda.io/en/latest/miniconda.html conda create -n heartmula python=3.10 conda activate heartmula
安装项目依赖
执行以下命令,安装项目所需的所有Python依赖:
pip install -e .
若安装速度慢,可使用国内镜像源:
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
(三)下载预训练权重
HeartMuLa的预训练权重可从Hugging Face Hub和ModelScope两大平台下载,推荐使用Hugging Face的hf-download工具,或ModelScope的modelscope库,以下是两种方式的实操步骤:
方式一:Hugging Face Hub下载(推荐)
安装
hf-download工具:
pip install hf-download
创建权重存储目录:
mkdir -p ./ckpt/HeartMuLa-RL-oss-3B mkdir -p ./ckpt/HeartCodec-oss mkdir -p ./ckpt/HeartTranscriptor-oss mkdir -p ./ckpt/HeartCLAP-oss
下载核心模型权重(以最新的RL优化版为例):
# 下载HeartMuLa-RL-oss-3B hf-download --local-dir './ckpt/HeartMuLa-RL-oss-3B' 'HeartMuLa/HeartMuLa-RL-oss-3B-20260123' # 下载HeartCodec-oss(20260123优化版) hf-download --local-dir './ckpt/HeartCodec-oss' 'HeartMuLa/HeartCodec-oss-20260123' # 下载HeartTranscriptor-oss hf-download --local-dir './ckpt/HeartTranscriptor-oss' 'HeartMuLa/HeartTranscriptor-oss' # 下载HeartCLAP-oss hf-download --local-dir './ckpt/HeartCLAP-oss' 'HeartMuLa/HeartCLAP-oss'
方式二:ModelScope下载(国内速度更快)
安装ModelScope库:
pip install modelscope
编写下载脚本(
download_weights.py):
from modelscope import snapshot_download # 下载HeartMuLa-RL-oss-3B snapshot_download( model_id="HeartMuLa/HeartMuLa-RL-oss-3B-20260123", local_dir="./ckpt/HeartMuLa-RL-oss-3B" ) # 下载HeartCodec-oss snapshot_download( model_id="HeartMuLa/HeartCodec-oss-20260123", local_dir="./ckpt/HeartCodec-oss" ) # 其他模型同理
运行脚本:
python download_weights.py
(四)运行第一个示例
项目的examples目录提供了多个开箱即用的示例脚本,以下以音乐生成和歌词转录为例,演示核心功能的使用。
示例1:运行音乐生成(run_music_generation.py)
进入示例目录:
cd examples
编辑脚本,修改输入参数(可选):
打开run_music_generation.py,修改lyrics(歌词)、tags(风格标签)、model_path(模型权重路径)等参数,示例:
# 核心参数修改 lyrics = """ 主歌: 窗外的雨滴 敲打着玻璃 思念像潮水 淹没了呼吸 副歌: 我还在等你 等你的归期 就算世界 都变成回忆 """ tags = ["华语流行", "钢琴伴奏", "慢板", "伤感"] model_path = "../ckpt/HeartMuLa-RL-oss-3B" codec_path = "../ckpt/HeartCodec-oss"
运行脚本:
python run_music_generation.py
查看结果:
运行完成后,会在examples/output目录下生成可播放的音频文件(如generated_song.wav),直接打开即可收听生成的音乐。
示例2:运行歌词转录(run_lyrics_transcription.py)
准备待转录的音乐音频(如
test_song.wav,支持wav、mp3格式),放入examples目录。编辑脚本,修改输入参数:
打开run_lyrics_transcription.py,修改audio_path(音频路径)、model_path(转录模型路径)等参数:
audio_path = "test_song.wav" model_path = "../ckpt/HeartTranscriptor-oss" language = "zh" # 语种:zh(中文)、en(英文)、ja(日语)、ko(韩语)、es(西班牙语)
运行脚本:
python run_lyrics_transcription.py
查看结果:
运行完成后,会在终端输出转录的歌词,同时生成lyrics_output.txt文件保存结果。
(五)可视化使用(ComfyUI节点)
若不想写代码,可使用社区贡献的ComfyUI自定义节点,通过可视化界面使用HeartMuLa:
安装ComfyUI(参考:https://github.com/comfyanonymous/ComfyUI)
下载HeartMuLa ComfyUI节点(社区链接:https://github.com/Benji/ComfyUI-HeartMuLa)
将节点放入ComfyUI的
custom_nodes目录,重启ComfyUI在ComfyUI中加载HeartMuLa节点,配置模型路径、输入歌词/标签,一键生成音乐
六、常见问题解答
问题1:安装依赖时出现“版本冲突”“安装失败”
解决方案:
优先使用conda虚拟环境,隔离不同项目的依赖;
升级pip到最新版本:
pip install --upgrade pip;手动安装冲突的依赖包,指定兼容版本:比如
pip install torch==2.0.1 torchaudio==2.0.2;使用国内镜像源安装,避免网络问题导致的安装失败。
问题2:下载模型权重时速度慢、下载失败
解决方案:
切换到ModelScope下载,国内速度更快;
使用代理工具(若有),或在网络稳定的时段下载;
手动下载权重文件(从Hugging Face/ModelScope网页下载),放入对应的
ckpt目录;检查磁盘空间,确保有足够的存储空间(3B模型权重约15GB,HeartCodec约2GB)。
问题3:运行示例时提示“显存不足”
解决方案:
降低batch size(音乐生成脚本中
batch_size=1即可);使用CPU推理(修改脚本中的
device="cpu"),但推理速度会大幅变慢;更换更小的模型版本(如用3B基础版代替RL版);
开启模型混合精度推理(
torch.cuda.amp.autocast()),节省显存。
问题4:生成的音乐风格与预期不符、质量差
解决方案:
使用最新的HeartMuLa-RL-oss-3B版本,可控性更强;
细化风格标签,避免模糊描述(比如不用“好听的歌”,改用“华语流行、钢琴伴奏、4/4拍、中速”);
优化歌词格式,按主歌、副歌、桥段分段,保持韵律一致;
调整生成参数(如
temperature=0.7,降低随机性,提升可控性)。
问题5:歌词转录准确率低,漏词、错词多
解决方案:
使用高质量的音频文件(采样率≥44.1kHz,无明显噪声);
正确指定语种参数(
language),避免语种不匹配;针对特定语种,使用专项优化的转录模型(若有);
对音频进行预处理(降噪、人声增强),再进行转录。
问题6:ComfyUI节点无法加载,提示“模型路径错误”
解决方案:
检查ComfyUI的
custom_nodes目录是否正确放置节点文件;确认节点中配置的模型路径与本地
ckpt目录一致,使用绝对路径避免错误;更新ComfyUI到最新版本,兼容新节点;
安装节点所需的额外依赖(参考节点的README文档)。
问题7:多语言生成效果差异大,非英语语种生成质量低
解决方案:
优先使用项目原生支持的语种(中英日韩西),避免使用未支持的语种;
优化非英语语种的歌词和标签,贴合该语言的韵律特点(比如中文歌词注意平仄和押韵);
针对目标语种,收集少量数据进行微调,提升生成质量;
等待官方发布更多语种的优化版本。
问题8:推理速度慢,RTF≈1.0(生成1分钟音乐需要1分钟)
解决方案:
等待官方发布推理加速、流式推理脚本(项目TODO中已规划);
使用更高性能的GPU(如RTX 4090、A100),提升推理速度;
优化模型推理参数(如
max_new_tokens,减少生成的token数量);采用模型量化技术(如INT8量化),降低计算量,提升速度。
七、相关链接
GitHub项目仓库:https://github.com/HeartMuLa/heartlib
Hugging Face模型主页:
ModelScope模型主页:
官方论文(arXiv):https://arxiv.org/abs/2601.10547
八、总结
HeartMuLa作为首个能在学术级资源下复现Suno级商业效果的开源多语言音乐基础模型项目,凭借全链路的音乐AI能力、强化学习优化的极致可控性、原生多语言支持和开源友好的生态,彻底打破了AI音乐领域的技术壁垒。它不仅为开发者提供了开箱即用的音乐生成工具,为研究者提供了高质量的基线模型,也为普通用户打开了零基础音乐创作的大门。
从音乐创作到内容配乐,从语言教育到娱乐互动,HeartMuLa的应用场景覆盖广泛,其模块化设计和开源特性,也为音乐AI的二次开发和创新提供了无限可能。在闭源产品主导的AI音乐市场中,HeartMuLa的出现,让音乐生成技术真正走向普惠,推动了整个音乐AI领域的发展与进步。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/heartmula.html





