Khala:中央音乐学院与清华大学联合开源的端到端AI歌曲生成模型
一、Khala是什么
Khala 是由中央音乐学院与清华大学联合团队研发、基于统一声学令牌架构打造的开源端到端AI歌曲生成模型,该项目主打全流程完整歌曲生成能力,区别于市面上多数仅能制作伴奏、短音频片段或人声哼唱的AI音乐工具,可依托文本指令、歌词内容直接生成带完整人声、编曲、旋律的成品歌曲。
项目采用 Python 语言开发,配套学术论文同步发布于 arXiv,核心技术围绕声学令牌、残差矢量量化、两阶段生成架构设计,兼顾生成音质、歌曲结构完整性与自定义能力。开源协议为 CC BY-NC 4.0,明确限定仅用于非商业用途、个人学习与学术研究,禁止任何形式的商业落地、二次售卖及商用服务搭建。

二、功能特色
Khala 聚焦完整歌曲生成核心场景,针对传统AI音乐存在的音质差、段落断裂、人声失真、风格单一等痛点进行优化,核心功能与特色分为以下几类:
2.1 核心生成功能
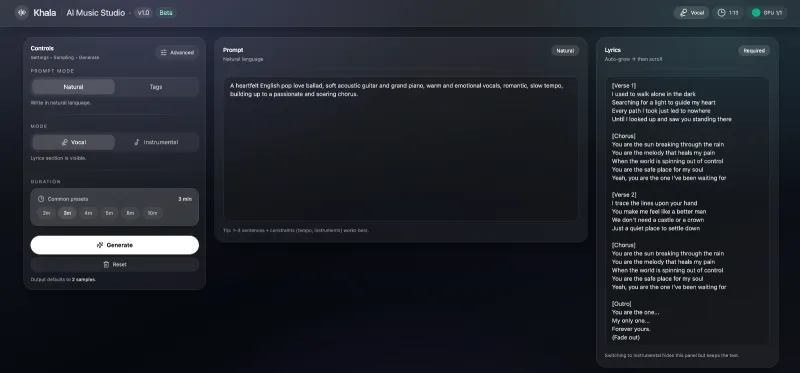
文本驱动歌曲生成:支持使用自然语言描述音乐风格、曲风、情绪、节奏、乐器组合,系统自动匹配对应的旋律、编曲与人声,无需专业乐理知识。
歌词定向作曲:导入自定义歌词后,模型自动匹配押韵、节奏与人声唱腔,生成词曲结合的完整演唱歌曲,适配原创填词、词曲创作需求。
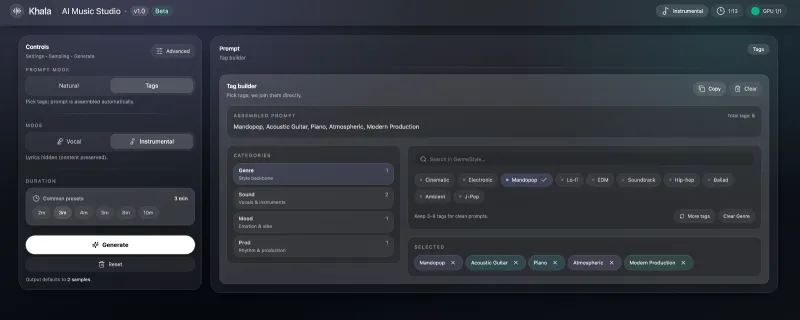
全维度风格自定义:覆盖流行、古风、民谣、摇滚、电子等主流曲风,同时可调节歌曲情绪(欢快、伤感、抒情、激昂)、人声音色、歌曲时长与段落结构。
2.2 工程化配套能力
完整前后端架构:项目内置可视化前端交互界面 + FastAPI 后端服务,普通用户可通过页面可视化操作,开发者可调用接口实现二次开发。
单卡GPU轻量化推理:优化模型推理逻辑,主流消费级独立显卡即可完成本地部署与推理,无需超高算力集群,降低个人使用门槛。
音频高保真输出:依托多层声学令牌还原细节,减少传统AI音乐常见的杂音、断音、乐器混叠问题,输出音频清晰度、层次感大幅提升。
2.3 附加实用特性
原生段落连贯优化:针对主歌、副歌、桥段、间奏等歌曲标准结构做专项适配,生成作品段落衔接自然,无生硬割裂感。
开源可二次开发:完整开放源码、模型权重、训练脚本与推理代码,技术开发者可基于现有框架微调模型、新增曲风、优化交互逻辑。
三、技术细节
Khala 摒弃了传统AI音乐常用的语义令牌、纯扩散模型方案,独创统一声学令牌架构,整体技术链路分为音频编码、两级生成、音频解码三大模块,技术逻辑清晰且具备创新性。
3.1 核心基础:64层残差矢量量化(RVQ)声学令牌
blockquote
残差矢量量化(RVQ)是本项目音质保障的核心基础,项目设计64层层级化声学令牌,将原始音频波形从粗粒度到细粒度逐层拆解。
传统方案多采用单层令牌编码,容易丢失音频细节,造成人声模糊、乐器音色失真。Khala 通过 64 层 RVQ 对音频进行分层编码:
粗粒度令牌层:承载歌曲整体结构、主旋律、节奏框架、段落划分等宏观信息;
细粒度令牌层:补充人声细节、乐器泛音、混响、动态强弱等音频微观细节。
分层设计实现了音乐结构与音频细节解耦,既保证整首歌曲框架稳定,又最大程度保留原声质感,从编码环节降低音质损耗。
3.2 整体架构:两阶段令牌生成流程
项目采用两阶段串行生成逻辑,分工明确,大幅提升成品完整性,整体流程代码逻辑示意如下:
# 伪代码:Khala 两阶段生成核心流程 # 阶段1:主干模型生成粗粒度声学令牌 coarse_tokens = backbone_model(text_prompt, lyrics, style_config) # 阶段2:超分模型补全细粒度声学令牌 full_tokens = super_res_model(coarse_tokens) # 最终解码:令牌还原为完整音频波形 audio_wave = decoder(full_tokens)
第一阶段:主干模型生成粗粒度令牌
输入文本描述、歌词、风格参数后,主干大模型优先生成整首歌曲的粗粒度声学令牌。该阶段重点把控歌曲整体架构,确定旋律走向、段落顺序、节拍速度、基础编曲,规避歌曲结构混乱、时长失控等问题。第二阶段:超分模型补充细粒度令牌
以第一阶段输出的粗粒度令牌为基础,超分模型逐层填充64层RVQ中的精细令牌,补全人声咬字、乐器音色、音频动态等细节,完成全层级声学令牌组合。
3.3 解码与输出模块
全层级声学令牌输入解码器后,直接还原为标准音频波形文件。解码器针对音乐场景做专项优化,优化了令牌转音频过程中的噪声抑制、频段平衡,有效解决同类开源项目普遍存在的金属杂音、底噪过大问题。
3.4 运行环境技术参数
开发语言:Python 3.9+
后端框架:FastAPI
推理依赖:PyTorch、Librosa、SoundFile 等音频处理库
硬件要求:支持单张消费级 GPU(显存 ≥8GB),支持本地离线推理
模型形态:权重文件开源,支持本地加载,无强制联网调用接口限制
四、应用场景
Khala 凭借完整歌曲生成、低部署门槛、开源免费(非商用) 的特性,适配个人创作、学习研究、内容制作等多类场景,具体分类如下:
个人原创音乐创作
独立音乐人、音乐爱好者可借助文本+歌词快速完成词曲创作,降低编曲、作曲门槛,快速产出原创歌曲小样、Demo作品。自媒体内容配乐
短视频、播客、图文自媒体创作者,可根据内容风格生成定制化原创人声歌曲、背景音乐,规避版权音乐侵权风险。音乐教学与学术研究
音乐专业院校、科研机构可用于AI音乐技术教学、声学模型、音乐生成算法相关课题研究;学生可借助项目理解音频编码、矢量量化、大模型音乐生成原理。歌词填词创作
作词爱好者、校园文艺创作群体,导入原创歌词即可自动谱曲演唱,快速实现“写词即出歌”。技术二次开发与模型微调
AI开发者、算法工程师可基于开源源码进行二次开发,例如新增方言人声、小众曲风、定制化交互界面,搭建个性化AI音乐工具。
注:依据项目开源协议,以上场景仅限非商业使用,广告营销、付费服务、商业产品内嵌等商用行为均被禁止。
五、使用方法
Khala 提供可视化前端使用和代码命令行使用两种方式,以下为本地部署+基础使用完整步骤,操作适配普通用户与开发者。
5.1 前置准备
硬件:电脑配备 NVIDIA 独立显卡,显存不低于 8GB;
软件:安装 Python 3.9 及以上版本、Git、CUDA 运行环境;
资源:从官方仓库拉取源码,下载配套模型权重文件。
5.2 步骤1:拉取项目源码
打开终端,执行以下命令克隆 GitHub 仓库代码:
git clone https://github.com/Khala-Music-AI/Khala.git cd Khala
5.3 步骤2:安装项目依赖
使用 pip 批量安装所需依赖库:
pip install -r requirements.txt
5.4 步骤3:启动后端与前端服务
启动 FastAPI 后端服务;
运行前端启动脚本,自动唤起本地可视化网页界面。
5.5 步骤4:页面内生成歌曲
在文本输入框填写风格、情绪、曲风等描述指令;
可选上传/输入自定义歌词文本;
调整歌曲时长、人声音色、节奏速度等参数;
点击生成按钮,等待推理完成后,直接播放或导出音频文件。
5.6 进阶:命令行推理(开发者使用)
熟悉代码的用户可直接调用推理脚本,通过命令行传入参数生成音频,适合批量生成、自动化流程对接。
六、竞品对比
选取目前主流的两款AI音乐生成产品(开源项目+商业化工具)与 Khala 进行多维度对比,从核心能力、部署方式、音质、开源属性、使用限制等维度区分差异。
| 对比维度 | Khala | 主流开源AI音乐项目A | 商业化AI歌曲工具B |
|---|---|---|---|
| 产品定位 | 开源高保真完整AI歌曲生成系统 | 开源AI伴奏/短旋律生成工具 | 云端商用AI歌曲生成平台 |
| 核心能力 | 文本/歌词生成完整人声歌曲,全段落连贯 | 主打伴奏、纯音乐、15s内短音频,无人声优化 | 完整歌曲生成,人声成熟,功能丰富 |
| 开源状态 | 完全开源,源码+权重开放 | 开源代码,部分高端模型权重闭源 | 闭源,仅提供云端接口/网页使用 |
| 部署方式 | 本地单卡GPU部署,离线运行 | 本地部署,算力要求中等 | 仅云端在线使用,无法本地部署 |
| 音质表现 | 高保真,段落衔接自然,杂音少 | 中等音质,长音频易出现断音、混叠 | 商用级高音质,稳定性最强 |
| 使用协议 | CC BY-NC 4.0,禁止商用 | 宽松开源协议,部分允许商用 | 付费制,商用需购买对应套餐 |
| 技术架构 | 64层RVQ声学令牌+两阶段生成 | 传统扩散模型+语义令牌 | 自研闭源大模型架构 |
总结差异:Khala 核心优势在于开源可本地部署、完整人声歌曲生成、音频细节优化出色;对比纯开源工具,它补齐了人声与长歌曲短板;对比商业云端工具,它拥有本地离线、免费非商用、可二次开发的优势,缺点是商业化功能与稳定性略低于付费平台。
七、常见问题解答
1. Khala 可以用来做商业用途吗?
不可以。项目开源协议为 CC BY-NC 4.0,明确规定所有内容、源码、生成音频均仅限个人学习、非商业创作与学术研究,禁止用于付费服务、商业宣传、产品售卖、商业自媒体盈利等任何商用场景。
2. 没有独立显卡可以运行 Khala 吗?
不建议使用纯CPU运行。该模型推理对算力要求较高,纯CPU环境下生成速度极慢,甚至会出现运行失败、内存溢出问题,官方推荐使用显存8GB及以上的NVIDIA独立显卡。
3. 生成的歌曲出现杂音、人声模糊该如何解决?
首先检查模型权重是否完整下载,权重缺失会直接导致音频失真;其次降低同时运行的软件数量,释放显卡显存;最后简化文本描述指令,过于复杂的风格混搭会增加模型生成难度,容易产生杂音。
4. 支持自定义人声音色、方言演唱吗?
原生版本仅支持默认标准人声音色,暂未内置方言演唱模型。由于项目开源,技术开发者可基于源码和数据集,自行训练方言、特殊音色模型进行拓展。
5. 生成的歌曲有版权吗?
基于Khala生成的音频作品,在遵守非商用协议的前提下,个人可自由使用;但模型本身、项目源码版权归研发团队所有,不得将生成内容打包为版权素材库进行售卖。
6. 部署时提示依赖库安装失败怎么办?
首先核对Python版本是否为3.9及以上,版本不匹配是主要原因;其次切换国内pip镜像源重新安装依赖;若存在CUDA报错,需匹配与PyTorch版本对应的CUDA运行环境。
八、相关链接
GitHub仓库地址:https://github.com/Khala-Music-AI/Khala
学术论文(arXiv):https://arxiv.org/abs/2605.01790
HuggingFace模型库:https://huggingface.co/liujiafeng/Khala-MusicGeneration-v1.0
九、总结
Khala 是一款由国内高校联合研发、技术特色鲜明的开源AI歌曲生成模型,依托64层残差矢量量化声学令牌与两阶段生成架构,解决了传统开源AI音乐工具长音频生成、人声还原、段落衔接、音质损耗等核心痛点,实现了通过文本和歌词快速生成完整高保真歌曲的能力。项目配备完整的前后端工程,降低了本地部署与上手难度,同时完全开放源码与模型权重,既满足音乐爱好者零基础创作歌曲的需求,也为AI算法研究者、二次开发者提供了优质的实践框架。受开源协议限制,该项目仅适用于非商业场景,是目前国内开源领域中综合实力突出的端到端AI音乐生成项目,在个人音乐创作、学术研究、技术学习等场景中具备很高的实用价值。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/khala.html