Kimi K2.7 Code:Moonshot AI(月之暗面)开源的工程级编程大模型
一、Kimi K2.7 Code 是什么
Kimi K2.7 Code 是 Moonshot AI(月之暗面) 发布的 K2 系列新一代编程专属 MoE 混合专家大模型,定位为工程级代码智能体(Code Agent),是在前代 K2.6 Code 基础上完成全面性能、推理效率、指令遵循能力升级的正式版本。
该模型主打长上下文编程、全编程语言适配、端到端项目自动化开发两大核心方向,区别于通用大模型,它针对代码语法、工程逻辑、项目架构、报错排错、脚本开发等场景做了专项数据训练与算法优化。模型采用开源协议分发,开发者可免费获取权重进行本地部署、二次开发、私有化部署,同时原生集成智能体调用能力,可直接对接 IDE、命令行工具、自动化运维平台,实现“AI 自主完成整套软件工程任务”。
从产品定位划分:
不属于轻量化代码小模型,属于万亿级参数工程级编程大模型;
不局限于单段代码生成,主打多文件、长项目、跨模块复杂工程开发;
自带视觉编码能力,支持图文结合的编程场景(如根据流程图、架构图编写代码)。

二、功能特色
Kimi K2.7 Code 围绕开发者全工作流进行能力设计,覆盖代码编写、调试、重构、运维、文档生成等全场景,核心功能分为七大板块,所有特色均经过基准测试验证,实用性突出。
2.1 全品类编程语言全覆盖
支持当下主流开发语言、脚本语言、数据库语言、底层编译语言,无语言适配短板:
后端语言:Python、Go、Java、Rust、C/C++、PHP、Ruby
前端语言:JavaScript、TypeScript、Vue/React 框架代码、HTML/CSS
脚本&运维语言:Shell、Batch、PowerShell、YAML、Dockerfile、K8s 配置清单
数据&数据库:SQL、MySQL、PostgreSQL、MongoDB 脚本、数据清洗代码
嵌入式&硬件:单片机代码、物联网控制脚本
模型可完成单函数编写、完整业务模块开发、框架项目搭建,对各类语言的语法规范、编码规范、行业最佳实践均有深度理解。
2.2 超长上下文窗口,适配大型项目开发
上下文窗口最高支持 262K Token,可一次性读取整个代码仓库、数十个关联文件、完整项目架构文档与需求文档。开发者无需拆分文件、分段提问,能够实现整仓级代码分析、跨文件逻辑重构、大型项目漏洞排查,彻底解决传统代码模型“短上下文无法处理复杂项目”的痛点。
2.3 推理效率大幅优化,降低使用成本
相较于前代 K2.6 Code,Kimi K2.7 Code 完成推理逻辑重构:
整体推理 Token 消耗**降低 30%**,简单代码任务自动精简冗余思考内容;
长任务、多轮对话场景下响应速度提升,云端调用、本地推理的资源占用显著下降;
自适应推理策略,区分简单代码片段与复杂工程任务,动态调整思考深度,兼顾速度与准确率。
2.4 专业代码调试与错误修复能力
内置海量报错案例、运行日志、异常堆栈训练数据,支持:
单行/整块代码语法错误、逻辑错误一键定位并修复;
解析程序崩溃日志、接口异常、性能瓶颈,输出优化方案;
针对内存泄漏、死循环、并发冲突、接口超时等工程常见问题给出专业解决方案;
自动编写单元测试用例、压力测试脚本,验证修复后代码的稳定性。
2.5 原生 Code Agent 智能体能力
模型原生支持结构化输出、循环工具调用、文件读写、终端指令联动,是标准的编程智能体:
可输出标准 JSON 格式指令,对接第三方工具链;
自主规划开发步骤,拆分复杂需求为多个子任务,分步执行编码;
配合官方 CLI 工具、IDE 插件,实现自动创建文件、写入代码、运行脚本、查看运行结果的全自动化流程;
支持多轮自主迭代,发现代码问题后自动回滚、修改、重新测试,无需人工反复干预。
2.6 图文协同编码能力
集成 MoonViT 视觉编码器,实现图文联动编程:
识别架构图、流程图、原型图、手绘逻辑图,根据视觉内容转换成对应代码;
解析截图中的报错界面、代码界面,快速定位问题;
结合图文需求文档,精准还原业务逻辑,降低沟通成本。
2.7 代码重构、优化与文档生成
代码重构:对老旧项目、杂乱代码进行规范化重构,统一编码风格、优化代码结构、降低耦合度;
性能优化:针对高并发、大数据场景优化代码执行效率,减少资源占用;
文档自动化:自动生成接口文档、代码注释、项目说明文档、部署手册,符合行业通用文档规范。
重点说明:该模型强制开启思考模式,无纯直出模式,所有代码输出都会附带逻辑思考过程,便于开发者理解编码思路,适合学习与二次修改。

三、技术细节
Kimi K2.7 Code 采用业界主流的 MoE 混合专家模型架构,结合专项代码训练数据集、视觉编码模块与推理优化算法,以下为完整技术参数、架构设计与训练细节,内容通俗易懂,兼顾技术人员与入门开发者阅读。
3.1 核心模型基础参数
下表为模型硬件与架构核心参数,是区分该模型与轻量化代码模型的关键依据:
| 参数类别 | 具体规格 |
|---|---|
| 模型架构 | MoE 混合专家大模型 |
| 总参数量 | 1 万亿(1T)参数 |
| 单次激活参数 | 320 亿(32B)参数 |
| 网络总层数 | 61 层(含 1 层共享全连接层) |
| 专家模块总数 | 384 个独立专家 |
| 单次推理激活专家 | 固定 8 个专家 |
| 最大上下文窗口 | 262K Token |
| 多模态模块 | 内置 MoonViT 视觉编码器 |
| 运行模式 | 强制思考模式,无纯输出模式 |
| 开源协议 | Modified MIT 协议 |
3.2 MoE 混合专家架构原理
混合专家(MoE)是当前万亿级大模型主流架构,Kimi K2.7 Code 采用该架构的核心目的是兼顾超大参数量能力与推理效率:
模型整体拥有 384 个独立专家网络,每个专家擅长不同领域的代码任务(如前端编码、底层算法、运维脚本、数据库开发等);
每一次用户请求,模型路由算法会自动筛选出8 个最匹配当前任务的专家参与推理,其余专家处于休眠状态;
单次推理仅激活 32B 参数,相比全量 1T 参数推理,算力、内存、显存占用大幅降低,让万亿级大模型可以在中高端服务器、本地显卡中运行。
该架构完美适配代码场景:不同编程语言、不同工程类型的任务可以分配给对应专精专家,代码理解与生成精度远高于同体量稠密模型。
3.3 视觉编码模块(MoonViT)
MoonViT 是 Moonshot AI 自研视觉编码器,和主模型深度融合,并非外挂独立模块:
支持图片、截图、图表等视觉内容解析,将视觉信息转化为文本语义,供编码模块调用;
图文信息融合精度高,不会出现“图文脱节”问题,适合根据架构图、流程图开发项目;
视觉模块轻量化设计,开启图文模式后,不会大幅增加推理延迟。
3.4 训练与优化细节
训练数据集:以全球开源代码仓库、工业级工程项目、运维脚本、算法代码为核心训练数据,覆盖数十年各类编程语言的优质代码样本,同时补充海量报错日志、调试案例、工程架构文档。
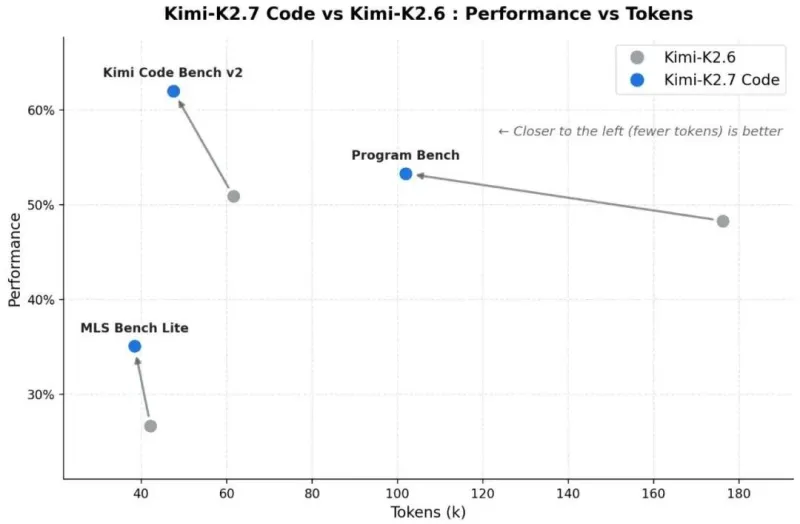
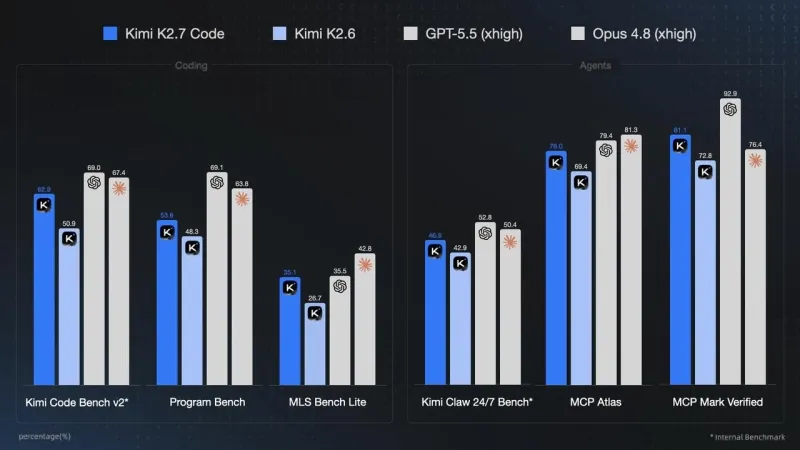
专项基准优化:针对三大主流代码基准做定向调优:
Kimi Code Bench v2:得分从 50.9 提升至 62.0,涨幅 21.8%;
Program Bench:得分从 48.3 提升至 53.6,涨幅 11.0%;
MLS Bench Lite:得分从 26.7 提升至 35.1,涨幅 31.5%。
推理层优化:重构自适应推理引擎,对简单代码片段、复杂工程任务做分层处理,减少无效思考 Token,整体推理成本下降 30%。
长上下文优化:优化注意力机制,在 262K 超长 Token 范围内,指令遵循、逻辑连贯性无明显衰减,保证整仓代码分析的准确性。
3.5 开源与权限说明
模型采用 Modified MIT 开源协议:
个人开发者:免费下载、本地部署、使用、二次微调,无商用限制;
企业团队:可私有化部署、集成至内部平台、二次开发后商用;
模型权重托管于 Hugging Face 平台,公开可下载,无加密、无使用门槛。
四、应用场景
Kimi K2.7 Code 能力覆盖个人开发、企业研发、运维自动化、AI 工具开发等多个领域,根据使用主体可分为六大核心场景,覆盖从入门开发者到大型技术团队的全需求。
4.1 个人开发者日常编码
快速生成业务代码、工具脚本、算法代码,提升开发效率;
学习编程:借助模型思考过程理解代码逻辑、语法规则;
个人项目开发:独立完成小型网站、桌面程序、爬虫、数据分析项目的全流程编码;
代码改写:优化个人旧项目,重构代码结构。
4.2 企业研发团队工程开发
中大型项目多文件协同开发,读取整个代码仓库,统一规划模块逻辑;
跨模块代码审查、漏洞检测、逻辑梳理,降低团队沟通成本;
新项目架构搭建、框架选型、基础代码脚手架生成;
老旧系统迭代、技术栈迁移、代码批量改造。
4.3 运维与 DevOps 自动化
编写 Shell、Docker、K8s、CI/CD 流水线脚本;
服务器监控脚本、日志分析脚本、故障自动排查脚本开发;
云服务、容器集群的配置文件编写与优化;
运维流程自动化工具开发,实现无人值守运维。
4.4 代码调试、排错与性能优化
解析程序崩溃日志、异常堆栈、接口报错,定位根因并修复;
对高并发、大数据程序做性能调优,解决卡顿、内存溢出等问题;
批量修复项目中的潜在 Bug、安全漏洞。
4.5 AI 工具与插件二次开发
基于模型原生 Agent 能力,开发第三方工具:
IDE 智能编码插件(VS Code、IDEA 等);
云端在线代码平台、AI 编程机器人;
自动化测试工具、代码文档生成工具。
4.6 教育培训与技术文档
编程教学场景:生成示例代码、练习题、讲解案例;
自动生成代码注释、项目说明、接口文档、部署手册;
技术团队知识库内容整理,代码案例标准化。
五、使用方法
Kimi K2.7 Code 提供云端调用、本地权重部署、官方工具链对接三种主流使用方式,操作流程清晰,兼顾新手与专业运维人员,以下分步讲解完整使用流程。
5.1 前置准备
硬件要求
本地部署:推荐高端显卡(显存 ≥ 48G)或多卡服务器;纯 CPU 可运行,但推理速度极慢,不推荐;
云端调用:无需本地硬件,仅需网络环境。
环境依赖:Python 运行环境、主流大模型部署框架(Transformers、vLLM、Text Generation Inference 等)。
5.2 方式一:Hugging Face 权重本地部署(主流方式)
下载模型权重
访问官方 Hugging Face 仓库,拉取完整模型文件,可使用 Git 或网页下载:
git clone https://huggingface.co/moonshotai/Kimi-K2.7-Code
安装依赖库
执行命令安装运行所需依赖:
pip install torch transformers accelerate vllm sentencepiece
基础调用代码示例
编写简单 Python 脚本加载模型并发起代码请求:
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载分词器与模型
model_path = "./Kimi-K2.7-Code"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
trust_remote_code=True
)
# 构造提问:生成Python冒泡排序代码
prompt = "请使用Python编写冒泡排序算法,并添加详细注释"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 推理生成
outputs = model.generate(**inputs, max_new_tokens=2048)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)运行脚本,即可获取模型输出的代码与思考过程。
5.3 方式二:使用官方 Kimi Code CLI 命令行工具
官方配套 CLI 工具,专为批量代码任务、运维场景设计:
下载并安装 Kimi Code CLI;
终端输入指令,直接对本地文件、代码仓库进行分析、改写、调试;
支持批量处理多文件,适合运维与项目批量改造场景。
5.4 方式三:对接 IDE 插件使用
Moonshot AI 提供官方 IDE 插件,适配 VS Code、JetBrains 系列编辑器:
在插件市场搜索「Kimi Code」完成安装;
配置模型接口(本地部署接口或云端接口);
在编辑器内选中代码、输入需求,即可实时生成、修改、调试代码,和日常编码无缝结合。
5.5 关键使用注意事项
模型强制开启思考模式,无法关闭,输出内容会包含推理逻辑;
处理大型项目文件时,建议启用 262K 完整上下文窗口;
本地部署建议使用 vLLM 推理框架,可大幅提升生成速度。
六、竞品对比
选取目前市场上三款主流专业代码大模型:DeepSeek-Code V2、CodeLlama 70B Instruct 与 Kimi K2.7 Code 做横向对比,从架构、参数、上下文、能力、开源协议、适用场景六个维度分析,客观展示产品差异。
| 对比维度 | Kimi K2.7 Code | DeepSeek-Code V2 | CodeLlama 70B Instruct |
|---|---|---|---|
| 模型架构 | MoE 混合专家架构 | 稠密Transformer架构 | 稠密Transformer架构 |
| 参数量 | 总1T,单次激活32B | 67B 稠密参数 | 70B 稠密参数 |
| 最大上下文 | 262K Token | 128K Token | 100K Token |
| 多模态能力 | 支持MoonViT视觉编码,图文协同编程 | 纯文本代码模型,无视觉能力 | 纯文本代码模型,无视觉能力 |
| Code Agent智能体 | 原生支持,工具调用、文件读写能力完善 | 支持基础智能体,复杂任务联动较弱 | 仅基础指令执行,无原生Agent设计 |
| 推理效率 | Token消耗低30%,长任务性价比高 | 常规推理效率,长上下文资源占用高 | 推理速度中等,大项目延迟明显 |
| 开源协议 | Modified MIT,商用自由 | Apache 2.0,商用自由 | Llama 协议,企业商用有约束 |
| 核心优势 | 超长上下文、整仓开发、图文编码、工程级Agent | 中小型代码片段生成精度高、生态完善 | Meta官方模型,社区插件丰富 |
| 主要适用场景 | 大型项目、整仓重构、运维自动化、图文编程 | 日常编码、算法开发、小型项目 | 个人学习、基础编码、教学场景 |
对比总结:
在大型工程、多文件项目、长上下文场景中,Kimi K2.7 Code 优势明显,262K 上下文远超另外两款模型,是唯一适配整仓开发的产品;
多模态图文编码为独有能力,另外两款竞品均为纯文本模型;
开源协议层面,三款模型均可商用,但 CodeLlama 存在协议约束,Kimi K2.7 Code 与 DeepSeek-Code 限制更少;
轻量化、小型代码任务场景下,三款模型表现接近,DeepSeek-Code 社区生态更成熟;复杂工程自动化场景,优先选择 Kimi K2.7 Code。
七、常见问题解答(FAQ)
Q1:Kimi K2.7 Code 必须开启思考模式吗?可以关闭吗?
A:该模型为工程级代码智能体,底层设计强制开启思考模式,没有关闭思考、纯代码直出的模式。所有输出内容都会附带任务分析、编码思路、排错逻辑,虽然内容篇幅更长,但便于开发者理解代码背后的逻辑,也能提升复杂任务的准确率。
Q2:本地部署 Kimi K2.7 Code 对硬件要求高吗?普通家用显卡能否运行?
A:模型单次激活参数为32B,对显存要求较高。普通家用消费级显卡(显存16G及以下)无法流畅运行,会出现显存溢出、推理卡死等问题。建议使用显存48G及以上专业显卡、多卡集群或者云服务器部署;纯CPU模式可以加载,但推理速度极慢,仅适合测试,不建议正式使用。
Q3:Kimi K2.7 Code 支持二次微调吗?微调后能否商用?
A:模型基于 Modified MIT 协议开源,完全支持开发者基于自有代码数据集进行二次微调。微调后的模型无论是个人使用还是企业商用,都在协议允许范围内,无需额外授权。
Q4:模型的262K Token 上下文窗口具体能容纳多少代码?
A:按照常规代码折算,1K Token 大约对应 700~800 行标准代码,262K Token 可容纳十几万行代码,足以加载一整个中小型代码仓库、数十个关联业务文件,满足绝大多数企业级项目整仓分析与重构需求。
Q5:该模型可以对接 VS Code、IDEA 等主流编辑器吗?
A:可以。官方推出了配套 IDE 插件,同时模型支持标准 API 接口调用,第三方开发者也可基于开放接口开发自定义插件,能够无缝对接市面上主流代码编辑器、集成开发环境。
Q6:Kimi K2.7 Code 和前代 K2.6 Code 核心区别在哪里?
A:主要有四点升级:一是代码基准得分全面提升,各类代码任务准确率大幅上涨;二是推理 Token 消耗降低30%,使用成本更低;三是 Code Agent 智能体能力增强,多轮自动化任务成功率更高;四是长上下文的指令遵循与逻辑连贯性进一步优化,大型项目处理更稳定。
Q7:模型支持中文需求提问吗?对中文编程指令理解是否准确?
A:模型深度适配中英文双语指令,针对中文技术需求、中文注释、中文文档做了专项训练。使用中文描述开发需求、排错要求、优化方向,模型都可以精准理解,国内开发者可直接使用中文交互。
八、总结
Kimi K2.7 Code 是 Moonshot AI 打造的一款面向工程级场景的开源混合专家编程大模型,依托万亿级总参数量、32B 动态激活参数与 262K 超大上下文窗口,实现了全编程语言适配、整仓级项目开发、代码调试优化、图文协同编程以及原生智能体自动化执行等多项能力,同时在推理效率、基准得分上完成了对前代版本的全面升级。模型采用宽松的 Modified MIT 开源协议,个人开发者与企业团队均可免费部署、二次开发并商用,搭配官方 CLI 工具与 IDE 插件可融入现有开发工作流。对比同类型主流代码大模型,它在长上下文处理、多模态编码、工程级智能体能力上具备显著优势,既能够满足个人日常编码、编程学习的基础需求,也可支撑中大型企业的项目开发、运维自动化、老旧系统迭代等复杂工程场景,是目前综合能力突出的开源专业编程大模型之一。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/kimi-k2-7-code.html





