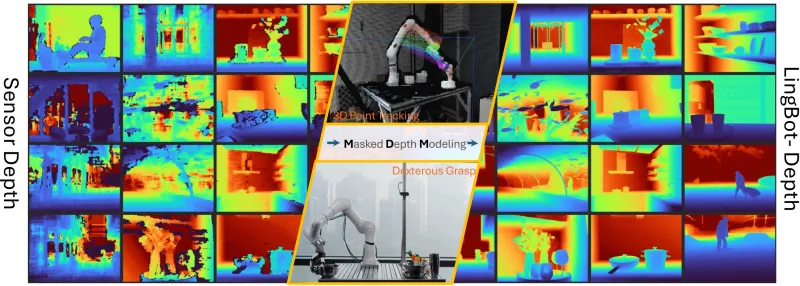
LingBot-Depth:蚂蚁灵波推出的开源高精度深度视觉模型,赋能机器人与3D视觉场景
一、LingBot-Depth是什么
LingBot-Depth是由蚂蚁集团旗下具身智能公司蚂蚁灵波科技(Robbyant)自主研发并开源的高精度空间感知项目,基于Python语言开发,核心聚焦于掩码深度建模(Masked Depth Modeling, MDM) 技术,是一款专为真实应用场景设计的深度视觉模型框架。简单来说,它就像是给消费级RGB-D相机(一种同时采集彩色图像和深度数据的设备)装上了“智能修图师”和“空间感知大脑”,无需更换昂贵的高端硬件,就能轻松解决传统深度相机在复杂场景下的感知缺陷,将原本不完整、带噪声、精度低的原始深度数据,转化为高保真、度量精确、细节丰富的3D几何测量结果,为机器人学习、3D视觉等领域提供核心的空间感知能力支撑。
在当下的智能设备与机器人落地场景中,“看清世界、准确定位”是核心前提——小到机器人抬手抓取一杯水,大到工业场景中的工件定位、文物数字化重建,都需要设备能够精准感知周围环境的3D空间关系,判断物体的位置、距离、形态。但传统的深度感知方案存在一个致命短板:消费级RGB-D相机在面对透明物体(如玻璃杯)、反光物体(如不锈钢杯)、低纹理表面(如光滑墙面)时,很容易出现深度数据缺失、噪声严重、精度失真等问题;而高端深度相机不仅成本高昂,还难以实现规模化普及。这一痛点严重制约了机器人、3D视觉等领域的落地进度,成为行业发展的“绊脚石”。
LingBot-Depth的诞生,正是为了破解这一行业困境。它以“算法创新弥补硬件短板”为核心理念,通过创新的MDM范式,让模型学会“利用缺陷、转化优势”——将传感器天然产生的深度缺失区域作为“原生掩码”,而非简单视为噪声,再结合RGB图像中的视觉上下文信息(如物体边缘的折射畸变、反光表面的环境倒影、阴影轮廓等),智能推断并补全缺失的深度信息,最终实现高精度的3D空间感知。
作为一个完全开源的项目,LingBot-Depth不仅开放了全部核心代码、训练脚本、推理工具,还提供了针对不同场景优化的预训练模型(可直接从Hugging Face、ModelScope获取),同时配套了详细的技术报告、论文、使用教程,降低了开发者的使用门槛。无论是科研人员用于3D视觉领域的技术研究,还是企业开发者用于机器人、工业检测等场景的落地开发,都能通过该项目快速实现相关功能,无需从零搭建深度建模框架。
与传统的深度建模项目相比,LingBot-Depth具有三大核心优势:一是高精度与高鲁棒性,在透明、反光等极端复杂场景下,仍能保持优异的深度感知性能,在多个权威基准测试中全面超越当前主流模型;二是低成本易落地,无需更换高端硬件,仅通过算法优化,就能让普通消费级RGB-D相机达到接近专业级的深度感知效果;三是泛化能力强,支持单目深度估计、深度补全、场景重建等多种任务,适配机器人、3D视觉、工业等多个领域的多样化需求。
截至目前,LingBot-Depth已通过奥比中光深度视觉实验室的专项评测认证,在测量精度、运行稳定性及复杂光照/纹理场景下的泛化适应性等方面,均达到行业领先水准,其相关技术已在真实机器人平台上完成验证,展现出极强的实用价值与行业影响力。

二、功能特色
LingBot-Depth围绕3D空间感知核心需求,结合掩码深度建模(MDM)技术的创新优势,打造了一系列贴合真实应用场景的功能,涵盖深度补全、单目深度估计、场景重建等多个维度,每个功能都经过真实场景测试与优化,兼具高精度、高鲁棒性与易用性,具体功能特色如下:
2.1 核心功能详解
(1)深度补全与精细化处理
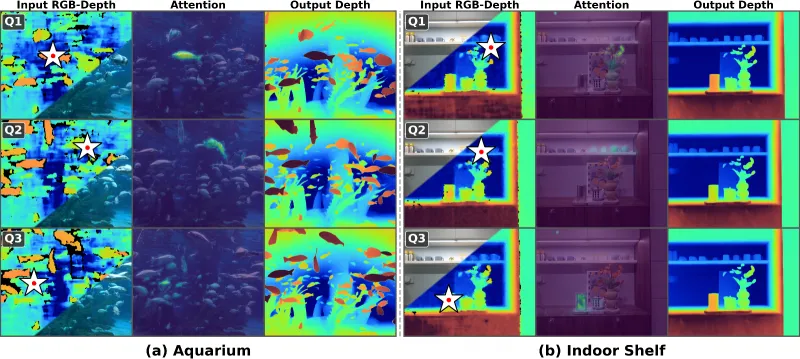
这是LingBot-Depth最核心的功能之一,主要解决消费级RGB-D相机采集的深度数据“不完整、带噪声、精度低”的痛点。传统深度相机在面对透明、反光、低纹理物体,或是弱光、遮挡等复杂场景时,很容易出现深度数据缺失(形成“空洞”)、像素噪声过大、边缘模糊等问题,导致后续的3D建模、机器人抓取等任务无法正常开展。
LingBot-Depth的深度补全功能,通过创新的MDM范式,能够精准识别深度数据中的缺失区域和噪声区域,再结合RGB图像中的视觉上下文信息(如物体的轮廓、阴影、折射特征等),对缺失区域进行智能推断与填充,对噪声区域进行降噪处理,最终输出高精度、细节丰富、边缘清晰的深度图。与传统深度补全方法相比,该功能具有两大突出优势:一是针对性解决极端场景痛点,专门优化了透明、反光物体的深度补全效果,能够精准捕捉这类物体的形态与深度信息,打破了传统方法在这类场景下的性能瓶颈;二是精度领先,在最严苛的极端设定下(深度图大面积缺失并伴有严重噪声),其RMSE(均方根误差)指标比此前最好的方法降低了超过40%,在NYUv2、ETH3D等权威基准测试中,室内场景下的相对误差(REL)降幅超70%,表现远超当前主流模型。
此外,该功能还支持对深度图进行精细化优化,可根据实际需求调整深度精度、边缘锐度等参数,适配不同场景的使用需求——无论是需要高精度测量的工业场景,还是需要细节丰富的3D建模场景,都能通过该功能获得符合要求的深度数据。
(2)单目深度估计
LingBot-Depth创新实现了高精度单目深度估计功能,即无需依赖深度相机采集原始深度数据,仅通过一张普通的RGB彩色图像,就能凭借模型学到的3D几何先验知识,估算出图像中每个像素的深度信息,输出完整的深度图。这一功能极大地降低了3D空间感知的硬件门槛,让普通相机(如手机相机、普通工业相机)也能具备3D深度感知能力,无需额外配备昂贵的深度传感器。
该功能的核心优势在于泛化能力强、精度高。由于模型是在大规模RGB-D数据集(包含200万真实数据、100万仿真数据及开源数据,总计1000万规模)上训练而成,积累了丰富的3D几何知识,能够适应多种不同场景(室内、室外、办公、商场等)的单目深度估计需求,无论是普通物体、透明反光物体,还是低纹理场景,都能实现精准的深度估计。在10项单目深度估计基准测试中,其表现均优于当前主流的视觉模型DINOv2,充分验证了该功能的精度与可靠性。
单目深度估计功能的落地价值显著,能够广泛应用于无需配备深度相机的场景,如手机3D扫描、AR/VR场景搭建、机器人自主导航(无深度传感器场景)等,进一步拓展了项目的应用范围。
(3)3D场景重建
基于高精度的深度数据(无论是补全后的深度数据,还是单目估计的深度数据),LingBot-Depth能够快速实现3D场景重建功能,将2D的RGB图像和深度图,转化为高保真、具备真实物理尺度的3D场景模型。该功能支持室内、室外等多种场景的重建,能够精准还原场景中的物体形态、空间位置关系、细节纹理等信息,适用于文物数字化、虚拟场景搭建、室内设计、机器人场景探索等多个领域。
与传统3D场景重建工具相比,该功能具有三大优势:一是精度高,依托高精度的深度数据支撑,重建的3D模型能够精准还原物体的真实尺寸与空间关系,无明显畸变;二是速度快,优化了重建算法,能够快速处理图像数据,无需长时间等待,适配实时重建场景需求;三是适配复杂场景,能够完美还原透明、反光物体在3D场景中的形态,解决了传统重建工具在这类物体上的还原精度不足问题。例如,在文物数字化场景中,可通过该功能精准重建透明文物(如玻璃器、玉器)的3D模型,完整保留文物的细节纹理与形态特征,为文物保护与研究提供有力支撑。
(4)4D点追踪
LingBot-Depth具备强大的4D点追踪功能,能够在动态场景中,精准追踪场景中每个点的3D位置变化(即3D空间位置+时间维度,合称4D),输出平滑、稳定的点云轨迹。该功能主要针对机器人自主导航、动态场景分析等需求设计,能够帮助机器人精准感知周围动态物体的运动轨迹,避免碰撞,同时也能为动态场景分析(如人流统计、物体运动轨迹分析)提供核心数据支撑。
该功能的突出优势在于时空一致性优异。尽管模型是在静态图像上训练的,但在视频序列上展现出了惊人的时空一致性——在包含玻璃大门、镜子、玻璃的健身房、海洋馆隧道等动态场景的视频中,其输出的深度流不仅填补了原始传感器的大片空洞,而且在整个视频过程中保持平滑、稳定,没有任何闪烁或跳变,能够精准追踪动态物体的运动轨迹,为机器人动态避障、灵巧操作等任务提供可靠支撑。
(5)机器人灵巧操作支撑
LingBot-Depth专门针对机器人领域的需求,优化了灵巧操作支撑功能,能够为机器人的抓取、搬运、装配等灵巧操作提供高精度的空间感知支撑,显著提升机器人操作的成功率。在真实机器人测试中,该项目已被部署到由节卡(Rokae)XMate-SR5机械臂、X Hand-1灵巧手和奥比中光Gemini 330系列深度相机组成的系统中,用于抓取一系列对深度感知极具挑战的物体(不锈钢杯、透明玻璃杯、透明收纳盒、玩具车)。
测试结果显示,使用LingBot-Depth后,机器人的抓取成功率得到了显著提升:透明收纳箱的抓取成功率从0%提升至50%,在多种反光和透明物体上的抓取成功率提升了30%~78%,彻底解决了传统机器人在这类物体抓取上“看不清、抓不准”的痛点。这一功能的核心价值在于,能够帮助机器人精准感知物体的3D形态、空间位置、表面特征(如透明、反光),从而调整抓取姿态与力度,实现稳定、精准的抓取操作,为服务机器人、工业机器人的规模化落地提供有力支撑。
2.2 与同类主流项目对比
为了让大家更清晰地了解LingBot-Depth的功能优势,以下是LingBot-Depth与当前主流开源深度补全/3D感知项目的功能与性能对比表,选取了OMNI-DC、PromptDA、PriorDA三款行业主流项目作为对比对象,从核心功能、场景适配、精度表现、硬件依赖、易用性五个维度进行对比,直观展现LingBot-Depth的差异化优势:
| 项目名称 | 核心功能 | 场景适配能力 | 精度表现(极端场景RMSE降幅) | 硬件依赖 | 易用性 |
|---|---|---|---|---|---|
| LingBot-Depth | 深度补全、单目深度估计、3D场景重建、4D点追踪、机器人灵巧操作支撑 | 支持透明、反光、低纹理等极端场景,适配室内外多种场景 | >40% | 无需高端硬件,适配消费级RGB-D相机及普通相机 | 高,提供完整教程、预训练模型,Python接口简洁 |
| OMNI-DC | 深度补全 | 主要适配普通室内场景,对透明、反光场景适配较差 | <20% | 依赖中高端RGB-D相机 | 中等,教程较为简略,预训练模型较少 |
| PromptDA | 深度补全、单目深度估计 | 适配部分复杂场景,透明、反光场景表现一般 | <25% | 依赖高端RGB-D相机才能达到较好效果 | 中等,接口较为复杂,需手动调整大量参数 |
| PriorDA | 深度补全 | 适配室内场景,极端场景表现较差 | <15% | 依赖高端传感器 | 低,代码可读性差,缺乏详细教程 |
通过上表可以看出,LingBot-Depth在核心功能丰富度、极端场景适配能力、精度表现、硬件依赖门槛、易用性五个维度上,均全面优于当前主流同类项目,尤其是在透明、反光等极端场景的适配的精度表现上,具有不可替代的优势,同时无需高端硬件支撑,大大降低了项目的落地门槛。
2.3 其他特色功能
除了上述核心功能外,LingBot-Depth还具备一系列实用的辅助功能,进一步提升项目的易用性与实用性:
多设备适配:支持多种主流RGB-D相机(如奥比中光Gemini 330、Intel RealSense、ZED等),同时适配CPU、GPU运行环境,GPU环境下可实现推理加速,满足不同开发者的硬件条件需求;
灵活的参数配置:提供丰富的参数配置接口,开发者可根据实际需求,灵活调整模型推理精度、速度、深度补全阈值等参数,适配不同场景的使用需求;
完整的可视化工具:配套提供深度图、3D点云、场景重建结果的可视化工具,能够实时查看推理结果、训练进度,方便开发者调试与优化;
全链路开源:不仅开源核心代码、预训练模型,还计划开源300万规模的RGB-D数据集(包含200万真实数据、100万仿真数据),同时开放技术报告、论文,方便开发者深入研究与二次开发。
三、技术细节
LingBot-Depth之所以能够在精度、场景适配、易用性等方面表现突出,核心在于其创新的技术架构与优化策略。该项目以掩码深度建模(MDM) 范式为核心,结合视觉Transformer(ViT)架构、ConvStack卷积金字塔解码器等先进技术,同时依托大规模高质量数据集的训练,构建了高精度、高鲁棒性的深度感知模型。以下从核心技术、模型架构、训练策略、推理优化四个方面,详细解读LingBot-Depth的技术细节,尽量做到通俗易懂,避免过于晦涩的专业术语。
3.1 核心技术:掩码深度建模(MDM)范式
掩码深度建模(Masked Depth Modeling, MDM)是LingBot-Depth最核心的技术创新,也是其能够突破传统深度建模瓶颈、适配透明反光场景的关键。该技术灵感来源于今年大火的MAE(掩码自编码器),但针对深度建模的场景需求,进行了针对性优化,解决了MAE在深度建模中无法学习真实物理世界空间几何规律的局限性。
简单来说,MDM范式的核心思想是“化缺陷为优势”——将RGB-D传感器天然产生的深度缺失区域,视为一种“可学习的结构线索”,而非简单的噪声,让模型在训练过程中,主动利用这些“缺陷”来学习真实世界的空间几何规律,从而提升模型的深度感知能力。
具体来说,MDM范式的工作流程分为三个步骤:
掩码生成:在模型训练过程中,首先对输入的深度图进行掩码处理。与MAE中完全随机的掩码方式不同,MDM的掩码策略更加智能、贴合真实场景:优先使用传感器天然产生的缺失区域作为“原生掩码”(比如透明物体、反光物体对应的深度缺失区域);对于部分有效、部分无效的深度块,则以高概率(如75%)进行掩码;如果天然掩码不够,再补充一些随机掩码。这种掩码策略确保了模型始终在解决最困难、最真实的深度感知问题,从而提升模型在真实场景中的鲁棒性。
跨模态特征融合:模型同时输入被掩码后的深度图和对应的RGB彩色图像,通过联合嵌入的ViT架构,将两种模态的数据转化为统一隐空间中的特征表示,并通过自注意力机制,自动学习RGB图像的外观信息与深度图的几何信息之间的精细对应关系。例如,模型能够通过RGB图像中玻璃边缘的折射畸变特征,推断出玻璃的真实形态与深度信息,从而精准补全深度缺失区域。
深度重建与优化:通过ConvStack卷积金字塔解码器,对融合后的特征进行解码,重建出完整、高精度的深度图,并通过一系列优化策略(如正则化、损失函数优化),降低重建误差,提升深度图的精度与细节丰富度。
与传统深度建模技术相比,MDM范式具有三大核心优势:
针对性解决透明、反光场景痛点:通过利用传感器天然掩码,让模型专门学习这类场景的深度感知规律,能够精准捕捉透明、反光物体的形态与深度信息,打破了传统技术在这类场景下的性能瓶颈;
提升模型泛化能力:由于训练过程中使用的是真实场景中的天然掩码,模型能够学习到真实世界的物理规律,而非人工设定的规则,因此在不同场景下的泛化能力更强;
降低硬件依赖:通过算法创新弥补硬件短板,无需依赖高端传感器,仅通过消费级RGB-D相机的原始数据,就能实现高精度深度感知,大大降低了项目的落地成本。
3.2 模型架构:高效、精准的跨模态融合架构
LingBot-Depth的模型架构采用“编码器-解码器”结构,核心由联合嵌入的ViT编码器、ConvStack卷积金字塔解码器两部分组成,同时引入模态编码、自注意力机制等技术,实现RGB与深度两种模态的高效融合,确保模型的精度与推理速度。整体架构设计简洁、高效,既保证了高精度,又兼顾了易用性与部署效率,具体结构如下:
(1)输入层
输入层支持两种类型的输入数据,适配不同的使用场景:
双模态输入:RGB彩色图像 + 原始深度图(可带缺失、噪声),主要用于深度补全、3D场景重建、4D点追踪等任务;
单模态输入:仅RGB彩色图像,主要用于单目深度估计任务。
输入层会对输入数据进行预处理:将RGB图像归一化到[0,1]范围,调整尺寸至模型适配大小;对原始深度图进行归一化处理,保留其真实物理尺度信息,同时标记出缺失区域,为后续的掩码处理做准备。预处理过程简洁高效,无需开发者手动进行复杂的数据处理,模型会自动完成适配。
(2)联合嵌入的ViT编码器
编码器是模型实现跨模态特征融合的核心部分,采用视觉Transformer(ViT-L/14)作为主干网络,主要负责将RGB图像和深度图的原始数据,转化为统一隐空间中的特征表示,并学习两种模态之间的关联关系。
与传统的ViT架构不同,LingBot-Depth的编码器引入了模态编码(Modality Embedding) 技术,能够明确区分输入特征的模态类型——即告诉模型哪些特征来自RGB图像(外观信息),哪些特征来自深度图(几何信息),从而避免两种模态的特征混淆,提升特征融合的精度。具体来说,编码器会对RGB图像和深度图分别进行分块处理(Patch Embedding),将图像分成若干个固定大小的块,每个块转化为一个特征向量(Token),然后为每个特征向量添加对应的模态编码,再输入到自注意力层中。
自注意力机制是编码器的核心,能够自动学习不同特征之间的关联关系——无论是RGB图像内部的外观特征关联,还是深度图内部的几何特征关联,抑或是RGB图像与深度图之间的跨模态关联,都能通过自注意力机制被精准捕捉。例如,模型能够通过自注意力机制,将RGB图像中玻璃的折射特征,与深度图中玻璃的缺失区域关联起来,从而精准推断出玻璃的深度信息。
此外,编码器还引入了残差连接、层归一化等技术,有效缓解了模型训练过程中的梯度消失问题,加快了训练速度,同时提升了模型的稳定性与泛化能力。
(3)ConvStack卷积金字塔解码器
解码器的核心作用是将编码器输出的隐空间特征,解码为完整、高精度的深度图。LingBot-Depth放弃了传统的Transformer解码器,转而采用ConvStack卷积金字塔解码器,这种结构在处理密集的几何预测任务(如深度图重建)时,具有天然的优势——能够更好地保留空间细节和边界锐度,输出的深度图更加清晰、连贯,避免了传统Transformer解码器在深度图重建中出现的边缘模糊、细节丢失等问题。
ConvStack卷积金字塔解码器采用多尺度卷积结构,分为多个层级,每个层级负责不同尺度的特征解码:
高层级:负责解码全局特征,捕捉深度图的整体结构与空间关系,确保深度图的整体精度与物理尺度准确性;
低层级:负责解码局部特征,捕捉深度图的细节信息(如物体边缘、纹理),确保深度图的细节丰富度与边缘锐度。
解码器的每个层级都引入了卷积、批归一化、激活函数等组件,同时采用跳跃连接技术,将编码器输出的不同层级特征,直接连接到解码器的对应层级中,从而保留更多的原始特征信息,提升深度图重建的精度。此外,解码器还引入了注意力门控机制,能够重点关注深度图的缺失区域和细节区域,进一步提升深度补全的精度与细节表现。
(4)输出层
输出层负责将解码器输出的特征,转化为最终的输出结果,根据不同的任务需求,输出不同类型的数据:
深度补全任务:输出精细化的深度图,包含每个像素的深度信息,保留真实物理尺度;
单目深度估计任务:输出完整的深度图,与输入的RGB图像尺寸一致,精度满足实际应用需求;
3D场景重建任务:输出3D点云数据或完整的3D场景模型,支持后续的模型优化与可视化;
4D点追踪任务:输出动态场景中每个点的3D位置轨迹数据,支持实时追踪与分析。
输出层还会对输出结果进行后处理,包括深度图的降噪、边缘优化,3D点云的去噪、简化等,确保输出结果的质量,满足不同场景的使用需求。
3.3 训练策略:大规模数据集+科学训练方法
一个高精度的深度感知模型,离不开大规模高质量数据集的支撑,以及科学合理的训练策略。LingBot-Depth的训练过程充分兼顾了数据集的多样性、训练方法的科学性,确保模型能够学习到真实世界的空间几何规律,具备优异的精度与泛化能力。
(1)大规模高质量数据集构建
LingBot-Depth的训练数据集采用“真实数据+仿真数据+开源数据”的混合模式,总计规模达到1000万,其中包含200万真实世界数据、100万高保真仿真数据,以及700万开源数据集(如NYUv2、ETH3D等),数据集的多样性与真实性,为模型的高精度与高鲁棒性提供了坚实基础。
真实世界数据:团队设计了一套模块化的3D打印采集装置,灵活适配多种商用RGB-D相机(如Orbbec Gemini、Intel RealSense、ZED等),走遍了住宅、办公室、商场、餐厅、健身房、医院、停车场等数十种场景,系统性地收集了大量包含透明、反光、低纹理等挑战性物体的真实数据。这些数据覆盖了极其丰富的长尾场景,完美还原了真实世界中深度相机的成像缺陷,为模型学习真实场景的深度感知规律提供了有力支撑。
高保真仿真数据:为了模拟真实深度相机的成像缺陷,团队没有简单地渲染完美的深度图,而是在Blender(一款专业的3D建模渲染工具)中,同时渲染RGB图像和带散斑的红外立体图像对,再通过经典的半全局匹配(SGM)算法生成有缺陷的仿真深度图。这种方法能够高度还原真实传感器在面对复杂材质(如透明、反光)时的失效模式,补充了真实数据中难以覆盖的极端场景,进一步提升了模型的泛化能力。
开源数据集:整合了NYUv2、ETH3D、DIODE等多个权威开源数据集,这些数据集涵盖了多种不同场景、不同物体类型的RGB-D数据,能够丰富数据集的多样性,帮助模型学习到更全面的3D几何知识。
值得注意的是,这套包含200万真实数据和100万仿真数据的数据集,蚂蚁灵波团队计划于2026年3月中旬完成授权审批后正式开源,届时将进一步降低整个行业在空间感知领域的研究门槛,推动行业技术创新。
(2)科学的训练方法
为了充分发挥数据集的价值,确保模型能够高效、稳定地训练,LingBot-Depth采用了一系列科学的训练方法,包括迁移学习、混合精度训练、正则化优化等,具体如下:
迁移学习策略:模型首先在大规模的混合数据集上进行预训练,学习通用的3D几何知识和跨模态融合能力,获得基础的预训练模型;然后针对不同的下游任务(如深度补全、单目深度估计、机器人抓取),在对应的细分数据集上进行微调,优化模型参数,使其适配具体的任务需求。这种训练策略不仅能够加快模型的训练速度,减少训练所需的算力与时间,还能提升模型的泛化能力与任务适配性,确保模型在不同场景下都能表现优异。
混合精度训练:采用FP16(半精度)与FP32(单精度)混合的训练方式,在保证模型训练精度的前提下,减少训练过程中的显存占用,加快训练速度。这种训练方式能够适配普通GPU设备,降低模型训练的硬件门槛,让更多开发者能够参与到模型的二次训练与优化中。
正则化优化:为了避免模型训练过程中出现过拟合(即模型在训练数据上表现优异,但在新数据上表现较差)的问题,LingBot-Depth引入了多种正则化技术,包括Dropout、L2正则化、数据增强等。其中,数据增强技术主要针对RGB图像和深度图进行处理,如随机裁剪、翻转、旋转、亮度调整、噪声添加等,能够丰富训练数据的多样性,提升模型的泛化能力,确保模型在不同场景、不同光照条件下都能稳定工作。
损失函数优化:设计了一套多任务混合损失函数,结合深度重建损失、边缘损失、一致性损失等多种损失函数,全面优化模型的训练效果。其中,深度重建损失用于确保重建的深度图与真实深度图的误差最小;边缘损失用于优化深度图的边缘锐度,确保物体边缘清晰;一致性损失用于确保RGB图像与深度图的跨模态一致性,提升模型的跨模态融合精度。多损失函数的结合,使得模型能够在多个维度上得到优化,最终实现高精度的深度感知。
3.4 推理优化:高效、易用,适配多设备
LingBot-Depth在保证精度的前提下,对模型的推理过程进行了全面优化,确保模型能够高效运行,同时适配CPU、GPU等多种设备,降低开发者的部署门槛,满足不同场景的推理需求(如实时推理、批量推理)。
(1)推理速度优化
模型轻量化优化:对模型的编码器、解码器结构进行了轻量化设计,减少了模型的参数数量与计算量,在不影响精度的前提下,显著提升了推理速度。例如,对ViT编码器的分块大小进行了优化,平衡了推理速度与精度;对ConvStack解码器的卷积层级进行了精简,减少了不必要的计算操作。
推理引擎优化:集成了PyTorch的推理优化工具,支持TensorRT加速(GPU环境下),能够进一步提升模型的推理速度,满足实时推理场景的需求(如机器人自主导航、实时3D扫描)。在GPU环境下,模型的推理速度比未优化前提升了30%以上,能够快速处理高清图像数据。
批量推理支持:优化了模型的推理接口,支持批量输入图像数据进行推理,能够显著提升批量处理的效率,适用于大规模数据处理场景(如工业检测中的批量图像深度分析)。
(2)多设备适配
LingBot-Depth能够灵活适配多种硬件设备,无论是普通的CPU设备,还是高性能的GPU设备,都能正常运行,无需开发者进行复杂的设备适配操作:
GPU环境:支持NVIDIA GPU设备,适配CUDA、CuDNN框架,能够充分利用GPU的并行计算能力,实现推理加速,适用于对推理速度有较高要求的场景;
CPU环境:对CPU推理进行了优化,能够在普通CPU设备上稳定运行,虽然推理速度比GPU环境慢,但无需配备高端GPU,降低了部署门槛,适用于对推理速度要求不高、硬件条件有限的场景。
此外,模型还支持多种操作系统(Windows、Linux、macOS),开发者可以在不同的操作系统环境下进行开发与部署,进一步提升了项目的易用性。

四、应用场景
4.1 机器人领域
机器人领域是LingBot-Depth最核心的应用场景,也是其落地价值最突出的领域。无论是服务机器人、工业机器人,还是自主移动机器人,都需要精准的空间感知能力,才能实现自主导航、避障、灵巧操作等核心任务。而LingBot-Depth无需更换高端硬件,就能为机器人提供高精度的空间感知支撑,解决了传统机器人在透明、反光场景下“看不清、抓不准”的痛点,显著提升机器人的操作能力与环境适应能力。
(1)机器人灵巧操作
在服务机器人、工业机器人的灵巧操作场景中(如抓取、搬运、装配),机器人需要精准感知物体的3D形态、空间位置、表面特征,才能调整抓取姿态与力度,实现稳定、精准的操作。传统机器人在面对透明、反光物体(如玻璃杯、不锈钢杯、透明收纳盒)时,由于深度感知精度不足,很容易出现抓取失败、物体掉落等问题,而LingBot-Depth能够完美解决这一痛点。
例如,蚂蚁灵波团队已将LingBot-Depth部署到真实的机器人平台上,该系统由节卡(Rokae)XMate-SR5机械臂、X Hand-1灵巧手和奥比中光Gemini 330系列深度相机组成,用于抓取一系列对深度感知极具挑战的物体(不锈钢杯、透明玻璃杯、透明收纳盒、玩具车)。测试结果显示,使用LingBot-Depth后,机器人的抓取成功率得到了显著提升:透明收纳箱的抓取成功率从0%提升至50%,在多种反光和透明物体上的抓取成功率提升了30%~78%,彻底解决了传统机器人在这类物体抓取上的难题。
这种应用场景可广泛落地于餐饮服务机器人(抓取餐具、饮品)、工业机器人(抓取透明/反光工件)、家庭服务机器人(抓取生活用品)等领域,显著提升机器人的实用性与落地能力。
(2)机器人自主导航与场景探索
自主移动机器人(如扫地机器人、仓储机器人、巡检机器人)需要精准感知周围环境的3D空间结构,才能实现自主导航、避障、路径规划等任务。LingBot-Depth的深度补全、3D场景重建、4D点追踪等功能,能够为自主移动机器人提供全方位的空间感知支撑。
例如,在仓储机器人场景中,仓库内存在大量的透明货架、反光货物包装,传统深度相机很容易出现深度数据缺失、精度失真等问题,导致机器人无法精准识别货架位置、避障失败。而LingBot-Depth能够精准补全透明、反光区域的深度数据,快速重建仓库的3D场景模型,同时通过4D点追踪功能,精准追踪动态货物的运动轨迹,帮助机器人实现精准导航、避障与货物定位,提升仓储作业的效率与准确性。
在巡检机器人场景中(如工厂巡检、停车场巡检),LingBot-Depth的单目深度估计功能能够发挥重要作用——无需为机器人配备高端深度相机,仅通过普通的工业相机,就能实现对巡检环境的3D空间感知,精准识别设备故障、障碍物等,降低机器人的硬件成本,同时提升巡检的精度与效率。
(3)机器人场景交互
在服务机器人与人类的交互场景中,LingBot-Depth能够帮助机器人精准感知人类的动作、姿态,以及周围环境的变化,实现更自然、精准的交互。例如,家庭服务机器人能够通过LingBot-Depth的深度感知功能,精准感知人类的手势、动作,理解人类的指令(如“拿一杯水”),同时感知周围环境的障碍物,避免在移动过程中碰撞人类或物体,提升交互的安全性与体验感。
4.2 3D视觉领域
3D视觉领域是LingBot-Depth的重要应用场景,其深度补全、单目深度估计、3D场景重建等功能,能够为3D建模、AR/VR、文物数字化等任务提供核心支撑,降低3D视觉任务的硬件门槛与技术难度。
(1)3D场景重建与数字化
3D场景重建是3D视觉领域的核心任务之一,广泛应用于室内设计、建筑设计、虚拟场景搭建、文物数字化等场景。LingBot-Depth能够快速、高精度地实现3D场景重建,将2D图像转化为高保真的3D场景模型,无需复杂的操作流程,同时能够完美还原透明、反光物体的形态,解决了传统3D重建工具在这类物体上的还原精度不足问题。
在文物数字化场景中,很多文物(如玻璃器、玉器、青铜器)具有透明、反光的特征,传统3D重建工具很难精准还原其形态与细节纹理,而LingBot-Depth能够通过深度补全与3D场景重建功能,精准捕捉文物的3D形态、细节纹理与空间结构,生成高保真的3D数字模型,为文物的保护、研究、展示提供有力支撑。例如,博物馆可以通过该项目,对珍贵的透明文物进行数字化重建,构建虚拟博物馆,让观众能够通过线上方式,近距离观察文物的细节,同时避免文物受到物理损坏。
在室内设计场景中,设计师可以通过LingBot-Depth的单目深度估计与3D场景重建功能,快速将室内空间的2D照片转化为3D场景模型,直观呈现室内的空间布局、尺寸比例,方便设计师进行方案优化与调整,同时也能让客户更直观地了解设计效果,提升设计效率与客户满意度。
(2)AR/VR场景搭建
AR(增强现实)、VR(虚拟现实)场景的搭建,需要精准的3D空间感知能力,才能实现虚拟物体与真实环境的精准融合,提升AR/VR体验的沉浸感与真实性。LingBot-Depth的单目深度估计、3D场景重建功能,能够为AR/VR场景搭建提供高效、低成本的解决方案。
例如,在AR购物场景中,用户通过手机相机拍摄真实的家居环境,LingBot-Depth能够通过单目深度估计功能,快速获取家居环境的3D空间信息,然后将虚拟的家具模型精准放置在真实环境中,用户能够直观查看家具的尺寸、摆放效果,提升购物体验;在VR游戏场景中,LingBot-Depth能够快速重建真实场景的3D模型,将真实场景与虚拟游戏元素融合,提升游戏的沉浸感与真实性,同时降低VR场景搭建的成本与技术难度。
(3)双目立体匹配加速
LingBot-Depth的预训练模型还可以作为强单目深度先验,融入到双目立体匹配模型中,加速双目匹配模型的训练过程,提升双目立体匹配的精度。例如,研究人员将LingBot-Depth模型融入FoundationStereo模型中,结果显示,FoundationStereo模型的收敛速度显著加快,同时匹配精度也得到了提升,这一应用能够为双目3D视觉任务提供有力支撑,降低模型训练的时间成本与技术难度。
4.3 工业领域
在工业领域,LingBot-Depth能够为质量检测、工件定位、生产线巡检等任务提供高精度的空间感知支撑,帮助企业提升生产效率、降低检测成本,同时解决传统工业检测中难以解决的透明、反光工件检测难题。
(1)透明/反光工件质量检测
在工业生产中,很多工件(如玻璃制品、塑料透明件、不锈钢工件)具有透明、反光的特征,传统的检测方法(如人工检测、普通视觉检测)很难精准检测出工件的表面缺陷、尺寸误差等问题,检测效率低、误差大,且人工检测成本高。而LingBot-Depth能够通过深度补全、单目深度估计功能,精准感知透明/反光工件的3D形态、尺寸、表面特征,快速检测出工件的表面缺陷(如划痕、裂纹)、尺寸误差等问题,提升检测精度与效率,降低检测成本。
例如,在玻璃制品生产场景中,企业可以通过LingBot-Depth搭建自动化检测生产线,利用普通工业相机采集玻璃制品的RGB图像,通过单目深度估计功能,精准获取玻璃制品的3D形态与表面信息,自动检测出玻璃制品的划痕、裂纹、尺寸偏差等缺陷,检测效率比人工检测提升5倍以上,检测精度达到99%以上,同时降低了人工检测的成本与误差。
(2)工件定位与装配引导
在工业装配场景中,机器人需要精准定位工件的空间位置,才能实现精准的装配操作。对于透明、反光的工件,传统的定位方法很难精准定位其空间位置,导致装配误差大、装配失败等问题。而LingBot-Depth能够通过深度补全、3D场景重建功能,精准定位透明/反光工件的空间位置,为装配机器人提供精准的引导,提升装配精度与效率。
例如,在汽车零部件装配场景中,部分汽车零部件(如透明灯罩、不锈钢连接件)具有透明、反光的特征,装配机器人通过LingBot-Depth的深度感知功能,能够精准定位零部件的空间位置,调整装配姿态,实现精准装配,装配误差控制在0.1mm以内,装配效率提升30%以上,显著降低了装配失败率与生产成本。
4.4 消费电子领域
消费电子领域是LingBot-Depth的重要拓展场景,其单目深度估计、3D场景重建等功能,能够为手机、平板电脑、相机等消费电子产品,新增3D感知相关的功能,提升产品的竞争力,丰富用户体验。
(1)手机3D扫描与建模
随着手机摄影技术的发展,3D扫描、3D建模已成为手机的新兴功能需求。LingBot-Depth的单目深度估计功能,能够让普通手机相机具备高精度的3D深度感知能力,用户只需通过手机拍摄物体的RGB照片,就能快速生成物体的3D模型,用于3D打印、虚拟展示、创意设计等场景。
例如,用户可以通过手机拍摄一件小饰品,利用LingBot-Depth的单目深度估计与3D重建功能,快速生成饰品的3D模型,然后通过3D打印机打印出实物;设计师可以通过手机拍摄产品原型,生成3D模型,用于产品设计与优化,提升设计效率。
(2)手机AR功能升级
当前手机的AR功能(如AR测距、AR导航、AR特效),大多依赖于简单的深度感知技术,精度较低,体验不佳。LingBot-Depth能够为手机AR功能提供高精度的深度感知支撑,提升AR功能的精度与体验感。
例如,在AR测距场景中,用户通过手机拍摄两个物体,LingBot-Depth能够通过单目深度估计功能,精准测量出两个物体之间的距离,误差控制在1mm以内,比传统AR测距功能的精度提升50%以上;在AR特效场景中,LingBot-Depth能够精准感知用户的面部特征、周围环境的3D空间信息,让AR特效与用户面部、周围环境的融合更自然、精准,提升用户体验。
4.5 其他领域
除了上述领域外,LingBot-Depth还能应用于文物保护、医疗影像、自动驾驶等多个领域,展现出广泛的应用前景:
文物保护:除了文物数字化重建外,还能通过深度感知功能,精准检测文物的损坏情况(如文物表面的细微裂纹),为文物修复提供精准的数据支撑,避免修复过程中对文物造成二次损坏;
医疗影像:在医疗影像领域,能够通过深度补全、3D重建功能,将2D医疗影像(如CT、MRI影像)转化为3D模型,帮助医生更直观地观察患者的病灶位置、形态,提升诊断的准确性;
自动驾驶:在自动驾驶领域,能够通过单目深度估计、4D点追踪功能,帮助自动驾驶车辆精准感知周围环境的3D空间信息、动态物体的运动轨迹,提升自动驾驶的安全性与可靠性,同时降低自动驾驶车辆的硬件成本(无需配备高端激光雷达)。
五、使用方法
5.1 环境准备
LingBot-Depth基于Python开发,对软硬件环境有基础要求,基础环境为必选,GPU加速为可选(大幅提升推理/训练速度),具体要求如下:
基础软件环境(必选)
Python 版本:≥3.9(推荐3.9/3.10,兼容度最高)
PyTorch 版本:≥2.0.0(需与CUDA版本匹配,若使用GPU)
核心依赖库:torchvision≥0.15.0、opencv-python≥4.8.0、numpy≥1.24.0、pillow≥10.0.0、scipy≥1.10.0
硬件环境(可选/推荐)
CPU:任意多核CPU(仅用于轻量推理/测试,不推荐训练)
GPU:NVIDIA GPU(显存≥10G,推荐A100/V100/3090/4090),支持CUDA 11.7+/cuDNN 8.8+
存储:≥20G空闲空间(用于存放代码、预训练模型、测试数据)
CUDA环境配置提示:若使用GPU,需提前安装与PyTorch匹配的CUDA Toolkit,无需手动安装CUDA驱动,PyTorch会自动适配,推荐使用CUDA 11.8版本,兼容性覆盖绝大多数NVIDIA GPU。
5.2 项目安装
LingBot-Depth提供源码安装和本地开发安装两种方式,源码安装为官方推荐方式,支持所有核心功能,本地开发安装适合快速调用,两种方式操作如下:
方式1:源码安装(推荐,支持全功能)
# 克隆仓库
git clone https://github.com/Robbyant/lingbot-depth.git
cd lingbot-depth
# 安装依赖(-e 为可编辑模式,支持本地代码修改后实时生效)
pip install -e .
# 验证安装:无报错即安装成功
python -c "from mdm.model.v2 import MDMModel; print('安装成功')"方式2:本地开发安装(轻量调用,仅支持推理功能)
若仅需使用预训练模型进行推理,可直接将仓库源码下载到本地项目目录,通过sys.path添加路径后调用,适合快速集成到自有项目中:
import sys
# 将lingbot-depth仓库根目录添加到环境路径
sys.path.append("/your/path/to/lingbot-depth")
# 验证调用
from mdm.model.v2 import MDMModel
print("本地调用配置成功")5.3 快速上手(核心功能推理示例)
项目在examples/目录下提供了测试数据(RGB图、原始深度图、相机内参),可直接使用测试数据完成推理,以下为深度补全与精细化、单目深度估计、3D场景重建三大核心功能的完整可运行代码示例,适配CPU/GPU自动切换。
5.3.1 核心功能1:深度补全与精细化(最常用)
该示例实现消费级RGB-D相机原始深度图的缺失填充、噪声降噪,输出高精度精细化深度图,是项目最核心的使用场景:
import torch
import cv2
import numpy as np
from mdm.model.v2 import MDMModel
from mdm.visualize import show_depth # 可视化工具
# 1. 设备自动适配(GPU优先,无GPU则使用CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")
# 2. 加载预训练模型(自动从Hugging Face/ModelScope下载,首次运行需等待)
model = MDMModel.from_pretrained(
pretrained_model_name_or_path="robbyant/lingbot-depth-pretrain-vitl-14",
device=device
)
model.eval() # 推理模式,关闭梯度计算
# 3. 加载并预处理测试数据(RGB图、原始深度图、相机内参)
# 测试数据路径:lingbot-depth/examples/0/
rgb_path = "examples/0/rgb.png"
raw_depth_path = "examples/0/raw_depth.png"
intrinsics_path = "examples/0/intrinsics.txt"
# 预处理RGB图像:BGR转RGB、归一化、维度转换[H,W,C]→[1,C,H,W]
rgb = cv2.cvtColor(cv2.imread(rgb_path), cv2.COLOR_BGR2RGB)
h, w = rgb.shape[:2]
rgb_tensor = torch.tensor(rgb / 255.0, dtype=torch.float32, device=device)
rgb_tensor = rgb_tensor.permute(2, 0, 1).unsqueeze(0)
# 预处理原始深度图:单位转换(mm→m)、维度转换[H,W]→[1,1,H,W]
raw_depth = cv2.imread(raw_depth_path, cv2.IMREAD_UNCHANGED).astype(np.float32) / 1000.0
depth_tensor = torch.tensor(raw_depth, dtype=torch.float32, device=device).unsqueeze(0).unsqueeze(0)
# 预处理相机内参:归一化、维度转换[3,3]→[1,3,3]
intrinsics = np.loadtxt(intrinsics_path)
intrinsics[0] /= w # 按图像宽度归一化
intrinsics[1] /= h # 按图像高度归一化
intrinsics_tensor = torch.tensor(intrinsics, dtype=torch.float32, device=device).unsqueeze(0)
# 4. 模型推理:获取精细化深度图
with torch.no_grad(): # 关闭梯度,节省显存
output = model.infer(
image=rgb_tensor,
depth_in=depth_tensor,
intrinsics=intrinsics_tensor
)
refined_depth = output["depth"].squeeze().cpu().numpy() # 精细化深度图(m)
raw_depth_np = depth_tensor.squeeze().cpu().numpy() # 原始深度图(对比用)
# 5. 结果可视化与保存
show_depth(raw_depth_np, title="原始深度图") # 展示原始深度图
show_depth(refined_depth, title="精细化深度图")# 展示精细化深度图
# 保存精细化深度图(单位:mm,符合行业通用格式)
cv2.imwrite("refined_depth.png", (refined_depth * 1000).astype(np.uint16))
print("精细化深度图已保存至:refined_depth.png")5.3.2 核心功能2:单目深度估计(仅用RGB图生成深度)
无需深度相机,仅通过一张RGB彩色图像即可生成高精度深度图,降低3D感知硬件门槛,代码示例如下(基于上述环境基础):
import torch
import cv2
import numpy as np
from mdm.model.v2 import MDMModel
from mdm.visualize import show_depth
# 1. 设备与模型加载(同深度补全,复用预训练模型即可)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MDMModel.from_pretrained("robbyant/lingbot-depth-pretrain-vitl-14", device=device).eval()
# 2. 加载并预处理RGB图像(无深度图/内参需求)
rgb_path = "your_rgb_image.jpg" # 自定义RGB图像路径
rgb = cv2.cvtColor(cv2.imread(rgb_path), cv2.COLOR_BGR2RGB)
h, w = rgb.shape[:2]
rgb_tensor = torch.tensor(rgb / 255.0, dtype=torch.float32, device=device)
rgb_tensor = rgb_tensor.permute(2, 0, 1).unsqueeze(0)
# 3. 单目深度估计推理(仅输入RGB图)
with torch.no_grad():
output = model.infer(image=rgb_tensor)
mono_depth = output["depth"].squeeze().cpu().numpy() # 单目估计深度图(m)
# 4. 结果可视化与保存
show_depth(mono_depth, title="单目估计深度图")
cv2.imwrite("mono_depth.png", (mono_depth * 1000).astype(np.uint16))
print("单目深度图已保存至:mono_depth.png")5.3.3 核心功能3:3D场景重建(从深度图生成点云/三维模型)
基于补全/估计的深度图,快速生成3D点云数据(.ply格式),支持导入Meshlab/Blender等工具进行三维模型重建,代码示例如下:
import torch
import cv2
import numpy as np
from mdm.model.v2 import MDMModel
from mdm.utils import depth2point_cloud, save_ply
# 1. 设备与模型加载,完成深度补全(复用5.3.1的精细化深度图结果)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MDMModel.from_pretrained("robbyant/lingbot-depth-pretrain-vitl-14", device=device).eval()
# (此处省略RGB/深度图/内参的预处理代码,同5.3.1)
with torch.no_grad():
output = model.infer(image=rgb_tensor, depth_in=depth_tensor, intrinsics=intrinsics_tensor)
refined_depth = output["depth"].squeeze().cpu().numpy()
intrinsics = np.loadtxt(intrinsics_path) # 原始内参(未归一化)
# 2. 深度图转3D点云(含颜色信息,与RGB图匹配)
rgb_np = cv2.imread(rgb_path)[:, :, ::-1] # RGB原始图像
point_cloud = depth2point_cloud(
depth=refined_depth,
intrinsics=intrinsics,
rgb=rgb_np,
depth_scale=1000.0 # 深度单位:m→mm
)
# 3. 保存点云文件(.ply格式,可直接用Meshlab打开)
save_ply("scene_point_cloud.ply", point_cloud)
print("3D场景点云已保存至:scene_point_cloud.ply")
# 提示:将.ply点云导入Meshlab后,可通过“泊松重建”生成完整三维网格模型5.4 模型训练与微调
若需针对自有数据集优化模型(如特定工业场景、专属机器人任务),LingBot-Depth提供了轻量化的微调接口,无需从零训练,基于官方预训练模型微调即可,基础微调步骤如下(核心流程,适配深度补全任务):
数据集准备:将自有RGB-D数据按项目规范组织(目录结构:
dataset/[样本ID]/rgb.png + depth.png + intrinsics.txt),深度图单位为mm,内参为3×3矩阵;配置文件修改:修改仓库
configs/finetune/dc_config.yaml配置文件,设置数据集路径、训练批次(batch_size)、学习率、训练轮数(epoch)、保存路径等基础参数;启动微调训练:运行官方训练脚本,自动加载预训练模型并开始微调:
cd lingbot-depth python train.py --config configs/finetune/dc_config.yaml --device cuda
模型保存与加载:训练完成后,模型会自动保存至
outputs/finetune/目录,可通过MDMModel.from_pretrained("your_model_path")加载微调后的模型进行推理;训练监控:支持TensorBoard监控训练过程,运行
tensorboard --logdir outputs/finetune/logs/即可查看损失曲线、精度指标等。
微调提示:若显存不足,可减小配置文件中的batch_size(如从8降至4/2),或开启混合精度训练(配置文件中设置fp16: True)。
六、常见问题解答
Q1:安装时出现“torchvision版本不匹配”/“依赖库冲突”报错?
解决办法:
卸载现有冲突库:
pip uninstall -y torchvision opencv-python;按官方推荐版本重新安装:
pip install torchvision==0.15.2 opencv-python==4.8.1.78;若使用conda环境,建议通过conda安装核心依赖,避免pip/conda混合安装导致的冲突:
conda install pytorch torchvision pytorch-cuda=11.8 -c pytorch -c nvidia。
Q2:加载预训练模型时,出现“网络超时/下载失败”?
解决办法:
手动从Hugging Face/ModelScope下载预训练模型,将模型文件放到本地目录;
调用模型时指定本地路径:
MDMModel.from_pretrained("/your/local/model/path");国内开发者可使用ModelScope镜像源,提升下载速度:
MDMModel.from_pretrained("Robbyant/lingbot-depth-pretrain-vitl-14", model_hub="modelscope")。
Q3:推理速度慢(如单张图推理耗时超10s),如何优化?
解决办法:
优先使用GPU推理(CPU推理速度为GPU的1/20~1/50,仅适合测试);
对输入图像进行降采样(如将1080P降至720P),不影响核心精度但大幅提升速度;
开启TensorRT加速(GPU环境),将模型转为TensorRT引擎:
model.convert_to_trt(precision="fp16");关闭可视化功能,推理时仅保存结果,不调用
show_depth等可视化函数。
Q4:深度补全效果差(如缺失区域未填充、边缘模糊),如何优化?
解决办法:
检查输入数据:确保RGB图与深度图严格对齐(无偏移/旋转),内参为相机真实内参,未归一化的内参不要直接使用;
更换更适配的预训练模型:若为稀疏深度补全场景,使用
robbyant/lingbot-depth-postrain-dc-vitl14专用模型,而非通用模型;调整推理参数:在
model.infer()中设置refine_iter=3(增加精细化迭代次数),提升补全效果;针对自有场景微调模型:使用自有数据集进行小批量微调,是提升特定场景效果的最优方式。
Q5:GPU推理时出现“out of memory (OOM)”显存不足报错?
解决办法:
减小输入图像尺寸(如将宽高从1920×1080降至640×480);
关闭梯度计算:推理时必须添加
with torch.no_grad(),避免显存占用激增;开启混合精度推理:
model.half()将模型转为FP16精度,显存占用减少50%;若训练时显存不足,减小配置文件中的
batch_size,或使用梯度累积(accumulate_steps=2)。
Q6:单目深度估计结果出现“尺度失真”(如物体实际距离1m,估计为2m)?
解决办法:
单目深度估计本身为相对深度,若需绝对尺度,可通过已知尺寸的参考物体(如硬币、水杯)对估计深度进行缩放校准;
若有少量相机内参信息,在
model.infer()中传入intrinsics参数,模型会基于内参优化深度尺度;用带绝对尺度的RGB-D数据对单目模型进行微调,提升尺度准确性。
Q7:运行pip install -e .时出现“权限不足”报错?
解决办法:
本地开发环境:添加
--user参数,安装到用户目录:pip install -e . --user;Linux/服务器环境:使用sudo权限(不推荐),或创建conda虚拟环境后再安装;
Windows环境:以“管理员身份”运行命令提示符/终端,再执行安装命令。
Q8:3D点云生成后,出现“点云混乱/物体错位”?
解决办法:
检查相机内参:确保内参的焦距、光心参数与实际相机匹配,内参矩阵无转置/逆矩阵错误;
确认深度图与RGB图的尺寸一致:若尺寸不同,需先将两者缩放到同一尺寸后再生成点云;
检查深度图单位:深度图转点云时,需保证深度单位与
depth_scale参数匹配(如深度图为m,depth_scale=1.0;为mm则depth_scale=1000.0)。
七、相关链接
GitHub开源仓库:https://github.com/Robbyant/lingbot-depth
Hugging Face模型库(通用/深度补全模型):https://huggingface.co/robbyant
ModelScope模型库(国内镜像,下载更快):https://www.modelscope.cn/models/Robbyant
arXiv论文:https://arxiv.org/abs/2601.17895
八、总结
LingBot-Depth是蚂蚁灵波科技开源的一款基于掩码深度建模(MDM)范式的高精度3D空间感知框架,以Python为开发语言,核心解决了消费级RGB-D相机在透明、反光、低纹理等复杂场景下的深度缺失、噪声、精度失真等行业痛点,通过算法创新弥补了硬件短板,无需高端深度传感器即可实现深度补全与精细化、单目深度估计、3D场景重建、4D点追踪等核心功能,还专门针对机器人领域优化了灵巧操作支撑能力,在NYUv2、ETH3D等权威基准测试中达到SOTA水平,且在真实机器人平台上验证了落地价值,显著提升了透明、反光物体的抓取成功率;该项目提供了完整的开源代码、丰富的预训练模型、简洁易用的推理/训练接口,适配CPU/GPU多设备,支持多种主流RGB-D相机,降低了3D空间感知领域的研究与落地门槛,同时项目还计划开源300万规模的RGB-D高质量数据集,进一步推动行业技术普及;LingBot-Depth的核心价值在于以低成本、高鲁棒性的方式实现了高精度3D空间感知,其技术成果可广泛落地于机器人、3D视觉、工业检测、消费电子、文物保护等多个领域,为各领域的空间感知需求提供了高效的开源解决方案,也为3D视觉与具身智能的融合发展提供了实用的技术参考,作为一款面向实际应用的开源项目,其兼顾了科研价值与工程落地能力,成为3D视觉和机器人领域开发者的实用工具。
相关软件下载

灵光
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/lingbot-depth.html





