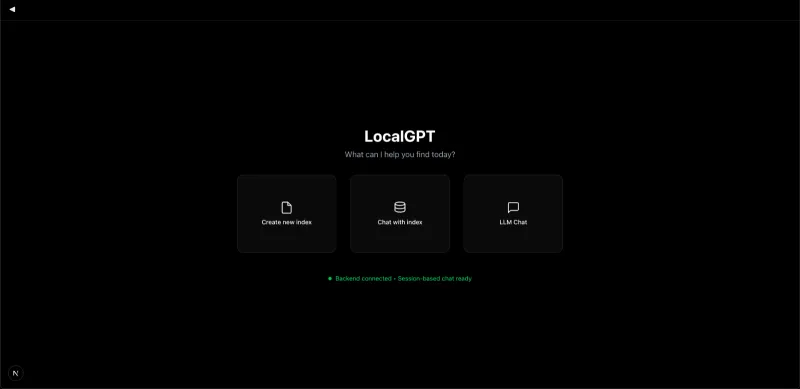
LocalGPT:开源本地AI文档问答工具,融合混合搜索与多模态RAG能力
一、LocalGPT是什么?
LocalGPT是一款完全开源、本地部署的智能文档问答工具,核心优势在于100%数据私有化——所有文档处理与AI交互均在用户设备内完成,无任何数据流出。它融合语义相似度、关键词匹配与Late Chunking技术构建混合搜索引擎,搭配智能路由与上下文增强机制,支持PDF、DOCX、TXT等多格式文档的问答、总结与洞察挖掘。
与传统的RAG(检索增强生成)工具不同,LocalGPT并非简单的“检索+生成”组合,而是构建了一套更智能、更精准的文档交互体系:它采用混合搜索引擎,融合语义相似度匹配、关键词搜索(BM25)与Late Chunking(延迟分块)技术,解决长文本上下文丢失问题;通过智能路由机制,自动为每个查询选择“RAG检索回答”或“直接LLM生成”模式;搭配句子级Context Pruning(上下文修剪)与独立验证环节,确保回答的相关性与准确性。
平台架构采用模块化设计,核心基于纯Python开发,依赖项极少,可按需启用组件,支持在 macOS、Ubuntu/Debian、Windows 等多系统部署,兼容CPU、GPU、HPU(Intel® Gaudi®)、MPS等多种计算平台,既适用于普通用户的个人知识库管理,也能满足企业级的敏感文档处理需求。
二、功能特色
LocalGPT的功能围绕“隐私安全、功能强大、易用灵活”三大核心展开,覆盖文档处理、AI交互、开发集成等全场景需求,具体特色如下:
1. 极致隐私保护,数据全程本地化
这是LocalGPT最核心的优势:所有文档上传、解析、嵌入存储,以及AI查询、回答生成等操作,均在用户本地设备完成,无任何数据传输至外部服务器,从根源上杜绝数据泄露风险,完全满足企业、科研机构等对敏感数据的隐私要求。
2. 多模型兼容与高效复用
模型集成灵活:通过Ollama无缝集成各类开源大模型(如Qwen3系列、DeepSeek等),同时支持HuggingFace的嵌入模型(如Qwen/Qwen3-Embedding-0.6B)与重排序模型(如answerdotai/answerai-colbert-small-v1);
模型复用机制:已下载的LLM模型无需重复下载,可在多次会话中直接调用,节省存储空间与网络带宽;
多任务模型分工:支持为“文本生成”“上下文增强”“检索重排序”等不同任务配置专属模型,平衡速度与效果(如用qwen3:0.6b实现快速路由,用qwen3:8b生成高质量回答)。
3. 多格式文档处理与批量支持
格式兼容广泛:当前已支持PDF、DOCX、TXT、Markdown、HTML等多种主流文档格式(文档标注“Currently only PDF is supported”为历史说明,最新代码已通过docling库扩展DOCX、HTML支持);
上下文增强:在文档索引阶段,通过AI生成补充上下文,提升模型对文档内容的理解深度,灵感源自Contextual Retrieval技术;
批量处理能力:支持同时上传多个文档进行批量索引构建,也可通过配置文件实现自动化批量处理(如demo_batch_indexing.py脚本)。
4. 智能AI聊天,精准高效交互
自然语言查询:支持用通俗的自然语言提问,无需学习特定语法,模型可理解复杂查询意图;
来源归因透明:每一个回答都会附带文档引用(来源标注),方便用户追溯答案的原始出处,提升可信度;
复杂查询分解:自动将长句、多维度的复杂查询拆解为多个子问题,分别检索回答后再合成最终结果,避免遗漏关键信息;
会话上下文记忆:在单个会话中,模型会记住之前的聊天历史,支持连续对话,无需重复输入背景信息;
语义缓存优化:采用TTL(生存时间)+ 相似度匹配的语义缓存机制,重复或相似查询可直接返回缓存结果,提升响应速度;
独立答案验证:针对关键查询,会启动独立的验证流程,通过额外模型校验回答准确性,降低错误率。
5. 多平台支持与灵活部署
计算架构兼容:原生支持CUDA(GPU)、CPU、HPU、MPS等多种计算方式,无高端硬件也可运行(CPU模式需8GB+内存,推荐16GB+);
部署方式多样:提供Docker容器化部署(一键启动)、直接开发环境部署(适合二次开发)、手动组件启动(灵活调试)三种方式,适配不同使用场景;
轻量易维护:纯Python核心,依赖项精简,模块化设计让用户可按需启用组件(如仅启动后端+RAG API,跳过前端),降低部署与维护成本。
6. 开发者友好,易集成扩展
完整RESTful API:提供索引管理、会话管理、聊天交互、批量处理等全功能API,方便集成到第三方应用或自建系统;
实时进度反馈:文档索引、查询处理等过程会返回实时进度,便于开发者监控流程状态;
灵活配置选项:支持自定义模型、分块大小(默认512)、检索参数(如检索数量k值)、搜索类型等,适配不同文档类型与查询需求;
可扩展架构:支持插件化开发,允许开发者添加自定义组件(如专属重排序算法、文档解析器)。
7. 现代直观的Web界面
简洁响应式设计:前端基于React/Next.js开发,界面干净直观,支持桌面端、平板等多设备访问;
索引管理便捷:可创建、命名、删除索引,直观查看已上传的文档列表,支持索引配置自定义;
会话分类管理:可按主题创建多个聊天会话,方便分类管理不同文档集的交互记录;
实时流式响应:聊天过程中采用流式输出,无需等待完整回答生成,即时获得反馈。
核心功能总结表
| 功能类别 | 核心特性 |
|---|---|
| 隐私安全 | 100%本地运行、数据零泄露、无第三方依赖 |
| 文档处理 | 多格式支持(PDF/DOCX/TXT等)、批量处理、上下文增强、Late Chunking |
| AI交互 | 自然语言查询、来源归因、查询分解、会话记忆、语义缓存、答案验证 |
| 模型支持 | Ollama集成、多模型复用、HuggingFace嵌入/重排序模型、多任务模型分工 |
| 部署与扩展 | 多计算架构兼容、Docker/开发环境/手动部署、RESTful API、插件化扩展 |
| 界面体验 | 响应式Web UI、索引管理、会话分类、实时流式响应 |
三、技术细节
LocalGPT的强大功能源于其模块化、高性能的技术架构,核心技术栈与设计逻辑如下:
1. 整体架构
LocalGPT采用分层模块化架构,自上而下分为5个核心层级,各模块松耦合,可独立部署与扩展:
Web界面层(React/Next.js)→ 后端API层(Python FastAPI)→ RAG代理层 → 处理管道层 → 存储层
Web界面层(src/目录):负责用户交互,包括文件上传、索引创建、聊天界面、配置管理等,基于Next.js实现服务端渲染,响应迅速;
后端API层(backend/目录):提供RESTful API接口,负责会话管理、索引元数据存储、权限控制(基础版),基于FastAPI开发,性能高效;
RAG代理层(rag_system/agent/目录):核心决策模块,实现智能路由(RAG/直接LLM选择)、查询分解、子问题调度、结果合成,基于ReAct代理模式设计;
处理管道层:包含检索管道(rag_system/retrieval/)与生成管道(rag_system/generation/),前者负责混合搜索、重排序、上下文修剪,后者负责文本生成与验证;
存储层:包含向量数据库、关键词索引、会话数据库,负责数据持久化存储。
2. 核心技术亮点
(1)混合搜索引擎
LocalGPT的检索核心是“多向量+关键词+延迟分块”的混合模式,解决传统单一检索的局限性:
语义向量检索(权重0.7):基于嵌入模型(如Qwen3-Embedding-0.6B)将文档与查询转换为向量,通过LanceDB进行语义相似度匹配,捕捉深层语义关联;
关键词检索(BM25,权重0.3):基于词频统计构建关键词索引,快速匹配字面相关内容,弥补语义检索对专有名词、缩写的敏感度不足;
Late Chunking(延迟分块):传统RAG在索引时分块,易割裂上下文;LocalGPT在检索后对匹配到的文档片段进行二次分块,确保上下文完整性,提升长文本回答精度。
(2)智能路由机制
RAG代理层会先对用户查询进行“分诊”:
结合聊天历史与文档摘要,构建分诊提示词;
调用轻量模型(如qwen3:0.6b)判断查询类型:
若查询可通过文档内容回答(如“文档中提到的项目周期是多久?”),则走RAG路径(检索+生成);
若查询与文档无关(如“今天天气如何?”),则走直接LLM路径(无需检索);
路由决策确保资源高效利用,避免不必要的检索开销。
(3)上下文处理优化
Context Pruning(上下文修剪):从检索结果中筛选句子级别的关键信息,剔除冗余内容,确保输入模型的上下文聚焦核心,避免token溢出;
上下文增强:索引阶段为文档片段生成AI辅助说明(如“这段内容讨论了项目预算分配”),检索时结合原始内容与增强说明,提升匹配准确性。
(4)多阶段验证流程
检索重排序:初始检索结果(默认20条)会通过专门的重排序模型(如answerdotai/answerai-colbert-small-v1)筛选Top10,提升相关性;
答案验证:生成最终回答后,若启用验证功能,会调用独立模型校验回答与原始文档的一致性,若存在矛盾则提示用户并补充原始引用。
3. 数据存储设计
LocalGPT采用“多存储协同”模式,不同数据类型对应不同存储方案:
| 数据类型 | 存储方案 | 用途说明 |
|---|---|---|
| 文本/嵌入向量 | LanceDB(./lancedb/) | 存储文档分块、嵌入向量、图像嵌入(未来支持)、文档元数据,支持高效向量检索 |
| 关键词索引 | 文件系统(./index_store/bm25/) | 存储BM25关键词索引,用于快速关键词匹配 |
| 会话历史/索引元数据 | SQLite(./backend/chat_data.db) | 存储会话记录、索引名称/描述、文档上传记录等结构化数据 |
| 文档摘要/知识图谱 | 文件系统(./index_store/) | 存储文档摘要(用于路由分诊)、知识图谱数据(未来支持) |
4. 关键技术栈与依赖
LocalGPT的技术栈以Python为主,前端辅以JavaScript/TypeScript,核心依赖如下:
后端核心:Python 3.8+、FastAPI(API服务)、torch==2.4.1(深度学习)、transformers==4.51.0(模型加载);
检索与存储:lancedb(向量数据库)、rank_bm25(关键词检索)、fuzzywuzzy(模糊匹配);
文档处理:docling(多格式文档解析)、sentence_transformers(嵌入生成)、rerankers(重排序);
前端技术:Next.js、React、Tailwind CSS(样式)、TypeScript(类型安全);
部署工具:Docker、Docker Compose(容器化)、Ollama(模型服务);
辅助工具:colpali-engine(未来多模态支持)、asyncio(异步处理)、python-dotenv(环境配置)。
四、应用场景
LocalGPT的“隐私优先+本地部署+多格式处理”特性,使其在多个场景中具备不可替代的优势,主要应用场景如下:
1. 企业内部敏感文档问答
适用对象:金融、法律、医疗、政府等对数据隐私有严格合规要求的企业;
应用场景:员工查询内部规章制度、合同条款解读、客户资料分析、财务报表总结等;
核心价值:所有敏感数据(如合同、客户信息)均在企业内网设备处理,避免数据泄露风险,同时通过AI提升查询效率,减少人工检索成本。
2. 科研机构文献分析
适用对象:高校科研团队、科研院所研究人员;
应用场景:批量处理学术论文(PDF格式为主)、查询特定研究方法细节、总结研究结论、对比多篇文献的核心观点、挖掘文献引用关系等;
核心价值:本地处理避免科研数据(如未发表成果)外泄,支持批量索引与复杂查询分解,帮助科研人员快速提炼文献精华,节省阅读时间。
3. 个人知识库管理
适用对象:学生、自由职业者、知识工作者;
应用场景:管理学习笔记(TXT/Markdown)、电子书(PDF)、工作文档(DOCX),查询知识点、总结学习内容、生成复习提纲等;
核心价值:数据私有化保护个人学习/工作隐私,支持多格式文档统一管理,无需切换多个阅读器,AI辅助提升知识消化效率。
4. 涉密行业文档处理
适用对象:军工、能源、航空航天等涉密单位;
应用场景:处理涉密技术文档、项目报告、设备手册,查询技术参数、操作流程、故障排查方案等;
核心价值:完全本地部署,不依赖外部网络,符合涉密信息管理规范,同时AI赋能提升文档使用效率,保障工作合规性与高效性。
5. 二次开发与RAG应用搭建
适用对象:开发者、创业团队;
应用场景:基于LocalGPT的API构建自定义RAG应用(如企业内部文档助手、垂直领域问答工具)、集成到现有系统(如OA、知识库平台)、扩展多模态功能(如图文文档问答);
核心价值:开源免费,模块化架构便于二次开发,避免重复构建底层RAG逻辑,同时支持本地部署,降低应用上线后的隐私风险。
6. 小型团队协作文档共享
适用对象:初创公司、项目团队、工作室;
应用场景:团队共享项目文档(如需求文档、设计方案、测试报告),成员通过自然语言查询文档内容、跟踪项目进展、确认任务分工等;
核心价值:无需依赖第三方云文档工具(如腾讯文档、飞书文档),避免团队数据存储在外部服务器,同时支持多人共享索引(本地局域网内),提升协作效率。
五、使用方法
LocalGPT提供三种部署方式,满足不同用户需求(推荐Docker部署,简单快捷;开发人员推荐直接开发部署),以下是详细使用步骤:
1. 前置条件准备
无论哪种部署方式,需先满足以下基础依赖:
| 依赖项 | 版本要求 | 说明 |
|---|---|---|
| Python | 3.8+(推荐3.11.5) | 核心后端运行环境 |
| Node.js + npm | Node.js 16+、npm 10.0+ | 前端运行与构建(测试版本:Node.js 23.10.0,npm 10.9.2) |
| Docker | 任意稳定版(可选) | 容器化部署需安装,推荐Docker Desktop(Windows/macOS)、Docker Engine(Linux) |
| Ollama | 最新版(必需) | 模型服务工具,用于加载与运行开源LLM模型 |
| 内存 | 8GB+(推荐16GB+) | CPU模式需8GB以上,GPU模式推荐16GB+,批量处理大文档需32GB+ |
| 网络 | 初始模型下载需联网 | 模型下载完成后,后续使用可离线 |
2. 基础环境安装(通用步骤)
(1)安装Ollama(必需)
Ollama是LocalGPT的核心模型服务工具,需先安装并下载基础模型:
安装命令(全平台通用):
curl -fsSL https://ollama.ai/install.sh | sh
下载推荐模型(启动后需这两个模型支持核心功能):
# 快速生成模型(轻量,适合路由、分块) ollama pull qwen3:0.6b # 高质量生成模型(适合最终回答生成) ollama pull qwen3:8b
启动Ollama服务:
ollama serve
启动后默认端口为11434,可通过
http://localhost:11434/api/tags验证是否正常运行。
(2)克隆仓库
当前稳定版本需克隆localgpt-v2分支(主分支合并前的推荐分支):
git clone -b localgpt-v2 https://github.com/PromtEngineer/localGPT.git cd localGPT
3. 三种部署方式详细步骤
方式1:Docker部署(推荐,一键启动,适合非开发用户)
Docker部署无需手动配置依赖,直接启动完整服务:
确保Ollama服务已启动(参考基础环境步骤);
在LocalGPT目录下执行启动脚本:
./start-docker.sh
脚本会自动构建Docker镜像(前端、后端、RAG API),并启动所有服务;
验证服务启动:
前端:访问
http://localhost:3000(默认端口);后端健康检查:
http://localhost:8000/health;RAG API健康检查:
http://localhost:8001/health;停止服务:
./start-docker.sh stop
查看日志(排查问题用):
docker compose logs -f
方式2:直接开发部署(推荐开发者,适合二次开发/调试)
直接部署可修改代码,支持实时调试,步骤如下:
安装Python依赖:
pip install -r requirements.txt
核心依赖会自动安装(torch、lancedb、docling等),若安装失败可尝试
--force-reinstall参数重新安装;安装Node.js依赖(前端):
npm install
确保Ollama服务已启动(
ollama serve);启动LocalGPT系统:
python run_system.py
该脚本会自动启动四大服务:
Ollama Server(11434端口):模型服务;
RAG API Server(8001端口):文档处理与检索;
Backend Server(8000端口):会话与索引管理;
Frontend Server(3000端口):Web界面;
访问应用:打开浏览器输入
http://localhost:3000;高级启动参数(可选):
# 生产模式启动 python run_system.py --mode prod # 仅启动后端+RAG API,跳过前端 python run_system.py --no-frontend # 查看服务健康状态 python run_system.py --health # 查看日志 python run_system.py --logs-only # 停止所有服务 python run_system.py --stop
方式3:手动组件启动(适合高级用户,灵活调试单个组件)
手动启动可单独控制每个服务,便于定位问题:
启动Ollama服务(终端1):
ollama serve
启动RAG API(终端2):
python -m rag_system.api_server
启动后端服务(终端3):
cd backend && python server.py
启动前端服务(终端4):
npm run dev
访问应用:
http://localhost:3000。
4. 核心操作流程(Web界面)
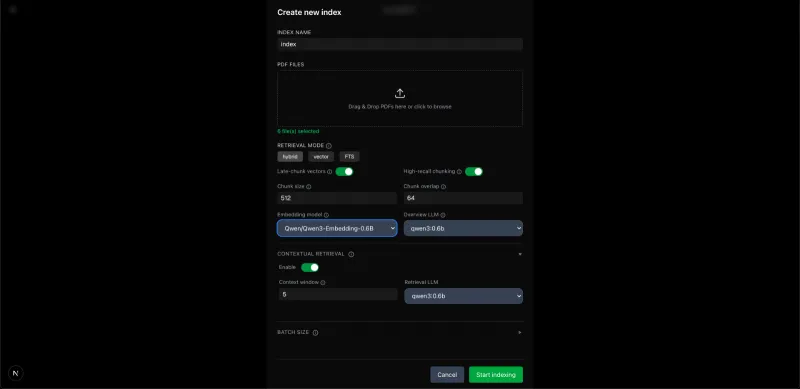
(1)创建文档索引(必需步骤)
索引是文档的“处理后版本”,聊天前需先创建索引:
打开
http://localhost:3000,点击“Create New Index”(创建新索引);输入索引名称(如“科研论文集”);
上传文档:拖拽PDF/DOCX/TXT等文件到上传区域,或点击浏览选择文件;
配置索引参数(可选):
检索模式:默认“hybrid”(混合搜索),可选“vector”(仅向量)、“FTS”(仅关键词);
分块大小:默认512(token数),分块重叠64;
模型选择:生成模型(默认qwen3:0.6b)、嵌入模型(默认Qwen/Qwen3-Embedding-0.6B);
启用上下文检索:建议开启,提升理解深度;
点击“Start indexing”(开始索引),等待处理完成(大文件需耐心等待,界面会显示进度)。
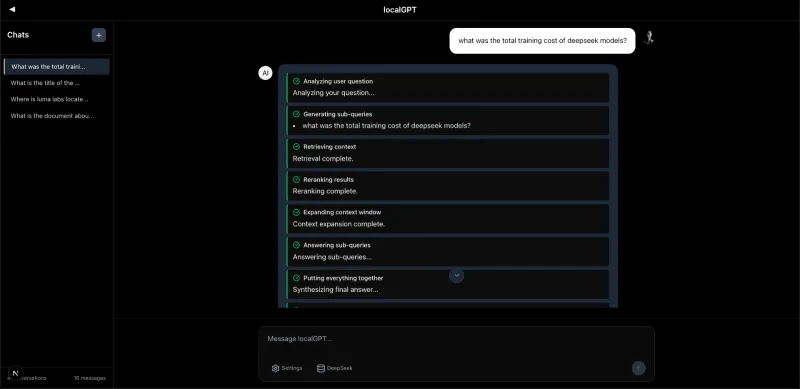
(2)开始聊天交互
索引创建完成后,点击“Chat with index”(与索引聊天);
选择要查询的索引(如“科研论文集”);
在输入框中输入自然语言查询(如“这篇论文的研究方法是什么?”“总结所有文档的核心结论”);
点击发送,模型会实时流式返回回答,同时显示来源文档引用;
支持连续对话:后续查询会自动关联之前的聊天历史,无需重复背景信息。
(3)API调用示例(开发者)
LocalGPT提供完整API,可通过代码调用,示例如下(Python):
import requests
# 1. 创建索引
create_index_response = requests.post(
"http://localhost:8000/indexes",
json={"name": "API测试索引", "description": "通过API创建的索引"}
)
index_id = create_index_response.json()["id"]
print(f"创建索引ID:{index_id}")
# 2. 上传文档
upload_response = requests.post(
f"http://localhost:8000/indexes/{index_id}/upload",
files={"files": open("test.pdf", "rb")}
)
print("文档上传结果:", upload_response.status_code)
# 3. 构建索引
build_response = requests.post(
f"http://localhost:8000/indexes/{index_id}/build",
json={"config_mode": "default", "chunk_size": 512}
)
print("索引构建结果:", build_response.status_code)
# 4. 聊天查询
chat_response = requests.post(
"http://localhost:8000/chat",
json={
"query": "文档的核心内容是什么?",
"session_id": "your-session-id",
"search_type": "hybrid",
"retrieval_k": 20
}
)
print("回答结果:", chat_response.json()["response"])5. 批量处理文档(高级功能)
通过配置文件实现批量文档索引,步骤如下:
编辑批量配置文件
batch_indexing_config.json:{ "index_name": "批量测试索引", "index_description": "批量处理示例", "documents": [ "./rag_system/documents/file1.pdf", "./rag_system/documents/file2.docx" ], "processing": { "chunk_size": 512, "chunk_overlap": 64, "enable_enrich": true, "enable_latechunk": true, "embedding_model": "Qwen/Qwen3-Embedding-0.6B", "generation_model": "qwen3:0.6b", "retrieval_mode": "hybrid" } }运行批量脚本:
python demo_batch_indexing.py --config batch_indexing_config.json
脚本会自动创建索引、上传文档、构建索引,完成后可在Web界面查看。
六、常见问题解答(FAQ)
Q1:Python版本符合要求,但安装依赖时提示torch安装失败?
A1:torch安装失败通常是网络问题或CUDA版本不匹配:
网络问题:使用国内镜像源安装,命令如下:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
CUDA版本不匹配:若无需GPU加速,可安装CPU版本torch:
pip install torch==2.4.1+cpu -f https://download.pytorch.org/whl/cpu/torch_stable.html
验证torch安装:
python -c "import torch; print(torch.__version__)",无报错则成功。
Q2:启动前端时提示“npm: 未找到命令”?
A2:Node.js安装后未配置环境变量:
Windows:安装Node.js时勾选“Add to PATH”,若未勾选,手动添加Node.js安装目录(如
C:\Program Files\nodejs)到系统环境变量;macOS/Linux:执行
export PATH="$PATH:/usr/local/bin/node"(临时生效),或编辑~/.bashrc/~/.zshrc添加永久环境变量。
Q3:Docker部署时提示“容器启动失败”?
A3:常见原因及解决方案:
Ollama未启动:先执行
ollama serve启动Ollama服务,再重新运行./start-docker.sh;端口占用:3000(前端)、8000(后端)、8001(RAG API)、11434(Ollama)端口被占用,关闭占用端口的程序,或修改
.env文件中的端口配置;Docker权限不足:Linux/macOS执行
sudo ./start-docker.sh,Windows以管理员身份运行PowerShell。
Q4:启动后提示“模型qwen3:0.6b未找到”?
A1:Ollama未成功下载模型,解决方案:
重新执行模型下载命令:
ollama pull qwen3:0.6b,确保网络通畅;验证模型是否存在:执行
ollama list,若列表中无目标模型,说明下载失败,检查网络或Ollama服务状态;若下载缓慢,可配置Ollama镜像源(参考Ollama官方文档)。
Q5:CPU模式运行时,回答速度极慢?
A2:CPU性能不足是主要原因,优化方案:
更换轻量模型:将生成模型改为更小巧的版本(如qwen3:0.6b,默认已配置),避免使用qwen3:8b等大模型;
调整分块大小:在创建索引时将分块大小调小(如256),减少单次处理的token数量;
启用语义缓存:确保
config.json中semantic_caching已启用,重复查询可直接返回缓存结果;升级硬件:条件允许时使用GPU(CUDA)模式,可大幅提升速度。
Q6:上传DOCX/HTML文件时提示“不支持的文件格式”?
A1:需确保启用了docling库支持,解决方案:
检查依赖:执行
pip list | grep docling,若未安装,执行pip install docling;确认代码版本:克隆
localgpt-v2分支(最新分支已支持多格式),旧分支可能仅支持PDF;查看文档大小:单个文件建议不超过100MB,过大文件可能解析失败。
Q7:回答没有来源归因,或来源标注错误?
A2:可能是索引构建不完整或检索参数配置不当:
重新构建索引:删除现有索引,重新上传文档并构建,确保索引过程无报错;
调整检索参数:在聊天时将
retrieval_k调大(如30),增加检索结果数量,提升来源匹配概率;启用重排序:确保
config.json中reranker.enabled为true,重排序可提升来源相关性。
Q8:会话历史无法保存,关闭页面后聊天记录消失?
A3:LocalGPT的会话历史仅保存在当前会话中(内存级存储),解决方案:
长期保存需求:使用API调用时,自行将会话历史存储到本地数据库(如MySQL、MongoDB);
避免刷新页面:当前会话未结束时,不要刷新浏览器,否则会话历史会丢失;
未来版本计划:官方已提及将支持会话持久化存储,可关注仓库更新。
Q9:批量处理大文档时,内存占用过高导致程序崩溃?
A1:优化内存占用方案:
分批处理:避免一次性上传过多文档,分多次创建索引;
调整批量大小:修改
batch_indexing_config.json中的batch_size为较小值(如4);关闭不必要功能:构建索引时禁用
enable_enrich(上下文增强)、enable_latechunk(延迟分块),减少内存消耗;环境变量优化:执行
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512(GPU模式)或export OMP_NUM_THREADS=4(CPU模式),限制资源占用。
Q10:Web界面响应缓慢,点击按钮无反应?
A2:可能是服务未完全启动或网络问题:
检查服务状态:执行
python run_system.py --health,确保所有服务(后端、RAG API、前端)均为“healthy”;清除浏览器缓存:浏览器缓存可能导致界面加载异常,清除缓存后重新访问;
检查日志:执行
python run_system.py --logs-only,查看是否有报错信息,针对性解决。
七、相关链接
GitHub仓库地址:https://github.com/PromtEngineer/localGPT
八、总结
LocalGPT是一款以“数据隐私”为核心竞争力的开源文档智能平台,通过本地部署、混合搜索引擎、智能路由与多格式文档处理能力,实现了“隐私安全”与“功能强大”的平衡,既解决了传统云文档工具的数据泄露风险,又通过AI技术提升了文档交互的效率与精准度。其模块化架构支持灵活部署与二次开发,兼容多计算平台与开源模型,适配企业、科研机构、个人用户等不同场景,且部署流程简单、界面直观,无需专业技术背景也能快速上手。作为一款持续迭代的开源项目,LocalGPT在文档智能领域为隐私敏感型用户提供了可靠的解决方案,是平衡隐私保护与AI效率的优质选择。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/localgpt.html





