MemMachine:开源 AI 智能体通用内存层,支持多类型记忆与跨会话持久化
一、MemMachine是什么
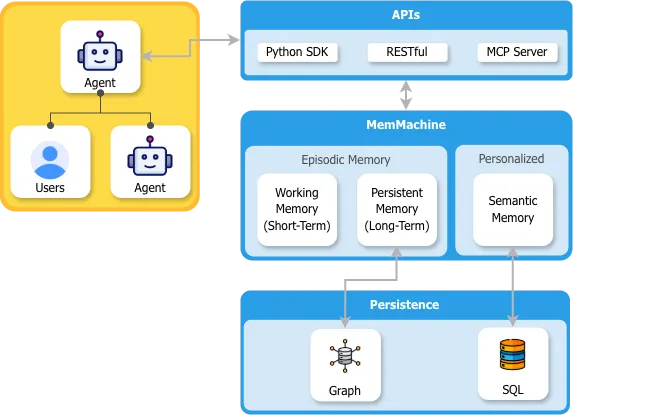
MemMachine是一款面向AI智能体的开源通用内存层工具,支持工作(短期)、持久(长期)、个性化(档案)三类记忆,可通过Python SDK、RESTful接口及MCP服务器实现便捷集成;其内存层可跨多个会话、代理及大语言模型持久化,将情景记忆存储于图数据库、档案记忆存储于SQL数据库,能为AI应用构建持续进化的用户档案,助力AI助手实现上下文感知的个性化交互,同时提供Docker容器与Python包两种部署方式,适配AI代理开发者与认知模型研究者的多元需求,遵循Apache 2.0开源协议。
在AI智能体技术快速落地的过程中,传统AI应用普遍存在“会话失忆”“交互无个性化”“跨模型数据割裂”的痛点:AI聊天机器人无法记住用户过往的偏好与对话细节,多智能体协作时难以共享用户档案,不同大语言模型间的交互数据也无法统一管理,导致AI应用的交互体验始终停留在“单次应答”层面,无法实现深度的个性化服务。
MemMachine正是为解决上述痛点而生的开源项目,该项目的核心价值在于让AI驱动的应用具备“学习、存储、回忆”的能力:既能留存过去会话中的数据与用户偏好,又能跨会话、跨智能体、跨大语言模型实现记忆持久化,进而构建出复杂且持续进化的用户档案,将传统的通用AI聊天机器人转化为个性化、上下文感知的专业AI助手。
二、功能特色
MemMachine的功能围绕“AI智能体记忆全生命周期管理”展开,兼顾技术实用性与开发者易用性,核心特色可分为5个维度:
1. 多维度记忆类型覆盖
MemMachine支持三类核心记忆,可满足AI智能体在不同场景下的记忆需求,实现从短期会话到长期档案的全场景覆盖:
工作记忆(短期):用于存储单次会话内的即时交互数据,如用户当前的咨询问题、AI的临时应答草稿等,会话结束后可按需清理,适配实时性强的短时交互场景。
持久记忆(长期):用于留存跨会话的核心信息,如用户过往的重要咨询记录、AI执行任务的历史结果等,数据会持久化存储,支持智能体跨时间维度调取信息。
个性化记忆(档案):用于构建专属用户档案,整合用户的偏好、身份信息、历史行为特征等,例如记录用户的医疗史、财务风险偏好、内容写作风格等,让AI助手的服务具备强个性化属性。
2. 开发者友好的多接口适配
为降低集成门槛,MemMachine提供三种主流的交互接口,适配不同技术栈的开发需求:
Python SDK:专为Python开发者设计,封装了记忆存储、检索、更新的核心方法,可直接嵌入AI智能体的Python代码中,无需复杂的接口调用逻辑。
RESTful接口:支持跨语言、跨平台调用,无论开发者使用Java、JavaScript还是Go语言,都可通过HTTP请求实现与MemMachine的交互,适配分布式AI系统的集成需求。
MCP服务器接口:可对接符合MCP协议的AI工具链,拓展MemMachine在专业AI工作流中的应用场景,提升工具链的记忆协同能力。
3. 跨会话/代理/模型的记忆持久化
这是MemMachine的核心竞争力之一,其记忆层可打破三类壁垒:
跨会话壁垒:用户在周一与AI助手咨询的财务问题,周三再次对话时,AI可直接调取周一的咨询记录,无需用户重复说明。
跨智能体壁垒:电商场景中,售前客服智能体记录的用户尺码偏好,可同步至售后客服智能体,实现全链路服务的信息互通。
跨大语言模型壁垒:用户在GPT-4中建立的内容写作风格档案,切换至Claude模型后,仍可沿用该档案,保障多模型协作的服务一致性。
4. 分层化的记忆管理架构
MemMachine采用“接口层-内存管理层-数据持久层”的三层架构,各层职责清晰且解耦,既保障了系统的稳定性,又便于功能拓展:
接口层负责接收智能体的调用请求,统一请求格式与异常处理;
内存管理层负责区分记忆类型、处理记忆的存储与检索逻辑;
数据持久层负责将不同类型的记忆存储至匹配的数据库,实现数据的安全留存。

三、技术细节
MemMachine的技术设计兼顾“功能适配性”与“开发扩展性”,以下从核心架构、技术栈选型、数据持久化方案三个维度解析其技术细节:
1. 核心架构设计
MemMachine的三层架构逻辑可拆解为具体的业务流转流程,完整链路如下:
用户与智能体交互:用户向AI智能体发起请求(如咨询财务投资建议),智能体通过Python SDK、RESTful接口或MCP服务器连接MemMachine核心。
内存管理层处理数据:MemMachine接收请求后,会自动识别数据类型——将即时对话内容归类为情景记忆,将用户的风险承受能力归类为档案记忆,同时为短期交互数据分配工作内存。
数据持久化存储:将情景记忆存储至图数据库(便于关联会话上下文),将档案记忆存储至SQL数据库(便于结构化查询与更新),工作内存则按需存储至缓存中。
记忆检索与反馈:当智能体需要调取记忆时,MemMachine会根据检索条件,从对应数据库中提取数据并返回,助力智能体生成个性化应答。
2. 技术栈选型
MemMachine针对不同模块的功能需求,采用了差异化的技术栈,既保障了性能,又适配了AI场景的技术生态,具体选型如下表所示:
| 模块名称 | 核心技术栈 | 选型原因 |
|---|---|---|
| 核心逻辑层 | Python、FastAPI | Python拥有丰富的AI开发工具链,FastAPI可实现高性能的接口服务,保障高并发场景下的响应速度 |
| 接口适配层 | Python SDK、FastAPI(RESTful)、MCP协议 | Python SDK降低Python开发者的集成门槛,FastAPI保障RESTful接口的稳定性,MCP协议拓展专业工作流适配能力 |
| 数据持久层 | 图数据库、SQL数据库、Redis(缓存) | 图数据库适配情景记忆的上下文关联检索,SQL数据库适配档案记忆的结构化管理,Redis保障工作内存的高速读写 |
| 部署模块 | Docker、Docker Compose | 容器化部署可实现环境隔离,支持CPU/GPU双镜像,适配不同算力环境的部署需求 |
| 依赖管理 | uv、pyproject.toml | uv是高性能的Python包管理器,可提升依赖安装与更新效率,pyproject.toml实现依赖的标准化管理 |
3. 开发与协作规范
为保障项目的可持续维护,MemMachine制定了完善的开发规范:
代码风格:遵循STYLE_GUIDE.md的要求,保障代码的可读性与一致性,同时通过自动化工作流实现代码格式校验。
贡献流程:区分核心代码贡献(CONTRIBUTING-CORE.md)与文档贡献(CONTRIBUTING-DOCS.md),核心代码贡献需经过PR审核、依赖冲突检测等流程。
版本管理:采用基于主干的开发策略,维护者通过分支管理实现功能迭代与版本发布,截至目前已完成7个版本的迭代,最新版本v0.1.6优化了会话数据的头信息传递功能。
四、应用场景
MemMachine的多类型记忆与持久化能力,可适配多领域的AI应用需求,以下是4个典型场景的详细落地说明:
1. CRM智能代理
在企业销售场景中,传统CRM系统仅能存储客户的基础信息,无法关联销售与客户的全量对话记录。集成MemMachine后,CRM智能代理可实现两大核心能力:
自动记录客户的完整沟通历史,包括客户对产品的疑问、价格敏感度、决策关键人等细节;
实时同步客户的交易阶段,当客户从“初步咨询”进入“方案洽谈”阶段时,代理可主动调取过往沟通中的核心诉求,辅助销售团队精准制定方案,加速成交流程。
2. 医疗导航助手
在医疗服务场景中,患者往往需要向不同科室的医护人员重复说明病史,既降低服务效率,又影响就医体验。基于MemMachine的医疗导航助手可:
建立患者专属的医疗档案,存储患者的过往病史、过敏史、用药记录、治疗进度等信息;
跨科室同步档案数据,患者从内科转诊至外科时,外科医生可直接通过助手调取完整医疗档案,实现诊疗服务的无缝衔接。
3. 个人财务顾问
个人财务咨询的核心是“基于用户历史数据的个性化建议”,MemMachine可助力财务顾问AI实现:
记忆用户的投资组合(如股票、基金的持仓比例)、风险承受能力(如保守型、进取型)、过往收益情况等核心数据;
当市场行情变动时,AI可结合用户的历史档案,生成针对性的调仓建议,而非提供通用的市场分析,提升财务咨询的专业度与个性化。
4. 专业内容写作助手
在企业文档创作场景中,不同员工撰写的文档往往存在风格不统一的问题。MemMachine赋能的内容写作助手可:
记忆企业的专属风格指南(如术语规范、排版要求、语气调性)、过往文档的写作逻辑;
当员工撰写新文档时,助手可实时校验内容是否符合风格规范,同时调取历史文档中的术语与框架,保障全企业文档的一致性,提升内容创作效率。
五、使用方法
MemMachine提供Docker容器与Python包两种部署方式,同时配套了快速入门指南,以下是不同场景的详细使用步骤:
1. Docker容器部署(适配企业级分布式场景)
步骤1:环境准备
确保本地已安装Docker与Docker Compose,若未安装可参考Docker官方文档完成配置。
步骤2:拉取仓库与配置镜像
# 克隆核心仓库 git clone https://github.com/MemMachine/MemMachine.git cd MemMachine # 拉取最新Docker镜像 ./memmachine-compose.sh pull
步骤3:启动服务
根据算力环境选择启动命令,CPU环境执行:
docker-compose up -d memmachine-cpu
GPU环境执行:
docker-compose up -d memmachine-gpu
步骤4:验证服务可用性
访问http://localhost:8000/health,若返回“健康”状态,则说明服务启动成功。
2. Python包安装(适配开发者本地开发)
步骤1:环境准备
确保本地Python版本≥3.8,推荐使用虚拟环境隔离依赖:
# 创建虚拟环境 python -m venv memmachine-env # 激活虚拟环境(Windows) memmachine-env\Scripts\activate # 激活虚拟环境(Linux/Mac) source memmachine-env/bin/activate
步骤2:安装MemMachine包
pip install memmachine
步骤3:基础记忆操作示例
初始化内存层并完成记忆的存储与检索:
from memmachine import MemoryLayer
# 初始化内存层,指定情景记忆存储至图数据库、档案记忆存储至SQL数据库
memory = MemoryLayer(
episodic_db="neo4j://localhost:7687", # 图数据库地址
profile_db="postgresql://user:pass@localhost:5432/mem_db" # SQL数据库地址
)
# 存储用户档案记忆(财务风险偏好)
memory.store_profile(
user_id="U001",
data={"risk_tolerance": "保守型", "portfolio": ["国债", "货币基金"]}
)
# 存储用户情景记忆(财务咨询对话)
memory.store_episodic(
user_id="U001",
data="用户咨询2025年低风险理财方案",
metadata={"timestamp": "2025-12-05 10:30:00"}
)
# 检索用户的财务相关记忆
profile = memory.retrieve_profile(user_id="U001")
episodic = memory.retrieve_episodic(user_id="U001", keyword="低风险理财")
print("用户档案:", profile)
print("咨询记录:", episodic)3. 快速接入示例代理
若需快速体验行业代理功能,可直接运行examples目录下的示例代码,以CRM代理为例:
cd examples/crm_agent python run_agent.py
运行后即可启动CRM代理,体验客户历史记录的记忆与检索功能。
六、常见问题解答
Q1:Docker启动MemMachine时提示数据库连接失败怎么办?
A1:首先检查图数据库与SQL数据库的服务是否正常启动,确认数据库地址、端口、账号密码与docker-compose.yml中的配置一致;其次,若使用本地数据库,需确保数据库开启了远程访问权限;最后,可查看Docker日志(docker logs memmachine-cpu)定位具体错误,若为数据库版本不兼容,可更换为项目推荐的neo4j(6.0.2+)与PostgreSQL(14+)版本。
Q2:如何为MemMachine新增自定义记忆类型?
A2:MemMachine支持拓展记忆类型,只需两步操作:一是在src/memmachine/memory_types目录下新建自定义记忆类,继承BaseMemory基类并实现store()、retrieve()方法;二是在配置文件中注册该记忆类型,重启服务后即可调用新的记忆接口。
Q3:Python SDK调用时出现“会话数据未传递”的报错如何解决?
A3:该报错是因为v0.1.6版本新增了会话数据头信息传递功能,需在初始化MemoryLayer时指定session_id参数,或在请求头中携带X-Session-ID字段,示例如下:
memory = MemoryLayer( episodic_db="neo4j://localhost:7687", profile_db="postgresql://user:pass@localhost:5432/mem_db", session_id="S001" # 新增会话ID参数 )
Q4:MemMachine的记忆数据如何保障隐私安全?
A4:项目提供了三重隐私保障:一是支持本地部署数据库,避免数据上云的隐私泄露风险;二是支持数据加密存储,可在配置文件中开启字段级加密;三是提供访问权限控制,可通过用户ID实现记忆数据的专属访问,防止数据越权调取。
Q5:跨大语言模型的记忆同步如何实现?
A5:MemMachine通过标准化的记忆数据格式实现跨模型同步,其存储的用户档案与会话记忆均采用通用JSON格式,且提供了多模型的适配插件,只需在大语言模型的调用链中集成该插件,即可实现记忆数据的无缝同步。
七、相关链接
八、总结
MemMachine是一款定位精准、功能完备的开源AI智能体通用内存层工具,2025年10月13日发布后已迭代至v0.1.6版本,其核心价值在于通过工作、持久、个性化三类记忆的全周期管理,以及跨会话、跨智能体、跨大语言模型的记忆持久化能力,解决了传统AI应用“会话失忆”“服务无个性化”的痛点;从技术层面来看,它采用三层解耦架构,搭配Python SDK、RESTful等多接口与图数据库、SQL数据库的多存储方案,既保障了系统的稳定性与扩展性,又降低了开发者的集成门槛;同时项目提供了多领域的示例代理与完善的社区支持,适配AI代理开发者与认知模型研究者的多元需求,无论是企业级的CRM智能代理、医疗导航助手,还是个人开发者的内容写作助手,都可通过MemMachine实现记忆能力的赋能,是AI智能体实现上下文感知与个性化服务的优质开源解决方案。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/memmachine.html





