MuseTalk:腾讯音乐开源的AI音频驱动唇形同步生成模型
MuseTalk是什么
MuseTalk 是由腾讯音乐娱乐集团(TME)旗下 Lyra Lab 团队于2024年推出、2025年4月开源训练代码的实时高质量音频驱动唇形同步(Lip-Sync)模型,核心解决“输入任意音频,让视频中人物唇形与音频精准匹配”的技术痛点。
它并非传统扩散模型,而是基于ft-mse-vae 的 latent 空间单步修复(Inpainting) 架构,可修改未知人脸的唇形区域(256×256分辨率),支持多语言、实时推理与灵活参数调优,常与同团队开源的 MuseV(虚拟人生成模型)搭配,构成完整虚拟人解决方案。
核心定位:面向数字人直播、视频配音、虚拟主播、影视唇形修正等场景的端到端唇形同步生成工具,兼顾高保真视觉效果与低延迟实时性。

功能特色
MuseTalk 1.5 为当前稳定主力版本,功能覆盖多语言适配、实时推理、高保真生成、灵活调优、全链路开源五大核心能力,具体特色如下:
1. 多语言唇形同步(核心优势)
原生支持中文、英文、日语等多语言音频输入,适配不同语种的发音与唇形变化规律;
中文优化:针对声调语言特点,通过 Whisper-tiny 编码音素,精准匹配唇形开合度;
日语适配:内置五十音图唇形映射库,支持促音、长音等特殊发音的唇形还原。
2. 实时高帧率推理
硬件适配:在 NVIDIA Tesla V100 显卡上实现 30fps+ 实时推理,满足直播级低延迟需求;
帧率兼容:推荐输入 25fps 视频(与训练数据帧率一致),低帧率视频可通过 FFmpeg 插值转换;
速度优化:支持
--skip_save_images参数,跳过中间帧保存,进一步提升生成速度。
3. 高保真生成与身份一致性
分辨率精准:专注 256×256 人脸区域修改,非人脸区域保持原始画质,避免全局失真;
损失函数升级(1.5版本):融合感知损失、GAN 损失、唇形同步损失,提升清晰度、身份一致性与唇形精准度;
时空采样策略:训练时匹配头部姿态相近的参考帧,减少头部抖动,强化时序连贯性。
4. 灵活可调的生成控制
人脸中心点调整:支持自定义人脸区域中心点,直接影响唇形生成效果,适配不同脸型与角度;
bbox_shift参数:调整蒙版上界,正值增大嘴部开合度,负值减小,精准控制唇形幅度;多推理模式:支持标准推理、实时推理、Gradio可视化界面,满足调试、批量生成、零代码测试等不同需求。
5. 全链路开源与生态兼容
代码开源:2025年4月开源训练代码、推理代码、预处理代码,支持自定义数据训练;
权重开放:提供基于 HDTF 公开数据集+私有数据集训练的预训练权重,开箱即用;
生态适配:可与 MuseV 生成的虚拟人视频无缝衔接,快速构建“文生视频+唇形同步”的虚拟人内容流水线。
技术细节
MuseTalk 技术架构围绕** latent 空间修复核心设计,分为音频编码、图像编码、跨模态融合、唇形生成、损失函数、训练策略**六大模块,整体流程简洁高效、非扩散模型架构。
1. 整体架构(非扩散模型)
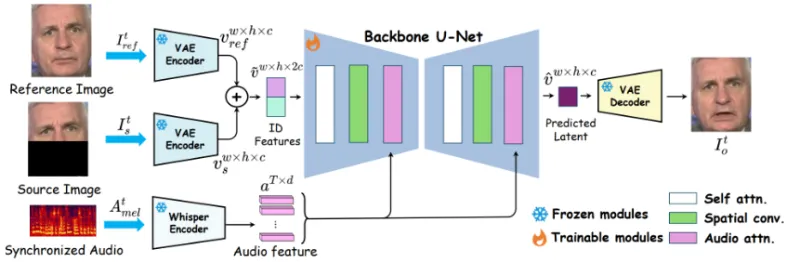
MuseTalk 借鉴 Stable Diffusion v1-4 的 UNet 架构,但非扩散模型,而是通过单步 latent 空间修复生成唇形:将人脸下半部分遮挡区域与参考图像编码到 latent 空间,用多尺度 UNet 融合音频-视觉特征,一次性输出修复后的唇形 latent 表示,再解码回图像空间。
2. 核心组件拆解
(1)图像编码(冻结VAE)
使用 冻结的 ft-mse-vae 对输入人脸图像编码,输出 4×4×768 维度的 latent 向量,保留人脸身份与纹理信息,避免编码过程破坏原始特征;
仅对人脸下半区域(唇形区) 进行修复,上半部分(眼睛、眉毛)直接复用原始 latent 特征,保证身份一致性。
(2)音频编码(Whisper-tiny)
采用 冻结的 whisper-tiny 模型,将输入音频(任意语言)编码为 50×384 维度的音频特征序列,提取音素、语速、语调等关键信息;
音频特征通过交叉注意力机制融入 UNet 各层,实现“音频驱动唇形”的跨模态对齐。
(3)UNet 融合网络(核心生成器)
基于 Stable Diffusion v1-4 UNet 改造,输入为“图像 latent(遮挡下半脸)+ 音频特征”,输出为“修复后唇形区域的 latent”;
多尺度特征融合:在 UNet 的下采样、中间层、上采样阶段均注入音频特征,确保不同尺度的唇形细节(如嘴角、牙齿)与音频精准同步。
(4)解码与后处理
将 UNet 输出的唇形 latent 与原始上半脸 latent 拼接,通过 ft-mse-vae 解码器还原为 256×256 人脸图像;
后处理:融合回原始视频帧,通过人脸对齐、边缘平滑消除修复区域与原始区域的接缝,提升自然度。
3. 1.5版本关键技术升级
(1)损失函数组合(核心提升)
感知损失(Perceptual Loss):基于 VGG16 特征匹配,提升生成图像的清晰度与纹理细节;
GAN 损失:对抗训练减少伪影,增强唇形区域的真实感;
唇形同步损失(Sync Loss):计算预测唇形与音频音素的对齐误差,确保口型与发音精准匹配。
(2)两阶段训练策略
第一阶段:用 L1 损失+感知损失 训练基础模型,优先保证图像质量;
第二阶段:加入 GAN 损失+同步损失 微调,平衡视觉质量与唇形同步精度,避免“画质好但口型不准”或“口型准但画质模糊”的问题。
(3)时空数据采样
训练时为每个目标帧筛选头部姿态(角度、俯仰)相近的参考帧,减少头部抖动;
时间维度上采样连续帧序列,强化唇形动作的时序连贯性,避免跳变。
4. 硬件与环境要求
最低配置:NVIDIA RTX 3090/4090(24GB显存),Python ≥3.10,CUDA 11.7;
推荐配置:NVIDIA Tesla V100/A100(32GB+显存),支持 30fps+ 实时推理;
依赖库:torch、torchvision、transformers、opencv-python、ffmpeg、mmcv、mmdet、mmpose 等。
应用场景
MuseTalk 聚焦音频驱动唇形同步核心能力,适配内容创作、虚拟人直播、影视后期、教育培训、数字政务五大高价值场景,落地门槛低、效果直观。
1. 虚拟人直播/短视频(最主流)
搭配 MuseV 生成虚拟人形象,输入任意语音(如带货话术、知识讲解),实时生成唇形同步的虚拟人视频,用于抖音、快手、视频号直播/短视频;
优势:低延迟(30fps+)、多语言、身份一致,虚拟人唇形自然无违和。
2. 视频配音/多语言本地化
对已有视频(如课程、广告、纪录片)进行多语言配音,自动生成与新音频匹配的唇形,无需重拍;
案例:中文视频转英文/日语版本,唇形精准对齐外语发音,降低本地化成本。
3. 影视后期唇形修正
修复拍摄时口型与台词不符、配音与唇形错位的问题,尤其适用于特写镜头;
优势:仅修改唇形区域,保留原始表情、光影、画质,无明显修图痕迹。
4. 语言教育/培训视频
生成标准发音+精准唇形的教学视频(如英语音标、日语五十音、中文拼音),帮助学习者通过口型模仿纠正发音;
支持慢速唇形、逐音分解,适配零基础学习场景。
5. 数字人客服/政务播报
构建7×24小时数字人客服,输入咨询语音实时生成唇形同步回复视频;
用于政务大厅、银行网点的数字人播报员,播报政策、业务指引等内容。
使用方法
MuseTalk 提供标准推理、实时推理、Gradio可视化界面三种使用方式,支持 Windows/Linux 系统,新手推荐 Gradio 界面,批量生成用标准推理,直播场景用实时推理。
1. 环境准备(必做)
(1)克隆仓库
git clone https://github.com/TMElyralab/MuseTalk.git cd MuseTalk
(2)安装依赖
# 安装Python依赖 pip install -r requirements.txt # 安装MIM依赖(mmcv/mmdet/mmpose) pip install --no-cache-dir -U openmim mim install "mmcv>=2.0.1" mim install "mmdet>=3.1.0" mim install "mmpose>=1.1.0"
(3)下载FFmpeg
下载
ffmpeg-static,设置环境变量:
# Linux/Mac export FFMPEG_PATH=/path/to/ffmpeg # Windows # 直接将ffmpeg.exe放入项目目录,或添加到系统PATH
(4)下载预训练权重
运行脚本自动下载(推荐):
# Linux/Mac ./download_weights.sh # Windows download_weights.bat
权重目录结构(自动生成):
/models/ ├── musetalkV15/ # MuseTalk 1.5权重 ├── dwpose/ # 姿态检测权重 ├── face-parse-bisent/ # 人脸解析权重 ├── sd-vae-ft-mse/ # VAE权重 └── whisper/ # Whisper-tiny权重
2. 方式一:Gradio可视化界面(新手推荐)
零代码操作,支持参数调整、实时预览、效果调试:
# 启动界面 python app.py --use_float16 --ffmpeg_path /path/to/ffmpeg
访问地址:
http://localhost:7860操作步骤:
上传输入视频/图片(支持256×256人脸);
上传音频文件(中文/英文/日语,任意时长);
调整参数:
bbox_shift(唇形开合度)、face_center(人脸中心点);点击“生成”,预览效果并下载视频。
3. 方式二:标准推理(批量生成)
适合一次性生成多个视频,支持自定义配置文件:
# Linux(1.5版本推荐) sh inference.sh v1.5 normal # Windows python -m scripts.inference ^ --inference_config configs/inference/test.yaml ^ --result_dir results/test ^ --unet_model_path models/musetalkV15/unet.pth ^ --version v15
配置文件
configs/inference/test.yaml关键参数:
video_path: "input/test_video.mp4" # 输入视频路径 audio_path: "input/test_audio.wav" # 输入音频路径 bbox_shift: 0 # 唇形开合度,-9~9 face_center: [128, 128] # 人脸中心点,256×256默认居中 output_fps: 25 # 输出帧率,推荐25fps
4. 方式三:实时推理(直播场景)
低延迟生成,适配数字人直播:
# Linux sh inference.sh v1.5 realtime # Windows python -m scripts.realtime_inference ^ --inference_config configs/inference/realtime.yaml ^ --preparation True # 新虚拟人设为True,复用设为False
关键参数:
--preparation True:首次处理新虚拟人,初始化模型缓存;--skip_save_images:不保存中间帧,提升速度至30fps+。
5. 最佳实践(提升效果)
输入视频:优先 25fps、256×256人脸、正面/小角度,避免侧脸、遮挡、模糊;
音频:清晰无杂音、音量适中,中文避免强背景音;
参数调优:
嘴部偏小:
bbox_shift=3~6;嘴部偏大:
bbox_shift=-3~-6;侧脸:调整
face_center向人脸偏移侧移动。
竞品对比
选取行业内主流开源/闭源唇形同步模型:Wav2Lip(开源标杆)、LatentSync( latent空间竞品)、MuseTalk(腾讯开源),从核心能力、技术、效果、速度、开源性五大维度对比,清晰凸显 MuseTalk 优势。
| 对比维度 | MuseTalk(腾讯,1.5) | Wav2Lip(开源标杆) | LatentSync( latent空间) |
|---|---|---|---|
| 核心定位 | 实时高保真多语言唇同步,虚拟人适配 | 高精度唇同步,通用场景 | latent空间唇同步,细节可控 |
| 技术架构 | 非扩散,latent空间单步修复+UNet | 3D人脸重建+光流对齐 | 扩散模型,latent空间生成 |
| 多语言支持 | 原生支持中/英/日,声调语言优化 | 英文为主,中文适配一般 | 英文为主,中文需微调 |
| 生成分辨率 | 256×256(人脸精准区) | 任意分辨率(全局修改) | 512×512(全局修改) |
| 视觉质量 | 感知/GAN/同步损失,清晰度高、身份一致 | 唇形准但画质模糊、易失真 | 细节细腻但易有伪影、速度慢 |
| 推理速度(V100) | 30fps+(实时) | 10~15fps(非实时) | 5~8fps(慢) |
| 开源性 | 完全开源(训练+推理+权重) | 完全开源(推理为主,训练有限) | 开源推理,训练代码未开源 |
| 生态适配 | 与MuseV无缝衔接,虚拟人全链路 | 独立模型,无配套生成工具 | 独立模型,无配套生态 |
| 适用场景 | 数字人直播、实时配音、虚拟主播 | 视频配音、影视修正(非实时) | 高精度短视频、艺术创作 |
结论:MuseTalk 在实时性、多语言适配、虚拟人生态、开源完整性四大维度显著领先,平衡“速度+质量+易用性”,是数字人直播/实时配音场景的最优开源选择;Wav2Lip 胜在通用稳定性但速度慢;LatentSync 细节好但无法实时推理。
常见问题解答(FAQ)
Q1:MuseTalk 和 MuseV 有什么区别?可以一起用吗?
A:MuseV 是虚拟人图像/视频生成模型(文生图、图生视频),负责生成虚拟人形象;MuseTalk 是唇形同步模型,负责给虚拟人匹配音频唇形。两者同属腾讯 Lyra Lab 开源项目,可无缝搭配:用 MuseV 生成虚拟人视频,再用 MuseTalk 做唇形同步,快速构建完整虚拟人内容流水线。
Q2:MuseTalk 支持中文方言吗?比如粤语、四川话?
A:原生支持标准普通话,粤语、四川话等方言可通过微调适配:需准备方言音频+唇形视频数据,用 MuseTalk 开源训练代码微调模型,即可实现方言唇形同步;官方暂未提供方言预训练权重。
Q3:为什么生成的视频唇形很准,但画质模糊、有伪影?
A:主要原因有3点:
输入视频分辨率低、模糊、人脸遮挡,模型难以提取清晰特征;
bbox_shift参数过大/过小,导致唇形区域修复异常;显存不足(<24GB),推理时启用低精度压缩,损失画质。
解决方法:用256×256清晰人脸视频、调小bbox_shift范围、使用24GB+显存显卡。
Q4:MuseTalk 可以在 CPU 上运行吗?
A:不推荐,且速度极慢。MuseTalk 基于 PyTorch 与 CUDA 加速,CPU 推理1秒视频需数分钟,完全无法使用;最低硬件要求为 NVIDIA RTX 3090/4090(24GB显存),推荐 Tesla V100/A100 以实现30fps+实时推理。
Q5:训练自己的自定义模型需要什么数据?
A:需准备配对数据:人脸视频(25fps、256×256)+ 对应音频(清晰无杂音),数据量建议≥10小时(覆盖不同表情、角度、语速);训练时需按官方文档预处理(人脸检测、姿态对齐、音频编码),再用开源训练代码启动训练。
Q6:生成的视频人脸会变形、身份不一致,怎么解决?
A:核心原因是模型过度修改人脸非唇形区域。解决方法:
确保输入视频人脸正面、无大角度偏转;
降低
bbox_shift绝对值,减少唇形区域修改范围;使用1.5版本(强化身份一致性损失),避免用1.0基础版。
相关链接
GitHub 仓库(主项目):https://github.com/TMElyralab/MuseTalk
HuggingFace 在线演示(零代码测试):https://huggingface.co/spaces/TMElyralab/MuseTalk
技术论文(arXiv):https://arxiv.org/abs/2410.10122
MuseV 配套项目(虚拟人生成):https://github.com/TMElyralab/MuseV
官方权重下载(HuggingFace):https://huggingface.co/TMElyralab/MuseTalk
总结
MuseTalk 是腾讯音乐娱乐集团 Lyra Lab 团队推出的实时高保真音频驱动唇形同步开源模型,以 latent 空间单步修复技术为核心,突破了传统唇同步模型“速度慢、多语言适配差、画质与精度难平衡”的痛点,在30fps+实时推理、中/英/日多语言原生支持、256×256人脸区域精准生成、全链路开源(训练+推理+权重)等方面形成显著优势,与 MuseV 虚拟人生成模型无缝衔接,构建了从虚拟人形象生成到唇形同步的完整技术生态,广泛适配数字人直播、视频配音、影视后期、语言教育等多元场景,为AI内容创作领域提供了一套低成本、高效率、高效果的实时唇同步解决方案,也为国内开源虚拟人技术的普及与创新提供了重要支撑。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/musetalk.html