Open-LLM-VTuber:开源AI虚拟主播系统,支持离线语音交互与Live2D形象驱动
一、Open-LLM-VTuber 是什么
Open-LLM-VTuber 是一款完全开源、模块化的本地离线AI虚拟主播/虚拟形象交互系统,基于大语言模型、语音识别、语音合成、Live2D动效等技术打造,面向个人爱好者、直播创作者、AI开发者、桌面趣味互动用户设计。项目全程开源免费,遵循开源协议,支持跨平台部署,兼顾离线本地运行与云端API对接两种模式,低配设备、高性能主机均可适配。
该项目打破了传统虚拟主播工具闭源、收费、依赖联网的痛点,将ASR语音识别、LLM大模型对话、TTS语音合成、Live2D虚拟形象驱动、视觉感知、长期记忆等能力整合为一体化解决方案。用户无需专业动捕设备、高额付费软件,仅依靠普通电脑即可搭建属于自己的AI虚拟形象,实现语音对话、桌面桌宠、直播互动、智能陪伴等多种玩法。
项目整体采用前后端分离架构,代码完全公开可二次开发,开发者可基于现有模块进行功能改造、模型替换、界面定制,是目前社区活跃度较高的开源VTuber解决方案之一。

二、功能特色
Open-LLM-VTuber 功能划分清晰,覆盖语音交互、虚拟形象、视觉能力、运行模式、拓展工具五大板块,全部功能开箱即用,同时支持自定义配置,核心特色如下:
2.1 全链路实时语音交互
双向语音对话:集成完整ASR语音转文字、LLM智能对话、TTS文字转语音链路,支持免手动输入,全程语音聊天。
语音打断功能:支持对话过程中随时插话,模拟真人交流逻辑,交互体验更自然。
多语音引擎适配:兼容主流本地TTS与云端语音接口,可自由切换音色、语速、语调。
2.2 专业 Live2D 虚拟形象驱动
标准模型兼容:原生支持 Live2D Cubism 5 格式模型,市面上通用二次元虚拟形象均可直接导入使用。
唇形&表情同步:对话过程中虚拟形象自动匹配口型、表情、肢体动作,动态效果连贯自然。
桌面桌宠模式:支持透明悬浮窗口,虚拟形象常驻桌面,不遮挡桌面操作,兼具娱乐与陪伴属性。
2.3 多维度视觉感知能力
摄像头接入:调用电脑摄像头捕捉画面,实现视觉互动,虚拟形象可对画面内容做出对应回应。
屏幕画面截取:支持截取桌面、指定窗口画面,结合大模型实现看图对话、画面解读等多模态交互。
2.4 灵活的运行与部署模式
纯本地离线运行:所有AI模型、语音、形象资源均可部署在本地,无需联网,保护隐私且不受网络限制。
云端API兼容:低配电脑可选择对接主流大模型云端接口,降低本地硬件压力,入门门槛极低。
跨平台支持:全面适配 Windows、macOS、Linux 三大主流桌面系统,同时兼容NVIDIA显卡、AMD显卡、Apple Silicon芯片以及纯CPU运行环境。
2.5 实用拓展功能
长期记忆模块:自动保存历史对话内容,虚拟形象可记住过往聊天信息,延续对话语境。
直播间弹幕互动:对接主流直播平台,自动抓取直播间弹幕并由虚拟形象实时回应,适配直播场景。
工具调用能力:支持基础外部工具调用,可拓展实现网页浏览、指令执行等进阶操作。
中文原生适配:界面、语音、对话逻辑均深度优化中文使用场景,国内用户上手无语言障碍。
三、技术细节
本项目技术栈分工明确,模块化设计降低了学习与二次开发难度,整体技术架构分为后端服务层、AI能力层、虚拟形象层、前端交互层四大模块,以下为详细技术拆解。
3.1 整体架构设计
项目采用前后端分离架构,后端负责AI推理、语音处理、数据交互、硬件调度;前端负责界面展示、Live2D渲染、用户操作交互。前后端通过标准接口通信,解耦性强,开发者可单独替换前端界面或后端服务。
3.2 核心技术栈
后端开发技术
后端主体基于 Python 开发,搭配主流AI生态库,稳定性与拓展性强,核心依赖框架:
FastAPI:构建高性能后端接口,负责模块间数据通信与请求调度 PyTorch/TensorRT:AI模型推理加速,提升本地大模型、语音模型运行效率 OpenCV:图像处理、摄像头画面捕获、屏幕截图功能实现 SQLite:轻量化本地数据库,存储对话记忆、配置文件、模型参数
AI能力模块技术选型
ASR语音识别:集成开源离线语音识别模型,支持本地转写,同时兼容各类云端语音识别API。
LLM大语言模型:无绑定限制,支持主流开源大模型本地部署,也可对接第三方云端大模型接口,用户可按需自由切换。
TTS语音合成:接入多款开源离线语音合成模型,支持音色自定义、音频参数调节。
虚拟形象渲染技术
虚拟形象部分基于 Live2D Cubism SDK 开发,遵循官方标准协议,支持模型动作分组、表情触发器、物理动效。渲染层采用轻量化图形库,保证低配置电脑也能流畅加载虚拟形象,同时实现窗口透明、置顶、缩放等窗口特性。前端交互技术
前端分为网页端与桌面客户端两个版本:网页端基于通用前端技术开发,浏览器直接打开即可使用;桌面客户端基于网页封装,实现本地窗口化运行,适配桌面交互逻辑。
3.3 运行硬件适配逻辑
项目针对不同硬件做了分层优化,自动适配运行策略:
独立显卡环境:自动启用GPU加速,大模型、语音模型、渲染任务全部交由显卡处理,响应速度最快。
Apple Silicon 设备:适配Metal加速框架,充分利用苹果芯片统一内存优势,运行流畅。
纯CPU/低配电脑:自动降参运行模型,或默认切换至云端API模式,保证基础功能可用。
3.4 数据与隐私机制
所有本地对话记录、配置文件、模型资源均保存在用户本地设备,数据不上传第三方服务器。离线模式下全程无网络请求,从底层保障用户隐私安全,适合注重数据保密的个人用户与工作室使用。
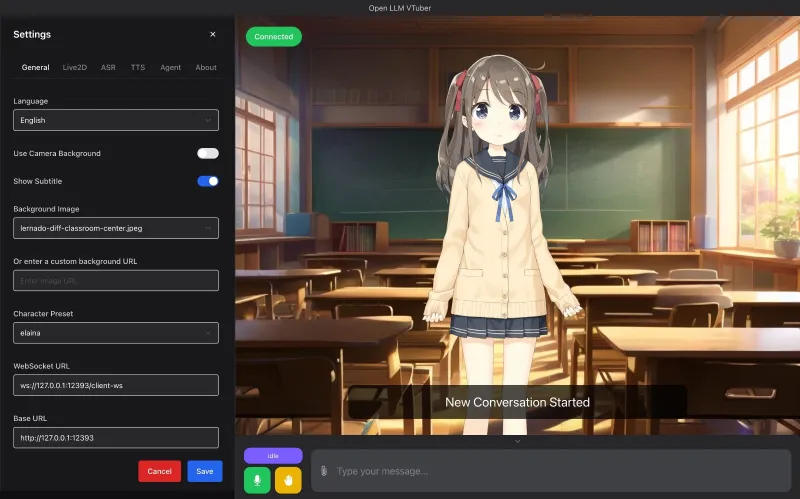
四、应用场景
Open-LLM-VTuber 凭借灵活的功能与部署方式,覆盖个人娱乐、直播创作、趣味办公、技术开发四大类场景,适用人群广泛。
个人AI智能陪伴
将虚拟形象设置为桌面常驻桌宠,依靠语音交互功能实现日常聊天、答疑、陪伴解闷,长期记忆功能可延续对话,打造专属个性化AI伙伴。自媒体/直播虚拟主播
直播从业者可导入自制Live2D模型,利用弹幕抓取+语音回应功能,实现全自动直播互动,替代真人出镜,降低直播运营成本,适合游戏直播、闲聊直播、电台类直播。桌面趣味互动与辅助
日常办公、学习时开启悬浮虚拟形象,可语音查询知识、设置提醒、解读屏幕内容,兼具趣味性与轻度办公辅助能力。AI技术学习与二次开发
对于AI开发者、编程爱好者,该项目是绝佳的学习案例。可基于现有代码研究ASR+LLM+TTS+多模态整合方案,也可二次开发定制专属虚拟形象系统、AI互动工具。小型展厅/门店智能引导
线下场景可部署大屏版本,搭配虚拟形象与语音交互,用作门店引导、简单咨询解答,打造轻量化智能接待形象。
五、使用方法
项目提供快速部署、本地运行、基础配置三套通用流程,分为新手简易流程与进阶自定义流程,操作门槛低,普通电脑用户也可完成部署。
5.1 前置准备
系统:Windows 10及以上、macOS、主流Linux发行版
环境:安装 Python 对应版本、Git 工具(源码部署必备)
资源:准备 Live2D Cubism 5 格式虚拟模型(可选,无模型可使用项目默认形象)
5.2 源码拉取(核心命令)
打开终端/命令提示符,执行以下命令拉取项目源码:
git clone https://github.com/Open-LLM-VTuber/open-llm-vtuber.git cd open-llm-vtuber
5.3 环境依赖安装
进入项目根目录,安装运行所需依赖库:
pip install -r requirements.txt
5.4 启动项目
后端启动:执行后端启动脚本,等待服务端口正常监听;
前端启动:打开桌面客户端或在浏览器访问本地服务地址,进入操作界面;
基础配置:
选择运行模式:本地模型 或 云端API;
导入Live2D模型(或使用默认模型);
开启麦克风、摄像头权限(按需选择);
开始使用:配置完成后,直接语音对话,测试形象动效、语音交互功能。
5.5 基础功能设置
桌宠模式:在界面开启「透明悬浮窗口」,虚拟形象置顶桌面;
语音设置:切换TTS音色、调节音量、语速;
记忆功能:开启/关闭对话历史记忆,手动清空历史记录;
直播配置:填入直播平台信息,开启弹幕监听功能。
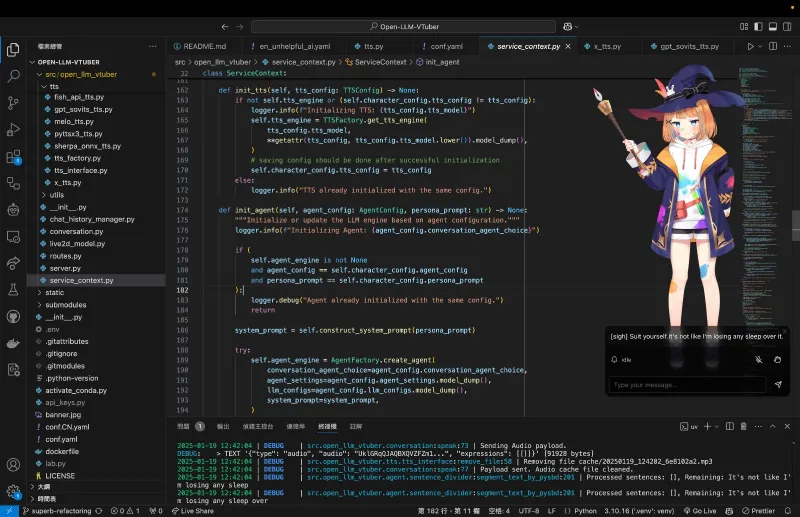
六、常见问题解答
1. 项目必须联网才能使用吗?
不需要。该项目完整支持本地离线运行,提前下载好对应的大模型、语音模型后,断开网络依然可以正常使用语音对话、虚拟形象交互等全部核心功能。仅当选择对接云端API、抓取直播弹幕时,才需要网络。
2. 电脑配置很低,能不能正常运行?
可以。项目做了全面的低配适配,低配置电脑可以放弃本地模型部署,切换为云端大模型API模式,仅运行虚拟形象与本地界面,硬件压力极小,普通办公电脑即可流畅使用。
3. 支持自定义自己制作的Live2D模型吗?
支持。项目原生兼容 Live2D Cubism 5 标准格式模型,你可以将自制或下载的合规模型导入项目文件夹,在设置界面选择加载,即可替换默认虚拟形象,表情、动作、唇形同步均可正常生效。
4. 运行时麦克风没有声音、无法语音识别怎么办?
首先检查电脑系统麦克风权限是否开启,确认终端/客户端已获取麦克风权限;其次在项目设置中核对ASR语音识别引擎是否选择正确;最后重启后端服务与前端界面,重新尝试即可。
5. 苹果Mac设备可以部署使用吗?
可以。项目专门适配 macOS 系统与Apple Silicon芯片,自带硬件加速优化,按照Linux类部署流程操作即可,整体运行体验稳定。
6. 对话记录会被上传到第三方服务器吗?
不会。所有对话记录、配置文件全部存储在用户本地设备的数据库中,离线模式下无任何网络数据传输,云端API模式仅传输对话文本至你自主选择的大模型服务商,项目本身不收集、不上传用户数据。
7. 新手看不懂代码,有没有图形化简易版本?
有。项目除了源码部署版本外,还提供封装好的桌面客户端,拥有完整图形化操作界面,无需操作代码,点击即可完成配置、切换功能,适合纯新手用户。
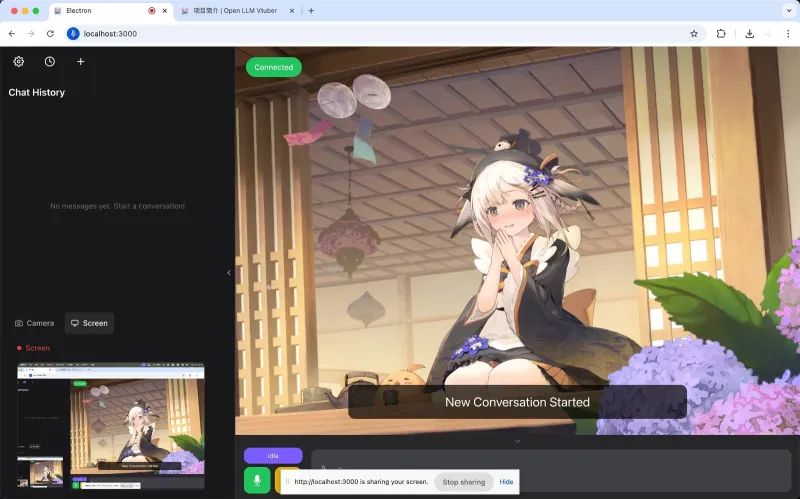
七、相关链接
Github仓库地址:https://github.com/Open-LLM-VTuber/open-llm-vtuber
项目官方文档站点:http://docs.llmvtuber.com/docs/
八、总结
Open-LLM-VTuber 是一套功能完整、架构成熟、适配性极强的开源AI虚拟主播与虚拟形象交互系统,它整合了语音识别、大语言模型、语音合成、Live2D渲染、视觉感知等多项主流AI技术,打破了传统虚拟形象工具收费、闭源、依赖网络的局限。项目跨平台兼容各类硬件设备,同时区分普通用户与开发者使用场景,既可以让零基础用户快速搭建桌面AI伙伴、直播虚拟主播,也能为技术爱好者提供优质的开源学习与二次开发范本。凭借全离线运行、隐私安全、模块化拓展、中文深度适配等亮点,该项目在开源VTuber领域具备很高的实用价值与社区价值,覆盖娱乐、直播、办公、技术研发等多元使用场景,是当下综合表现出色的免费开源虚拟形象解决方案。
相关软件下载

Open-LLM-VTuber
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/open-llm-vtuber.html