PawBench:阿里通义开源的全链路AI智能体自动化评测基准
一、PawBench 是什么
PawBench 是由阿里通义实验室旗下 AgentScope 团队推出的开源AI智能体系统评测基准,托管于 GitHub 平台,专为完整 AI Agent 链路打造综合能力评测体系。
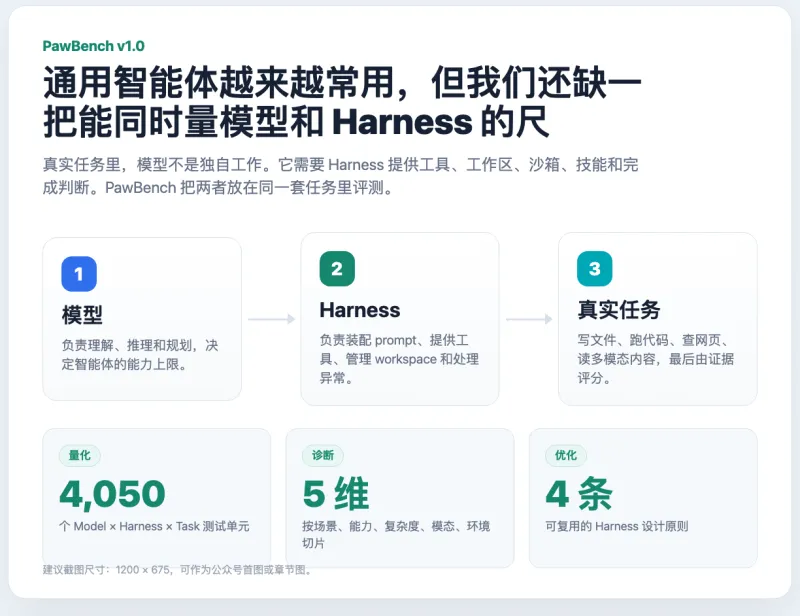
传统大模型评测大多仅针对模型本身的文本理解、问答、推理能力进行单项打分,忽略了模型、运行框架、实际业务任务三者结合后的整体表现。而 PawBench 跳出单一模型评测的局限,采用三维交叉评测理念,将大语言模型、智能体运行框架、真实落地任务融为一体,实现对整套 AI 智能体解决方案的全维度量化评估。
该项目首发版本内置海量真实场景测试用例,面向个人助理、自动化办公、工具调用、复杂决策等主流 Agent 应用场景设计测试任务,不仅能衡量基座大模型的能力上限,还可检测智能体框架的工程稳定性、任务调度能力、多工具协同适配性,是目前业内专注于全链路AI智能体评测的标杆级开源工具。
二、功能特色
PawBench 围绕 AI 智能体落地评测核心需求,打造多项差异化功能,整体兼顾专业性、实用性与易用性,核心特色如下:
三维一体化评测体系
摒弃传统单模型评测模式,构建大模型 + 智能体框架 + 真实任务三维评测矩阵,一次运行即可同时评估模型性能、框架兼容性、任务完成率三大核心指标,定位问题更精准。海量标准化测试用例
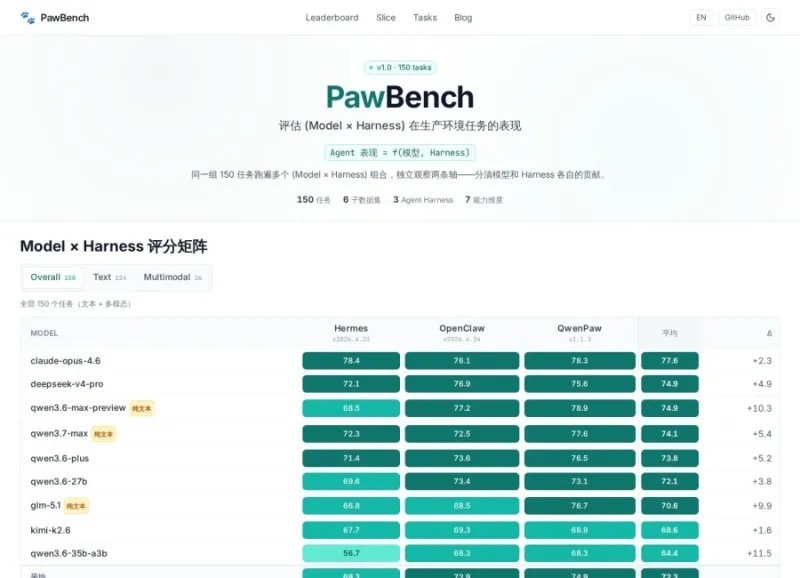
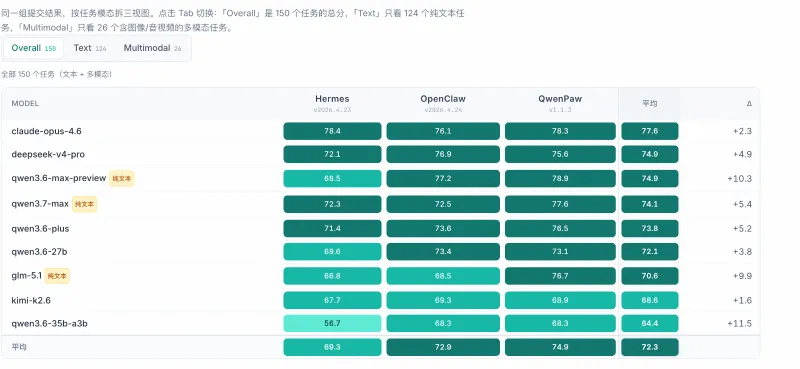
内置150项真实场景任务,拆解为4050个独立测试单元,覆盖日常助理、工具调用、逻辑推理、多轮交互、复杂指令拆解等主流场景,测试样本标准化、可复现,保证评测结果客观公正。多框架、多模型原生兼容
原生适配 Qwenpaw、Openclaw、Hermes 三大主流 AI 智能体运行框架,同时兼容市面上9款主流开源/商用大模型,无需大幅改造代码即可快速接入现有 Agent 项目。自动化评测与结果可视化
支持全流程自动化跑测,无需人工介入逐个执行任务;评测完成后自动生成量化报表、成功率统计、错误类型分类,直观展示智能体在不同场景下的短板。开源开放、轻量化部署
项目完全开源,遵循开源协议允许个人、企业二次开发与商用;部署门槛低,依赖组件少,普通服务器、本地开发机均可快速搭建运行环境。细粒度问题定位能力
针对任务失败案例进行分类溯源,可区分模型理解错误、框架调度异常、工具调用失败、逻辑链路断裂等不同故障类型,为智能体迭代优化提供明确方向。
三、技术细节
3.1 整体架构
PawBench 整体采用分层模块化架构,自上而下分为任务调度层、评测执行层、适配接入层、数据存储与输出层四大模块,模块间低耦合,便于扩展与维护。
任务调度层:负责读取预设测试任务集,按规则分配测试单元,控制测试并发、执行顺序与超时机制,保障批量测试稳定运行。
评测执行层:核心计算模块,调用接入的大模型与智能体框架,执行交互流程,实时记录每一步输入、输出、调用日志。
适配接入层:提供统一标准化接口,针对不同智能体框架、大模型做适配封装,降低第三方组件接入成本。
数据存储与输出层:统一存储原始日志、中间数据、评测得分,最后整合生成结构化评测报告、统计表格与可视化数据。
3.2 核心技术逻辑
测试单元拆分规则
所有150项场景任务均按照单步指令、多轮交互、跨工具联动三个维度拆解为最小测试单元,每个单元独立计分,保证评测颗粒度足够精细。整体测试单元总量计算公式:
框架数量 × 模型数量 × 场景任务数 = 4050 个,与项目标准配置保持一致。评分机制
采用百分制综合打分,由多维度指标加权计算得出:任务完成成功率(占比60%)、指令理解准确率(占比20%)、响应耗时(占比10%)、异常容错能力(占比10%)。系统自动比对智能体输出与标准参考答案,完成客观打分,规避人工评分主观误差。接口适配规范
项目统一封装标准调用接口,代码层面基于 Python 开发,主流依赖为网络请求库、日志库、数据解析库。接入第三方大模型或智能体框架时,仅需实现规定接口函数,即可完成对接,无需改动核心评测逻辑。
3.3 运行环境要求
基础环境:Python 3.8 及以上版本
硬件要求:本地开发机/普通云服务器均可,无强制高算力要求(若接入超大参数大模型,需匹配模型运行算力)
网络要求:可正常访问对应大模型接口、框架依赖资源
3.4 核心代码目录说明
项目源码目录结构清晰,关键目录与文件作用如下:
PawBench/ ├── benchmarks/ # 核心测试任务集、测试用例定义目录 ├── adapters/ # 框架、大模型适配适配器,对接各类Agent框架 ├── core/ # 评测核心逻辑、调度引擎、打分规则 ├── utils/ # 工具函数、日志、数据处理通用模块 ├── reports/ # 评测报告自动生成目录 ├── configs/ # 全局配置文件、模型/框架参数配置 └── run.py # 项目启动入口文件
四、应用场景
PawBench 定位为全链路 AI 智能体评测工具,覆盖技术研发、产品选型、性能优化、学术研究四大类主流场景,具体应用方向如下:
AI 智能体产品选型
企业、开发者在搭建自有 AI Agent 系统时,可使用 PawBench 批量测试多款大模型+框架组合的综合表现,根据评测数据择优选择适配自身业务的技术方案,避免盲目选型。智能体版本迭代测试
研发团队在更新智能体框架、升级基座大模型、优化业务逻辑后,使用标准化测试用例做回归测试,快速验证新版本是否出现能力下降、兼容性故障等问题。问题排查与性能调优
当线上 AI 智能体出现任务失败、响应异常、调用卡顿等问题时,通过 PawBench 复现故障场景,定位问题出在模型、框架还是业务逻辑层面,针对性完成调优。行业评测与榜单制作
行业媒体、技术社区可基于该开源基准开展横向评测,输出客观、可复现的 AI 智能体能力榜单,为行业提供参考依据。教学与学术研究
高校、科研机构可将其作为 AI 智能体方向的实验工具,用于模型能力研究、框架对比实验、智能体算法验证等学术场景。开源项目兼容性适配
各类开源 AI 框架、大模型开发者,可借助 PawBench 验证自身项目与主流生态的兼容性,完善生态对接能力。
五、使用方法
本节基于官方标准流程,讲解完整部署、配置、运行、查看报告全步骤,操作简单,新手也可快速上手。
5.1 环境准备
确保设备已安装 Python 3.8+ 环境,建议使用虚拟环境隔离依赖:
# 创建并激活虚拟环境 python -m venv pawbench-env # Windows 激活 pawbench-env\Scripts\activate # Linux/Mac 激活 source pawbench-env/bin/activate
安装项目依赖,进入项目根目录执行:
pip install -r requirements.txt
5.2 源码拉取
通过 Git 克隆官方仓库代码:
git clone https://github.com/agentscope-ai/PawBench.git cd PawBench
5.3 配置文件修改
进入 configs/ 目录,打开全局配置文件,完成两项核心配置:
填入需要测试的大模型接口地址、密钥、模型名称;
选择启用的智能体框架(Qwenpaw / Openclaw / Hermes),可单选或多选;
根据需求设置测试并发数、任务超时时间、测试用例范围。
5.4 启动评测任务
在项目根目录执行启动命令,运行全量测试:
python run.py
如需指定部分任务测试,可追加参数限定任务范围,命令示例:
python run.py --task partial
5.5 查看评测结果
任务执行过程中,控制台实时输出每一个测试单元的运行状态、执行结果;
全部任务跑完后,结构化评测报告、日志文件、统计表格会自动生成至
reports/目录;打开目录内 HTML/JSON 格式报告,即可查看综合得分、成功率、错误分类等详细数据。

六、竞品对比
选取目前业内主流的两款 AI 智能体/大模型评测基准 EvalPlus、AgentBench,与 PawBench 进行横向对比,从评测维度、适配范围、核心定位、部署难度、适用场景五大维度做客观分析。
| 对比维度 | PawBench | EvalPlus | AgentBench |
|---|---|---|---|
| 核心定位 | 全链路AI智能体系统评测(模型+框架+任务三维评测) | 大代码模型、通用大模型单项能力评测 | 面向复杂Agent任务的专项能力评测 |
| 评测维度 | 任务完成率、框架兼容性、响应速度、容错性多维度综合打分 | 代码生成、推理、文本能力单项打分 | 长链路任务、多工具调用专项打分 |
| 适配框架 | 原生支持Qwenpaw、Openclaw、Hermes三大主流Agent框架 | 无专属Agent框架适配,仅对接大模型 | 支持通用Agent框架,无原生定制适配 |
| 测试用例 | 150项真实落地场景,4050个标准化测试单元 | 以代码题、逻辑题为核心,偏向技术能力 | 侧重超长多轮交互、复杂综合任务 |
| 部署难度 | 低,轻量化部署,依赖少 | 中等,部分模型需本地部署算力 | 中等,长任务测试耗时久、配置复杂 |
| 核心优势 | 全链路问题定位,适配落地场景,工程化能力评测强 | 单项模型评测精度高,代码评测领域成熟 | 复杂长任务评测能力突出 |
总结:三款工具各有侧重。EvalPlus 更适合单纯评估大模型基础能力,AgentBench 擅长复杂长链路智能体任务测试,而 PawBench 主打整套智能体工程系统评测,更贴合企业实际落地、框架适配、版本迭代的需求,工程实用性更强。
七、常见问题解答
Q1:PawBench 只能使用官方指定的三款智能体框架吗?
A:并不是。项目原生适配 Qwenpaw、Openclaw、Hermes,同时提供标准化适配器接口,开发者可以按照接口规范自行开发适配器,接入其他自研或第三方AI智能体框架。
Q2:运行评测任务时报依赖缺失错误,该如何解决?
A:首先确认已激活对应 Python 虚拟环境,再重新执行 pip install -r requirements.txt 命令完整安装依赖。若仍报错,可根据提示单独安装缺失的第三方库,并检查 Python 版本是否满足 3.8 及以上要求。
Q3:评测结果中的任务失败,如何区分是模型问题还是框架问题?
A:PawBench 会在日志中记录每一步调用流程。如果模型输出内容逻辑正常,但最终任务未完成,大概率是智能体框架调度、工具调用出现异常;如果模型输出理解偏差、答非所问,则问题出在基座大模型本身。
Q4:是否可以将该项目用于商业产品内部测试?
A:该项目为开源项目,按照官方开源协议,允许个人与企业用于内部产品测试、版本迭代等商业相关场景,二次开发时需遵守对应的开源协议约束。
Q5:本地算力不足,无法运行大模型,可以使用云端模型接口吗?
A:完全支持。PawBench 不限制模型部署形式,无论是本地私有化部署模型,还是云端 API 接口形式的大模型,只要配置好接口地址与鉴权信息,均可正常接入测试。
Q6:测试用例是否支持自定义新增?
A:支持。所有测试任务均定义在 benchmarks 目录下,按照原有格式编写新的任务用例、标准答案与评分规则,即可扩展专属业务场景的测试集。
八、相关链接
GitHub仓库地址:https://github.com/agentscope-ai/PawBench
项目官网主页:https://agentscope-ai.github.io/PawBench/
九、总结
PawBench 是 AgentScope 团队推出的一款聚焦全链路 AI 智能体的开源评测基准,打破了传统大模型评测仅关注模型单体能力的局限,创新性地搭建起模型、框架、真实任务相结合的三维评测体系,凭借标准化的海量测试用例、多生态原生兼容、自动化跑测与结果分析、低门槛部署等优势,成为 AI 智能体研发、选型、优化环节中实用的工具。它不仅能够精准量化整套智能体系统的综合性能,快速定位运行过程中的各类故障问题,同时兼顾个人开发者、中小企业、科研机构等不同群体的使用需求,在 AI Agent 工程化落地与生态完善过程中发挥着重要的支撑作用,是当前面向落地场景的智能体评测领域优质开源解决方案。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/pawbench.html





