PersonaPlex:英伟达开源的全双工实时语音对话模型,支持角色定制与自然打断交互
一、PersonaPlex是什么
PersonaPlex是NVIDIA研究团队于2026年1月开源的全双工实时语音对语音(Speech-to-Speech)对话模型,基于Kyutai的Moshi架构与Helium语言模型构建,核心解决传统语音助手“听一次、答一次”的僵化交互问题,实现边说边听、实时打断、自然轮替的类人对话体验,同时支持语音+文本双重角色控制,让AI对话具备高度一致性与个性化。
该项目以MIT协议开源代码,模型权重遵循NVIDIA开放模型许可,提供7B参数版本(PersonaPlex-7B-v1),兼顾性能与部署成本,可在消费级GPU(如RTX 3090/4090)或云端环境运行,适用于智能客服、虚拟助手、互动娱乐等多场景。
核心定位
技术定位:端到端单一Transformer架构的全双工语音对话模型,替代传统“ASR+LLM+TTS”级联方案
产品定位:可定制角色的实时语音交互引擎,支持自然打断、低延迟响应、多风格语音输出
开源定位:面向开发者的语音交互基础设施,提供完整部署方案与预置资源,降低全双工语音应用开发门槛

二、功能特色
PersonaPlex的核心特色围绕全双工交互、角色定制、低延迟、多场景适配展开,具体如下:
1. 全双工实时交互(核心突破)
边说边听:AI在输出语音时持续监听用户输入,无需等待用户说完再响应
自然打断:用户可随时插话、打断AI发言,模型能快速切换对话轮次,响应延迟低至240ms
轮替接管:对话动态性强,轮转接管率达**90.8%**,接近人类自然对话的流畅度
无等待响应:告别传统语音助手的“等待结束”机制,实现真正的双向实时交互
2. 双重角色定制控制
通过语音提示(Voice Prompt)+文本提示(Text Prompt) 实现深度个性化,精准定义AI角色:
语音控制:提供预置语音嵌入(Voice Embedding),覆盖自然/多样风格、男女声,可自定义参考音频控制音色、语调、语速
文本控制:用文字描述角色身份、背景、话术规则、业务逻辑,AI严格遵循设定对话(如“银行客服”“游戏NPC”“英语外教”)
一致性保障:模型在长对话中保持角色设定不跑偏,任务遵从性优于同类开源/闭源模型
3. 低延迟与高性能
端到端架构:单一Transformer模型完成语音理解、对话生成、语音合成,减少多模块级联的延迟损耗
高效编解码:采用24kHz采样率,通过Mimi编解码器(ConvNet+Transformer)实现波形与离散词元的快速转换
硬件适配:支持NVIDIA GPU加速,可在RTX 3090/4090等消费级硬件实现实时交互,云端部署可支持高并发
4. 丰富的预置资源与易用性
预置语音库:提供16种预置语音嵌入,分类清晰(自然女声/男声、多样女声/男声),开箱即用
Web UI交互:内置客户端模块,启动服务后可通过浏览器快速体验,无需复杂开发
离线评估工具:支持批量处理音频文件,生成语音/文本输出,方便模型调试与效果验证
Docker部署:提供Dockerfile与docker-compose.yaml,简化环境配置与部署流程
5. 行业级评测表现
在FullDuplexBench(通用全双工对话基准) 与ServiceDuplexBench(客服场景扩展基准) 中,PersonaPlex在流畅度、任务完成率、中断适应性、响应延迟等维度均超越多个开源(如Moshi)及闭源竞品,是目前全双工语音对话领域的标杆级开源项目。
核心特色对比表
| 特性 | 传统级联语音助手 | PersonaPlex |
|---|---|---|
| 交互模式 | 半双工(听→答,等待用户结束) | 全双工(边说边听,实时打断) |
| 响应延迟 | 500ms+(多模块级联损耗) | 240ms(端到端单一模型) |
| 角色定制 | 仅文本控制,语音风格固定 | 语音+文本双重控制,风格灵活 |
| 打断支持 | 不支持或响应卡顿 | 自然打断,无缝切换轮次 |
| 架构复杂度 | 多模型拼接,部署繁琐 | 单一模型,部署简洁 |
| 对话流畅度 | 生硬,轮替不自然 | 接近人类对话,轮转接管率90.8% |
三、技术细节
1. 核心架构:基于Moshi的端到端Transformer
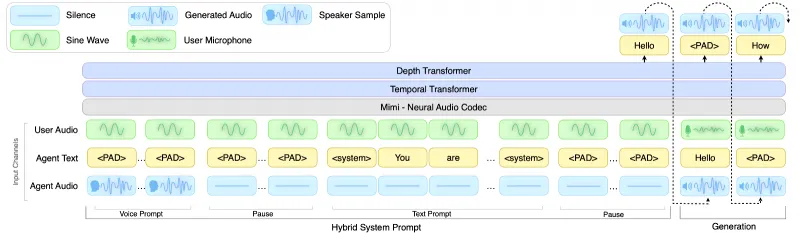
PersonaPlex以Kyutai Moshi为基础架构,采用单一Transformer模型实现全链路语音处理,核心流程如下:
语音编码:输入音频(24kHz)经Mimi编解码器转换为离散语音词元(Speech Tokens)
语言理解与生成:Transformer主干(基于Helium 7B)处理语音词元+文本提示,生成对话逻辑与响应词元
语音合成:响应词元经Chatterbox TTS转换为输出音频,同时持续监听输入音频,实现全双工
角色控制:语音嵌入(Voice Embedding)注入音色特征,文本提示注入角色逻辑,双重引导生成
2. 模型参数与训练数据
模型规模:PersonaPlex-7B-v1,70亿参数,兼顾性能与部署成本
训练数据:融合1217小时真实Fisher对话数据(学习自然交谈习惯)+2250小时合成场景数据(客服/助教/游戏等,学习任务规则),总训练时长超3400小时
训练目标:同时优化自然度(贴近人类对话)与任务遵从性(严格遵循角色设定),解决传统模型“自然但不听话”的痛点
3. 关键技术模块
(1)Mimi编解码器
结合ConvNet与Transformer,实现高保真、低延迟的语音波形-词元转换
支持24kHz采样率,压缩比高,减少模型计算量
开源可复用,是PersonaPlex实时性的核心保障
(2)Helium语言主干
NVIDIA自研的轻量级高效语言模型,适配语音对话场景
支持长上下文理解,保障长对话的角色一致性
泛化能力强,可处理训练数据外的场景与问题
(3)Voice Embedding(语音嵌入)
提取参考音频的音色、语调、语速等特征,生成固定维度嵌入向量
注入模型生成阶段,精准控制输出语音风格
提供预置嵌入库,也支持自定义音频生成嵌入
(4)全双工对话调度
实时音频流处理,支持重叠语音(用户与AI同时说话)
动态轮替算法,判断对话接管时机,避免卡顿或抢话
中断响应机制,用户插话时立即停止当前输出,切换到响应模式
4. 技术优势总结
架构创新:端到端单一模型,替代传统级联方案,延迟降低60%以上
数据融合:真实+合成数据结合,平衡自然度与任务能力
控制灵活:语音+文本双重控制,角色定制粒度细
开源开放:代码+部分权重开源,支持二次开发与场景定制
四、应用场景
PersonaPlex的全双工交互与角色定制能力,适用于企业服务、互动娱乐、教育、智能家居等多个领域,核心场景如下:
1. 智能客服(核心场景)
场景描述:银行、电商、运营商等行业的语音客服,替代人工处理咨询、查询、投诉等
核心价值:
全双工交互,模拟人工客服的自然对话,提升用户体验
文本提示注入业务规则(如订单查询、套餐办理),任务完成率高
预置语音风格,匹配品牌调性(如亲切女声、专业男声)
示例:银行客服AI,可查询账户余额、办理转账、解答理财问题,支持用户随时打断提问
2. 虚拟助手与智能家居
场景描述:手机/音箱/车载虚拟助手、智能家居控制中心
核心价值:
实时打断,无需等待助手说完再指令(如“播放音乐→暂停→切歌”连续操作)
角色定制,打造个性化助手(如“温柔生活助手”“硬核技术助手”)
低延迟响应,适配智能家居的实时控制需求
示例:车载助手,支持导航、音乐、电话控制,用户可边开车边插话调整指令
3. 互动娱乐与游戏NPC
场景描述:元宇宙、VR/AR游戏、虚拟主播、有声互动小说
核心价值:
全双工对话,实现与游戏NPC的自然闲聊、任务交互
角色定制,打造风格各异的NPC(如“傲娇法师”“憨厚战士”)
语音风格多样,提升娱乐沉浸感
示例:VR游戏中的虚拟伙伴,可实时对话、接梗、响应玩家动作,支持玩家随时打断互动
4. 教育与语言学习
场景描述:AI外教、口语陪练、儿童启蒙教育
核心价值:
全双工交互,模拟真实语言交流,提升口语练习效果
角色定制,打造不同风格的外教(如“美式幽默外教”“英式严谨外教”)
语音控制,匹配学习者的发音习惯,纠正发音
示例:英语外教AI,可进行日常对话、语法讲解、发音纠正,支持学生随时提问打断
5. 具身智能与服务机器人
场景描述:服务机器人、导览机器人、陪护机器人
核心价值:
实时语音交互,适配机器人的移动与操作场景
角色定制,匹配机器人的功能定位(如“商场导览员”“医院陪护员”)
低延迟响应,保障人机交互的流畅性
示例:商场导览机器人,可实时解答店铺位置、活动信息,支持游客随时插话询问
五、使用方法
1. 环境准备
(1)硬件要求
最低配置:NVIDIA GPU(支持CUDA 11.7+),显存≥24GB(如RTX 3090/4090、A10等)
推荐配置:NVIDIA A100/H100,显存≥40GB,支持高并发与长对话
其他:CPU≥8核,内存≥32GB,硬盘≥100GB(存储模型权重与依赖)
(2)软件要求
操作系统:Ubuntu 20.04/22.04(推荐)、Windows 11(WSL2)
CUDA:11.7及以上版本
Python:3.10及以上版本
其他依赖:PyTorch 2.0+、Transformers、SoundFile、FastAPI等
2. 安装部署
(1)克隆仓库
git clone https://github.com/NVIDIA/personaplex.git cd personaplex
(2)安装核心模块
# 安装moshi核心模块 pip install moshi/. # 安装客户端依赖(可选,用于Web UI) pip install -r client/requirements.txt
(3)模型权重准备
登录Hugging Face,接受PersonaPlex-7B-v1的模型许可证
配置Hugging Face令牌:
export HF_TOKEN="你的Hugging Face令牌"
模型会在首次运行时自动下载,也可手动下载至
~/.cache/huggingface/hub/
(4)Docker部署(推荐,简化环境配置)
# 构建镜像 docker build -t personaplex:latest . # 启动容器(映射端口与SSL目录) docker run -it --gpus all -p 8998:8998 -v $(pwd)/ssl:/ssl personaplex:latest
3. 核心使用方式
(1)实时交互(Web UI,推荐)
启动带临时SSL证书的服务,通过浏览器访问交互:
# 创建临时SSL目录 SSL_DIR=$(mktemp -d) # 启动服务 python -m moshi.server --ssl "$SSL_DIR"
本地访问:
https://localhost:8998(需信任临时证书)远程访问:替换
localhost为服务器IP,端口默认8998操作步骤:
选择预置语音(如NATM1、NATF0)
输入文本提示(定义角色)
点击“开始对话”,通过麦克风实时交互,支持随时打断
(2)离线评估(批量处理音频)
基于输入音频文件生成输出音频/文本,支持自定义语音与文本提示:
HF_TOKEN="你的HF_TOKEN" \ python -m moshi.offline \ --voice-prompt "NATM1.pt" \ # 选择预置语音 --text-prompt "$(cat assets/test/prompt_service.txt)" \ # 文本提示文件 --input-wav "assets/test/input_service.wav" \ # 输入音频 --seed 42424242 \ # 随机种子,保证结果可复现 --output-wav "output.wav" \ # 输出音频 --output-text "output.json" # 输出对话文本
(3)自定义语音嵌入
使用参考音频生成专属语音风格:
python -m moshi.voice_embed \ --input-wav "custom_voice.wav" \ # 参考音频(10-30秒,清晰语音) --output-pt "custom_voice.pt" # 生成的语音嵌入文件
生成后可在实时交互或离线评估中通过--voice-prompt调用。
4. 预置语音列表
PersonaPlex提供16种预置语音嵌入,分类如下,可直接通过文件名调用:
| 风格类型 | 女声 | 男声 |
|---|---|---|
| 自然风格 | NATF0、NATF1、NATF2、NATF3 | NATM0、NATM1、NATM2、NATM3 |
| 多样风格 | VARF0、VARF1、VARF2、VARF3、VARF4 | VARM0、VARM1、VARM2、VARM3、VARM4 |
5. 文本提示示例
(1)客服角色(银行)
You are a customer service representative at ABC Bank. Your name is Li Ming. You can help customers check account balance, transfer money, and answer questions about credit cards. Be polite and professional. If you don't know the answer, say "I need to check with our team and get back to you soon."
(2)教育角色(英语外教)
You are a friendly English teacher from the US. Your name is Sarah. Help students practice spoken English, correct their grammar and pronunciation, and encourage them to speak more. Use simple words and sentences.
(3)娱乐角色(游戏NPC)
You are a blacksmith in a fantasy game. Your name is Gareth. You are gruff but kind. You can forge weapons, repair armor, and tell stories about your adventures. Don't reveal game secrets. Use medieval-style language.
六、常见问题解答(FAQ)
Q1:启动服务时提示CUDA out of memory怎么办?
A:降低模型批量大小、使用FP16/INT8量化(后续版本支持)、升级GPU显存,或在云端租用高显存实例(如AWS G5、阿里云GN7)。
Q2:Windows系统如何部署?
A:推荐使用WSL2安装Ubuntu 22.04,按Linux步骤部署;或使用Docker Desktop启动容器,需开启GPU支持(安装NVIDIA Container Toolkit)。
Q3:模型权重下载失败怎么办?
A:检查HF_TOKEN是否正确、是否接受模型许可证;手动下载权重至~/.cache/huggingface/hub/models--nvidia--personaplex-7b-v1/;更换网络环境(如使用代理)。
Q4:实时交互时语音卡顿、延迟高怎么办?
A:确保GPU显存充足(≥24GB)、关闭其他占用GPU的程序;使用有线网络(远程部署);降低音频采样率(非推荐,影响音质)。
Q5:如何自定义AI的语音风格?
A:录制10-30秒清晰的参考音频(单人、无背景噪音),使用moshi.voice_embed模块生成语音嵌入文件,在交互时通过--voice-prompt调用。
Q6:文本提示的长度有限制吗?
A:建议文本提示长度≤512 token,过长会影响模型响应速度与角色一致性;核心角色信息(身份、规则、风格)放在提示开头。
Q7:AI角色设定跑偏,不遵循文本提示怎么办?
A:优化文本提示,明确角色规则与限制(如“禁止回答无关问题”“必须使用专业术语”);缩短提示长度,突出核心信息;使用更具体的角色描述(如“你是中国移动的5G客服,仅回答5G套餐相关问题”)。
Q8:输出语音音质差、有杂音怎么办?
A:确保输入音频清晰(无背景噪音);选择高质量的预置语音(如NAT系列);避免使用过短的参考音频生成自定义嵌入;升级GPU,减少计算误差。
Q9:全双工交互时,AI抢话或不响应打断怎么办?
A:调整对话灵敏度(后续版本支持参数配置);确保输入音频音量适中,避免静音或过大声;使用最新版本代码,修复调度算法bug。
Q10:如何将PersonaPlex集成到自己的应用中?
A:通过moshi.server的API接口(WebSocket)实现语音流传输;或使用moshi.offline模块批量处理音频,集成到后端服务;参考client/目录的Web UI代码,开发自定义前端。
Q11:支持多语言吗?
A:当前版本主要支持英语,后续版本计划支持中文等多语言;可通过文本提示用英语描述角色,实现英语对话。
七、相关链接
模型权重(Hugging Face):https://huggingface.co/nvidia/personaplex-7b-v1
官方论文:https://research.nvidia.com/labs/adlr/files/personaplex/personaplex_preprint.pdf
八、总结
PersonaPlex作为NVIDIA开源的端到端全双工实时语音对语音对话模型,凭借单一Transformer架构实现了240ms低延迟响应与90.8%的高轮转接管率,彻底打破了传统语音助手“听一次、答一次”的交互瓶颈,同时通过语音+文本双重控制实现了高度个性化的角色定制,兼顾了自然对话流畅度与任务遵从性。该项目依托真实+合成的融合训练数据,在通用与客服场景的专业基准测试中表现优异,且提供了完整的部署方案、预置资源与易用工具,降低了全双工语音交互应用的开发门槛。无论是企业级智能客服、互动娱乐的游戏NPC,还是教育领域的AI外教,PersonaPlex都能提供接近人类的自然交互体验,是当前开源语音对话领域的标杆级项目,为实时语音交互技术的落地与创新提供了强大的基础设施支持。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/personaplex.html





