SongBloom:腾讯开源的AI完整歌曲生成框架,支持音频提示与高质量音乐输出
1. SongBloom 是什么
SongBloom 是由 腾讯人工智能实验室(Tencent AI Lab) 开发并开源的 全长歌曲生成框架。它的核心目标是让AI能够从一个简短的音频提示(如10秒的参考音频)出发,自动生成一首完整、连贯、风格一致的歌曲,长度可达2分30秒(150秒)。
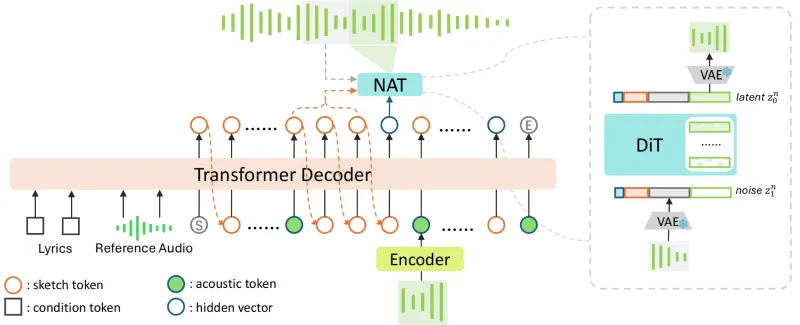
与以往的音乐生成模型不同,SongBloom 创新性地采用了 交错的自回归草图绘制(Autoregressive Sketching) 和 扩散模型精炼(Diffusion Refinement) 技术,将语言模型的可扩展性与扩散模型的高保真度结合起来,实现了从粗到细、从短到长的渐进式音乐生成。
该项目于 2025 年 6 月首次开源,随后在 9 月推出了经过 DPO(Direct Preference Optimization)优化的版本,进一步提升了生成音乐的质量和可控性。
2. 功能特色
SongBloom 在音乐生成领域具备多项独特优势,下面通过表格形式对比其与传统音乐生成方法的差异:
| 特性 | SongBloom | 传统自回归音乐模型 | 纯扩散音乐模型 |
|---|---|---|---|
| 生成长度 | 最长 150 秒(2分30秒) | 较短(通常 < 30秒) | 中等(30-90秒) |
| 提示类型 | 10秒音频(部分模型支持文本) | 文本或旋律 | 文本或噪声 |
| 音质 | 高保真,细节丰富 | 中等,易产生重复或断裂 | 高,但长时一致性差 |
| 可控性 | 可通过提示音频控制风格、节奏 | 受限于文本描述 | 较弱,风格不稳定 |
| 一致性 | 整首歌曲风格统一,结构完整 | 短片段一致性好,长段落易脱节 | 局部一致性好,整体连贯性弱 |
| 开源性 | 开源代码与模型权重 | 部分开源 | 部分开源 |
主要特色
全长音乐生成
支持一次性生成完整的歌曲,而非片段式拼接,避免了传统方法中常见的段落衔接不自然问题。双阶段生成范式
草图阶段:自回归模型生成音乐的“骨架”(低分辨率的旋律与和声结构)。
精炼阶段:扩散模型对骨架进行细节填充,提升音质与表现力。
高保真输出
生成音频采样率为 48kHz,音质接近专业制作水平。多样化模型选择
提供基础版、DPO优化版等多个模型,适应不同的生成需求。易于使用
提供简洁的推理脚本和JSONL输入格式,只需准备提示音频和歌词即可生成歌曲。
3. 技术细节
3.1 整体架构
SongBloom 的架构可以分为四个主要部分:
音频编码器(Audio Encoder)
将输入的提示音频转换为潜在空间的特征表示。
采用基于VAE的音频压缩技术,保留关键声学特征。
自回归草图生成器(Autoregressive Sketch Generator)
基于Transformer架构,处理编码器输出的特征。
按时间步逐步生成音乐的低分辨率“草图”。
草图包含旋律走向、和声结构和节奏信息。
扩散精炼器(Diffusion Refiner)
接收草图作为条件输入。
通过多步扩散过程,将低分辨率草图提升为高保真音频。
引入交叉注意力机制,确保精炼过程与草图内容一致。
音频解码器(Audio Decoder)
将扩散模型输出的特征映射回时域波形。
输出48kHz的高质量音频。
3.2 核心技术创新
交错生成机制:自回归与扩散模型并非完全独立,而是在多个时间尺度上交错工作,确保全局结构和局部细节的平衡。
上下文整合:模型不仅关注当前生成的音乐片段,还会回顾已生成的内容,保持风格一致性。
多尺度建模:草图阶段处理较低时间分辨率的特征,精炼阶段则恢复高频细节,这种分工提高了生成效率和质量。
3.3 数据与训练
训练数据:包含大量授权音乐作品,涵盖多种风格。
歌词处理:支持将歌词作为条件输入,影响生成音乐的情感和节奏。
DPO优化:通过人类偏好数据微调模型,提升音乐的审美质量。

4. 应用场景
SongBloom 的高-quality 全长音乐生成能力,使其在多个领域具有广泛应用前景:
| 应用领域 | 具体场景 | 价值 |
|---|---|---|
| 音乐创作 | 作曲家快速获取灵感、生成伴奏初稿 | 提高创作效率,降低入门门槛 |
| 广告传媒 | 为广告片、短视频生成定制背景音乐 | 快速匹配视频风格,降低版权成本 |
| 教育领域 | 音乐教学中的示例生成、即兴伴奏 | 提供多样化的教学素材 |
| 游戏开发 | 为游戏场景、角色定制主题音乐 | 丰富游戏音效库,提升沉浸感 |
| 个人娱乐 | 普通用户创作个性化歌曲 | 满足非专业人士的音乐创作需求 |
5. 使用方法
5.1 环境准备
创建并激活虚拟环境
conda create -n SongBloom python==3.8.12 conda activate SongBloom
安装依赖
pip install -r requirements.txt
注意:PyTorch版本建议使用2.2.0,并根据CUDA版本选择合适的安装命令。
5.2 数据准备
输入为JSONL格式文件,每行一个样本:
{
"idx": "001",
"lyrics": "这是一首关于春天的歌...",
"prompt_wav": "example/test.wav"
}提示音频要求:
时长:10秒
采样率:48kHz
格式:WAV
5.3 模型下载
模型权重托管在Hugging Face:
5.4 推理运行
基础命令:
source set_env.sh python3 infer.py --input-jsonl example/test.jsonl
低VRAM设备优化:
python3 infer.py --input-jsonl example/test.jsonl --dtype bfloat16
5.5 结果输出
生成的音频文件默认保存在output目录下,文件名为样本idx加上时间戳。
6. 常见问题解答
Q1: SongBloom 需要什么级别的GPU?
A: 推荐使用至少24GB显存的GPU(如RTX 3090/4090)。12GB显存也可运行,但需要使用bfloat16精度并调整批处理大小。
Q2: 生成一首2分30秒的歌曲需要多长时间?
A: 在RTX 4090上,大约需要1-2分钟,具体时间取决于模型类型和精度设置。
Q3: 可以控制生成音乐的风格吗?
A: 可以,主要通过选择不同风格的提示音频来控制整体风格。未来版本计划支持更精细的风格控制参数。
Q4: SongBloom支持中文歌词吗?
A: 是的,完全支持中文歌词输入,并能根据歌词内容调整音乐情感。
Q5: 该项目的许可证是什么?
A: SongBloom代码和模型权重仅允许学术用途,禁止商业使用。
Q6: 如何处理生成结果中的不自然过渡?
A: 可以尝试更换提示音频、调整歌词结构,或使用DPO优化版模型,通常能获得更自然的结果。
Q7: 是否支持其他采样率的输入音频?
A: 目前仅支持48kHz的输入音频,其他采样率需要先转换。
7. 相关链接
Hugging Face模型页: https://huggingface.co/CypressYang/SongBloom
8. 总结
SongBloom 是一个突破性的全长歌曲生成框架,它巧妙地结合了自回归模型和扩散模型的优势,实现了高质量、风格一致的完整音乐创作。该项目不仅为音乐创作者提供了强大的辅助工具,也为AI音乐生成研究领域贡献了宝贵的开源资源。通过简洁易用的接口和多样化的模型选择,SongBloom 降低了AI音乐创作的技术门槛,使更多人能够享受到音乐生成的乐趣。无论是专业音乐制作还是个人娱乐创作,SongBloom 都展现出了巨大的应用潜力。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/songbloom.html





