SongGeneration 2:腾讯、清华大学联合开源的AI音乐大模型,商用级歌曲生成与多语种精准演唱
一、SongGeneration 2是什么
SongGeneration 2是腾讯AI Lab与清华大学人机语音交互实验室联合研发的开源AI歌曲生成大模型,是SongGeneration系列的第二代升级版本,核心模型代号为LeVo 2。它是当前开源领域少数能达到商用级音质、结构完整、歌词准确、风格可控的端到端歌曲生成系统,可直接输入文本提示、歌词、参考音频,一键生成包含人声与伴奏的完整歌曲。
该项目定位为音乐生成基础模型,面向开发者、音乐人、内容创作者、企业用户开放,支持本地私有化部署,兼顾研究与生产环境使用。其核心目标是解决AI音乐长期存在的三大痛点:音乐性弱、歌词幻觉/咬字不准、风格不可控,让开源模型真正具备工业级可用能力。
SongGeneration 2已在NeurIPS 2025发表学术成果,代码、模型权重、推理脚本、工具链全部开源,支持中文、英文、日语、西语等多语种演唱,最长可生成4分30秒完整结构歌曲,输出格式包含完整歌曲、纯伴奏、纯人声、双轨分离文件,满足后期制作需求。
二、功能特色
1. 商用级音乐质量
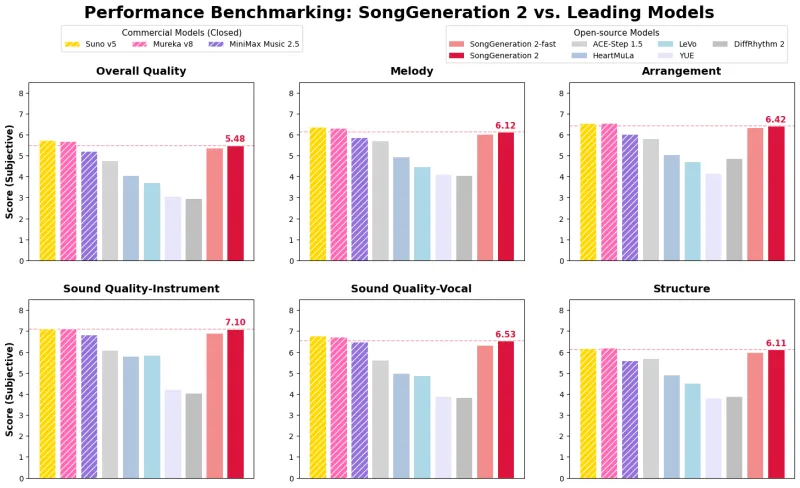
SongGeneration 2经过20位行业专家、6大维度、每模型100首歌曲的盲测评估,在整体质量、旋律、编曲、音质、结构、情感表达上全面超越现有开源模型,主观听感可对标顶级闭源商用系统。模型能处理复杂多轨编曲,具备自然的段落结构、和声走向与动态层次,告别机械拼接感。
2. 超低歌词错误率,多语种精准演唱
模型攻克AI音乐“歌词幻觉、跑调、咬字模糊”难题,**音素错误率(PER)低至8.55%**,显著优于Suno v5(12.4%)、Mureka v8(9.96%)等商用模型,接近真人演唱准确度。支持中文、英文、日语、西语等多语言,歌词与旋律严格对齐,长句、RAP、抒情唱法均稳定输出。
3. 全模式输出,灵活适配制作流程
支持四种输出模式,满足不同场景需求:
完整歌曲(人声+伴奏混合)
纯伴奏(无人声)
纯人声(无伴奏)
人声+伴奏双轨分离文件
输出音频为高保真格式,可直接导入剪辑软件、DAW编曲工程二次编辑。
4. 强指令可控,文本+音频双驱动
文本控制:输入风格、情绪、速度、乐器、人声类型等描述,精准控制生成结果。
音频提示:输入10秒参考音频,一键复刻风格、情绪、唱法、音色,无需训练即可风格迁移。
结构控制:支持主歌、副歌、桥段、前奏、尾奏等完整歌曲结构生成。
5. 多版本适配,消费级硬件可运行
项目提供多个模型版本,覆盖大中小参数量,兼顾效果、速度、显存占用:
| 模型版本 | 最大长度 | 支持语言 | 显存要求(无提示/有提示) | 推理速度(RTF) |
|---|---|---|---|---|
| SongGeneration-v2-large | 4分30秒 | 中、英、日、西等 | 22GB / 28GB | 0.82 |
| SongGeneration-v2-medium | 4分30秒 | 中、英、日、西等 | 12GB / 18GB | 0.69 |
| SongGeneration-v2-fast | 4分30秒 | 中、英、日、西等 | 低显存优化 | 1分钟内完成 |
6. 完整工具链与生态
配套开源SongPrep数据处理工具,支持歌曲结构解析、歌词时间戳标注、音素对齐、数据集清洗;提供Gradio可视化界面、命令行脚本、Python API,降低使用门槛。

三、技术细节
1. 核心架构:LLM + Diffusion 双核设计
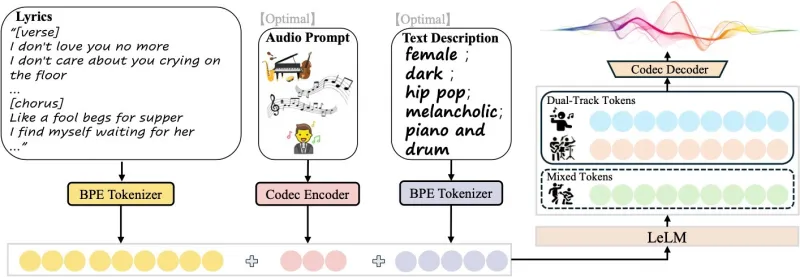
SongGeneration 2采用创新混合架构,将语言模型与扩散模型优势结合:
LeLM(作曲大脑):基于大语言模型,负责全局音乐结构、旋律走向、歌词-旋律对齐、演奏细节规划,解决“唱什么、怎么唱、如何编排”。
Diffusion(高保真渲染器):在LeLM指导下生成细腻声学细节,提升音质、空间感、音色真实度,负责最终音频渲染。
2. 分层表征建模
模型并行建模两种令牌,兼顾结构与音质:
混合令牌:统一建模人声+伴奏,保证整体和谐度。
双轨令牌:独立编码人声与伴奏,支持分离输出与精细控制。
这种设计既保证旋律流畅稳定,又实现高保真双轨分离,是行业首创技术路线。
3. 多阶段对齐训练
为提升音乐性与歌词准确性,采用三阶段训练策略:
SFT监督微调:用高质量歌曲数据构建基础生成能力。
大规模离线DPO:基于20万+偏好样本对优化,消除歌词幻觉,提升指令遵循。
半在线DPO:结合美学评估框架持续迭代,拉满音乐性上限。
4. 音乐编解码与声学建模
使用自研高保真音乐编解码器,支持48kHz采样率,在压缩率与音质间取得最优平衡;结合Mel频谱、音素特征、节奏特征联合建模,保证演唱自然度。
5. 长序列建模能力
专门优化Transformer结构,支持最长4分30秒音频生成,解决传统模型只能生成短片段、结构断裂问题,可生成主歌-副歌-桥段完整流行歌曲。
四、应用场景
1. 个人音乐创作
零基础用户快速生成原创歌曲、demo小样;音乐人快速扩展灵感,批量生成不同风格版本。
2. 短视频与自媒体配乐
为剧情、口播、vlog、广告生成专属BGM与人声歌曲,避免版权风险。
3. 影视与动画配音配乐
制作影视剧插曲、片尾主题曲、动画角色歌,快速迭代版本。
4. 游戏音频设计
生成游戏背景音乐、剧情歌曲、角色主题曲,支持风格统一批量生产。
5. 广告与品牌营销
定制品牌主题曲、宣传曲、 slogan 歌曲,强化品牌听觉符号。
6. 教育与内容科普
制作儿歌、知识歌曲、语言学习素材,提升趣味性与记忆点。
7. 企业私有化服务
搭建内部音乐生成API,为产品、APP、工具链提供音乐生成能力,保护数据隐私。
五、使用方法
1. 环境要求
系统:Linux / Windows WSL2
Python:3.8+
GPU:建议NVIDIA,显存≥10GB(推荐12GB+)
依赖:PyTorch、torchaudio、soundfile、transformers等
2. 安装步骤
# 克隆仓库 git clone https://github.com/tencent-ailab/songgeneration cd songgeneration # 安装依赖 pip install -r requirements.txt # 安装系统依赖(Linux) sudo apt-get install libsndfile1
3. 模型下载
从Hugging Face下载对应版本权重:tencent/SongGeneration-v2-largetencent/SongGeneration-v2-mediumtencent/SongGeneration-v2-fast
4. 命令行推理
# 基础生成 python generate.py \ --model tencent/SongGeneration-v2-large \ --text "温暖男声 流行 抒情 钢琴 缓慢" \ --lyrics "你是落在我世界里的光" \ --duration 180 \ --output output/song.wav
5. 音频提示风格迁移
python generate.py \ --model tencent/SongGeneration-v2-large \ --prompt_wav reference.wav \ --lyrics "新的歌词内容" \ --duration 180 \ --output output/song.wav
6. 启动Gradio可视化界面
python app.py
启动后打开浏览器访问本地地址,可上传歌词、输入提示、选择模型、试听下载。
7. Python API调用
from songgeneration import SongGenerator
# 加载模型
model = SongGenerator.from_pretrained("tencent/SongGeneration-v2-large")
# 生成歌曲
result = model.generate(
text="流行 轻快 女声",
lyrics="阳光洒在街道上",
duration=180
)
# 保存音频
result.save("my_song.wav")六、常见问题解答
SongGeneration 2可以商用吗?
可以,项目核心代码采用MIT开源协议,允许商用、修改、分发,只需遵守协议声明。
本地运行最低需要什么配置?
基础版本可在10GB显存GPU运行,推荐使用12GB以上显存显卡(如RTX 4090、3090、A10等)。
生成一首歌曲需要多久?
v2-large版本在4090上生成4分30秒歌曲约3–5分钟;fast版本可在1分钟内完成。
支持哪些语言?
v2版本支持中文、英文、日语、西语等多语种,歌词发音准确,旋律对齐稳定。
可以只生成伴奏不生成人声吗?
可以,支持输出纯伴奏、纯人声、双轨分离、混合歌曲四种模式。
歌词必须输入吗?
不是必须,可仅用文本提示生成纯音乐或哼唱类歌曲;输入歌词则生成带歌词演唱。
能否控制歌手性别、年龄、音色?
可以,在text提示中加入“男声/女声/童声/沙哑/清澈”等描述即可控制。
支持多长的歌曲?
最大支持4分30秒,可生成完整结构的流行歌曲。
模型权重在哪里下载?
在Hugging Face Hub搜索tencent/SongGeneration即可下载所有版本权重。
Windows系统可以运行吗?
可以使用WSL2环境运行,或直接在Windows终端配置CUDA环境运行。
生成的歌曲有版权问题吗?
用户使用模型生成的内容版权归用户所有,可用于个人与商业用途,无版权风险。
可以微调训练自己的模型吗?
项目提供训练框架与工具链,支持在高质量数据集上微调,定制专属风格。
七、相关链接
GitHub官方仓库:https://github.com/tencent-ailab/songgeneration
Hugging Face模型权重:https://huggingface.co/tencent/SongGeneration
Hugging Face在线演示:https://huggingface.co/spaces/tencent/SongGeneration
官方Demo音频示例:https://levo-demo.github.io/levo_v2_demo/
学术论文:https://arxiv.org/abs/2506.07520
八、总结
SongGeneration 2是腾讯AI Lab与清华大学联合推出的商用级开源AI歌曲生成大模型,基于LeVo 2双核架构,通过LLM负责音乐结构与歌词对齐、Diffusion负责高保真渲染,实现了音乐性、歌词准确度、可控性的全面突破,支持多语种、长完整歌曲、双轨分离输出与消费级GPU本地部署,配套完善工具链与在线演示,既可作为研究基座,也可直接用于商业内容生产,是当前开源音乐生成领域的标杆项目,为个人创作者、企业开发者提供了零门槛、高质量、私有化的音乐生成能力。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/songgeneration-2.html