VerseCrafter:复旦、港大&腾讯联合开源的 4D 几何可控的动态真实视频世界模型
一、VerseCrafter是什么
VerseCrafter是一款具备4D几何可控能力的动态真实视频世界模型,由复旦大学、香港大学、腾讯ARC Lab等机构联合开源,核心解决传统AI视频生成中“几何失真、运动不可控、时空一致性差”的核心痛点。与常规文本驱动或单维度控制的视频生成模型不同,VerseCrafter将视频生成从“2D画面合成”升级为“4D时空建模”(3D空间+1D时间),通过统一的4D控制状态,实现对相机运动路径、多目标物体3D轨迹及二者协同关系的可解释、精细化调控,最终输出几何结构准确、视觉质量优异、长时序一致的动态视频。
该模型依托大规模真实世界视频数据集VerseControl4D训练,从海量野生视频中学习真实的动态世界先验,既能处理静态场景的视角切换,也能应对多目标协同运动的复杂动态场景,在保持Wan2.1骨干网络强大生成能力的基础上,新增了几何可控性这一核心优势,填补了当前可控视频生成领域“4D几何精准控制”的技术空白。
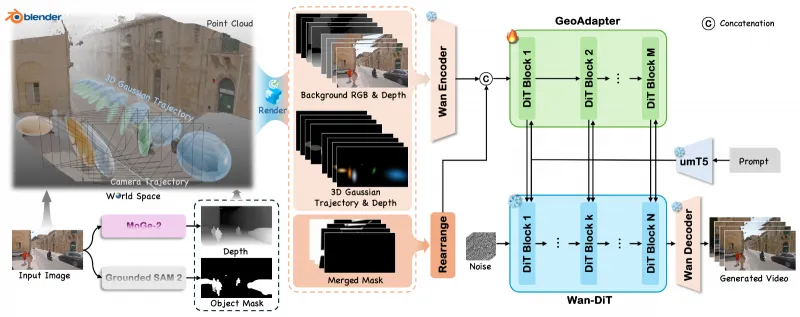
从技术定位来看,VerseCrafter并非从零构建的视频生成模型,而是基于成熟的Wan2.1-T2V-14B预训练视频扩散模型进行轻量化改造,通过“冻结骨干+插入GeoAdapter”的架构设计,实现“低算力成本、高可控精度、强生成质量”的平衡,既降低了部署与训练门槛,又能快速适配各类可控视频生成场景,是面向研究与工业落地的实用型开源项目。
二、功能特色
VerseCrafter的核心竞争力集中在4D几何可控性、多模式控制机制、高保真生成、强泛化能力四大维度,同时具备轻量化适配、多工具兼容等实用特性,具体功能特色如下:
(一)核心4D几何可控能力
这是VerseCrafter最核心的功能突破,区别于所有传统视频生成模型:
相机轨迹精准控制:支持自定义相机的6自由度运动(平移+旋转),包括推近、拉远、环绕、平移、俯仰等任意路径,可精准设定相机在每一帧的位姿(位置+朝向),实现“指哪拍哪”的视角控制,彻底解决传统生成中相机运动随机、视角混乱的问题。
多目标3D轨迹控制:支持对视频中的多个目标物体(如人物、车辆、动物、道具等)分别设定3D高斯轨迹,精准控制每个目标的运动速度、方向、位置及姿态变化,实现“单个目标独立运动、多个目标协同运动”的精细化调控,避免目标穿模、形变、运动逻辑混乱等问题。
相机-目标协同控制:支持同时设定相机轨迹与多目标轨迹,实现二者的动态协同(如相机跟随目标运动、目标按相机视角同步移动、多目标与相机形成互动场景等),构建符合真实物理逻辑的动态场景,提升视频的真实感与叙事性。
(二)多模式控制机制,适配多样化需求
VerseCrafter提供三种核心控制模式,覆盖从简单到复杂的全场景创作需求,具体如下表所示:
| 控制模式 | 核心功能 | 适用场景 | 操作复杂度 |
|---|---|---|---|
| 相机独立控制 | 仅自定义相机轨迹,目标物体保持静态或自然运动 | 静态场景视角切换、全景漫游、产品展示视频 | 低 |
| 目标独立控制 | 仅自定义多目标3D轨迹,相机保持固定或自然运动 | 多目标动作演示、角色动画、动态场景填充 | 中 |
| 相机-目标协同控制 | 同时自定义相机轨迹与多目标轨迹,实现二者动态协同 | 影视镜头调度、游戏剧情动画、VR交互场景 | 高 |
(三)高保真视频生成,兼顾质量与一致性
视觉质量优异:基于Wan2.1-T2V-14B骨干网络,保留其强大的文本-视频生成能力,生成视频的画质、细节、色彩还原度达到行业顶尖水平,支持1080P及以上分辨率输出,满足影视、广告等高质量内容生产需求。
时空一致性强:通过4D几何控制信号的监督,生成视频在时间维度上(帧间)运动流畅、无跳变,在空间维度上(物体/场景)几何结构稳定、无穿模/形变,长时序视频(如30秒以上)仍能保持高度一致性。
几何保真度高:所有控制信号均基于真实3D几何逻辑设计,生成视频的物体比例、空间关系、运动轨迹符合真实物理规则,避免传统生成中“物体变形、比例失调、空间错位”等常见问题。
(四)强泛化能力,适配多场景与多类型内容
场景泛化性:基于VerseControl4D数据集训练,覆盖室内、室外、自然、城市、动态、静态等全类型场景,对未知场景(如小众场景、自定义场景)具备强适应能力,无需额外微调即可生成高质量内容。
内容泛化性:支持文本驱动+4D控制的双模式输入,既能通过文本描述场景内容(如“森林中奔跑的鹿群”),又能通过4D控制信号指定运动逻辑,兼顾“内容创意”与“运动可控”,适配影视、游戏、教育、广告等多领域内容类型。
工具泛化性:兼容Blender等3D创作工具,提供Blender插件,可直接在Blender中设计相机轨迹与目标轨迹,导出后输入VerseCrafter生成视频,打通3D创作与AI视频生成的链路,降低创作者的技术门槛。
(五)轻量化适配,降低部署与使用门槛
架构轻量化:采用“冻结Wan2.1骨干+插入GeoAdapter”的设计,GeoAdapter为轻量级模块,仅需少量参数即可实现4D控制,无需重新训练整个骨干网络,训练与推理算力成本大幅降低。
环境易部署:提供完整的环境配置脚本、依赖清单与推理脚本,支持Conda环境快速搭建,兼容NVIDIA CUDA 12.1及以上版本,普通高性能GPU(如RTX 4090、A100)即可完成推理部署。
接口易调用:提供API服务接口(api_server.py)与模型服务接口(model_server.py),支持批量推理、远程调用,可快速集成到现有内容生产系统中,实现工业化落地。

三、技术细节
VerseCrafter的技术核心是“4D控制信号编码+GeoAdapter注入+Wan2.1骨干生成”的三位一体架构,同时配套VerseControl4D数据集提供监督信号,整体技术逻辑清晰、可解释性强,具体技术细节如下:
(一)核心技术架构:冻结骨干+GeoAdapter轻量化改造
VerseCrafter的技术架构以“保留生成质量、新增可控能力”为核心,采用“双模块协同”设计,具体分为三个层级:
底层:Wan2.1-T2V-14B骨干网络
作为视频生成的核心引擎,采用预训练的视频扩散模型,具备强大的时空建模与高保真生成能力,负责将文本提示与控制信号转化为像素级视频帧。
训练与推理过程中全程冻结,不修改其原有参数,确保生成质量不下降,同时避免大规模训练的算力成本。
中层:GeoAdapter几何适配器(核心创新模块)
这是VerseCrafter实现4D控制的核心模块,为轻量级神经网络,插入在Wan2.1的各扩散层之间,负责将4D控制信号编码为模型可识别的空间特征图。
工作流程:接收4D控制信号(相机轨迹+3D高斯目标轨迹)→ 将信号渲染为背景RGB图、深度图、3D高斯轨迹热力图 → 编码为多通道空间特征 → 嵌入Wan2.1的扩散模块中,实现控制信号与生成过程的端到端融合。
优势:参数规模小(仅占Wan2.1的1%以下)、推理速度快、兼容性强,不影响骨干网络的生成效率。
顶层:4D控制信号处理模块
负责接收用户输入的相机轨迹(6自由度位姿序列)与目标轨迹(3D高斯参数序列),进行标准化处理与可视化渲染,生成GeoAdapter可接收的控制信号格式。
支持多种输入方式:手动编写轨迹参数、Blender插件导出轨迹、第三方3D工具生成轨迹等,适配不同创作者的使用习惯。
(二)4D控制信号:统一的时空控制状态
VerseCrafter的4D控制信号是实现精准控制的核心,采用“相机轨迹+多目标3D高斯轨迹”的统一表示方式,具体定义如下:
相机轨迹表示
采用6自由度位姿(3D平移+3D旋转)表示每一帧的相机状态,平移参数为(x, y, z)坐标,旋转参数为四元数(q_x, q_y, q_z, q_w)或欧拉角(roll, pitch, yaw)。
轨迹为时序序列,每一帧对应一个位姿,支持线性插值、贝塞尔曲线插值等平滑处理,确保相机运动流畅无跳变。
多目标3D高斯轨迹表示
采用3D高斯模型表示目标物体,每个目标由一组高斯核参数定义:位置(x, y, z)、缩放(s_x, s_y, s_z)、旋转(四元数)、颜色(RGB)、不透明度(α)。
每个目标的轨迹为时序序列,每一帧对应一组高斯参数,支持多个目标独立定义,实现多目标协同运动。
优势:3D高斯模型能高效表示复杂物体的3D结构与运动,且渲染速度快,适配实时控制与推理需求。
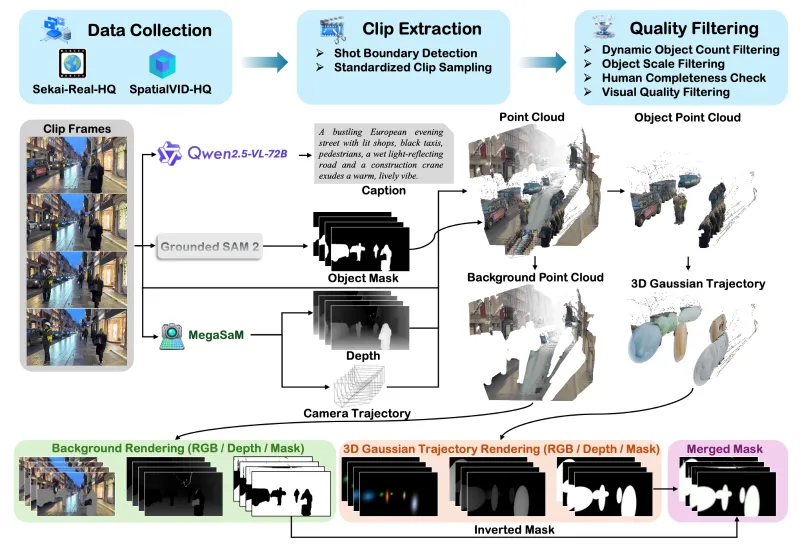
(三)VerseControl4D数据集:大规模4D几何监督信号
VerseCrafter的训练依赖配套的VerseControl4D数据集,这是目前业内规模最大的4D可控视频生成数据集,核心特点如下:
数据规模:包含数十万条视频片段,总时长超过1000小时,覆盖室内、室外、自然、城市、动态、静态等全类型场景,多目标运动场景占比超过60%。
数据标注:自动提取精准的相机位姿序列与多目标3D高斯轨迹序列,标注精度达到亚像素级,为模型训练提供高质量的4D几何监督信号。
数据来源:从海量真实野生视频中筛选,结合自动标注工具(如Grounded-SAM-2、MoGe、3D高斯拟合工具)完成标注,无需人工干预,数据质量与规模兼顾。
数据用途:用于监督VerseCrafter的GeoAdapter模块训练,让模型学习“4D控制信号→视频生成”的映射关系,确保控制信号能精准驱动视频生成过程。
(四)关键技术流程:从输入到输出的全链路逻辑
VerseCrafter的推理流程分为输入处理→控制信号编码→骨干生成→视频输出四个步骤,具体如下:
输入处理:用户输入文本提示(描述场景内容)+ 4D控制信号(相机轨迹+目标轨迹),系统对控制信号进行标准化、插值平滑处理,确保时序一致性。
控制信号编码:GeoAdapter将处理后的4D控制信号渲染为RGB图、深度图、热力图,编码为多通道空间特征图,注入Wan2.1的各扩散层。
骨干生成:Wan2.1骨干网络接收文本提示与控制特征图,通过扩散过程逐步生成视频帧,每一步生成均受4D控制信号的监督,确保几何与运动符合预期。
视频输出:生成的帧序列经过后处理(如去噪、分辨率提升、帧率优化),输出为MP4、MOV等格式的视频文件,支持自定义分辨率(如720P、1080P、4K)与帧率(如24fps、30fps、60fps)。
(五)技术对比:VerseCrafter与传统视频生成模型的差异
为更清晰体现VerseCrafter的技术优势,下表对比其与传统文本驱动视频生成模型、单维度控制视频生成模型的核心差异:
| 技术维度 | VerseCrafter | 传统文本驱动视频生成模型 | 单维度控制视频生成模型 |
|---|---|---|---|
| 控制维度 | 4D(3D空间+1D时间),相机+多目标协同控制 | 2D,仅文本驱动,无几何控制 | 2.5D,单维度控制(如相机、单目标) |
| 几何保真度 | 高,无穿模、形变,空间关系准确 | 低,易出现穿模、形变、比例失调 | 中,仅单维度可控,多目标易混乱 |
| 时空一致性 | 高,长时序视频运动流畅、结构稳定 | 低,帧间跳变、运动逻辑混乱 | 中,单维度一致,多维度易冲突 |
| 生成质量 | 高,保留Wan2.1的顶尖生成能力 | 高(如Wan2.1、Sora),但不可控 | 中,可控性提升但生成质量下降 |
| 算力成本 | 低,冻结骨干,仅训练GeoAdapter | 高,需训练整个骨干网络 | 中,需微调部分骨干参数 |
| 适用场景 | 影视、游戏、VR、教育等需精准控制的场景 | 创意短视频、内容填充等无严格控制需求的场景 | 简单视角切换、单目标动画等基础场景 |
四、应用场景
VerseCrafter的4D几何可控能力与高保真生成特性,使其能覆盖内容创作、虚拟现实、游戏开发、教育仿真、互动媒体等五大核心领域,具体应用场景如下:
(一)影视与广告创作:精准镜头调度,提升内容生产效率
影视镜头预演:导演可通过VerseCrafter快速生成镜头调度方案,自定义相机轨迹与角色运动轨迹,提前预览影视片段的视觉效果,减少实地拍摄与后期制作成本,缩短创作周期。
广告视频制作:针对产品展示、品牌宣传等广告场景,精准控制相机环绕产品运动、多产品协同展示,生成高质量、高可控的广告视频,满足品牌方的个性化需求。
动画短片创作:无需专业动画制作工具,通过文本描述+4D控制信号,快速生成角色动画、场景动画,降低动画创作的技术门槛,助力独立创作者产出优质内容。
(二)虚拟现实(VR)与增强现实(AR):构建高沉浸感交互场景
VR虚拟空间构建:生成可自由探索的3D虚拟场景,支持用户自定义相机(视角)运动轨迹,实现VR场景的全景漫游、互动探索,提升VR体验的沉浸感与自由度。
AR内容叠加:将生成的4D可控动态目标(如虚拟角色、道具)叠加到真实场景中,精准控制目标的运动轨迹与姿态,实现AR互动体验(如AR游戏、AR教育、AR营销)。
虚拟直播与数字人:生成可控的数字人运动轨迹,结合实时相机控制,实现虚拟直播中的数字人互动、场景切换,打造高互动性的虚拟直播内容。
(三)游戏开发:快速生成动态内容,优化开发流程
游戏场景填充:为游戏中的开放世界、副本场景生成动态背景(如移动的车辆、奔跑的动物、飘动的云朵),精准控制目标运动轨迹,提升游戏场景的真实感与活跃度。
游戏动画制作:快速生成游戏角色的动作动画、技能特效动画,自定义角色运动路径与姿态变化,减少美术人员的动画制作工作量,缩短游戏开发周期。
游戏镜头设计:为游戏剧情、过场动画设计相机轨迹与角色协同运动,生成高质量的过场视频,提升游戏的叙事性与视觉体验。
(四)教育与仿真:搭建高拟真度教学模拟环境
学科教学演示:针对物理、化学、生物、历史等学科,生成可控的动态演示视频(如分子运动、天体运行、历史事件还原、工程装配演练),精准控制运动轨迹与视角,帮助学生理解抽象知识。
职业技能仿真:为医疗、机械、航空等职业技能培训搭建仿真场景,生成可控的操作流程视频(如手术操作、机械维修、飞行模拟),让学员通过可视化视频掌握操作技能。
安全教育培训:生成火灾、地震、交通事故等应急场景的动态视频,精准控制事件发展轨迹与视角,提升安全教育培训的真实性与警示效果。
(五)互动媒体与内容创新:打造新型交互体验
分支剧情视频:生成多分支剧情的互动视频,观众可通过选择相机视角或目标运动轨迹,主动影响视频剧情发展,打造“观众参与创作”的新型内容形态。
视角可选式短片:为同一视频生成多个相机轨迹版本,观众可自由切换视角(如第一人称、第三人称、上帝视角)观看,提升视频的互动性与观赏性。
数字艺术创作:艺术家可通过自定义4D控制信号,生成抽象的动态艺术视频,实现“几何可控+创意表达”的结合,拓展数字艺术的创作边界。
五、使用方法
VerseCrafter提供完整的开源代码、环境配置脚本、推理脚本与模型权重,支持本地部署与推理,同时兼容Blender插件进行轨迹设计,具体使用方法分为环境部署、权重下载、推理运行、Blender插件使用四个步骤,详细说明如下:
(一)环境部署:快速搭建运行环境
VerseCrafter基于Python 3.11开发,依赖PyTorch、CUDA、第三方库(如Grounded-SAM-2、MoGe、pytorch3d等),推荐使用Conda进行环境管理,具体步骤:
克隆仓库:
git clone https://github.com/TencentARC/VerseCrafter.git cd VerseCrafter
创建Conda环境:
conda create -n versecrafter python=3.11 conda activate versecrafter
安装核心依赖:
# 安装PyTorch(CUDA 12.1,根据自身CUDA版本调整) pip3 install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121 # 安装项目依赖清单 pip install -r requirements.txt
安装第三方依赖(关键,需按顺序安装):
# 安装Grounded-SAM-2(目标检测与分割) pip install git+https://github.com/facebookresearch/grounded-sam-2.git # 安装MoGe(相机位姿估计) pip install git+https://github.com/facebookresearch/omnidata.git # 安装pytorch3d(3D几何处理) pip install pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py311_cu121_pyt230/download.html # 安装flash-attn(加速推理) pip install flash-attn --no-build-isolation
环境验证:运行
python -c "import torch; print(torch.cuda.is_available())",若输出True则环境部署成功。
(二)权重下载:获取模型与检测权重
VerseCrafter需下载VerseCrafter模型权重、Wan2.1骨干权重、检测模型权重三类文件,均通过Hugging Face Hub下载,具体步骤:
创建权重目录:
mkdir -p weights/verscrafter weights/wan2.1 weights/detection
下载VerseCrafter模型权重:
huggingface-cli download TencentARC/VerseCrafter --local-dir weights/verscrafter
下载Wan2.1-T2V-14B骨干权重:
huggingface-cli download TencentARC/Wan2.1-T2V-14B --local-dir weights/wan2.1
下载检测模型权重(Grounded-SAM-2、Grounding DINO):
# Grounded-SAM-2权重 huggingface-cli download facebookresearch/grounded-sam-2 --local-dir weights/detection/grounded_sam2 # Grounding DINO权重 huggingface-cli download IDEA-Research/GroundingDINO --local-dir weights/detection/grounding_dino
权重验证:检查权重目录下是否包含
.bin、.pth等格式的权重文件,确保文件完整无缺失。
(三)推理运行:生成4D可控视频
VerseCrafter提供脚本推理与API服务两种推理方式,推荐新手使用脚本推理,具体步骤:
方式1:脚本推理(快速上手)
准备输入文件:
文本提示:在
demo_data/prompts.txt中编写场景描述(如“a deer running in the forest, camera moving forward slowly”)。4D控制信号:在
demo_data/trajectories/目录下放置相机轨迹(camera_trajectory.json)与目标轨迹(target_trajectories.json),可使用示例数据快速测试。运行推理脚本:
# 基础推理(使用示例数据) bash inference.sh # 自定义输入推理 python inference/versecrafter_inference.py \ --prompt "your text prompt" \ --camera_trajectory "path/to/camera_trajectory.json" \ --target_trajectories "path/to/target_trajectories.json" \ --output_dir "path/to/output" \ --resolution 1080p \ --fps 30
查看输出:生成的视频文件保存在
output/目录下,格式为MP4,可直接播放查看效果。
方式2:API服务(批量/远程调用)
启动模型服务:
python model_server.py --port 8000 --weights_dir weights/
启动API服务:
python api_server.py --port 8001 --model_server_url http://localhost:8000
调用API:通过POST请求向
http://localhost:8001/generate发送输入参数(文本提示、轨迹文件、输出参数),示例请求:
{
"prompt": "a car driving on the road, camera circling around the car",
"camera_trajectory": "base64_encoded_camera_trajectory.json",
"target_trajectories": "base64_encoded_target_trajectories.json",
"resolution": "1080p",
"fps": 30,
"output_format": "mp4"
}获取结果:API返回生成视频的Base64编码或下载链接,可直接解析使用。
(四)Blender插件使用:可视化设计4D轨迹
VerseCrafter提供Blender插件,支持在Blender中可视化设计相机轨迹与目标轨迹,导出后直接用于推理,具体步骤:
安装插件:
打开Blender(推荐3.6及以上版本),进入
编辑→偏好设置→插件→安装,选择blender_addon/verscrafter_blender_addon.py文件,启用插件。设计轨迹:
相机轨迹:在Blender中创建相机,通过关键帧设置相机的位置与旋转,生成相机运动轨迹。
目标轨迹:在Blender中创建3D模型(或使用内置模型),通过关键帧设置模型的位置、缩放、旋转,生成目标3D高斯轨迹。
导出轨迹:
点击Blender右侧面板的
VerseCrafter选项,选择Export Trajectories,导出相机轨迹(camera_trajectory.json)与目标轨迹(target_trajectories.json)。推理使用:将导出的轨迹文件输入VerseCrafter推理脚本,生成对应视频。
六、常见问题解答(FAQ)
Q:安装PyTorch时提示CUDA版本不匹配怎么办?
A:根据自身GPU的CUDA版本调整PyTorch安装命令,例如CUDA 11.8可使用pip3 install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu118;若为CPU版本,可使用pip3 install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0(仅支持推理,速度较慢)。
Q:安装Grounded-SAM-2或pytorch3d失败怎么办?
A:① 确保C++编译环境正常(Windows需安装Visual Studio,Linux需安装gcc/g++);② 升级pip版本:pip install --upgrade pip;③ 参考官方仓库的安装指南(Grounded-SAM-2:https://github.com/facebookresearch/grounded-sam-2,pytorch3d:https://pytorch3d.org/),手动编译安装。
Q:运行时提示“缺少xxx库”怎么办?
A:根据提示安装对应的库,例如缺少opencv-python可执行pip install opencv-python,缺少numpy可执行pip install numpy;若为版本冲突,可使用pip install xxx==版本号指定兼容版本。
Q:Hugging Face下载速度慢怎么办?
A:① 使用Hugging Face镜像源:export HF_ENDPOINT=https://hf-mirror.com;② 安装huggingface-cli后,使用--local-dir-use-symlinks False参数避免符号链接问题;③ 手动从Hugging Face网页下载权重文件,复制到对应目录。
Q:权重文件缺失或损坏怎么办?
A:重新执行下载命令,或手动下载缺失的权重文件;若为压缩包格式,需解压后放置到对应目录。
Q:是否需要下载全部Wan2.1权重?
A:是的,VerseCrafter依赖Wan2.1-T2V-14B的完整权重,缺失部分权重会导致推理失败。
Q:推理时提示“CUDA out of memory”怎么办?
A:① 降低分辨率(如从1080P改为720P);② 降低帧率(如从30fps改为24fps);③ 减少目标数量(控制在3个以内);④ 使用更小的batch size(推理脚本中默认batch size为1,无需调整);⑤ 更换显存更大的GPU(推荐24GB及以上显存)。
Q:生成视频的运动轨迹与预期不符怎么办?
A:① 检查轨迹文件的参数是否正确(如相机位姿、目标高斯参数);② 对轨迹进行平滑插值处理(Blender插件中可开启“轨迹平滑”功能);③ 调整文本提示,确保文本描述与轨迹逻辑一致(如文本提示“camera moving forward”,轨迹需为向前运动);④ 增加控制信号的权重(推理脚本中可调整control_weight参数,默认1.0)。
Q:生成视频出现穿模、形变怎么办?
A:① 优化目标3D高斯参数,确保缩放与旋转符合真实物体比例;② 减少目标之间的重叠,避免轨迹冲突;③ 调整相机视角,避免近距离拍摄导致的几何失真;④ 使用更高质量的轨迹文件(如Blender中精细设计的轨迹)。
Q:推理速度慢怎么办?
A:① 启用flash-attn加速(已在环境部署中安装,默认开启);② 使用FP16精度推理(推理脚本中添加--fp16参数);③ 降低分辨率与帧率;④ 使用多GPU并行推理(修改model_server.py中的device_ids参数)。
Q:Blender中安装插件失败怎么办?
A:① 确保Blender版本为3.6及以上;② 检查插件文件是否完整,无损坏;③ 重启Blender后重新安装;④ 手动将插件文件复制到Blender的插件目录(Blender.app/Contents/Resources/3.6/scripts/addons/)。
Q:导出的轨迹文件无法被VerseCrafter识别怎么办?
A:① 确保导出的轨迹文件为JSON格式,参数名称与示例文件一致;② 检查轨迹的帧数量与推理脚本中的num_frames参数匹配;③ 避免导出空轨迹(相机或目标无关键帧)。
Q:VerseCrafter支持Windows/Linux/macOS系统吗?
A:支持Linux与Windows系统(推荐Linux,推理速度更快);macOS系统仅支持CPU推理,不支持GPU加速,不推荐使用。
Q:VerseCrafter支持自定义场景与目标吗?
A:支持,可通过文本描述自定义场景内容,通过3D高斯轨迹自定义目标物体,无需额外训练。
七、相关链接
GitHub开源仓库:https://github.com/TencentARC/VerseCrafter
Hugging Face模型仓库:https://huggingface.co/TencentARC/VerseCrafter
八、总结
VerseCrafter作为复旦大学、香港大学与腾讯ARC Lab联合开源的4D几何可控动态真实视频世界模型,突破了传统AI视频生成“几何不可控、时空一致性差”的核心瓶颈,通过冻结Wan2.1骨干网络+轻量化GeoAdapter模块的创新架构,实现了对相机运动、多目标3D轨迹及二者协同关系的显式4D控制,同时依托VerseControl4D大规模数据集的强监督,保障了生成视频的高保真度与强泛化能力。该项目不仅提供了完整的开源代码、环境配置、推理脚本与多工具兼容方案,降低了可控视频生成的技术与算力门槛,还覆盖了影视创作、VR/AR、游戏开发、教育仿真等多领域应用场景,为AIGC内容生产从“随机生成”向“精准可控”升级提供了核心技术支撑。其Apache 2.0的开源协议与完善的官方资源,也为研究者与开发者提供了自由探索、二次开发与工业落地的广阔空间,是当前可控视频生成领域极具实用价值与创新意义的开源项目。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/versecrafter.html





