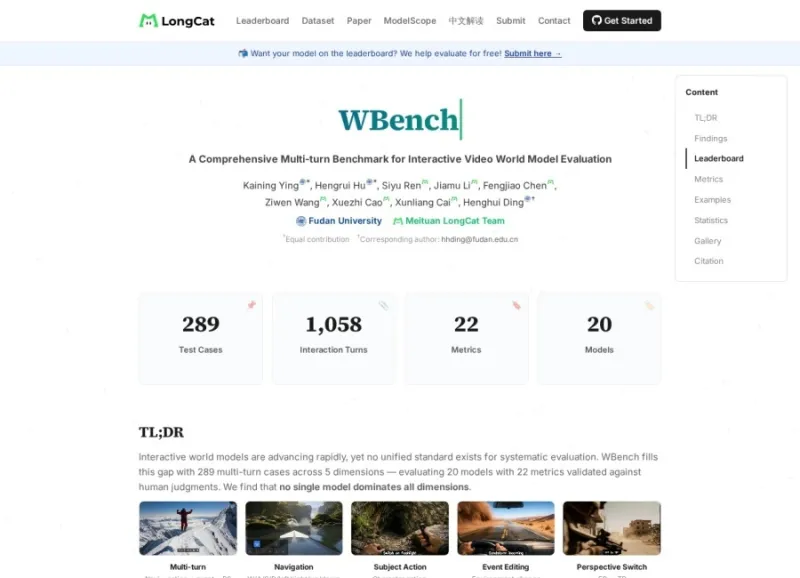
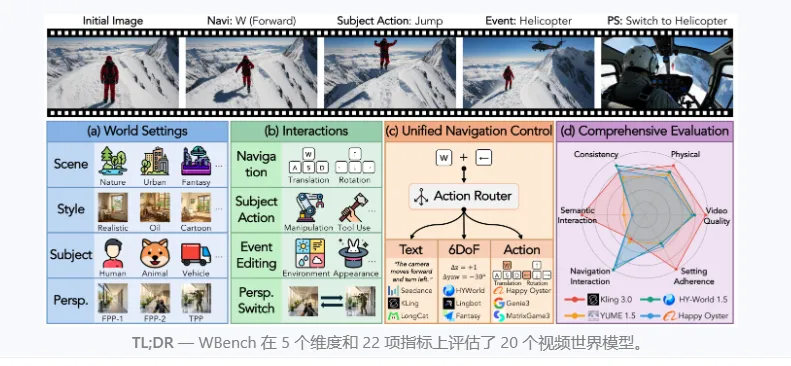
WBench:美团联合复旦开源的AI视频交互能力标准化评测基准
一、WBench 是什么
WBench 是由美团 LongCat 团队联合复旦大学共同推出的开源系统性评测基准,也是业内首个专门面向交互式视频世界模型打造的多轮交互评测体系,聚焦解决当前AI视频模型评测维度单一、无法验证连续交互能力、物理逻辑与时空一致性缺失等行业痛点。
在AIGC视频领域,传统评测方案大多仅针对单帧画面画质、视频流畅度、文本匹配度做基础打分,完全忽略多轮人机交互、场景状态延续、现实物理规则、视角切换逻辑等核心能力。而交互式视频世界模型区别于普通文生视频、图生视频模型,核心价值在于支持用户持续下达指令、动态改变场景与物体状态、完成连续动作交互,这类模型也是虚拟仿真、数字人、沉浸式互动视频、机器人视觉等方向的底层核心。
WBench 以此为切入点,构建了完整的数据集、评测指标、自动化打分体系与运行框架,能够全方位量化交互式视频世界模型的综合能力,为模型研发、算法迭代、产品选型提供客观、可信、标准化的评测依据。项目整体开源开放,数据集、评测代码、测试案例全部对外共享,面向全球开发者、科研人员与企业技术团队使用。
二、功能特色
WBench 围绕交互式视频交互场景设计全套能力,功能覆盖数据集、多维度评测、自动化评估、多范式兼容等多个模块,核心特色如下:
全场景多轮交互测试能力
内置289个标准化测试案例、总计1058个连续交互轮次,覆盖真实使用中高频出现的连续指令交互场景,打破传统单轮视频评测的局限,精准检验模型长序列交互稳定性。双视角兼容设计
原生支持第一人称、第三人称两大主流视频视角,适配沉浸式第一视角仿真、常规第三人称互动视频两类主流产品形态,适用范围更广。四大交互类型全覆盖
完整收录行业主流交互形式:导航移动、主体动作操控、场景事件编辑、镜头视角切换,覆盖交互式视频90%以上的业务交互需求。高可信度自动化评测体系
设计22项精细化自动化评估指标,自动化打分结果与人工评测结果相关系数≥0.94,大幅降低人工测评成本,同时保证评测数据客观、准确。多控制范式兼容
支持文本指令、位姿控制、离散动作等当下主流的AI视频控制方式,可对不同技术路线的交互式视频模型进行横向公平对比。轻量化开源部署
代码架构简洁,依赖环境配置简单,本地、服务器均可快速部署运行,个人开发者、小型实验室、企业研发团队都能低成本上手。
三、技术细节
3.1 整体架构
WBench 整体分为数据层、交互执行层、评测计算层、结果输出层四层架构,各模块解耦独立,可单独扩展与二次开发:
数据层:核心为标准化测试数据集,统一存储交互指令、场景初始状态、标准参考视频、判定规则等基础数据,数据格式规范化,支持自定义案例拓展。
交互执行层:作为中间调度模块,负责向待测视频模型下发多轮交互指令,接收模型输出的连续视频流,记录每一轮交互前后的场景变化、物体状态、镜头信息。
评测计算层:项目核心模块,集成22项评估算法,从时空一致性、物理合理性、指令跟随度、画面连续性、交互逻辑性等维度完成自动化打分。
结果输出层:自动生成可视化评测报告、分数榜单、问题定位日志,直观展示模型优势与能力短板。
3.2 核心评测维度与指标分类
项目划分五大核心评测维度,所有22项自动化指标均归属对应维度,下表为维度说明与核心检测方向:
| 评测维度 | 核心检测内容 | 作用说明 |
|---|---|---|
| 指令跟随能力 | 模型是否精准执行每一轮文本/动作指令、指令理解准确率 | 检验模型对人类交互指令的解析与执行能力 |
| 时空一致性 | 连续帧、多轮交互中物体位置、形态、场景布局是否错乱 | 规避视频画面跳变、物体凭空消失/生成等问题 |
| 物理逻辑合规性 | 物体运动、碰撞、受力、姿态是否符合现实物理规则 | 区分“视觉好看”与“逻辑合理”,适配仿真类场景 |
| 交互连续性 | 多轮指令衔接过程中,场景状态能否持续延续 | 考核模型长序列记忆与状态保持能力 |
| 视角与画面质量 | 镜头切换流畅度、画面清晰度、动作衔接自然度 | 兼顾交互逻辑与基础视频视觉体验 |
3.3 技术依赖与运行环境
项目基于Python主流技术栈开发,适配主流深度学习运行环境,基础依赖如下:
# 核心运行依赖 Python >= 3.8 PyTorch / TensorFlow(兼容主流深度学习框架) OpenCV(视频帧解析与画面处理) NumPy、Pandas(数据计算与结果统计) Matplotlib(评测报告可视化绘图)
框架无强绑定限制,开发者可根据自身待测模型的技术栈灵活适配,同时支持Linux、Windows两大操作系统部署。
3.4 打分算法逻辑
自动化评测采用多特征融合打分机制:首先对视频逐帧提取视觉特征、物体坐标、运动轨迹、语义特征,再结合交互指令语义做匹配计算;单轮交互得出分项分数后,加权计算综合得分,最终汇总所有交互轮次、所有测试案例得到模型整体评分。全程无需人工干预,输出结果可复现。
四、应用场景
WBench 定位为通用型交互式视频模型评测工具,面向科研、企业研发、产品选型、算法竞赛等多类人群,具体应用场景分为以下几类:
AI视频模型研发迭代
算法工程师可使用本基准常态化测试自研交互式视频模型,快速定位模型在多轮交互、物理逻辑、时空一致性上的缺陷,针对性优化算法。学术科研与论文实验
高校、实验室可将WBench作为标准评测数据集与基准,用于交互式世界模型相关论文的实验论证、数据对比,统一行业实验标准。虚拟仿真与机器人视觉测评
机器人仿真、工业虚拟场景、自动驾驶视觉交互等场景,可借助本工具测试视觉交互模块的连续指令执行能力与物理模拟能力。数字人与互动视频产品评测
互动短剧、虚拟数字人直播、沉浸式互动视频等产品,可用来评测底层视频生成模型的交互稳定性,保障终端用户体验。模型横向选型与对比
企业技术团队在采购、接入第三方交互式视频模型时,可通过统一基准完成多款模型公平对比,筛选适配业务的最优方案。AI算法赛事标准题库
可作为视频交互类算法竞赛的标准测试集与评分规则,保证赛事评分公平、统一。
五、使用方法
整体使用流程分为环境准备、数据集获取、配置待测模型、执行评测、查看结果五大步骤,操作流程简洁,步骤如下:
5.1 环境部署
确保本地/服务器已安装
Python 3.8及以上版本。通过 pip 安装项目所需依赖包,执行命令:
pip install -r requirements.txt
根据待测模型框架,安装对应深度学习库(PyTorch/TensorFlow)。
5.2 获取项目代码与数据集
拉取官方 GitHub 源码仓库:
git clone https://github.com/meituan-longcat/WBench.git cd WBench
前往官方数据集地址下载完整测试案例、参考视频与配置文件,放置到项目指定
datasets目录下。
5.3 接入待测模型
修改项目目录下 model_config.py 配置文件,填入待测交互式视频模型的调用接口、输入输出格式、指令交互规则,完成模型对接。
# model_config.py 基础配置示例 MODEL_API = "待测模型接口地址" INPUT_TYPE = "text_pose" # 支持 text / pose / action 三种类型 VIEW_MODE = "first_person" # first_person / third_person
5.4 启动自动化评测
执行主运行脚本,开始全案例自动化评测:
python run_benchmark.py
脚本会自动遍历所有289个测试案例,依次下发多轮交互指令,调用模型生成视频并完成打分。
5.5 查看评测结果
评测结束后,结果自动保存至 output/report 目录:
文本日志:记录每一个案例、每一轮交互的分项得分与异常信息;
可视化图表:展示五大维度得分分布、模型能力雷达图;
综合榜单:生成模型整体总分与排名。
5.6 自定义拓展(可选)
开发者可在 custom_cases 目录下新增自定义交互测试案例,按照官方数据格式编写指令与场景规则,实现业务场景定制化评测。
六、竞品对比
选取当前视频领域主流评测基准,与 WBench 做横向对比,本次选取VideoBench、GenAI-Video-Eval两款主流评测工具,从定位、交互能力、评测维度、自动化程度、适用场景五大维度对比:
| 对比项 | WBench | VideoBench | GenAI-Video-Eval |
|---|---|---|---|
| 产品定位 | 交互式视频世界模型多轮交互专项评测基准 | 通用文生视频单轮评测工具 | 多模态视频生成综合评测框架 |
| 交互能力支持 | 支持多轮连续交互、双视角、四类交互动作 | 仅支持单轮指令,无连续交互逻辑检测 | 以单轮生成为主,弱交互支持 |
| 核心评测维度 | 指令跟随、时空一致性、物理逻辑、交互连续性、画面质量 | 画质、文本匹配度、视频流畅度 | 画面美学、语义匹配、风格还原度 |
| 自动化程度 | 全流程自动化打分,人工相关系数≥0.94 | 半自动化,部分维度需人工复核 | 自动化为主,复杂逻辑需人工辅助 |
| 核心适用场景 | 交互式世界模型、虚拟仿真、互动视频、机器人视觉 | 普通文生视频、短视频生成模型 | 多模态图文转视频、风格化视频生成 |
总结差异:VideoBench 与 GenAI-Video-Eval 均偏向传统单轮视频生成评测,侧重画面与语义匹配;而 WBench 是业内首个聚焦多轮交互式视频的专项基准,在交互逻辑、物理规则、长序列状态保持上具备不可替代的优势,精准填补细分领域空白。
七、常见问题解答
Q1:WBench 只能用于美团自研模型评测吗?
A:并非仅限美团内部模型,项目完全开源开放,支持所有第三方、自研、开源类交互式视频世界模型接入使用,无厂商限制。
Q2:部署 WBench 对服务器硬件要求高吗?
A:评测框架本身硬件需求较低,普通CPU服务器即可运行;硬件压力主要来自待测视频生成模型,可根据自身模型配置对应算力设备。
Q3:是否支持新增自定义测试案例?
A:支持。项目预留了自定义案例接口,开发者按照官方数据格式编写交互指令、场景规则与参考标准,即可拓展专属测试场景。
Q4:自动化打分结果可以作为正式论文实验数据吗?
A:可以。官方标注自动化评分与人工评测相关系数不低于0.94,数据可信度高,目前已被多篇学术论文采用作为标准实验基准。
Q5:项目支持非中文/英文指令的交互评测吗?
A:原生支持中英文指令,若需适配其他语言,可修改指令解析模块的语义识别组件,完成二次适配。
Q6:运行评测时出现视频解析失败如何解决?
A:首先检查OpenCV依赖是否完整安装,其次确认数据集内视频文件格式统一为通用MP4格式,最后核对文件路径配置是否正确。
八、相关链接
九、总结
WBench 是美团 LongCat 团队联合复旦大学打造的开源交互式视频世界模型专用评测基准,针对传统视频评测工具无法检测多轮交互、物理逻辑、时空一致性的行业短板,搭建了包含标准化数据集、多维度评估指标、全自动化打分体系的完整评测方案。项目依托289个测试案例与千余组交互轮次,覆盖第一/第三人称视角及四类主流交互形式,兼容多种模型控制范式,部署简单、拓展性强,既能够满足企业研发团队对交互式视频模型迭代优化、产品选型的需求,也可为高校科研、算法竞赛提供统一标准的实验基准。作为细分赛道首款专项评测工具,WBench 补齐了交互式视频世界模型的评测体系短板,为整个交互式AIGC视频领域建立了客观、可复用、开源共享的评测规范。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/wbench.html