Yuan3.0 Ultra:浪潮的开源万亿参数多模态大模型,企业级智能体高效底座
一、Yuan3.0 Ultra是什么
Yuan3.0 Ultra是浪潮信息旗下YuanLab.ai团队开源的万亿参数级多模态基础大模型,是当前全球范围内少数开源的万亿参数多模态大模型之一。它以“高性能、高效率、高企业适配性”为设计目标,采用统一多模态架构与MoE混合专家架构,通过自研训练与推理优化技术,在保持万亿参数能力的同时,大幅降低训练与推理成本,专为企业级复杂AI应用、多模态智能体、文档数据处理等场景打造。
该模型从设计之初就面向产业落地,兼顾学术研究与商业使用,完整开源模型权重、训练代码、推理框架、技术报告与评测数据,支持学术研究与合规商业二次开发,是企业搭建私有大模型、构建行业智能体的理想底层底座。
核心定位:
万亿参数、开源开放、多模态统一
企业级场景深度优化
高效训练与高效推理兼顾
支持智能体、RAG、文档处理、数据查询等核心企业任务

二、功能特色
Yuan3.0 Ultra围绕“能力强、效率高、企业好用、生态开放”四大方向构建核心功能,在保持通用大模型能力的同时,重点强化企业场景刚需能力。
1. 万亿参数规模,轻量激活运行
模型总参数1010B,但推理时仅激活68.8B参数,在保持万亿级模型理解与推理能力的同时,显著降低显存与算力消耗,让万亿模型可在常规GPU集群上部署运行。
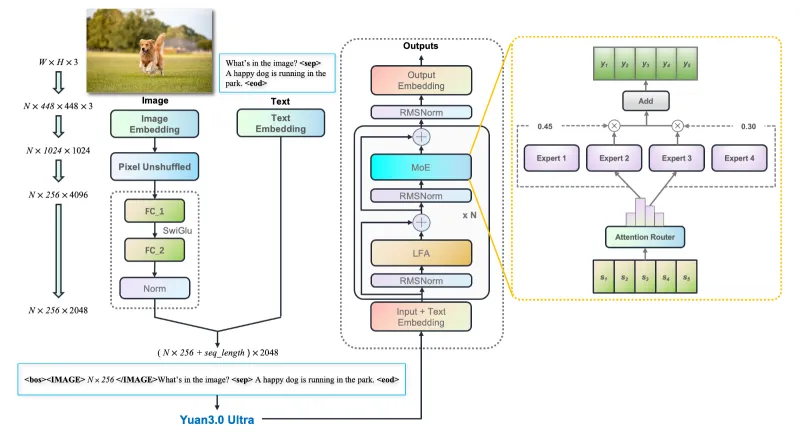
2. 统一多模态架构,图文表格统一理解
采用“视觉编码器+语言主干+多模态对齐模块”一体化架构,支持文本、图像、表格、图文混排文档的统一输入与理解,可直接处理PDF、扫描件、报表、合同等企业常见文档类型。
3. 企业级任务能力拉满
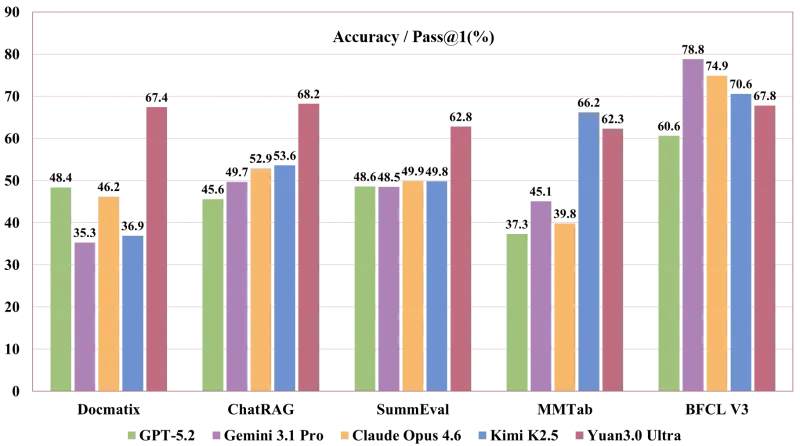
在多个企业场景权威基准上达到领先水平:
多模态文档理解(DocMatix)
检索增强生成(ChatRAG)
复杂表格理解(MMTab)
文本转SQL(Spider/BIRD)
长文本摘要(SummEval)
智能体工具调用(BFCL)
4. 训练效率大幅提升
自研LAEP层自适应专家剪枝算法,在预训练阶段动态裁剪低贡献专家,将模型从初始1515B优化至1010B,**预训练算力效率提升49%**,显著降低万亿模型训练成本与周期。
5. 推理更精准、更简短
创新RIRM反射抑制奖励机制,优化强化学习过程,让模型“少废话、答对题”,推理准确率提升16.33%,输出token长度减少14.38%,降低推理计费与时延。
6. 语义建模更强
引入LFA局部滤波注意力机制,相比传统Attention结构更擅长捕捉长距离语义依赖与复杂逻辑关系,在文档理解、逻辑推理、表格分析上表现更稳定。
7. 开源完整、开箱即用
开源内容包括:
模型权重(16bit / 4bit量化)
训练代码(Megatron-LM、VERL、RLHF)
推理优化(vLLM深度适配)
技术报告PDF
评测数据与复现脚本
8. 支持商业使用与二次开发
采用友好开源协议,支持企业私有化部署、模型微调、行业适配、产品化落地,无需依赖公有云API,数据安全可控。
三、技术细节
Yuan3.0 Ultra的技术竞争力来自架构创新、训练优化、推理加速三大层面,是一套完整的万亿模型工程化方案。
1. 模型整体架构
采用统一多模态MoE架构:
视觉编码器:负责图像特征提取
多模态对齐模块:将视觉token与语言token映射到同一语义空间
语言主干:103层Transformer + MoE混合专家架构
注意力层:LFA局部滤波注意力
2. MoE架构与LAEP专家剪枝
MoE(Mixture of Experts)是稀疏激活架构,每个token只激活部分专家网络,实现“大参数、低计算”。
但传统MoE存在专家负载不均、部分专家闲置问题。
Yuan3.0 Ultra提出LAEP(Layer-Adaptive Expert Pruning):
在训练稳定阶段自动识别低利用率专家
逐层裁剪冗余专家
配合专家重排算法均衡设备负载
参数量减少33%,训练效率提升49%
3. LFA局部滤波注意力
传统Attention容易在长文本中出现信息弥散。LFA机制:
对注意力权重做滤波筛选
强化关键信息权重
抑制噪声与冗余信息
提升语义建模精度与长文本稳定性
4. RIRM反射抑制奖励机制
针对大模型“过度思考、重复输出、步骤冗余”问题:
在Fast-thinking RL阶段重新设计奖励信号
对“正确且简短”的输出高奖励
对“错误且冗长”的输出强惩罚
最终准确率提升16.33%,token减少14.38%
5. 训练与推理栈
预训练:基于Megatron-LM分布式训练
对齐训练:VERL + RLHF
推理加速:深度适配vLLM,支持高并发、低时延、量化推理
部署支持:16bit / 8bit / 4bit量化,支持单卡/多卡/集群部署
6. 关键参数表
| 项目 | 参数值 |
|---|---|
| 总参数量 | 1010B |
| 激活参数量 | 68.8B |
| Transformer层数 | 103层 |
| 架构 | MoE稀疏激活 |
| 核心优化 | LAEP剪枝、RIRM奖励、LFA注意力 |
| 训练效率提升 | 49% |
| 输出token减少 | 14.38% |
| 模态支持 | 文本、图像、表格、文档 |
7. 性能表现(企业基准)
在DocMatix、ChatRAG、MMTab、Spider、SummEval、BFCL等企业任务上,Yuan3.0 Ultra达到国际第一梯队水平,尤其在中文文档、复杂表格、长文本理解上优势明显。
四、应用场景
Yuan3.0 Ultra的场景定位高度聚焦企业复杂信息处理,覆盖从文档办公到数据决策、从智能客服到自动研发的全链路。
1. 企业多模态文档处理
财报解析、合同审查、招标文件理解
PDF/图片/扫描件内容提取、结构化输出
大量文档批量审阅、风险点识别
2. 检索增强生成(RAG)
企业知识库智能问答
跨文档信息整合与摘要
内部资料精准检索与生成
3. 数据查询与分析(Text-to-SQL)
自然语言查询数据库
业务报表自动生成
多表关联、复杂查询自动生成
4. 长文本处理与内容生成
研究报告、方案、总结自动撰写
会议纪要、对话记录结构化
内容润色、续写、优化
5. 企业智能体(Agent)
流程自动化、多步骤工具调用
业务决策辅助、问题诊断
与OpenClaw等智能体框架深度兼容
6. 行业私有化大模型
金融、政务、制造、医疗、法律行业底座
私有化部署、数据不出域
行业数据微调、能力定制
7. 二次开发与研究
大模型架构研究、稀疏训练研究
多模态算法创新、注意力机制改进
高校/研究所科研实验平台
五、使用方法
Yuan3.0 Ultra提供完整开源栈,支持从模型下载、环境配置、推理运行到微调训练的全流程。
1. 获取开源资源
GitHub仓库:https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
包含:
README(中英)
模型权重下载链接
推理代码
训练代码
Docs技术报告
vLLM推理适配
2. 环境依赖
Python 3.8+
PyTorch 2.0+
CUDA 11.7+
vLLM(推理加速)
Megatron-LM(训练)
VERL(RLHF)
3. 模型下载
提供多种版本:
16bit浮点版(效果最好)
4bit量化版(显存占用低)
可从HuggingFace、ModelScope、始智AI、Wisemodel下载。
4. 快速推理(命令行)
克隆仓库
git clone https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra cd Yuan3.0-Ultra
安装依赖
pip install -r requirements.txt
运行推理脚本
python inference.py --model path/to/model --prompt "你的问题"
5. vLLM加速推理
项目内置vLLM适配,支持高并发、流式输出、批量请求,适合生产环境。
python vllm_infer.py --model path/to/model --port 8000
6. 微调与训练
基于rlhf目录进行SFT与RLHF训练
基于megatron-lm进行继续预训练
支持LoRA、全参数微调
7. 部署方式
单卡推理(消费级/专业卡)
多卡张量并行
集群分布式推理
API服务封装(FastAPI/Flask)
六、常见问题解答(FAQ)
Yuan3.0 Ultra可以商用吗?
可以,项目采用开源开放协议,支持企业合规商用、私有化部署、二次开发与产品化落地,具体可查看仓库LICENSE文件。
运行Yuan3.0 Ultra最低需要什么显卡?
4bit量化版本可在单张24GB显存显卡运行;16bit版本建议使用8×80GB A100/H100或同等配置集群;具体视序列长度与并发而定。
Yuan3.0 Ultra支持中文吗?
全面支持中文,在中文长文本、表格、文档、专业术语理解上做了深度优化,是面向中文企业场景的最优开源底座之一。
模型支持多模态输入吗?
支持,可同时处理文本、图像、表格、图文混排文档,具备统一多模态理解能力。
如何下载模型权重?
在GitHub仓库README中提供官方下载链接,包括HuggingFace、ModelScope、Wisemodel、始智AI等平台。
推理速度如何,是否支持流式输出?
官方适配vLLM推理引擎,支持高吞吐、低时延、流式输出,可直接用于在线服务。
能否在CPU上运行?
不推荐,模型规模大,CPU推理速度极慢,仅建议用于调试,正式使用必须使用NVIDIA显卡。
是否支持LoRA微调?
支持,提供SFT与RLHF完整训练脚本,支持LoRA、QLoRA高效微调,降低硬件门槛。
和Yuan3.0 Flash有什么区别?
Flash是40B参数轻量版;Ultra是万亿参数旗舰版,面向企业高复杂度任务,能力更强、场景更专业。
训练自己的行业数据需要多少数据量?
继续预训练建议百万级token以上;SFT建议数千条高质量指令数据;具体视行业差异而定。
模型支持多长上下文长度?
支持长上下文窗口,可处理企业级超长文档、多页PDF、长篇报告,具体可参考技术报告。
如何提交Bug或贡献代码?
通过GitHub Issues提交问题,通过Pull Request贡献代码,项目维护团队会定期处理。
七、相关链接
八、总结
Yuan3.0 Ultra是YuanLab.ai团队推出的开源万亿参数多模态基础大模型,以MoE稀疏架构为基础,通过LAEP层自适应专家剪枝、RIRM反射抑制奖励、LFA局部滤波注意力三大核心技术实现训练效率与推理效果的双重突破,总参数1010B、激活参数68.8B,在多模态文档理解、RAG、表格分析、Text-to-SQL、智能体工具调用等企业级任务上表现领先,同时提供完整训练、推理、部署代码与模型权重,支持学术研究与合规商业使用,可广泛应用于企业文档处理、知识问答、数据决策、行业私有化大模型、智能体系统等场景,是当前国内少数可直接落地的万亿级开源多模态大模型方案。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/yuan3-0-ultra.html





