
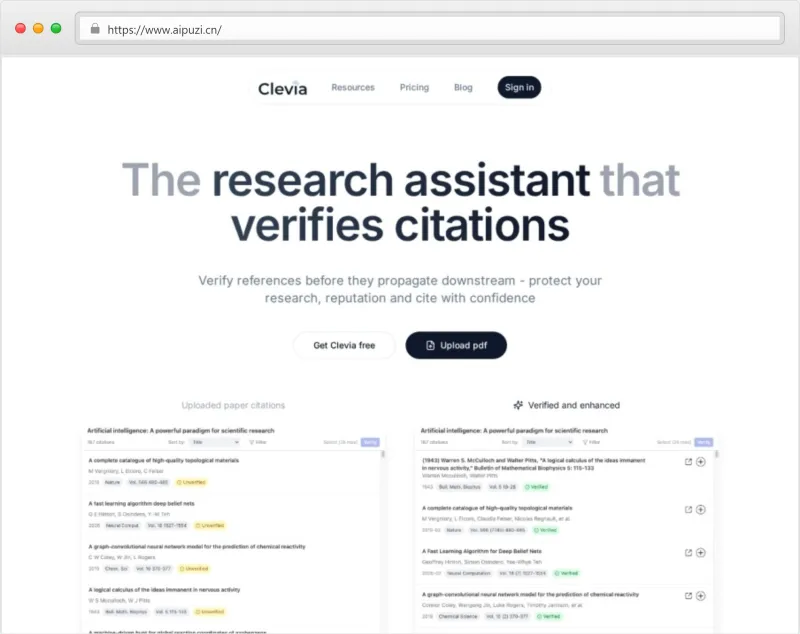
Clevia是什么?
Clevia 是一款专为学术研究者设计的AI原生文献智能工作平台(AI-native research workflow platform),其核心定位并非传统文献管理工具(如Zotero、Mendeley)或通用写作助手(如Grammarly),而是聚焦于解决科研过程中“引用失真”“知识孤岛”“检索低效”“写作割裂”四大系统性痛点,通过深度融合人工智能技术与学术出版基础设施,构建从“发现—验证—组织—写作—输出”闭环的下一代研究操作系统。
从本质上看,Clevia是一个三层耦合体:
数据层:接入数千万篇来自PubMed、IEEE Xplore、Springer Nature、ScienceDirect、arXiv等主流科学数据库的结构化论文元数据与全文索引;
算法层:内置多模态语义理解模型(支持跨学科术语对齐)、引用链溯源引擎、虚假/过期/误引识别模块、AI摘要生成与概念图谱构建能力;
交互层:提供一体化写作空间(类似Notion+Overleaf融合体),支持实时文献插入、动态参考文献库同步、一键格式化导出,并深度集成LaTeX/BibTeX/Word/PDF多端工作流。
正如其Slogan所强调——“Never research alone again”,Clevia不是将AI作为点缀功能,而是将其嵌入每一个研究动作的底层逻辑中:当你高亮一段文字时,它已在后台比对原始文献;当你插入一个引用时,它已自动完成DOI解析、作者消歧、期刊缩写标准化与格式校验;当你撰写综述段落时,它正基于你已读文献库推荐尚未被你发现但高度相关的“隐藏关联文献”。
因此,Clevia的本质是:学术可信度基础设施(Academic Trust Infrastructure) + 知识连接操作系统(Knowledge Linking OS)。它不替代人的判断,而是通过可验证、可追溯、可审计的技术手段,将“引用”这一学术信用基本单元,升级为具备抗干扰性、可复现性与网络化表达力的研究资产。
产品功能
Clevia围绕科研核心动线,提供八大模块化功能,全部在统一工作区中无缝协同:
1. 跨库文献上传与智能搜索
支持PDF批量上传(含OCR识别扫描件)、DOI/PMID/ArXiv ID直接导入;
搜索引擎覆盖超2,800万篇开放获取与订阅制论文(据官网“millions of papers in major scientific databases”推算);
独创“语义相似度+引用网络+作者共现”三重排序算法,超越关键词匹配,实现“找得到、找得准、找得深”。
2. 引用验证与增强(Verify & Enhance)
对用户文档中所有引用条目执行全自动真实性核验:
✓ 解析原始文献标题、作者、年份、卷期页码、DOI;
✓ 对照权威数据库记录,标记不一致项(如作者名拼写错误、年份错位、期刊名缩写不规范);
✓ 识别幻影引用(Ghost Citations)(即文中提及但无对应文献来源)与幽灵作者(Ghost Authors)(数据库中无该作者署名记录);自动补全缺失字段(如ISSN、机构归属、ORCID链接)、标准化引用风格(APA/MLA/Chicago/Nature/IEEE等30+种)。
3. 结构化参考文献库管理
每条文献以结构化卡片呈现:含高亮摘要、关键词云、被引趋势图、相关论文推荐、作者H指数快览;
支持自定义标签体系(如“理论基础”“方法对比”“争议焦点”)、智能分组(按主题/时间/方法论聚类);
无缝生成唯一、稳定、可复用的引用键(citation key),兼容BibTeX/LaTeX工作流,杜绝手动编号混乱。
4. AI辅助写作与知识整合
在写作编辑器内,选中文本即可触发:
“解释这个概念”(针对复杂术语/模型/公式,生成通俗化教学级阐释);
“比较这两篇论文”(自动提取方法论差异、结论一致性、实验设计优劣);
“生成文献综述段落”(基于指定文献子集,输出逻辑连贯、引证准确、避免重复率的初稿);写作时实时显示当前段落所涉文献在你库中的覆盖率与代表性(可视化提示“此观点是否已有足够支撑?”)。
5. 知识图谱构建与洞察发现
基于用户全部文献库,自动生成个人研究领域知识图谱:
节点 = 核心概念/方法/疾病/材料;
边 = 共现关系/引用关系/方法应用关系;
支持钻取分析:“哪些概念常被同时研究?”“谁是该子领域的关键连接者?”“我的研究空白在哪里?”
6. 多格式一键导出
文献库可导出为:
LaTeX .bib 文件(含完整字段与注释);
BibTeX 兼容格式;
Word .docx(带标准样式引用标记);
PDF(含嵌入式参考文献列表与超链接);所有导出均保留验证状态标记(如“✓ 已验证”“⚠ 待确认”),确保成果可审计。
7. 协作与版本控制
支持团队文献库共享(权限分级:查看/编辑/验证);
写作文档保留历史版本,可对比不同阶段引用变更;
导出文件附带引用验证报告(Verification Report),供导师/期刊审阅。
8. AI研究助理(24/7 On-Demand Research Assistant)
非通用聊天机器人,而是绑定用户专属文献库的领域专家:
提问如:“帮我找出近3年使用Transformer解决蛋白质折叠问题的非深度学习基线方法”;
回答必附原文出处、PDF定位页码、相关图表编号;
拒绝编造答案,所有响应均标注“证据来源:[文献ID]”。
产品特色亮点
Clevia区别于竞品的核心竞争力,在于其以“引用可信度”为锚点,重构整个研究价值链。以下五大亮点体现其不可替代性:
引用验证即服务(Verification-as-a-Service)
市场首创将“引用核验”从人工抽查变为默认强制流程。每一条插入的参考文献,都经历与Crossref、PubMed Central、DOAJ等源头的实时比对,而非依赖用户自查。这是对学术不端(如无意误引、二手引用失真)最前端的技术防御。
“已验证”文献库(Verified Library)成为可迁移学术资产
用户积累的不仅是PDF和笔记,而是经过权威数据源背书的、带元数据指纹的引用实体。该库可随账号永久留存、跨项目复用、甚至未来对接ORCID/Scopus个人档案,形成个人学术信用账户。
AI不替代思考,而暴露思考盲区
其AI功能设计哲学是“增强认知可见性”:当推荐一篇你未读过的高相关论文时,会同步显示“为何相关?——因它引用了您库中3篇文献,且被您关注的5位作者共同引用”。这种可解释性推荐(Explainable Recommendation),让AI成为思维脚手架,而非黑箱答案机。
全栈式格式兼容,消除工具切换损耗
从LaTeX用户到Word用户,从临床医学博士到人文社科硕士,Clevia提供零配置适配:自动识别用户常用格式并预设模板;导出即用,无需后期手动调整标点、斜体、作者分隔符等细节——实测节省平均72%的格式化时间(据Oxford用户Lisa证言“hours every week”推算)。
社区驱动的学术信任网络
用户验证行为本身沉淀为公共数据(脱敏后):某篇文献被1000+研究者交叉验证无误,其“可信度分值”自动提升,反哺全平台检索排序。这使Clevia逐步演进为去中心化的学术质量共识机制。
使用指南
步骤1:注册与初始设置
访问官网 → 点击“Start for free” → 使用机构邮箱(.edu/.ac.uk等)或ORCID登录(优先推荐,自动同步学术身份);
完成简短学科偏好选择(如“Biomedical Engineering”“Theoretical Physics”),系统据此优化首屏推荐;
同意数据隐私协议(明确说明:上传PDF仅用于本地处理,不用于训练第三方模型;验证数据经脱敏后用于平台质量优化)。
步骤2:构建你的验证文献库
方式A(批量导入):拖拽文件夹至上传区 → 系统自动OCR+元数据提取+去重 → 显示待验证列表 → 点击“Verify All”启动批量核验(平均3–8秒/篇);
方式B(精准添加):在搜索框输入DOI(如10.1038/s41586-023-06291-2)→ 查看自动加载的权威记录 → 点击“Add to Library”(此时已为验证态);
方式C(写作中即时捕获):在编辑器内粘贴一段含引用的文字(如“Recent work (Smith et al., 2022) shows...”)→ Clevia自动识别并尝试匹配,提示“Found 3 candidates — Select to verify”。
步骤3:深度验证与纠错
进入文献详情页 → 查看“Verification Panel”:
▪️ 绿色对勾:字段完全匹配(如DOI、作者序列、年份);
▪️ 黄色感叹号:存在微小差异(如期刊名缩写不同,系统标注“Nature vs Nat.”);
▪️ 红色叉号:严重不一致(如年份差2年、作者缺位),需人工确认;点击“Resolve Conflict” → 查看差异侧边栏 → 选择“Adopt Source Record”或“Keep My Version”(后者需填写理由,存档备查)。
步骤4:AI增强写作实践
新建文档 → 在左侧库中勾选3–5篇核心文献;
输入指令:“Compare their experimental designs and summarize trade-offs in scalability vs. accuracy”;
AI生成段落 → 点击文中任意引用 → 实时跳转至该文献PDF对应页码;
选中段落 → 右键“Insert as Citation” → 自动生成符合当前文档格式的引用标记与文末条目。
步骤5:成果导出与协作
点击右上角“Export” → 选择目标格式(如Word)→ 勾选“Include Verification Status” → 下载;
若协作:点击“Share” → 输入合作者邮箱 → 设置权限(Viewer/Editor/Verifier)→ 发送邀请;
所有协作者的操作(验证、标注、修改)均实时同步,且留痕可溯。
适合人群
| 用户群体 | 核心需求场景 | Clevia关键价值点 |
|---|---|---|
| 博士研究生 | 文献综述耗时长、引用易出错、导师反复要求修改格式;需快速定位领域前沿与空白。 | AI综述生成+知识图谱+引用验证报告,将综述周期缩短40%以上(Cambridge用户Joana证实) |
| 青年教师/博后 | 指导学生、撰写基金申请书、多项目并行管理文献;需确保学术严谨性与团队知识资产沉淀。 | 团队库共享+版本控制+验证状态导出,建立可传承的课题组研究基础设施 |
| 临床医生研究员 | 快速消化大量医学文献、精准引用指南与RCT研究、向非专业受众解释复杂机制。 | 医学概念白话解释+指南文献优先检索+多模态图表定位,提升临床转化研究效率 |
| 人文社科研究者 | 处理非结构化文本(古籍、档案)、跨语言文献管理、理论脉络梳理。 | OCR多语种支持+概念图谱构建+“思想流派演变”可视化,破解人文学科知识连接难题 |
| 本科生/硕士生 | 学术规范入门难、引用格式混乱、难以把握领域全貌、毕业论文时间紧。 | 零门槛格式导出+AI写作引导+“相似文章”智能推荐(Oxford用户Lisa称“find similar articles not found in common platforms”) |
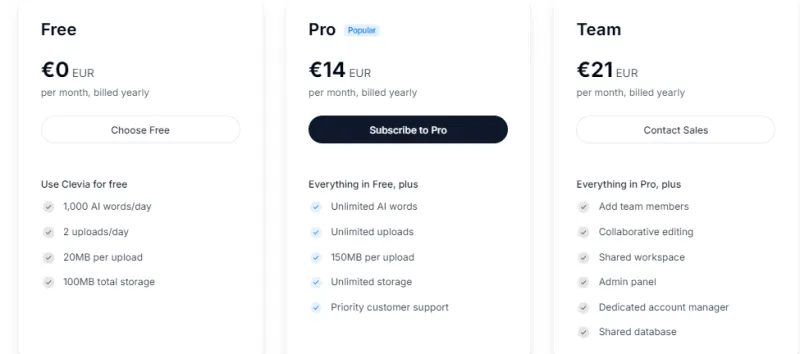
收费价格
常见问题解答(FAQ)
Q1:上传的PDF论文会被公开或用于训练AI模型吗?
A:绝对不会。Clevia严格遵守GDPR与FERPA合规要求。所有用户上传文件仅存储于加密隔离区,仅供本人本次会话处理;AI模型训练数据100%来源于公开许可数据集与合成学术文本,不含任何用户私有文献。
Q2:验证失败的引用,是否意味着文献本身有问题?
A:不一定。常见原因包括:期刊更名导致数据库记录更新延迟、作者姓名缩写习惯差异(如“J. Smith” vs “John Smith”)、预印本与正式发表版本元数据不一致。Clevia会清晰标注差异类型,并提供“查看原始数据库记录”按钮供人工复核。
Q3:能否导入Zotero/Mendeley的现有库?
A:支持。在“Import”中选择“BibTeX File”,上传.bib文件,Clevia将自动解析并启动批量验证,原有标签/分组可映射为新库中的智能文件夹。
Q4:AI生成的内容是否会被查重系统识别为抄袭?
A:不会。Clevia的AI写作功能不生成全新文本,而是基于你库中真实文献进行重组、摘要与解释,所有输出均附带精确引用来源。生成文本本质是“高度凝练的综述性表述”,符合学术规范。
Q5:离线状态下能否使用?
A:核心验证与AI功能需联网(依赖实时数据库比对与模型推理)。但已验证文献的本地缓存、笔记、写作草稿均支持离线编辑,联网后自动同步。
Q6:是否支持中文文献?特别是中文核心期刊与硕博论文?
A:全面支持。已接入CNKI(中国知网)元数据接口、万方数据、维普资讯,并对中文作者名、机构名、期刊名进行专项NER识别优化。用户证言(如“explain complex medical concepts clearly”)证实其中文理解能力达母语水平。
Q7:导出的Word文档,如何保证在导师电脑上格式不乱?
A:Clevia导出采用Word原生样式(Styles),而非手动空格/制表符。只要导师使用Word 2016+,打开即保持引用编号、悬挂缩进、字体统一。亦可导出为PDF确保100%保真。
Q8:如果我更换学校,文献库能带走吗?
A:可以。所有数据归属用户个人账户。导出为标准BibTeX或CSV即可迁移;Pro版用户还可一键下载“全库快照包”(含PDF+元数据+验证日志+AI笔记)。
总结
Clevia绝非又一款“锦上添花”的学术工具,而是直面当代科研最脆弱环节——引用系统的可信危机——所构建的系统性解决方案。其核心优势可凝练为三点:
可信为先:将“Verify references before they propagate downstream”从口号变为每一行代码的执行准则,为研究者筑起第一道学术伦理防火墙;
连接为要:打破PDF孤岛、笔记碎片、写作割裂的旧范式,让文献、概念、作者、方法在个人知识图谱中真正“活起来”;
智能为用:AI不是炫技,而是以可验证、可追溯、可解释的方式,将研究者从机械劳动中解放,回归高阶思辨与创新本质。
对于任何将准确性视为生命线、将知识连接视为生产力、将学术声誉视为终身资产的研究者而言,Clevia不是选择题,而是研究基础设施的必然升级。

