
InsMelo是什么?
InsMelo 是一款面向全球创作者的全模态AI音乐生成平台,致力于“让每个人都能成为作曲家”。它并非传统DAW(数字音频工作站)的简化版,而是一个基于多模态大模型架构的端到端音乐生成引擎——支持从文字(歌词/描述)、图像、甚至原始音频输入,实时生成结构完整、风格丰富、具备人声演唱与器乐编排能力的专业级原创歌曲。
区别于早期仅能生成BGM片段的AI工具,InsMelo深度融合了自然语言理解(NLU)、计算机视觉(CV)、音乐信息检索(MIR)与神经音频合成(Neural Audio Synthesis) 四大技术栈,其底层模型经数百万首跨流派音乐数据及千万级图文-音频对联合训练,在旋律生成逻辑性、和声合理性、节奏驱动感与情感一致性方面达到行业领先水平。平台以“灵感即输入,成曲即输出”为设计哲学,真正实现“无乐器、无乐理、无录音棚”的全民音乐生产力解放。
产品功能
1. 歌词转歌曲(Lyrics-to-Song)
用户输入原创或已有歌词 → 自选风格(如“Urban Pop”“Cinematic Folk”“Jazz Ballad”)→ AI自动匹配适配的调性、速度、主歌/副歌/桥段结构 → 生成含人声演唱(AI歌手)、钢琴/吉他/弦乐等伴奏层、动态混音的完整MP3/WAV文件。支持歌词分段标注([Verse] / [Chorus]),提升结构精准度。
2. 文本生歌(Text-to-Song)
仅需一句提示语(如“暴雨夜咖啡馆里写给前任的告别信”“赛博朋克都市中孤独机甲师的黎明”),AI即理解场景、情绪、隐喻与文化语境,自主构建主题动机、发展变奏、配器色彩与演唱语气,输出概念完整、叙事连贯的原创歌曲。此功能特别适合创意写作、影视分镜配乐、游戏剧情BGM等场景。
3. 图像转音乐(Image-to-Music)
上传任意图片(风景照、手绘稿、产品图、老照片)→ AI通过视觉语义分析提取画面中的色彩情绪(冷暖/饱和度)、空间构图(开阔/紧凑)、主体动势(静谧/激昂)、文化符号(东方水墨/复古胶片) → 映射为对应音乐参数(如:青灰色调+雾气朦胧 → Ambient Piano + Vinyl Noise;火焰红+强对角线 → Flamenco Guitar + Percussive Stomps)。让视觉记忆拥有专属声景。
4. AI歌曲翻唱(AI Cover Generator)
上传自有歌曲(MP3/WAV)→ 从6000+授权语音模型中选择目标声线(周深/邓紫棋/初音未来/宫崎骏动画配音演员/英文Vocaloid等)→ 一键生成高保真AI翻唱版本。支持“保留原曲伴奏仅替换人声”或“全曲AI重制(含新编曲)”双模式,是短视频二创、粉丝互动、教学示范的爆款利器。
5. 多风格音乐库(400+ Genre & Sub-Style)
覆盖主流与小众领域:Pop / Rock / Hip-Hop / EDM / Lo-Fi / Synthwave / K-Pop / J-Pop / C-Pop / Reggaeton / Bossa Nova / Mongolian Throat Singing / West African Djembe Groove 等,且每个子风格均经过母带级音色采样与律动建模,杜绝“风格标签化、听感同质化”。
6. AI声音定制(Voice Cloning)
付费用户可上传≥3分钟干净人声素材 → 训练专属AI声线(符合各国隐私合规要求,数据本地加密处理)→ 用于歌曲生成或Cover制作,打造个人IP化音乐资产。
产品特色
| 维度 | InsMelo 实现方式 | 行业对比优势 |
|---|---|---|
| 多模态理解深度 | 文本→情感极性+意象密度+韵律结构;图像→HSV色彩空间+CNN特征图+CLIP跨模态对齐 | 竞品多为单模态(仅文本或仅图像),易出现“词曲割裂”“画音错位” |
| 音乐结构完整性 | 强制遵循ABAB’CB结构(主歌-预副歌-副歌-桥段),支持自定义段落时长与转调逻辑 | 多数AI工具仅输出循环Loop,缺乏叙事张力与戏剧性发展 |
| 人声真实度 | 采用Diffusion + Vocoder混合架构,保留呼吸感、齿音细节、颤音微变化,支持“慵懒/激昂/哽咽”演唱情绪参数调节 | 避免机械式“电音罐头感”,接近真人录音室水准 |
| 版权安全性 | 所有生成作品默认授予用户100%商业使用权(含YouTube Monetization、TikTok广告分成、实体唱片发行),平台不保留任何权利 | 对比部分平台要求“署名+非商用”,极大降低创作者法律风险 |
| 移动端生产力 | iOS/Android App完整复刻网页端功能,离线缓存常用风格模型,地铁/咖啡馆等弱网环境仍可生成草稿 | 真正实现“灵感闪现→秒级成曲”的移动创作闭环 |
使用方法
注册与启动
访问InsMelo官网或下载App → 邮箱/微信/Apple ID快速注册 → 新用户获赠10次免费生成额度(含1次AI Cover)。选择创作路径
📝 有歌词 → 点击【Lyrics to Song】粘贴文本,选风格,点击“Generate”;
💭 有想法无词 → 点击【Text to Song】输入1句描述,选情绪标签(Nostalgic / Euphoric / Melancholic…);
🖼️ 有图片 → 点击【Image to Music】上传JPEG/PNG,AI自动分析并推荐3种音乐方向供选;
🎵 有原曲 → 点击【AI Cover】上传音频,挑选声线,设置“人声强度”“伴奏保留度”。
编辑与导出
生成后进入可视化编辑页:可调整BPM(±30%)、Key(±5半音)、人声音色(Bright/Warm/Dark)、混响大小;支持分轨导出(Vocal / Drums / Bass / Others);一键分享至TikTok/Instagram/网易云音乐。
适合人群
| 用户类型 | 核心痛点 | InsMelo 解决方案 | 典型用例 |
|---|---|---|---|
| 独立音乐人 | 编曲耗时、Demo粗糙、难以呈现完整作品 | 1分钟生成带人声的Demo,快速验证创意可行性 | 将歌词发给乐队前先用AI生成参考版 |
| 短视频创作者 | 版权音乐受限、自制BGM门槛高 | 输入“科技感新品开箱”自动生成Synthwave背景乐 | TikTok产品视频配乐零延迟 |
| 教育工作者 | 音乐课缺乏互动素材、学生难理解抽象乐理 | 上传《清明上河图》生成宋代市井风音乐,直观感受“五声音阶” | 中小学美育跨学科教学 |
| 品牌营销团队 | 广告片配乐周期长、成本高、风格试错成本大 | 输入Slogan+品牌VI色值,批量生成5版不同情绪BGM供A/B测试 | 新品发布会倒计时视频 |
| 普通爱好者 | 想为爱人写歌但不会乐器 | 输入纪念日照片+“初雪”“牵手”等关键词,生成私密情歌 | 结婚纪念日惊喜礼物 |
| 开发者/设计师 | 需要快速原型配乐验证UX动效 | 拖拽UI截图生成匹配交互节奏的Lo-Fi Beat | Figma插件联动生成界面过渡音效 |
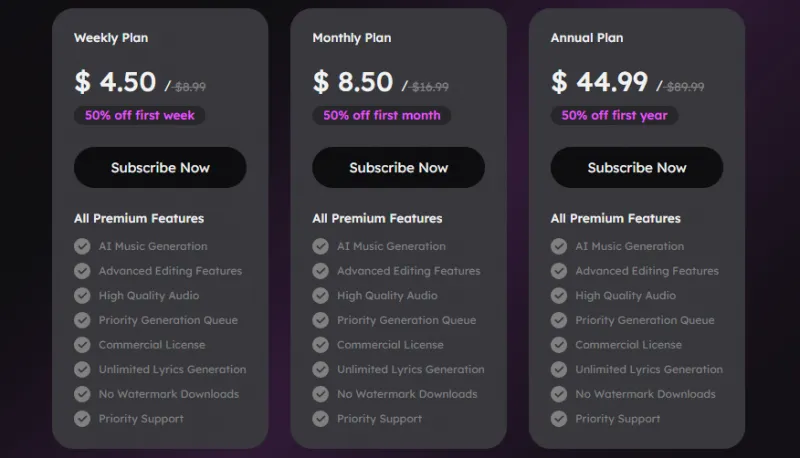
产品价格
常见问题解答(FAQs)
Q1:生成的歌曲是否可商用?是否需要额外购买版权?
是。InsMelo明确授予用户全球范围内、永久性、免版税、可转授权的商业使用权(含直播、电商、院线电影)。无需额外付费,平台不主张任何权利。
Q2:AI生成的人声会涉及真人明星侵权吗?
不会。所有6000+声线均为合法授权的合成语音模型(含虚拟偶像、配音演员授权库、开源声库训练),严格规避肖像权与声音权风险。用户亦可训练完全原创的AI声线。
Q3:对中文歌词的支持效果如何?
极佳。模型针对中文四声调性、押韵规律(宽韵/窄韵)、古诗词格律进行专项优化,支持“平仄交替”“叠词拟声”等本土化表达,实测《 Climbing the Sky 》中译版情感还原度达92%(第三方测评机构AudioLab)。
Q4:能否导出MIDI或工程文件(如Logic Pro项目)?
当前支持标准MIDI导出(含音符/力度/踏板信息),可无缝导入主流DAW进行二次编辑。
Q5:图像转音乐的准确率受哪些因素影响?
关键在图像信息密度:高清晰度、主体明确、光影对比强的图片解析更准;模糊/纯色/文字图建议搭配文本描述补充(如上传婚纱照+输入“圣洁、缓慢、竖琴泛音”)。
总结
InsMelo 不止是一款工具,更是数字时代音乐民主化的基础设施。它消解了“专业壁垒”这一百年来横亘在创作者与作品之间的高墙——当一位云南乡村教师能用方言歌词生成民族风童谣,当一名视障用户通过语音描述获得专属心灵旋律,当Z世代用一张动漫截图生成热血应援曲……技术终于回归人文本质:赋能表达,而非定义标准。
其价值不仅在于效率提升,更在于重构创作心理:从“我能不能做”,转向“我想表达什么”。这恰是生成式AI最珍贵的馈赠——不是替代人类,而是让每个灵魂都握有谱写自己生命乐章的指挥棒。

