OuteTTS-1.0-0.6B 全指南:开源轻量级多语言TTS模型本地部署实战
在语音交互日益普及的今天,高性能、低门槛、多语言支持的文本转语音(TTS)模型正成为开发者与AI应用落地的关键基础设施。OuteTTS-1.0-0.6B 作为2025年5月由OuteAI开源的轻量级TTS模型,以仅6亿参数实现媲美大模型的语音自然度与跨语言泛化能力,兼具WavTokenizer音频标记化、CTC时间对齐、窗口化重复惩罚等创新设计,真正兼顾边缘部署可行性与生产级语音质量。本文将从模型原理、环境配置、全流程本地部署到UI交互实战,手把手带你完成OuteTTS-1.0-0.6B在Ubuntu 22.04 + RTX 4090平台的零基础落地,助你快速构建中文/英文/阿拉伯语等20+语言的私有化语音合成服务。
一、模型介绍
OuteTTS-1.0-0.6B 是 OuteAI 于 2025 年 5 月发布的开源语音合成模型,基于 Qwen-2.5-0.5B 架构优化,参数规模 6 亿,专注于轻量级高性能语音合成。
该模型通过创新技术路径实现了多语言支持、声音克隆和低资源消耗的平衡,在边缘计算、移动应用等场景展现出独特优势。
技术特性:轻量化与多模态融合
模型采用 LLaMa 架构基础,结合 WavTokenizer 音频标记化技术,将连续音频波形转换为离散令牌序列,每秒处理 150 个令牌。通过 CTC 强制对齐技术,实现文本与音频的精确映射,无需预处理即可生成时间戳对齐的语音流。窗口化重复惩罚机制的引入,显著提升了语音输出的连贯性和自然度,尤其在长文本合成中表现稳定。
多语言支持是其核心亮点之一。模型直接支持英语、中文、阿拉伯语等 20 余种语言的文本输入,无需罗马化处理。训练数据覆盖高资源语言(如英语、中文)和中等资源语言(如葡萄牙语、波斯语),未训练语言也可生成语音但效果有限。
二、模型部署步骤
模型部署环境
| ubuntu | 22.04.4 LTS |
|---|---|
| cuda | 12.4.1 |
| python | 3.10 |
| NVIDIA Corporation | RTX4090 |
1.更新基础的软件包
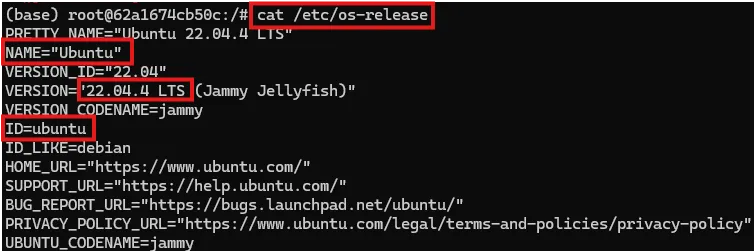
查看系统版本信息
#查看系统的版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等 cat /etc/os-release
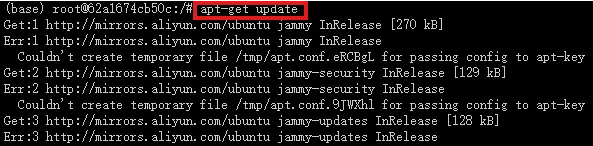
配置国内源
#更新软件列表 apt-get update
apt配置阿里源
vim /etc/apt/sources.list
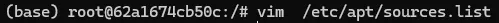
将以下内容粘贴进文件中
deb http://mirrors.aliyun.com/debian/ bullseye main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye main non-free contrib deb http://mirrors.aliyun.com/debian-security/ bullseye-security main deb-src http://mirrors.aliyun.com/debian-security/ bullseye-security main deb http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib deb http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
2.基础Miniconda3环境
查看系统是否有miniconda的环境
conda -V

显示如上输出,即安装了相应环境,若没有miniconda的环境请安装
3.创建虚拟环境
创建名为“Outetts”的虚拟环境
conda create -n OuteTTs python=3.10 -y

激活虚拟环境
conda activate OuteTTs

4.下载模型
输入命令克隆OuteTTS项目
git clone https://github.com/edwko/OuteTTS.git cd OuteTTS
5.安装pytorch环境
安装pytorch,选择合适的版本安装,建议python版本至少为3.9及以上
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

持续等待直至出现“successfully”开头的提示,则安装成功

6.下载依赖库
pip install -e .
依赖库下载时间较长,直至出现“successfully”显示下载成功
7.存储模型运行命令
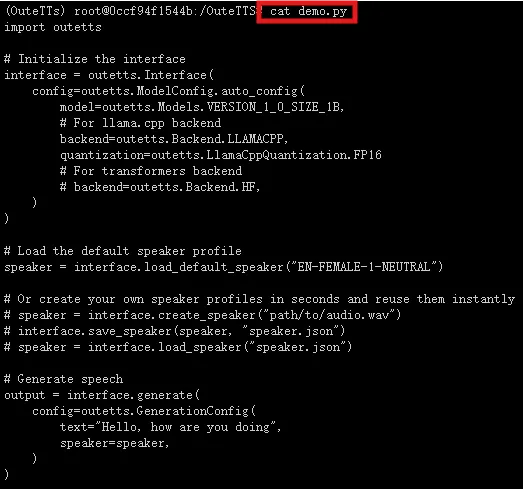
创建demo.py文件
vim demo.py

cat demo.py
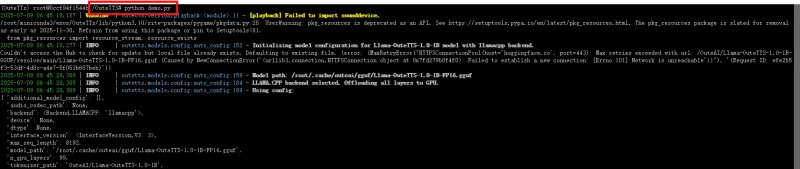
运行模型测试命令
python demo.py
三、UI界面
下载其他缺失依赖包
pip install gradio

访问界面
python app.py

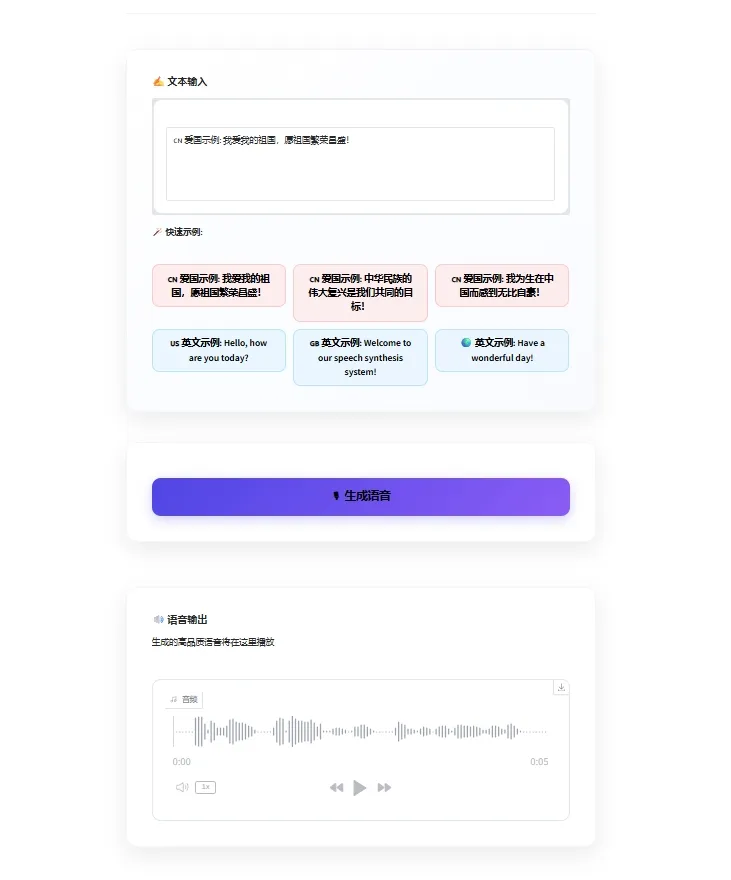
出现如上显示可通过项目实例的开放端口进行访问,输入需要生成语音的文本包括中文及英文即可合成
总结:
OuteTTS-1.0-0.6B 不仅是一次轻量化TTS的技术突破,更代表了“小而强、开箱即用、多语原生”的新一代语音合成范式。通过本文详实的部署指南,读者已可独立完成从系统源配置、Conda虚拟环境搭建、PyTorch CUDA适配、模型克隆编译,到命令行推理与Gradio Web界面启动的全链路实践。该模型在无预处理、支持时间戳对齐、无需罗马化输入等特性上显著降低工程门槛,特别适合IoT设备、移动App集成、无障碍工具及多语言内容生成等真实场景。持续关注其社区演进(如新增语言微调脚本、ONNX导出支持、量化推理优化),将进一步释放其在资源受限环境中的潜力。
版权及免责申明:本文来源于#算家计算,由@AI工具集整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/869.html