TIPSv2:谷歌 DeepMind 开源的多模态编码器,强化 Patch-Text 对齐与空间感知
一、TIPSv2是什么
TIPSv2(Text-Image Pretraining with Spatial Awareness v2) 是Google DeepMind推出的第二代空间感知型文本-图像预训练编码器,收录于CVPR 2026,核心解决多模态模型“全局理解强、局部定位弱”的行业痛点,实现图像块(Patch)与文本特征的精准对齐。
作为TIPSv1(ICLR 2025)的升级版,TIPSv2通过三大核心技术创新,在9大类任务、20个权威数据集上实现SOTA性能,尤其在零样本分割、深度估计、空间特征定位等细粒度任务上表现突出。模型开源Apache 2.0协议,支持PyTorch/Jax双框架部署,适配从86M(Base)到1.1B(Giant)的多规格模型,兼顾科研与产业落地需求。
二、功能特色
1. 核心功能
零样本密集对齐:无需微调,直接实现图像Patch与文本的细粒度匹配,支持零样本分割、目标定位、前景提取。
多模态特征编码:统一图像-文本特征空间,适配图像检索、图文匹配、视觉问答(VQA)等任务。
空间感知增强:精准捕捉图像局部细节与空间布局,支持深度估计、法向量预测、语义分割等密集预测任务。
多规格模型适配:提供B/14、L/14、SO/14、g/14等多版本,覆盖轻量推理到高精度科研场景。
2. 核心优势
强局部理解:首创Patch级全区域监督,解决传统模型“全局懂、局部懵”的缺陷,零样本分割性能提升14.1个百分点。
训练高效低成本:Head-only EMA策略减少42%训练参数,多粒度文本增强提升数据利用率,降低大模型训练门槛。
开箱即用:预训练权重直接可用,支持HuggingFace在线体验、Colab交互式推理,无需复杂配置。
跨框架兼容:同时支持PyTorch(工业部署)与Jax(科研训练),权重双向转换,适配不同技术栈。

三、技术细节
1. 核心架构
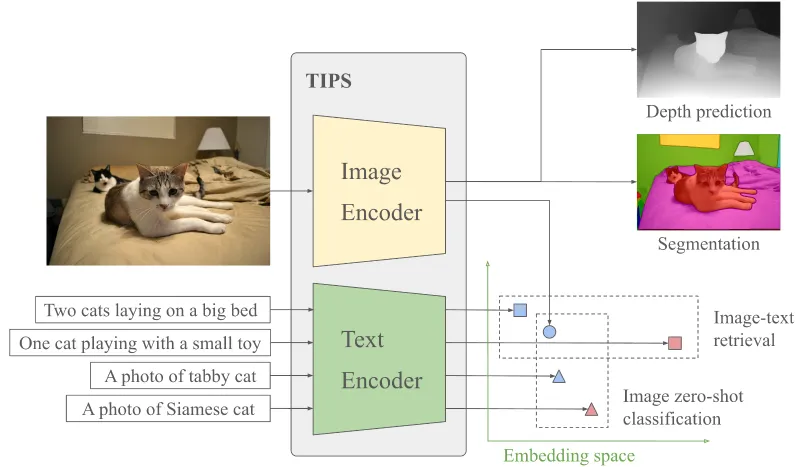
TIPSv2基于ViT(Vision Transformer) 骨干网络,采用“图像编码器+文本编码器+投影头”的双塔结构,视觉编码器与文本编码器通过对比学习实现特征对齐。
图像编码器:ViT-B/L/SO/g系列,输入图像分块为14×14 Patch,输出Patch级特征序列。
文本编码器:Transformer文本模型,输出文本嵌入向量,与图像Patch特征计算相似度。
投影头:将图像/文本特征映射至统一维度,采用Head-only EMA更新,仅优化顶层投影层,降低训练成本。
2. 三大技术创新
(1)iBOT++:全区域精细监督
传统掩码预训练(如iBOT)仅计算掩码区域损失,忽略可见区域细节,导致局部语义漂移。TIPSv2的iBOT++ 强制模型对所有可见Patch进行特征一致性监督,从“掩码拼图”升级为“全图精读”,显著增强密集对齐能力。
(2)Head-only EMA:高效训练策略
标准自监督学习需对全模型执行EMA,显存占用极高。TIPSv2发现文本监督可稳定视觉骨干,仅对投影头(Projection Head) 执行EMA,冻结骨干网络EMA更新,训练参数减少42%,性能几乎无损。
(3)多粒度文本增强(Multi-Granularity Captions)
混合三种文本数据训练:
短描述:网页Alt-text,覆盖基础语义;
中描述:PaliGemma生成的局部密集字幕,强化细节对齐;
长描述:Gemini生成的全局深度描述,增强上下文理解。
难易样本交替训练,防止模型“偷懒”,提升特征鲁棒性。
3. 模型规格与性能
TIPSv2提供4种主流规格,核心参数与性能如下:
| 模型 | 视觉参数 | 文本参数 | 零样本分割(PASCAL) | ImageNet-KNN |
|---|---|---|---|---|
| B/14 | 86M | 110M | 82.3 | 81.5 |
| L/14 | 304M | 330M | 84.5 | 83.1 |
| SO/14 | 400M | 430M | 84.8 | 83.3 |
| g/14 | 1.1B | 1.2B | 85.1 | 83.7 |
| 数据来源:TIPSv2官方论文,2026 |
四、应用场景
1. 计算机视觉
零样本语义分割:医疗影像病灶分割、工业质检缺陷定位、遥感图像地物识别。
深度/法向量估计:自动驾驶环境感知、3D重建、机器人空间导航。
图像检索与匹配:电商商品检索、版权图像溯源、跨模态内容搜索。
2. 多模态交互
视觉问答(VQA):细粒度图像问答、场景理解、智能客服图像咨询。
图文生成辅助:为文生图模型提供精准视觉特征,提升生成图像与文本的一致性。
3. 科研与教育
多模态研究基准:作为通用编码器,支撑分割、检测、检索等任务的算法研发。
教学演示:HuggingFace/Colab交互式Demo,直观展示Patch-Text对齐与空间感知能力。
五、使用方法
1. 环境安装(PyTorch)
# 创建虚拟环境 conda create -n tipsv2 python=3.11 conda activate tipsv2 # 安装依赖 pip install torch torchvision torchaudio pip install git+https://github.com/google-deepmind/tips.git pip install huggingface_hub transformers
2. 快速推理示例
from tips.pytorch import TIPS
from PIL import Image
import torch
# 加载预训练模型(B/14版本)
model = TIPS.from_pretrained("google/tipsv2-b14")
model.eval()
# 加载图像与文本
image = Image.open("test.jpg").convert("RGB")
texts = ["一只猫", "一只狗", "一本书"]
# 特征提取与相似度计算
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(texts)
similarity = (image_features @ text_features.T).softmax(dim=-1)
print("相似度:", similarity)3. 在线体验与Colab Demo
HuggingFace Space:https://huggingface.co/spaces/google/TIPSv2,支持零样本分割、特征可视化。
Colab笔记本:仓库
notebooks/目录提供PyTorch/Jax版本推理、零样本分割训练示例,直接运行无需本地配置。
六、竞品对比
选取当前主流多模态编码器SigLIP2、DINOv3与TIPSv2对比,核心维度如下:
| 对比维度 | TIPSv2(g/14) | SigLIP2(g/14) | DINOv3(L/14) |
|---|---|---|---|
| 核心优势 | 强Patch-Text对齐、空间感知 | 全局图文对齐、多语言支持 | 纯视觉表征、自监督学习 |
| 零样本分割(PASCAL) | 85.1 | 79.3 | 82.7 |
| 训练效率 | Head-only EMA,显存占用低 | 全模型EMA,显存消耗大 | 全模型EMA,训练成本高 |
| 适用场景 | 细粒度分割、深度估计、空间定位 | 图文检索、全局VQA、多语言任务 | 纯视觉分类、检测、特征提取 |
| 开源协议 | Apache 2.0(商用免费) | Apache 2.0 | MIT |
| 数据来源:官方论文与基准测试,2026 |
核心结论:TIPSv2在细粒度空间任务上全面领先SigLIP2与DINOv3,训练效率显著优于竞品;SigLIP2更适合全局图文任务,DINOv3在纯视觉场景有优势。

七、常见问题解答
Q:TIPSv2与TIPSv1的核心区别是什么?
A:TIPSv2在TIPSv1基础上引入三大技术创新:iBOT++全区域监督、Head-only EMA高效训练、多粒度文本增强,零样本分割性能提升约5个百分点,训练成本降低40%以上,同时优化模型泛化能力,适配更多下游任务。
Q:TIPSv2可以商用吗?
A:可以。TIPSv2采用Apache 2.0开源协议,允许免费商用、修改与二次分发,无需支付版权费用,仅需保留原始版权声明。
Q:如何选择适合的模型规格?
A:轻量推理(移动端/边缘设备)选B/14;平衡精度与速度选L/14;高精度科研/工业场景选SO/14或g/14;显存不足时优先选择PyTorch版本,支持模型并行与梯度累积。
Q:TIPSv2支持中文吗?
A:支持。文本编码器基于多语言预训练模型优化,可直接处理中文文本,适配中文图文检索、中文视觉问答等任务,无需额外微调。
八、相关链接
HuggingFace模型库:https://huggingface.co/collections/google/tipsv2
HuggingFace在线体验:https://huggingface.co/spaces/google/TIPSv2
九、总结
TIPSv2是Google DeepMind推出的第二代空间感知型文本-图像预训练编码器,通过iBOT++、Head-only EMA与多粒度文本增强三大核心技术,精准解决多模态模型局部定位弱、训练成本高的痛点,在零样本分割、深度估计等细粒度任务上实现SOTA性能。模型开源Apache 2.0协议,支持PyTorch/Jax双框架与多规格模型部署,兼顾科研创新与产业落地需求,为计算机视觉、多模态交互等领域提供高效、易用的基础模型支撑。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/tipsv2.html





