Qwen3.7-Plus:通义千问推出的多模态智能体大模型,全链路自动化编程与GUI视觉操控
Qwen3.7-Plus是由阿里达摩院通义千问团队自研、依托Qwen3.7原生基座迭代升级的多模态通用智能体大模型,主打视觉+文本+代码三位一体的自主智能体闭环能力,Qwen3.7-Plus从底...

Qwen3.7-Plus是由阿里达摩院通义千问团队自研、依托Qwen3.7原生基座迭代升级的多模态通用智能体大模型,主打视觉+文本+代码三位一体的自主智能体闭环能力,Qwen3.7-Plus从底...
Step‑3.7‑Flash是阶跃星辰开源的生产级Agent专用多模态大模型,采用稀疏MoE架构,总参数198B、激活参数11B,最高生成速度400 Tokens/s,支持256K上下文与三级推理级别。模...

Mamoda2.5 是字节跳动 Mamoda 团队自研推出的开源统一多模态大模型,依托 DiT-MoE 稀疏混合专家架构 打造,采用 AR-Diffusion 统一建模范式,实现多模态理解、内容生成、智...

Muse Spark是Meta超级智能实验室打造的首款原生多模态推理AI模型,主打文本、图像深度融合理解,提供即时、思考、沉思三级推理模式,支持16并行智能体协同与视觉思维链,在...

Kimi K2.5是由北京月之暗面科技(Moonshot AI)发布的开源多模态大模型,同步上线于Hugging Face官方仓库,是Kimi系列模型的重磅升级版本。其核心定位是“面向全场景的高性...

STEP3-VL-10B是阶跃星辰(StepFun AI)开源的轻量级多模态基础大模型,核心定位是在10B(100亿)参数的紧凑规模下,实现高效性与前沿多模态智能的极致平衡,打破“参数越大...
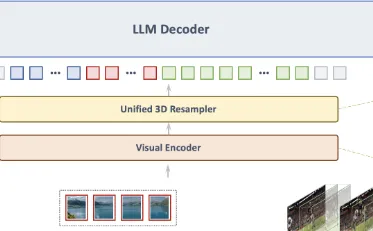
深度解析 MiniCPM-V 4.5 多模态大模型,手把手教你完成本地部署。支持高精度 OCR 与长视频理解,基于 Ubuntu 环境,适配 GGUF 量化,轻松在消费级硬件运行视觉语言模型。
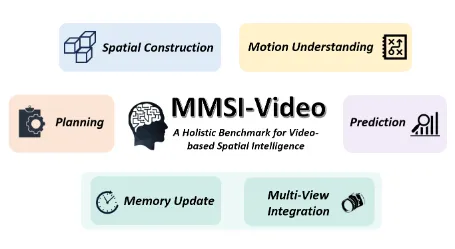
MMSI-Video-Bench是一款开源的视频空间智能专项评测基准。该基准聚焦多模态大模型(MLLMs)在视频场景下的空间智能能力评估,构建了覆盖“感知-规划-预测-跨视频推理”的四...

VideoLLaMA3是由阿里巴巴达摩院新加坡NLP团队研发并开源的多模态基础模型,聚焦于图像与视频的内容理解与分析任务。作为VideoLLaMA系列模型的升级版本,该模型基于字节跳动...

UniPixel是由香港理工大学、腾讯ARC实验室等机构联合开发的开源多模态大模型(MLLM),专注于像素级视觉语言理解与细粒度推理任务。该模型基于Qwen2.5-VL系列扩展,融合视觉...