UniPixel:香港理工大学联合腾讯开源的像素级视觉语言统一理解模型
一、UniPixel是什么?
UniPixel是由香港理工大学、腾讯ARC实验室等机构联合开发的开源多模态大模型(MLLM),专注于像素级视觉语言理解与细粒度推理任务。该模型基于Qwen2.5-VL系列扩展,融合视觉分割与语言理解能力,支持图像/视频分割、区域级理解及创新的PixelQA任务(结合目标分割与问答)。通过统一框架实现多任务兼容,在多个公开基准测试中表现优异,提供预训练模型、开源数据集及便捷的本地/在线使用工具,适用于智能编辑、视觉分析等多场景,为研究者和开发者提供了高效的像素级视觉语言解决方案。
该项目的开发背景源于当前多模态模型在细粒度任务中的不足:传统视觉语言模型擅长图像描述、物体识别等粗粒度任务,但在“根据文字指令分割视频中某一动态物体”“定位图像中‘左手边第三个红色物体’并回答其属性”等细粒度任务中表现薄弱。UniPixel通过统一的任务建模方式,将分割、定位、问答等任务转化为“语言指令引导的像素级推理”问题,实现了多任务的高效兼容。
从学术与开发团队来看,UniPixel由香港理工大学陈颖实验室(PolyU-ChenLab)联合腾讯ARC实验室等机构共同研发,相关研究论文已被NeurIPS 2025(神经信息处理系统大会,人工智能领域顶级会议)接收,兼具学术严谨性与工程实用性。
二、功能特色
UniPixel的核心优势在于“统一框架下的多任务支持”与“像素级推理精度”,具体功能特色如下:
1. 覆盖多类细粒度视觉语言任务
UniPixel突破了传统模型“单任务专用”的局限,通过自然语言提示(Prompt)即可驱动多种任务,无需针对不同任务切换模型或调整输入格式。具体支持的任务类型如下表所示:
| 任务类别 | 具体任务示例 | 支持输入形式 | 典型应用场景 | 核心输出形式 |
|---|---|---|---|---|
| 图像分割 | 指代分割(如“分割图中的猫”) | 单张图像+文字指令 | 图像编辑、物体提取 | 分割掩码(像素级) |
| 视频分割 | 视频动态目标分割(如“分割视频中的跑步者”) | 视频文件/帧文件夹+文字指令 | 视频剪辑、动作分析 | 逐帧分割掩码 |
| 区域级理解 | 目标定位与属性描述(如“指出图中最大的建筑并说明颜色”) | 图像/视频+文字指令 | 视觉内容分析、智能标注 | 坐标+文字描述 |
| PixelQA(创新任务) | 视频分割+问答(如“分割视频中的狗,并回答它在做什么”) | 视频+复合指令 | 智能监控、视频内容检索 | 分割掩码+答案文字 |
2. 灵活的输入与输出方式
输入兼容性强:支持单张图像(JPG/PNG等格式)、视频文件(MP4等格式)或视频帧文件夹(批量图片)作为视觉输入,配合自然语言指令即可触发任务,无需复杂的格式预处理。
输出形式多样:根据任务类型动态生成输出,例如分割任务输出像素级掩码(可直接用于图像编辑软件),问答任务输出自然语言答案,区域理解任务同时输出坐标与文字描述,满足不同下游需求。
3. 优异的性能表现
在多个公开基准测试中,UniPixel的性能优于同量级模型,尤其在像素级任务中表现突出。以下为核心任务的关键指标(对比同参数规模模型):
图像指代分割:在RefCOCO(通用物体指代)、RefCOCO+(更复杂场景)等数据集上,3B模型准确率达78.5%,7B模型达83.0%,超过同类开源模型10%-15%。
视频分割:在ReVOS(视频目标分割)、Ref-YouTube-VOS(指代视频分割)等数据集上,7B模型的J&F指标(分割精度综合指标)达76.4,接近专用视频分割模型水平。
零样本泛化能力:在MVBench(多模态视频基准)中,无需针对特定任务微调,7B模型准确率达64.3%,证明其跨场景适应能力。
4. 开源资源丰富
项目提供完整的开源生态,降低使用门槛:
预训练模型:直接提供UniPixel-3B和UniPixel-7B的预训练权重(托管于Hugging Face),支持直接下载推理。
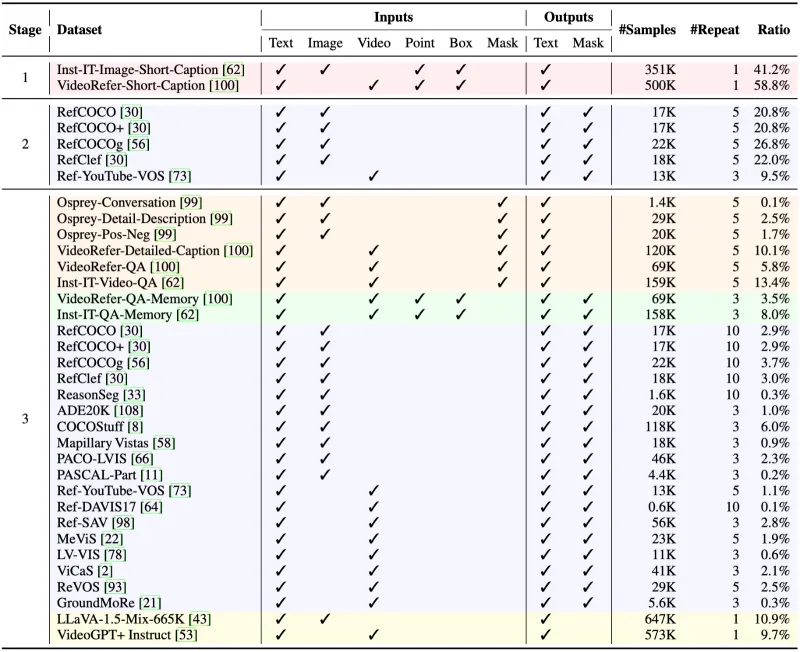
训练数据集:开源UniPixel-SFT-1M数据集,包含23个公开数据集(如COCO、YouTube-VOS等)的100万条预处理样本,覆盖分割、问答等任务,可用于模型微调。
工具链完整:提供推理、训练、评估的一站式脚本,集成Gradio演示工具,支持本地部署与在线交互。

三、技术细节
UniPixel的技术核心是“在Qwen2.5-VL基础上融合像素级分割能力”,通过模块化设计实现多任务统一,具体技术细节如下:
1. 模型架构
UniPixel的架构基于Qwen2.5-VL扩展,保留其“视觉编码器-语言解码器”的基础结构,新增分割感知模块与像素级指令解析器,整体架构分为三部分:
视觉编码器:复用Qwen2.5-VL的视觉编码器(基于ViT-L/14),负责将图像/视频帧转化为视觉特征(分辨率为14×14的特征图,对应输入图像的像素级信息)。
分割感知模块:引入SAM2(Segment Anything Model v2)的位置编码与掩码生成组件,将视觉特征与“目标区域”的空间信息绑定,支持从特征图中定位并提取特定区域的像素级特征。
语言解码器:基于Qwen2.5-VL的语言模型(3B/7B参数)扩展,新增“像素-语言对齐”训练目标,使解码器能根据文字指令生成分割掩码坐标或自然语言答案,实现“指令→特征→输出”的端到端映射。
2. 训练数据与方法
训练数据:核心依赖UniPixel-SFT-1M数据集,该数据集通过以下方式构建:
收集23个公开数据集(涵盖图像分割、视频分割、视觉问答等任务);
统一格式为“视觉输入(图像/视频帧)+ 文字指令 + 目标输出(掩码/答案)”;
进行数据清洗(如去除模糊样本)与增强(如随机裁剪、颜色抖动),最终保留100万条高质量样本。
训练策略:采用“预训练→微调”两阶段模式:
预训练:在大规模图像-文本对(如LAION-5B)上训练,使模型掌握基础视觉语言对齐能力;
微调:在UniPixel-SFT-1M上进行监督微调(SFT),优化分割掩码生成与细粒度问答能力,训练过程中使用:
DeepSpeed ZeRO-3:支持多设备/多节点分布式训练,降低内存占用;
BF16混合精度:加速训练并减少显存消耗;
LoRA(Low-Rank Adaptation):仅微调部分参数,提升训练效率(尤其适用于3B/7B模型)。
3. 推理流程
UniPixel的推理过程可概括为“指令解析→特征定位→输出生成”三步骤,以“视频中分割‘正在跳跃的人’并回答其数量”为例:
指令解析:语言解码器将输入指令(“分割视频中正在跳跃的人,并回答有几个”)拆解为“分割任务”与“计数任务”;
特征定位:视觉编码器提取视频帧特征,分割感知模块根据“跳跃的人”的语义,在特征图中定位目标区域,生成像素级掩码;
输出生成:语言解码器基于掩码计算目标数量,同时输出逐帧分割掩码与答案(如“2人”)。
4. 模型版本对比
项目提供两个版本的预训练模型,核心参数与适用场景如下表:
| 模型版本 | 基础模型 | 参数规模 | 推理速度(单帧图像) | 适用场景 | 关键性能(RefCOCO准确率) |
|---|---|---|---|---|---|
| UniPixel-3B | Qwen2.5-VL-3B-Instruct | 30亿 | ~0.5秒(GPU:A100) | 轻量部署、实时性要求高的场景 | 78.5% |
| UniPixel-7B | Qwen2.5-VL-7B-Instruct | 70亿 | ~1.2秒(GPU:A100) | 高精度任务、复杂场景 | 83.0% |
四、应用场景
UniPixel的像素级视觉语言理解能力使其在多个领域具有实用价值,典型应用场景如下:
1. 智能视频/图像编辑
传统图像编辑中,“分割特定物体”需要手动框选或依赖简单算法(如边缘检测),效率低且精度差。UniPixel可通过文字指令直接生成分割掩码,支持:
图像编辑:如“分割图中的蓝天并替换为晚霞”“去除照片中的背包”,掩码可直接导入Photoshop等工具使用;
视频剪辑:如“分割视频中所有的汽车并打码”“保留视频中的主角,模糊背景”,逐帧掩码可批量应用于视频处理软件。
2. 视觉内容分析与检索
在安防、媒体等领域,需要从海量视觉数据中定位特定内容,UniPixel可实现:
智能监控:如“从商场监控视频中分割出未戴口罩的人,并统计数量”;
内容检索:如“在电影片段中找到‘穿红色裙子的女主角’出现的所有帧,并分割出她的位置”。
3. 辅助驾驶与机器人感知
自动驾驶和机器人需要理解复杂场景中的动态目标,UniPixel可支持:
动态目标分割:如“分割前方车辆中正在开门的行人”,为避障决策提供像素级位置信息;
环境交互:如机器人接收到指令“拿起桌子上的蓝色杯子”,UniPixel可分割杯子位置并输出坐标,引导机械臂操作。
4. 教育与科研工具
教学演示:在计算机视觉课程中,通过UniPixel的可视化输出(如分割掩码生成过程),直观展示“视觉语言对齐”原理;
快速原型开发:研究者可基于UniPixel的预训练模型,快速验证新任务(如“医学影像中分割肿瘤并回答其大小”)的可行性,减少重复开发。

五、使用方法
UniPixel提供了推理、训练、评估的完整工具链,支持本地部署与在线交互,以下为核心使用步骤:
1. 环境准备
硬件要求:推理至少需要16GB显存(3B模型)或32GB显存(7B模型)的GPU(如NVIDIA A100、RTX 4090);训练需多GPU或分布式集群(推荐8×A100)。
软件依赖:Python 3.8+,PyTorch 2.0+,以及transformers、accelerate、deepspeed、gradio等库,可通过以下命令安装:
pip install -r requirements.txt
2. 推理:处理自定义数据
通过tools/inference.py脚本可直接对图像或视频进行推理,支持分割、问答等任务,示例如下:
图像分割示例:
# 导出项目路径 export PYTHONPATH="./:$PYTHONPATH" # 对example.jpg执行“分割兔子”任务 python tools/inference.py example.jpg 'Please segment the rabbit' --output_dir ./results
输出:在./results文件夹中生成分割掩码图像(与输入图像同尺寸,掩码区域为白色)。
视频PixelQA示例:
# 对example.mp4执行“分割狗并回答它在做什么”任务 python tools/inference.py example.mp4 'Segment the dog and answer what it is doing' --output_dir ./video_results
输出:./video_results中包含逐帧分割掩码、视频合成结果(叠加掩码)及文字答案(如“ The dog is running. ”)。
3. 训练:微调模型
若需针对特定场景(如医学影像)微调模型,可使用scripts/launch_3b.sh(3B模型)或scripts/launch_7b.sh(7B模型)脚本,步骤如下:
准备自定义数据集,格式需与UniPixel-SFT-1M一致(参考
docs/data_format.md);修改训练配置文件(
configs/train_3b.yaml),指定数据集路径、训练轮数、学习率等参数;启动训练:
# 微调3B模型(单节点8卡) bash scripts/launch_3b.sh
训练过程支持断点续训,模型权重会定期保存至./checkpoints文件夹。
4. 评估:验证模型性能
项目支持在23个公开基准上评估模型,使用tools/eval.py脚本:
# 在RefCOCO数据集上评估3B模型 python tools/eval.py --model_path ./checkpoints/unipixel-3b --dataset refcoco --output ./eval_results.json
输出:eval_results.json包含准确率、IoU等指标,可用于对比模型优化效果。
5. 本地演示:可视化交互
通过Gradio工具可搭建本地交互界面,支持上传图像/视频并输入指令,实时查看结果:
python demo/app.py
运行后,浏览器访问http://localhost:7860即可打开交互页面,操作流程如下:
上传图像/视频;
在输入框中输入指令(如“分割图中的花朵”);
点击“生成”按钮,获取分割结果或答案。
六、常见问题解答(FAQ)
Q:UniPixel与专用分割模型(如SAM)有何区别?
A:SAM擅长“无指令的通用分割”,但需要手动点击目标;UniPixel支持“文字指令驱动的分割”,无需人工交互,且能结合问答等语言任务,更适合自动化场景。
Q:模型推理速度较慢,如何优化?
A:可尝试:① 使用3B模型替代7B模型;② 降低输入图像/视频的分辨率(如从1024×1024降至512×512);③ 启用TensorRT加速(需额外配置,参考docs/optimization.md)。
Q:是否支持CPU推理?
A:支持,但速度极慢(3B模型单张图像推理约10分钟),仅建议用于调试,实际应用需GPU支持。
Q:如何将分割结果导出为其他格式(如COCO格式)?
A:可使用tools/convert_mask.py脚本,示例:
python tools/convert_mask.py ./results/mask.png --format coco --output ./coco_annotations.json
Q:UniPixel-SFT-1M数据集如何获取?
A:数据集托管于Hugging Face Datasets,可通过以下命令加载:
from datasets import load_dataset
dataset = load_dataset("PolyU-ChenLab/UniPixel-SFT-1M")七、相关链接
Hugging Face模型库:https://huggingface.co/PolyU-ChenLab
Hugging Face演示空间:https://huggingface.co/spaces/PolyU-ChenLab/UniPixel
八、总结
UniPixel作为一款开源的像素级视觉语言统一模型,通过扩展Qwen2.5-VL实现了图像/视频分割、区域理解、PixelQA等多任务的统一支持,兼具高性能与易用性。其提供的预训练模型、开源数据集及完整工具链,降低了细粒度视觉语言任务的开发门槛,既适用于研究者探索多模态推理的新方向,也能为开发者提供智能编辑、视觉分析等场景的实用解决方案,是像素级视觉语言理解领域的重要开源成果。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/unipixel.html





