
CodeGraph:开源本地代码图谱工具,联动AI编程助手高效解析源码
CodeGraph是MIT协议开源的本地代码语义图谱工具,适配Cursor、Claude Code等AI编程软件,支持多语言多框架源码解析,离线存储保障代码隐私,具备符号检索、变更影响分析、实...

CodeGraph是MIT协议开源的本地代码语义图谱工具,适配Cursor、Claude Code等AI编程软件,支持多语言多框架源码解析,离线存储保障代码隐私,具备符号检索、变更影响分析、实...

Stable Audio 3是Stability AI研发的开源AI音频生成项目,支持文本生成音乐音效、音频片段修复续写,搭载多款梯度模型,兼容多类硬件设备,具备LoRA风格微调能力,提供网页...

Lance是由字节跳动正式开源发布的轻量化统一原生多模态大模型,整体参数量仅3B,依托自研Transformer主干架构完成全链路从零训练,摒弃传统多模态模型拆分式设计思路,真正...

2026年精选10款完全免费或高免费额度的AI生成内容检测工具,涵盖GPTZero、腾讯朱雀、Copyleaks等国内外主流平台,详细对比各工具核心功能、免费额度、准确率、适用场景,适...

Skillshare是一款开源轻量化AI技能统一管理同步工具,支持全平台一键同步各类AI提示词、智能体规则与自定义配置,内置安全风险审计功能,跨Windows、macOS、Linux系统部署,...
Composer 2.5是Cursor编辑器全新升级的全域AI项目编排引擎,具备全局项目解析、超长上下文代码生成、多语言多框架适配、智能代码纠错与增量重构等多项实用功能,支持自然语...

HiCAD是一款开源免费的AI驱动在线3D CAD建模平台,基于Vue3+NestJS架构开发,支持自然语言生成参数化三维建模代码,具备实时3D预览、参数调节、STL/OBJ模型导出等功能,无需...

OpenSRE 是由 Tracer-Cloud 团队开源打造的AI 驱动 SRE 智能代理框架,基于大语言模型与云原生可观测体系深度融合而生,专为运维、SRE、研发工程师设计,聚焦生产故障自动排...

OpenMontage 是一款开源 AI 智能体驱动的全流程视频制作系统,由 calesthio 团队开源维护,基于大模型智能体架构打造,彻底重构传统短视频、纪录片、科普动画的制作流程。
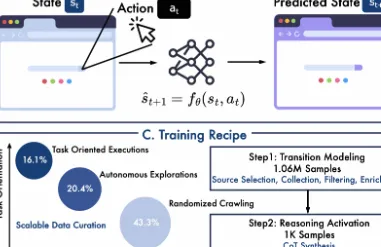
WebWorld 是由阿里通义千问QwenLM团队重磅开源的大规模网页世界模型,依托通义千问3大模型底座构建,是专门为网页智能体(Web Agent) 量身打造的浏览器仿真模拟环境框架。