DeepSeek-OCR 2:DeepSeek-AI推出的开源类人逻辑OCR识别工具,适配图片与PDF全场景
一、DeepSeek-OCR 2是什么
DeepSeek-OCR 2是由深度求索(deepseek-ai)开源的新一代OCR模型,同步发布同名技术报告《DeepSeek-OCR 2: Visual Causal Flow》,是对前代DeepSeek-OCR模型的重大升级[5]。它本质上是一款基于类人视觉编码逻辑设计的开源光学字符识别工具,核心目标是解决传统OCR模型在复杂文档排版(如多栏布局、合并单元格表格、嵌入公式)中识别顺序混乱、准确率低的痛点,让AI能够像人类一样“读懂”文档,而非单纯“看见”文字[3]。
与传统OCR模型相比,DeepSeek-OCR 2的核心差异在于其“视觉因果流”设计——模型会先对整个文档页面进行全局感知,识别出标题、条款、表格、公式等不同元素的位置与逻辑关系,再按照人类的阅读习惯(如从封面到目录、从总则到附件)按逻辑顺序提取文字,彻底解决了多栏文档、复杂表格识别时上下文断裂、内容错位的问题。
作为开源项目,DeepSeek-OCR 2完全开源可商用,提供完整的代码仓库、技术论文、依赖配置及推理示例,支持本地部署、云端API调用两种方式,同时预留了vLLM与Transformers两种推理入口,兼顾了普通用户的易用性与开发者的二次开发需求[5]。其核心优势体现在高精度、高效率与高适配性上:在OmniDocBench v1.5权威基准测试中,整体得分达到91.09%,较前代模型提升3.73%;在衡量阅读顺序准确度的标准化编辑距离指标上,从0.085降至0.057,性能提升约33%;在实际生产环境中,能够显著减少日志、PDF预处理中的重复内容与无意义输出,稳定性与可靠性大幅提升[5]。
二、功能特色
DeepSeek-OCR 2以“类人识别、高精度、高效率、易使用”为核心,整合了前代模型的优势并进行全面升级,其功能特色可概括为以下6点:
(一)核心功能特色
类人视觉因果流阅读(核心亮点)
这是DeepSeek-OCR 2最突出的功能特色,区别于传统OCR“左上到右下”的固定栅格扫描模式,该模型采用视觉因果流设计,先对文档页面进行全局结构解析,再按人类逻辑顺序提取内容。例如,识别多栏排版的采购合同时,模型会先区分条款、价格表、附件等模块,再按“封面→目录→总则→价格表→违约责任→附件”的顺序识别,确保条款上下文连贯,避免出现“左栏第3条接右栏第1条”的混乱情况;识别带合并单元格的表格时,能够精准还原表格结构,确保单元格内容与表头对应无误,解决传统OCR表格识别错位的痛点。高精度多类型内容识别
模型在文本、表格、公式识别上均达到行业优异水平,尤其适配复杂文档场景:在OmniDocBench v1.5基准测试中,文本识别错误率从0.073降至0.048,减少34%;公式识别错误率从0.236降至0.198,能够精准识别嵌入正文的复杂公式(如“违约金=合同金额×0.5%×逾期天数”),且识别结果可直接复制编辑;同时支持中英文双语文档、学术论文、杂志、发票、病历等多种类型文档的识别,适配不同字体、不同排版风格,抗干扰能力强(如轻微倾斜、模糊的图片也能正常识别)[4]。高效推理,兼顾速度与成本
项目核心采用vLLM推理框架,兼顾推理速度与资源消耗:支持图片流式输出,识别过程中可实时查看结果,无需等待整体处理完成;支持PDF文档并发处理,推理速度与前代DeepSeek-OCR持平,能够高效处理多页PDF文档;通过视觉token压缩技术,将视觉token控制在256–1120之间,在不降低识别精度的前提下,大幅减少计算资源消耗,兼顾精度与部署成本[3]。同时预留了Transformers推理入口,满足不同开发者的推理框架使用习惯。多场景全面适配
覆盖OCR核心应用场景,无需额外开发即可直接使用:支持单张/多张图片OCR识别(格式包括jpg、png、jpeg等常见格式)、多页PDF文档识别(支持并发处理)、OmniDocBench v1.5等基准数据集的批量评估,适配学术论文、企业合同、财务发票、生产日志、教材资料等多种实际场景,真正实现“一站式”OCR处理[2]。开源可定制,部署灵活
项目完全开源,所有代码、配置文件、技术论文均公开可获取,支持用户根据自身需求进行二次开发(如修改识别逻辑、适配特定行业文档、集成到自有系统);支持本地部署(适配GPU环境)与云端API调用两种方式,本地部署可保障数据隐私,云端调用可降低部署成本;同时兼容主流深度学习环境,解决了vLLM与Transformers推理框架的版本冲突问题,部署过程简单易懂[5]。环境兼容,易用性强
推荐运行环境为cuda11.8 + torch2.6.0,兼容Windows、Linux等主流操作系统;安装过程提供完整的命令指引,关键步骤补充注意事项(如vllm包的下载、版本冲突解决),即使是非专业开发者也能快速完成部署与使用;推理过程仅需执行简单命令,无需编写复杂代码,同时支持通过修改配置文件调整输入/输出路径、识别参数等,兼顾易用性与灵活性。
(二)DeepSeek-OCR 2与传统OCR模型功能对比表
| 核心功能 | 传统OCR模型 | DeepSeek-OCR 2 |
|---|---|---|
| 阅读模式 | 固定栅格扫描(左上到右下),无逻辑识别 | 视觉因果流阅读,先全局感知,再按人类逻辑顺序识别 |
| 复杂排版识别(多栏、表格) | 识别顺序混乱,表格单元格错位、条款上下文断裂 | 精准还原结构,内容顺序连贯,表格与表头对应无误 |
| 公式识别 | 易识别为乱码或错误字符,无法编辑 | 精准识别复杂公式,识别结果可直接复制编辑 |
| 基准测试表现 | 无明确优异成绩,错误率较高 | OmniDocBench v1.5得分91.09%,错误率显著降低 |
| 推理速度 | 单线程处理,PDF多页识别速度慢 | vLLM推理,支持流式输出、PDF并发处理,速度高效 |
| 资源消耗 | 视觉token冗余,计算资源消耗大 | 视觉token压缩(256–1120),兼顾精度与成本 |
| 开源可定制 | 多为闭源工具,开源版本可定制性差 | 完全开源,支持二次开发,预留多推理入口 |

三、技术细节
DeepSeek-OCR 2的核心优势源于其底层技术架构的创新,结合开源仓库的技术文档与官方发布的技术报告,以下从核心架构、关键技术、推理框架、技术参数四个方面,以通俗易懂的方式解读其技术细节:
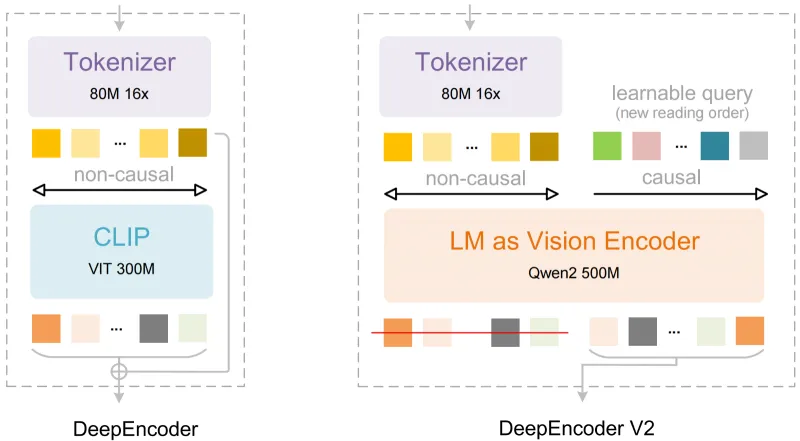
(一)核心架构:DeepEncoder V2
DeepSeek-OCR 2采用全新的DeepEncoder V2架构,这是其实现类人视觉因果流阅读的核心基础,与前代模型及传统OCR模型的核心差异在于视觉编码器的升级与注意力机制的优化[2]:
弃用传统OCR常用的CLIP编码器,改用Qwen2-0.5B轻量LLM(大语言模型)作为视觉编码器,让模型不仅能够“看见”文字,还能“理解”文字的逻辑关系,为类人阅读顺序识别提供了基础;
引入“因果流查询token”(Causal Flow Query Token),该token能够模拟人类的阅读注意力分配,引导模型先关注文档的核心模块(如标题、关键条款),再逐步拓展到次要内容,实现逻辑化阅读顺序的控制[2];
整体架构轻量化设计,在保证识别精度的前提下,降低了模型的部署门槛,普通GPU即可满足本地部署需求,同时提升了推理速度。
(二)关键技术:双注意力机制
为实现“全局感知+逻辑顺序识别”的双重目标,DeepSeek-OCR 2引入了双注意力机制,分别对应视觉感知与逻辑推理两个环节,协同提升识别效果:
视觉token双向注意力:用于文档全局结构感知,模型通过双向注意力机制扫描整个文档页面,识别出文本、表格、公式、图片等不同元素的位置、边界与类型,构建全局文档结构图谱,为后续逻辑顺序识别奠定基础;
因果流token因果注意力:用于逻辑顺序推理,因果流查询token通过因果注意力机制,学习人类的阅读习惯(如先主后次、先总后分),按逻辑顺序提取各个模块的内容,确保识别结果的上下文连贯性,避免出现内容错位、顺序混乱的问题。
这种双注意力机制的结合,让模型既具备“全局观”(看懂文档结构),又具备“逻辑感”(按人类习惯阅读),从根本上解决了传统OCR复杂文档识别的核心痛点。
(三)推理框架:vLLM为主,Transformers为辅
项目核心优化了推理效率,采用“vLLM推理为主、Transformers推理为辅”的双推理入口设计,兼顾速度与兼容性[3]:
主流推理方式:vLLM推理框架,版本要求≥0.8.5,该框架能够大幅提升大模型的推理速度,支持流式输出(实时查看识别结果)与PDF并发处理,是项目推荐的推理方式,也是实现高效识别的核心保障;
备用推理方式:预留Transformers推理入口,版本要求≥4.51.1,适配习惯使用Transformers框架的开发者,无需修改核心代码,仅需调整推理脚本即可切换推理方式;
版本冲突解决方案:项目已优化依赖配置,若需在同一环境中同时运行vLLM与Transformers推理代码,无需担心两者的版本冲突问题,降低了使用门槛。
(四)核心技术参数表
为便于开发者快速了解项目的技术适配范围,以下整理核心技术参数,清晰明了:
| 技术参数 | 具体要求/数值 |
|---|---|
| 核心架构 | DeepEncoder V2 |
| 视觉编码器 | Qwen2-0.5B(轻量LLM) |
| 注意力机制 | 视觉token双向注意力、因果流token因果注意力 |
| 推理框架 | vLLM(≥0.8.5)、Transformers(≥4.51.1) |
| 推荐运行环境 | cuda11.8 + torch2.6.0 |
| 支持Python版本 | 3.12.9(推荐) |
| 视觉token范围 | 256–1120(可调整) |
| 基准测试得分(OmniDocBench v1.5) | 91.09% |
| 阅读顺序标准化编辑距离 | 0.057(较前代下降33%) |
| 支持文档格式 | 图片(jpg、png、jpeg等)、PDF |
| 开源协议 | 开源可商用(详见仓库LICENSE) |
四、应用场景
DeepSeek-OCR 2凭借其高精度、高效率、多场景适配的特点,可广泛应用于文档处理、办公自动化、教育科研、企业数字化等多个领域,覆盖个人用户、开发者、企业等不同群体,具体应用场景如下:
(一)文档数字化场景
这是OCR最核心的应用场景,DeepSeek-OCR 2尤其适配复杂格式的文档数字化,解决传统OCR数字化后内容混乱的问题:
企业档案数字化:将企业留存的纸质合同、财务发票、人事档案、生产日志等转化为可检索、可编辑的数字文本,模型能够精准识别合同中的多栏条款、合并单元格表格、嵌入公式,确保数字化后内容的完整性与准确性,同时支持批量处理,大幅提升档案数字化效率,减少人工校对成本[5];
政务/医疗文档数字化:将政务办理中的纸质材料、医院的病历、检查报告等转化为数字文本,适配不同排版风格,确保关键信息(如姓名、日期、检查结果、条款内容)识别无误,助力政务高效办理、医疗档案电子化管理;
个人文档数字化:将个人留存的纸质笔记、教材、杂志文章、身份证、银行卡等图片转化为数字文本,支持流式输出,实时查看识别结果,方便后续编辑、备份与检索。
(二)办公自动化场景
适配企业日常办公中的文档处理需求,提升办公效率,减少人工重复劳动:
PDF文档处理:批量处理多页PDF文档(如员工手册、会议纪要、客户资料),将PDF中的文字、表格、公式提取为可编辑的文本格式(如TXT、Word),支持并发处理,速度高效,解决传统PDF转文字后格式混乱、表格错位的问题;
图片文字提取:快速提取工作中图片中的文字(如截图、扫描件、现场拍摄的公告),无需手动录入,支持多张图片批量处理,适用于会议纪要整理、公告内容提取、截图文字复用等场景;
批量核对处理:对批量的发票、单据进行OCR识别,提取关键信息(如金额、日期、发票号),便于后续批量核对、统计,减少财务、行政人员的手动录入与核对工作量,降低错误率。
(三)教育科研场景
适配教师、科研人员的文档处理需求,助力学术研究与教学工作高效开展:
学术论文处理:快速识别中英文学术论文中的文本、公式、表格,将扫描版论文转化为可编辑的文本,方便科研人员引用公式、整理表格数据、修改论文内容,尤其适合老旧论文的数字化复用与文献综述整理;
教材/课件整理:将教材、讲义、课件中的图片、扫描件转化为可编辑文本,提取其中的公式、知识点,便于教师修改课件、整理教学资料,也方便学生提取知识点、整理笔记;
智能批改辅助:提取学生作业、试卷中的手写文字(清晰手写)与公式,辅助教师进行批量批改、知识点统计,减少手动批改的工作量,提升批改效率。
(四)开发者二次开发场景
由于项目完全开源,支持二次开发,开发者可基于DeepSeek-OCR 2的核心代码,适配自身行业需求,开发专属OCR工具:
集成到自有系统:将DeepSeek-OCR 2的推理功能集成到企业自有系统(如客户管理系统、档案管理系统、办公自动化系统),实现系统内的OCR识别功能,提升系统的智能化水平;
定制化开发:根据特定行业需求,修改识别逻辑、优化识别精度(如适配特定字体、特定格式的文档),开发专属的OCR工具(如法律行业的合同专用OCR、医疗行业的病历专用OCR);
技术研究与优化:基于项目的核心架构与技术论文,开展OCR相关的技术研究,优化模型性能、拓展应用场景,助力OCR技术的进一步发展。
(五)企业级批量处理场景
适配中大型企业的海量文档处理需求,具备高稳定性与高效率,可应用于:
生产日志处理:对企业生产过程中产生的海量日志扫描件、图片进行OCR识别,提取关键生产数据(如产量、时间、设备参数),便于后续数据统计、分析与存档,减少人工录入工作量,提升生产管理效率;
海量档案管理:对企业积累的海量纸质档案、扫描件进行批量数字化处理,构建可检索的数字档案库,便于档案的查询、复用与管理,降低档案存储与管理成本;
跨部门文档协同:将不同部门的纸质文档、PDF、图片转化为统一格式的数字文本,便于跨部门文档协同、共享与编辑,提升企业内部的工作协同效率。
五、使用方法
DeepSeek-OCR 2的使用分为“环境准备→仓库克隆→依赖安装→推理使用”四个核心步骤,全程提供详细命令指引,适配GPU环境(推荐),即使是非专业开发者也能快速上手。
(一)前置准备
硬件要求:推荐使用支持CUDA的GPU(显存≥8G),确保能够正常运行cuda11.8版本;若没有GPU,可使用CPU运行,但推理速度会大幅下降,不推荐用于批量处理或复杂文档识别;
软件要求:提前安装Anaconda(用于创建虚拟环境,避免依赖冲突)、Git(用于克隆仓库),确保电脑能够正常访问GitHub与Hugging Face(用于下载模型与代码);
提前下载文件:需提前下载vllm-0.8.5对应版本的whl包(适配cuda11.8、python3.12.9),可从vllm官方仓库或镜像源下载,避免安装时下载失败。
(二)具体操作步骤
步骤1:克隆项目仓库
打开终端(Windows使用Anaconda Prompt,Linux使用终端),执行以下命令,克隆DeepSeek-OCR 2的开源仓库,并进入仓库目录:
# 克隆仓库 git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git # 进入仓库目录 cd DeepSeek-OCR-2
注意事项:若克隆失败(如网络问题),可直接访问GitHub仓库(链接见下文“相关官方链接”),手动下载仓库压缩包,解压后进入解压目录即可。
步骤2:创建并激活虚拟环境
为避免依赖冲突,推荐使用Anaconda创建独立的虚拟环境,执行以下命令:
# 创建虚拟环境(环境名:deepseek-ocr2,python版本3.12.9) conda create -n deepseek-ocr2 python=3.12.9 -y # 激活虚拟环境 conda activate deepseek-ocr2
注意事项:python版本推荐使用3.12.9,若使用其他版本,可能会出现依赖安装失败的问题;虚拟环境名可自定义,激活后终端前缀会显示环境名,表明已进入虚拟环境。
步骤3:安装依赖包
依赖包安装分为4步,需严格按照顺序执行,确保版本对应,避免出现报错;提前将下载好的vllm-0.8.5 whl包放入当前仓库目录:
# 1. 安装PyTorch套件(适配cuda11.8版本,关键步骤) pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 # 2. 安装vllm离线包(提前下载好的whl包,替换下方文件名为实际下载的文件名) pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 3. 安装仓库依赖包(读取requirements.txt中的依赖) pip install -r requirements.txt # 4. 安装flash-attn(提升模型推理速度,需添加--no-build-isolation参数) pip install flash-attn==2.7.3 --no-build-isolation
关键注意事项:
若cuda版本不是11.8,需对应修改PyTorch与vllm包的版本,否则会出现无法运行的问题;
若安装flash-attn失败,可尝试更换镜像源(如阿里云、清华镜像源),或参考flash-attn官方文档解决;
若需同时使用vLLM与Transformers推理框架,无需担心版本冲突,项目已优化依赖配置。
步骤4:下载模型文件
DeepSeek-OCR 2的模型文件需从Hugging Face下载,执行以下步骤:
访问Hugging Face模型地址(见下文“相关官方链接”);
下载模型文件(可通过git lfs克隆,或手动下载压缩包);
将下载好的模型文件解压,放入仓库的指定目录(默认路径:DeepSeek-OCR2-master/DeepSeek-OCR2-vllm/model/,若路径不存在,可手动创建)。
注意事项:模型文件较大(约数GB),建议使用高速网络下载;若手动下载失败,可使用git lfs命令克隆模型仓库。
步骤5:推理使用(核心步骤)
项目支持3种核心推理场景:图片推理、PDF推理、基准测试批处理,分别介绍具体操作方法,均需在激活虚拟环境、进入对应目录后执行:
场景1:图片推理(支持流式输出)
适用于单张/多张图片的OCR识别,支持流式输出,实时查看识别结果:
# 进入vLLM推理目录 cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm # 执行图片推理命令(默认读取config.py中配置的图片路径) python run_dpsk_ocr2_image.py
注意事项:
可修改config.py文件中的“image_input_path”(输入图片路径)与“image_output_path”(输出结果路径),适配自身需求;
支持jpg、png、jpeg等常见图片格式,多张图片可放入同一输入目录,批量处理;
流式输出可实时查看识别过程,若无需流式输出,可修改脚本中的输出配置。
场景2:PDF推理(支持并发处理)
适用于多页PDF文档的OCR识别,支持并发处理,速度高效:
# 进入vLLM推理目录(若已在该目录,可跳过此步) cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm # 执行PDF推理命令(默认读取config.py中配置的PDF路径) python run_dpsk_ocr2_pdf.py
注意事项:
可修改config.py文件中的“pdf_input_path”(输入PDF路径)与“pdf_output_path”(输出结果路径);
支持多页PDF并发处理,可在config.py中修改并发数(根据自身GPU性能调整,避免显存溢出);
输出结果默认保存为TXT格式,可修改脚本,将结果保存为Word、Markdown等格式。
场景3:基准测试批处理
适用于OmniDocBench v1.5等基准数据集的批量评估,用于测试模型性能:
# 进入vLLM推理目录 cd DeepSeek-OCR2-master/DeepSeek-OCR2-vllm # 修改config.py文件(关键步骤) # 1. 修改“benchmark_input_path”:基准数据集输入路径 # 2. 修改“benchmark_output_path”:评估结果输出路径 # 3. 配置其他评估参数(如批量大小、推理模式) # 执行基准测试命令 python run_dpsk_ocr2_benchmark.py
注意事项:需提前下载OmniDocBench v1.5基准数据集,放入指定路径;测试过程中会输出模型的识别准确率、编辑距离等指标,用于评估模型性能。
步骤6:退出虚拟环境
使用完成后,执行以下命令退出虚拟环境:
conda deactivate
(三)关键使用注意事项
环境配置是核心,务必确保cuda11.8、torch2.6.0、vllm-0.8.5版本对应,否则会出现无法运行或推理报错的问题;
模型文件需放入指定目录,路径配置错误会导致推理失败,若忘记路径,可查看脚本中的注释或config.py文件;
批量处理图片/PDF时,需根据自身GPU显存大小调整批量数,避免显存溢出(若出现显存溢出,可减少批量数或关闭其他占用GPU的程序);
识别模糊、严重倾斜、手写潦草的图片时,识别准确率会下降,建议使用清晰、正置的图片/扫描件;
若需使用Transformers推理框架,可进入“DeepSeek-OCR2-master/DeepSeek-OCR2-hf/”目录,执行对应推理脚本,步骤与vLLM推理类似。
六、常见问题解答(FAQ)
结合开源项目的常见问题、用户可能遇到的操作报错,以及项目的技术特性,整理以下常见问题及详细解决方法,通俗易懂,帮助用户快速解决使用过程中的问题:
1. 环境安装时,出现“cuda版本不匹配”报错,怎么办?
问题原因:torch版本与cuda版本不对应(如cuda11.8安装了适配cuda12.1的torch),或未安装cuda11.8。
解决方法:
先确认电脑的cuda版本:终端执行“nvcc -V”(若未安装cuda11.8,需先安装cuda11.8,参考NVIDIA官方教程);
卸载当前torch版本:执行“pip uninstall torch torchvision torchaudio”;
重新安装适配cuda11.8的torch版本,严格执行步骤3中的命令,确保使用“--index-url https://download.pytorch.org/whl/cu118”参数。
2. 安装vllm时,出现“下载失败”或“版本不兼容”,怎么办?
问题原因:网络问题导致无法下载vllm包,或vllm包版本与python、cuda版本不匹配。
解决方法:
提前从vllm官方仓库(https://github.com/vllm-project/vllm)下载适配cuda11.8、python3.12.9的vllm-0.8.5 whl包,放入仓库目录后,执行离线安装命令;
若仍出现版本不兼容,可更换python版本为3.12.9(推荐版本),或查看vllm官方文档,确认适配的python与cuda版本。
3. 推理时,出现“模型路径错误”或“模型文件缺失”报错,怎么办?
问题原因:模型文件未放入指定目录,或config.py中配置的模型路径与实际路径不一致。
解决方法:
确认模型文件已下载完成,并放入“DeepSeek-OCR2-master/DeepSeek-OCR2-vllm/model/”目录(若路径不存在,手动创建);
打开config.py文件,找到“model_path”参数,修改为模型文件的实际路径(绝对路径或相对路径均可);
若模型文件缺失某部分(如下载中断),需重新下载模型文件,确保文件完整。
4. 识别PDF/图片时,出现“显存溢出”报错,怎么办?
问题原因:批量处理时批量数过大,或GPU显存不足,无法支撑当前推理任务。
解决方法:
减少批量数:打开config.py文件,找到“batch_size”参数,适当减小数值(如从8改为4、2),根据自身GPU显存大小调整;
关闭其他占用GPU的程序:关闭终端、浏览器等可能占用GPU的程序,释放显存资源;
若GPU显存过小(<8G),建议减少单次处理的文件数量,或改用CPU推理(不推荐,速度极慢)。
5. 识别结果出现顺序混乱、表格错位、公式错误,怎么办?
问题原因:未启用视觉因果流功能,或图片/PDF清晰度不足、排版过于复杂,或模型版本未更新。
解决方法:
确认启用视觉因果流功能:检查推理脚本,确保“causal_flow”参数设置为“True”(默认启用,若被修改,需改回);
优化输入文件:使用清晰、正置的图片/扫描件,避免模糊、倾斜、遮挡的文件;对于过于复杂的排版(如多栏嵌套、表格合并过多),可拆分文件,分部分识别;
更新模型版本:克隆最新的仓库代码,重新下载模型文件,确保使用的是最新版本(修复了前代的识别bug)。
6. 能否在CPU环境下使用DeepSeek-OCR 2?如何操作?
回答:支持CPU环境使用,但推理速度会大幅下降(约为GPU的1/10甚至更慢),仅推荐用于少量简单图片的识别,不推荐批量处理或复杂文档识别。
操作方法:
安装依赖时,无需安装cuda相关组件,直接执行pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0(无需添加--index-url参数,自动安装CPU版本torch);
修改config.py文件,将“device”参数设置为“cpu”;
执行推理命令,即可在CPU环境下运行,注意减少批量数,避免运行过慢。
7. 如何将识别结果保存为Word/Markdown格式?
问题原因:默认输出格式为TXT,需修改推理脚本,添加对应输出逻辑。
解决方法:
打开对应的推理脚本(如run_dpsk_ocr2_image.py、run_dpsk_ocr2_pdf.py);
找到输出相关的代码(如“with open(output_path, 'w', encoding='utf-8') as f:”);
引入对应的库(如python-docx用于保存Word,markdown库用于保存Markdown);
修改输出逻辑,将识别结果按对应格式写入文件(具体可参考python-docx、markdown库的使用教程,难度较低)。
8. 二次开发时,如何修改识别逻辑、优化特定场景的识别精度?
解决方法:
核心修改文件:进入“DeepSeek-OCR2-master/DeepSeek-OCR2-vllm/model/”目录,修改模型的配置文件(如model_config.py),调整注意力机制参数、识别逻辑;
数据微调:若需适配特定场景(如特定字体、特定格式文档),可准备对应场景的数据集,对模型进行微调,优化识别精度(参考仓库中的微调教程,需具备基础的深度学习知识);
脚本修改:根据需求,修改推理脚本(如run_dpsk_ocr2_image.py),添加自定义的预处理(如图片降噪、倾斜校正)或后处理(如结果格式化、错误修正)逻辑。
七、相关链接
模型下载地址(Hugging Face):https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
八、总结
DeepSeek-OCR 2是由deepseek-ai开源的新一代OCR模型,基于视觉因果流设计理念,采用DeepEncoder V2核心架构,弃用传统CLIP编码器,改用Qwen2-0.5B轻量LLM作为视觉编码器,引入双注意力机制,实现了类人逻辑的文档识别,彻底解决了传统OCR复杂排版识别混乱的痛点。该项目开源可商用,提供完整的代码、论文、推理工具及依赖配置,支持vLLM与Transformers双推理入口,具备高精度(OmniDocBench v1.5得分91.09%)、高效率(流式输出、PDF并发处理)、多场景适配(图片、PDF、基准测试)、易使用、可定制的特点,在文档数字化、办公自动化、教育科研、开发者二次开发等多个领域均有广泛应用。其核心优势在于兼顾了类人识别的精准性与实际使用的高效性,同时通过开源降低了使用与开发门槛,既适合普通用户快速完成OCR识别任务,也适合开发者进行二次开发与技术研究,是一款兼具易用性与专业性的开源OCR工具。
相关软件下载

DeepSeek
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/deepseek-ocr-2.html





