Unlimited-OCR:百度开源长文档OCR模型,单次推理批量解析数十页PDF文档
Unlimited-OCR是百度开源的端到端长文档OCR多模态模型,基于Deepseek-OCR迭代升级,主打单次前向传播一次性完成数十页长文档连贯解析,官方定位为「One-shot Long-horizon ...

Unlimited-OCR是百度开源的端到端长文档OCR多模态模型,基于Deepseek-OCR迭代升级,主打单次前向传播一次性完成数十页长文档连贯解析,官方定位为「One-shot Long-horizon ...

PP-OCRv6 是百度飞桨(PaddlePaddle)团队推出的第六代开源轻量化通用光学字符识别模型套件,隶属于PaddleOCR开源项目体系,专为全终端、全行业文字识别场景打造。

dots.mocr是由小红书人文智能实验室HiLab携手华中科技大学联合研发、完全开源的轻量化多模态文档解析与增强型OCR大模型,隶属于dots系列AI视觉技术生态,专为解决传统OCR技...

Qianfan-OCR是百度千帆团队研发的4B参数端到端统一文档智能模型,基于视觉语言架构,将文档解析、版面分析、文档理解融为一体,支持图像直接转Markdown/JSON/HTML,覆盖OCR...

Zerox是一款面向AI数据摄入场景的开源光学字符识别工具,核心定位是用极简方式把各类视觉形态的文档,转换成AI可直接处理的结构化Markdown格式。它由getomni-ai团队开发并维...

GLM-OCR是智谱AI开源的轻量级多模态文档OCR模型,核心定位是小参数、高精度、易部署、全场景覆盖的专业级文档理解与文字提取工具。它基于GLM-V视觉-语言编码器-解码器架构构...

DeepSeek-OCR 2是由deepseek-ai开源的新一代OCR(光学字符识别)模型,基于视觉因果流设计理念,核心是让AI模拟人类阅读逻辑处理图像与文档,该模型采用DeepEncoder V2架构...

LightOnOCR-2-1B 是由 LightOnAI 开源的端到端多语言视觉 - 语言 OCR 模型,仅含 10 亿参数,却实现了当前业界领先的识别性能。该模型打破传统多阶段 OCR 流水线的局限,可...
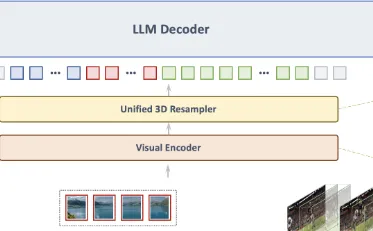
深度解析 MiniCPM-V 4.5 多模态大模型,手把手教你完成本地部署。支持高精度 OCR 与长视频理解,基于 Ubuntu 环境,适配 GGUF 量化,轻松在消费级硬件运行视觉语言模型。

DeepOCR是基于VILA代码库复现Deepseek-OCR的开源项目,核心聚焦于通过视觉-文本令牌压缩技术实现高效OCR任务。其创新的DeepEncoder架构融合SAM(窗口注意力)与CLIP(全局注...

HunyuanOCR是腾讯混元开源的端到端OCR专家模型,基于混元原生多模态架构构建,仅1B参数便实现了业界多项SOTA性能。该工具覆盖文字检测识别、复杂文档解析、开放字段信息抽取...

olmocr 是由AllenAI开源的文档 OCR 工具包,专注于将 PDF、PNG、JPEG 等图像格式的文档转换为结构化、可读的纯文本(尤其是 Markdown 格式)。它基于 7B 参数的视觉语言模型...

DeepSeek-OCR 是由 deepseek-ai 团队开源的高性能 OCR 模型,核心聚焦于从 LLM 视角探索视觉 - 文本压缩技术,支持图像、PDF 等多模态输入的文本提取。该模型提供 Native和...

Qwen3-VL 是 Qwen 系列开源的强大多模态视觉 - 语言模型,支持图像 / 视频理解、文本交互、视觉代理等全场景任务,具备长上下文处理、空间感知、跨语言 OCR 等核心能力,提...

Dolphin是字节跳动推出的一款多模态文档图像解析框架,采用"分析-解析"两阶段范式,通过异构锚点提示技术实现高精度文档理解。该框架能够有效识别和解析文档中的文本段落、...