DeepSeek-V4:深度求索(DeepSeek) 发布的第四代开源大语言模型
DeepSeek-V4是什么
DeepSeek-V4是深度求索(DeepSeek)于2026年4月推出的新一代开源混合专家(MoE)大语言模型,分为V4-Pro(1.6T总参数)与V4-Flash(284B总参数)双版本,全系标配100万Token超长上下文,搭载DSA稀疏注意力与mHC架构创新,推理效率较前代大幅提升。模型强化Agent能力与复杂推理性能,适配代码开发、法律金融、科研办公等场景,兼容OpenAI接口并支持华为昇腾与英伟达双算力部署,以高性能、低成本、开源开放的特性,推动国产大模型在长文本与智能体领域的普惠落地。
版本核心参数
DeepSeek-V4-Pro:总参数1.6T,激活参数49B,预训练数据33T,定位高性能旗舰,主打复杂推理、Agent任务与高强度代码开发。
DeepSeek-V4-Flash:总参数284B,激活参数13B,预训练数据32T,定位高效经济,主打低时延、低成本的日常场景与轻量Agent任务。
DeepSeek-V4的核心突破在于长上下文效率革命与Agent能力专项优化:通过DSA稀疏注意力、mHC超连接、Engram条件存储等技术创新,将百万上下文的推理成本降至前代V3.2的10%-27%,显存占用降低40%,推理速度提升1.8倍,同时强化工具调用、思维链(思考模式)与多文件代码理解能力,适配从个人用户到企业级的多元需求。

功能特色
DeepSeek-V4围绕长文本处理、高效推理、Agent智能体、企业级适配四大核心方向打造,兼具技术突破性与场景实用性,核心特色如下:
1. 百万上下文标配,长文本处理能力拉满
原生1M Token无损上下文:支持一次性处理约75万字中文,可完整读完整本专业书籍、整套合同或大型代码库,记忆准确率达98.2%。
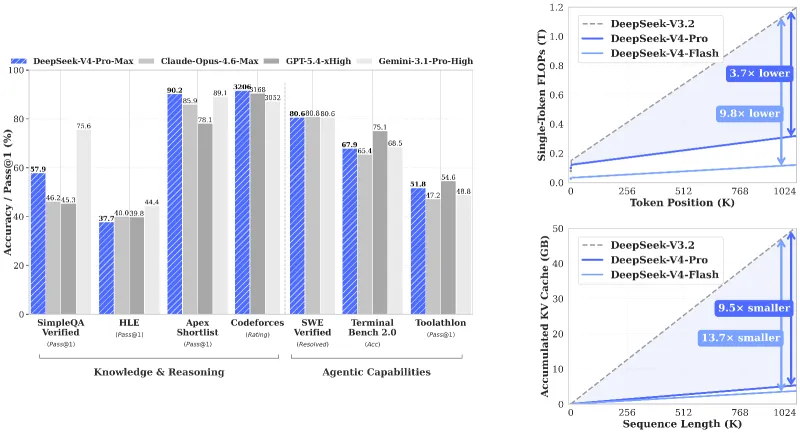
DSA稀疏注意力+混合注意力(CSA+HCA):在Token维度压缩,规避传统注意力O(n²)复杂度,1M上下文下单Token推理FLOPs仅为V3.2的27%(Pro)/10%(Flash),KV Cache降至10%(Pro)/7%(Flash),大幅降低长文本处理的算力与显存门槛。
超长文档无缝交互:支持直接拖拽上传百万字级文档(PDF/Word/TXT),自动提炼核心、梳理逻辑、提取关键信息,无需碎片化分段处理。
2. 双模式推理,兼顾效率与深度思考
思考模式(Think Mode):内置思维链(CoT) 能力,自动拆解复杂问题、分步推理、自我校验,在数学竞赛、科研推理、复杂代码设计等场景效果显著提升,V4-Pro思考模式下Agentic Coding评测达开源最佳水平。
非思考模式(Fast Mode):关闭深度推理,响应速度提升30%-50%,适合日常对话、文案生成、简单问答等轻量场景,兼顾速度与成本。
模式一键切换:用户可根据任务复杂度灵活切换,API支持通过参数控制模式,适配不同业务需求。
3. Agent能力专项强化,工程级智能体表现
代码Agent天花板:支持338种编程语言,一次性理解数十万行跨文件代码库,可完成全局重构、漏洞检测、测试生成与架构设计;LiveCodeBench得分93.5%、Codeforces Rating 3206,超越Claude Opus 4.5、GPT-5.4,登顶开源模型首位。
工具调用全适配:原生支持函数调用、API调用、代码解释器、文件操作等工具能力,适配Claude Code、OpenClaw、CodeBuddy等主流Agent框架,可自主完成“需求拆解-工具调用-结果整合”全流程任务。
长程任务规划:依托百万上下文,支持超长序列任务(如大型项目管理、长期数据分析),可记忆历史交互、执行多步骤复杂指令,减少人工干预。
4. 极致推理效率,低成本高性能
MoE稀疏激活:万亿级总参数仅激活少量专家(Pro 49B/Flash 13B),实现“大模型知识储备+小模型推理成本”,同等性能下推理成本较稠密模型降低9倍。
双算力原生支持:同时适配英伟达CUDA与华为昇腾CANN,V4-Pro在昇腾950上推理时延低至20ms,V4-Flash低至10ms,单卡性能达英伟达H20的2.87倍,助力国产算力自主可控。
普惠定价策略:V4-Flash输入0.2元/百万Token、输出2元/百万Token;V4-Pro输入1元/百万Token、输出24元/百万Token,成本仅为GPT-5.5的1.55‰、Claude Opus的数十分之一。
5. 企业级功能完备,安全可控
OpenAI兼容接口:API格式与OpenAI完全一致,开发者仅需修改model_name为
deepseek-v4-pro或deepseek-v4-flash即可无缝迁移,零学习成本。JSON格式输出:原生支持结构化JSON输出,适配数据解析、系统对接、自动化工作流等企业场景。
隐私保护与数据安全:支持本地部署、私有化部署,企业可开启隐私保护盾,数据不出境、不泄露,符合合规要求。
FIM补全与对话续写:支持代码中间补全(FIM)与对话前缀续写,适配开发工具集成、长对话场景。
应用场景
DeepSeek-V4凭借百万上下文、高效推理、Agent能力三大核心优势,覆盖个人创作、企业办公、代码开发、法律金融、科研教育、工业制造等全场景,尤其在长文本处理与复杂Agent任务中表现突出:
1. 代码开发:工程级全栈助手
大型代码库理解:一次性解析数十万行跨文件代码,梳理架构逻辑、检测漏洞、生成文档,处理1亿Token代码库仅需2分18秒。
全流程开发支持:从需求分析、架构设计、代码生成、调试优化到测试用例生成,全链路辅助,支持338种编程语言,适配前端、后端、移动端、嵌入式等开发场景。
竞赛级编程能力:Codeforces Rating 3206,可解决高难度算法题,适合科研编程、竞赛训练与复杂算法开发。
2. 法律与金融:专业长文本处理标杆
法律合同审查:处理百万字级合同、协议、法规,自动检测条款冲突、风险点、合规问题,效率提升10倍,成本降至传统方式的1/10。
金融投研分析:快速消化百页级财报、招股书、研报,提炼核心数据、分析趋势、生成投资报告,支撑风险计量、反洗钱监测、市场预测。
合规文档生成:生成合规报告、风险披露文件、监管申报材料,确保内容准确、格式规范、符合行业标准。
3. 智能办公:长文档与多任务效率革命
超长文档处理:一键分析千页级报告、书籍、会议纪要,自动总结、提取要点、生成摘要,支持多文档对比与关联分析。
内容创作辅助:撰写长文、报告、方案、文案,支持结构化排版、多版本迭代、内容润色,适配职场办公、自媒体创作、学术写作。
自动化工作流:通过Agent能力自动完成邮件分类、日程安排、数据整理、报表生成等重复性工作,提升团队协作效率。
4. 科研与教育:知识深度理解与教学赋能
学术论文分析:解析长篇论文、综述、研究报告,提炼研究方法、实验数据、核心结论,支持跨论文对比与研究思路梳理。
复杂知识讲解:讲解数学、物理、计算机等硬核学科知识,分步拆解难题、推导过程、答疑解惑,适配K12、高等教育、职业培训。
科研数据处理:分析基因组学、天体物理、社会科学等领域超长序列数据,加速前沿研究进程,降低科研成本。
5. 企业服务与客服:长对话与智能交互升级
长对话记忆:依托百万上下文,支持超长会话(如全天客服、长期咨询),记忆历史交互内容,无需重复说明需求,提升用户体验。
智能客服与咨询:自动解答复杂问题、处理多轮咨询、生成个性化回复,适配电商、金融、医疗、政务等行业客服场景。
企业知识库问答:构建企业专属知识库,支持长文档问答、精准检索、知识推理,助力员工培训、客户咨询、内部协作。
使用方法
DeepSeek-V4提供网页端、移动端、API调用、本地部署四种使用方式,覆盖普通用户与开发者需求,操作简单、上手门槛低:
1. 网页端(新手首选,零部署)
访问官网:打开浏览器输入
https://chat.deepseek.com,无需注册即可体验。模型选择:默认使用V4-Flash,点击顶部“模型切换”可选择V4-Pro。
模式切换:点击“思考模式”开关,开启/关闭深度推理,适配不同任务。
交互操作:直接输入文字提问,或拖拽上传文档(PDF/Word/TXT),支持长文本输入与多轮对话。
高级功能:支持代码编辑、JSON输出、对话续写,可调整温度(随机性)、最大生成长度等参数。
2. 移动端(随时随地使用)
App端:iOS/Android应用商店搜索“DeepSeek”下载官方App,支持手机号/微信登录,同步网页端对话记录,支持模型切换与思考模式开关。
小程序端:微信搜索“DeepSeek-R1”小程序,无需注册,即点即用,默认V4-Flash,支持模型切换,适合快速问答与轻量任务。
3. API调用(开发者/企业集成)
注册账号:访问
https://platform.deepseek.com注册,生成API Key并保存。安装依赖:使用OpenAI官方SDK,执行安装命令:
pip install openai
基础调用代码(Python):
from openai import OpenAI
client = OpenAI(
api_key="你的API Key",
base_url="https://api.deepseek.com" # DeepSeek兼容接口
)
response = client.chat.completions.create(
model="deepseek-v4-pro", # 可选:deepseek-v4-flash
messages=[
{"role": "system", "content": "你是资深Python开发者"},
{"role": "user", "content": "实现带重试机制的HTTP客户端"}
],
temperature=0.7,
max_tokens=4096,
stream=False # 关闭流式输出
)
print(response.choices[0].message.content)流式输出(实时返回结果):
stream = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "分析这段代码时间复杂度"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)工具调用(Agent能力):支持函数调用、代码解释器等,适配复杂任务自动化。
4. 本地部署(私有化/离线使用)
环境准备:
硬件:英伟达GPU(≥24G显存)或华为昇腾NPU
软件:Python 3.9+、PyTorch 2.0+、Transformers 4.40+
模型下载:从Hugging Face或ModelScope下载模型权重:
Hugging Face:
https://huggingface.co/collections/deepseek-ai/deepseek-v4ModelScope:
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4部署代码(简易版):
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "deepseek-ai/DeepSeek-V4-Flash"
tokenizer=AutoTokenizer.from_pretrained(model_name)
model=AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
load_in_8bit=True # 8位量化,降低显存占用
)
prompt = "解释稀疏注意力机制原理"
inputs=tokenizer(prompt, return_tensors="pt").to("cuda")
outputs=model.generate(**inputs, max_length=1024)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))竞品对比
选取当前主流长文本大模型Claude Opus 4.6(闭源)、GPT-5.4(闭源)、智谱GLM-5(开源) 与DeepSeek-V4进行核心维度对比,突出其在上下文、效率、成本、开源方面的优势:
| 对比维度 | DeepSeek-V4-Pro | DeepSeek-V4-Flash | Claude Opus 4.6 | GPT-5.4 | 智谱GLM-5 |
|---|---|---|---|---|---|
| 模型类型 | 开源MoE | 开源MoE | 闭源稠密 | 闭源MoE | 开源MoE |
| 总参数 | 1.6T | 284B | 未公开 | 未公开 | 1.3T |
| 上下文窗口 | 1M Token | 1M Token | 200K Token | 262K Token | 200K Token |
| 激活参数 | 49B | 13B | 全参数激活 | 未公开 | 40B |
| 推理效率(1M上下文) | V3.2的27% FLOPs | V3.2的10% FLOPs | 高(稠密) | 中(MoE) | 中 |
| 代码能力(LiveCodeBench) | 93.5% | 89.2% | 88.8% | 85% | 87.1% |
| 数学能力(AIME 2026) | 99.4% | 92.1% | 95% | 96% | 93.5% |
| 开源状态 | ✅ 完全开源 | ✅ 完全开源 | ❌ 闭源 | ❌ 闭源 | ✅ 开源 |
| 双算力支持 | 英伟达+昇腾 | 英伟达+昇腾 | 仅英伟达 | 仅英伟达 | 英伟达+昇腾 |
| 输入定价(/百万Token) | 1元 | 0.2元 | 12美元 | 5美元 | 1.5元 |
| 输出定价(/百万Token) | 24元 | 2元 | 24美元 | 25美元 | 3元 |
| 思考模式 | ✅ 原生支持 | ✅ 原生支持 | ✅ 支持 | ✅ 支持 | ❌ 无 |
对比结论
上下文能力断层领先:DeepSeek-V4全系1M上下文,远超竞品200K-262K,长文本处理场景(法律、金融、科研)优势无可替代。
开源+高性能双重优势:作为唯一开源且性能比肩闭源旗舰的模型,V4-Pro代码与数学能力超越Claude Opus 4.6、GPT-5.4,兼顾开源开放与顶级性能。
成本优势碾压级:V4-Flash输出定价2元/百万Token,仅为Claude Opus的1/80、GPT-5.4的1/12,普惠性强;V4-Pro性能接近闭源旗舰,价格仅为其1/10。
国产算力适配领先:原生支持华为昇腾,助力国产算力生态落地,竞品仅支持英伟达,自主可控性不足。
常见问题解答
Q:DeepSeek-V4的1M上下文是真无损吗?
A:是。DeepSeek-V4采用DSA稀疏注意力+混合注意力,实现1M Token无损上下文,无上下文压缩或截断,记忆准确率达98.2%,可完整理解百万字长文本的所有细节与逻辑关联,区别于竞品的“伪长上下文”(实际压缩或分段处理)。
Q:DeepSeek-V4-Pro和Flash该怎么选?
A:按任务复杂度与成本预算选择:
选V4-Pro:适合高强度代码开发、复杂推理、法律合同审查、科研论文分析等专业场景,追求极致性能与准确性。
选V4-Flash:适合日常对话、文案生成、轻量办公、客服咨询等场景,追求低时延、低成本,性价比极高。
Q:DeepSeek-V4可以本地部署吗?对硬件有什么要求?
A:可以完全本地部署,支持英伟达GPU与华为昇腾NPU:
英伟达:建议≥24G显存(如RTX 4090、A10),支持8bit/4bit量化,降低显存占用。
华为昇腾:支持昇腾910/950,原生优化,推理时延更低、性能更强。
部署方式:可通过Transformers、vLLM、TensorRT-LLM等框架部署,支持单机与分布式部署。
Q:DeepSeek-V4的思考模式和非思考模式有什么区别?
A:核心区别在于是否启用深度推理(思维链):
思考模式:自动拆解复杂问题、分步推理、自我校验、多轮反思,推理准确率提升20%-40%,适合数学、代码、科研等复杂任务,响应速度略慢。
非思考模式:关闭深度推理,直接生成结果,响应速度提升30%-50%,适合日常对话、简单问答、文案生成等轻量场景,成本更低。
Q:DeepSeek-V4兼容OpenAI接口吗?迁移成本高吗?
A:完全兼容OpenAI接口,迁移成本几乎为零:
API格式、参数、返回结果与OpenAI完全一致,仅需修改base_url与model_name即可无缝迁移。
支持OpenAI生态工具(如LangChain、LlamaIndex),可直接接入现有工作流,无需修改业务代码。
Q:DeepSeek-V4开源吗?开源协议是什么?
A:完全开源,支持商业与非商业使用:
开源平台:Hugging Face、ModelScope双平台同步开源,提供模型权重、配置文件、技术报告。
开源协议:宽松的Apache 2.0协议,允许自由使用、修改、分发、商用,无需开源衍生作品,降低企业使用门槛。
相关链接
在线体验(网页端):https://chat.deepseek.com
开发者平台(API管理):https://platform.deepseek.com
Hugging Face模型库:https://huggingface.co/collections/deepseek-ai/deepseek-v4
ModelScope模型库:https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
总结
DeepSeek-V4作为深度求索推出的新一代开源混合专家大模型,以百万上下文标配、双模式推理、Agent能力强化、高效低成本、国产算力适配为核心亮点,打破了长文本处理的成本壁垒与性能上限,兼顾开源开放与顶级性能,适配从个人用户到企业级的多元场景。其V4-Pro版本在代码、数学、推理等核心能力上比肩甚至超越Claude Opus、GPT-5.4等闭源旗舰,V4-Flash版本以极致性价比普惠日常使用,原生支持华为昇腾算力更助力国产AI生态自主可控。作为国产大模型的里程碑之作,DeepSeek-V4不仅推动了长文本与智能体技术的普及落地,更为全球AI领域提供了高性能、低成本、开源开放的新选择,为行业发展注入新动力。
相关软件下载

DeepSeek
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/deepseek-v4.html





