Depth Anything 3:字节跳动开源的全场景任意视图3D几何重建模型
一、Depth Anything 3是什么?
Depth Anything 3(简称DA3)是字节跳动Seed团队于2025年11月正式开源的通用3D视觉几何重建模型,核心目标是让机器像人类一样,从“任意视觉输入”中理解并恢复三维空间结构——无论是单张照片、多张不同角度的图像,还是一段视频,甚至无需提前知道相机的位置、朝向(姿态)或焦距参数,都能输出空间一致的深度信息、相机姿态,并支持进一步生成3D点云或可渲染模型。
在DA3出现前,3D视觉领域的主流方案是“一个任务一套模型”:比如单目深度估计用专门的Disparity模型,多视图重建用SfM(运动恢复结构)算法,相机姿态估计又需单独的定位模型。这种“拆分式”设计不仅导致模型架构复杂、训练成本高,还存在“泛化性差”的问题——换个场景(如从室内到户外)就需要重新调参或微调。即便近年有统一模型尝试,也多依赖定制化架构和从零开始的联合训练,无法复用大规模预训练模型(如DINOv2)的特征提取能力。
DA3的核心突破在于“极简统一”:用一个未经特殊改造的Transformer(如DINOv2)作为主干网络,通过“Depth-Ray(深度-射线)”这一极简表示,将所有3D几何任务统一为“密集预测问题”。这种设计既继承了预训练模型的强大能力,又避免了多任务耦合的复杂性,最终实现“单模型覆盖全场景,性能超越专用模型”的效果——所有模型均在公共学术数据集上训练,无私有数据依赖,开源后可直接用于科研与工业场景。
二、Depth Anything 3的功能特色
DA3的功能特色围绕“统一、高效、精准、易用”四大核心,具体可拆解为以下5点:
1. 全场景任务统一覆盖
无需切换模型,仅通过调整输入配置,即可完成6大3D视觉核心任务,解决传统方案“任务割裂”的痛点:
单目深度估计:从单张RGB图像预测像素级深度图(区分物体远近);
多视图深度估计:融合多张不同视角图像,输出空间一致的深度图,用于高质量3D点云生成;
姿态条件深度估计:若提供相机姿态(位置/朝向),可进一步提升深度图的一致性与精度;
相机姿态估计:从1张或多张图像中,直接估计相机的外参(旋转/平移)与内参(焦距/畸变);
3D高斯估计:直接预测3D高斯参数,支持高保真“新视角合成”(如从任意角度渲染场景);
天空分割:部分模型(如DA3METRIC-LARGE、DA3MONO-LARGE)内置天空区域分割能力,避免天空区域对深度估计的干扰。
2. 极简架构设计,兼顾性能与效率
摒弃“模块堆叠”的复杂设计,核心架构仅包含“单Transformer主干+双DPT头”,同时具备两大优势:
无架构特殊化:主干网络直接使用标准DINOv2(视觉Transformer),无需修改底层结构,可直接复用其在海量图像上学习的特征提取能力;
输入自适应:通过“跨视角自注意力机制”动态适配输入视图数量——输入1张图时自动退化为单目模式(无额外计算开销),输入多张图时自动启动跨视图信息融合,无需手动切换模式。
3. SOTA级性能,全面超越前代与同类模型
在字节跳动构建的“Visual Geometry Benchmark”(涵盖ETH3D、ScanNet++、7Scenes等5个主流数据集)上,DA3的性能全面刷新纪录,关键指标如下:
相机姿态精度:DA3-Giant模型平均超越前代SOTA模型VGGT 35.7%(AUC-3/AUC-30指标);
几何重建精度:在所有5个数据集上均取得SOTA,平均提升23.6%;
单目深度性能:优于前作DA2,同时保持DA2在细节捕捉(如物体边缘)与鲁棒性(如复杂光照)上的优势;
推理效率:轻量化模型(DA3-Small)推理速度达160 FPS(帧/秒),基础模型(DA3-Base)达126 FPS,可满足实时场景需求(如机器人导航、视频处理)。
4. 多场景适配性,兼容“有无相机姿态”
真实场景中,相机姿态(如手机拍照时的位置、车载相机的标定参数)往往未知,DA3通过两种设计解决这一问题:
无姿态也能跑:若未提供相机姿态,模型通过“Depth-Ray表示”隐式编码相机运动信息,仍能输出准确的深度与3D结构;
有姿态更精准:若提供姿态,可通过“轻量级相机编码器”将姿态信息以“camera token”形式注入模型,为几何重建提供额外约束,进一步提升精度。
5. 工程化支持完善,开箱即用
为降低使用门槛,DA3提供全套工程化工具,兼顾科研调试与工业部署:
交互式Web UI:基于Gradio构建,可可视化模型输出(深度图、点云)、对比不同模型结果,无需编写代码;
灵活CLI工具:支持批量处理(如文件夹内所有图像)、视频处理(指定FPS提取帧并估计深度)、特征可视化(查看Transformer层输出特征);
多格式导出:结果可导出为glb(3D模型通用格式,支持Blender/Unity导入)、npz(深度数据)、ply(点云)、3DGS视频(新视角合成视频)等,无缝衔接下游工具;
模块化代码:代码库按“模型定义-输入处理-输出导出”拆分,支持自定义模型配置(如替换主干网络、调整输出维度),便于科研扩展。
三、Depth Anything 3的技术细节
DA3的技术核心围绕“极简建模策略”展开,可拆解为三大关键技术模块,下表清晰展示各模块的设计逻辑与优势:
| 技术模块 | 核心设计 | 解决的核心问题 | 技术优势 |
|---|---|---|---|
| Depth-Ray(深度-射线)表示 |
为每张输入图像预测两个密集图: 1. 深度图:像素级距离(物体到相机的距离) 2. 射线图:像素级6维参数(3维原点+3维方向) | 传统模型需单独预测相机姿态(正交约束难满足) |
1. 3D点计算简单:3D坐标=射线原点+深度×射线方向 2. 天然空间一致:所有射线在统一世界坐标系下 3. 任务统一:无需拆分深度与姿态任务 |
| 输入自适应跨视角自注意力 |
将Transformer层分为两组: 1. 前2/3层:单图内特征处理 2. 后1/3层:交替进行跨视图融合与单图处理 | 多视图模型无法适配“任意输入数量”(如1张/10张) |
1. 输入数量自适应:无需手动切换单目/多视图模式 2. 信息融合高效:仅在关键层进行跨视图交互,平衡精度与速度 |
| 教师-学生训练范式 |
1. 教师模型:在大规模高质量合成数据上训练,生成高保真伪标签 2. 学生模型(DA3):用伪标签+真实数据训练 | 真实数据噪声多(如深度相机空洞),合成数据泛化差 |
1. 兼顾精度与泛化:教师提供高质量监督,真实数据提升场景适配性 2. 训练高效:无需从零训练,复用教师模型知识 |
1. Depth-Ray表示:用“最小目标”描述3D空间
传统3D模型需要“深度+相机姿态”两个独立目标,而DA3通过“Depth-Ray表示”将两者统一:
射线图的物理意义:对于图像中的每个像素,可想象“一条从相机中心出发、穿过像素指向物体”的射线——射线的“原点”是相机中心在世界坐标系中的位置,“方向”是从相机中心到像素的单位向量(6维参数即可完整描述);
3D空间恢复逻辑:有了深度图(每个像素的“距离”)和射线图(每个像素的“位置与方向”),只需通过简单向量运算即可得到像素对应的3D坐标:
3D坐标 = 射线原点 + 深度值 × 射线方向;隐式编码相机姿态:射线图的原点与方向隐含了相机的位置(原点)和朝向(方向),无需单独预测相机的旋转矩阵(避免正交约束的技术难题)。若需显式输出相机姿态,DA3还设计了一个“轻量级相机头”——通过处理每个视图的“camera token”,直接输出焦距、旋转(四元数)、平移参数,计算成本可忽略不计。
2. 单Transformer主干:用“通用架构”适配全任务
DA3的主干网络直接采用DINOv2(Meta开源的视觉Transformer,在140M张图像上预训练),仅通过“跨视角自注意力”进行扩展,具体流程如下:
输入编码:将所有输入图像(无论数量多少)转换为图像token(如224×224图像转换为14×14=196个token),同时为每个视图添加1个“camera token”(用于姿态相关任务);
单图特征处理:前2/3的Transformer层仅处理单图内的token,学习图像的局部特征(如边缘、纹理),保留DINOv2的特征提取能力;
跨视图融合:后1/3的Transformer层动态调整token顺序——将不同视图的token按空间位置关联,实现“跨视图信息交互”(如视图A的像素token与视图B的对应像素token交换特征),从而学习视图间的几何关系;
双DPT头预测:最终通过“双分支Dense Prediction Transformer(DPT)头”输出结果——两个分支共享特征重组模块(保证特征对齐),一支输出深度图,另一支输出射线图,实现“深度与射线的联合优化”。
3. 教师-学生训练:用“合成数据”解决真实数据痛点
3D模型训练面临“真实数据质量差、合成数据泛化差”的矛盾,DA3通过“教师-学生范式”解决:
教师模型训练:仅使用大规模高质量合成数据(覆盖室内、户外、物体级等场景)训练教师模型——教师模型架构与DA3一致(DINOv2+DPT头),但直接预测“指数深度”(放大近距离物体的深度差异,解决近距离区分度低的问题),确保输出的深度图无噪声、无空洞;
伪标签生成:用训练好的教师模型,对海量真实世界数据(如ScanNet、ETH3D中的噪声深度数据)生成“高保真伪标签”(深度图+射线图);
学生模型训练:DA3(学生模型)以“伪标签为监督”,同时结合真实数据的图像特征进行训练——既避免了真实数据噪声的干扰,又通过真实数据提升模型在现实场景中的泛化能力,最终实现“合成数据的精度+真实数据的鲁棒性”。

四、Depth Anything 3的应用场景
DA3的“全场景适配性”与“工程化支持”使其可落地于多个领域,以下为5个典型应用场景:
1. 自动驾驶:多相机空间感知
自动驾驶车辆通常搭载多个相机(前视、侧视、后视),但相机间可能无视角重叠(如侧视与后视),传统模型难以融合其深度信息。DA3可直接输入所有相机的图像,输出“空间一致的深度图”,帮助车辆构建统一的3D环境感知(如识别侧后方来车的距离、行人位置),同时估计各相机的相对姿态,减少相机标定的依赖。某新兴车企已将DA3集成至城市道路感知系统,在低功耗嵌入式设备上实现实时深度生成,行人与障碍物距离预判精度提升20%以上。
2. AR/VR与元宇宙:场景快速重建
AR/VR需要“真实场景的3D数字化”作为虚拟内容的载体,传统方案需专用3D扫描设备(如激光雷达),成本高、操作复杂。DA3仅需普通手机拍摄的多张照片,即可快速生成场景的3D点云或3D高斯模型——用户用手机绕房间拍10-20张照片,输入DA3后可输出glb格式的3D模型,直接导入AR/VR引擎(如Unity),大幅降低沉浸式体验的硬件门槛。上海某元宇宙公司已用DA3实现“手机拍场景,即时生成VR环境”,场景重建时间从数小时缩短至几分钟。
3. 机器人导航与SLAM
机器人在未知环境中导航需实时“定位(自身位置)+建图(环境结构)”(即SLAM),传统SLAM依赖特征匹配(如ORB-SLAM),在纹理少的场景(如白墙)易失效。DA3可作为SLAM的“深度与姿态估计模块”:机器人搭载单目或双目相机,DA3实时输出深度图与相机姿态,帮助机器人理解环境障碍(如桌子高度、门框宽度),同时减少定位漂移。实验表明,用DA3替换VGGT-Long中的姿态估计模块后,大规模环境下的定位漂移降低30%以上,效果优于需要48小时预处理的COLMAP(传统SLAM工具)。
4. 医疗辅助诊断:内窥镜深度推断
内窥镜手术中,医生需通过2D影像判断病灶的空间位置(如肿瘤与血管的距离),但2D影像缺乏深度信息,易导致误判。研究人员正将DA3应用于内窥镜影像处理:输入内窥镜拍摄的2D视频帧,DA3输出像素级深度图,帮助医生直观看到“病灶与周围组织的距离”,辅助制定手术方案。目前在胃肠镜临床测试中,DA3的深度估计误差已控制在1mm以内,具备临床辅助价值。
5. 工业数字化:老旧零件扫描
传统工业零件数字化(如老旧机床零件)需专用3D扫描仪,且零件需固定在特定位置(确保视角重叠),操作繁琐。DA3可简化这一流程:工作人员用普通相机从任意角度拍摄零件(无需保证视角重叠),输入DA3后即可生成零件的3D点云,后续仅需轻微手动修复(如小孔洞)即可用于零件复刻或数字存档。某汽车零部件厂商测试表明,用DA3处理老旧发动机零件,数字化时间从1天缩短至1小时,精度满足后续3D打印需求。
五、Depth Anything 3的使用方法
DA3提供“Python API”与“CLI工具”两种使用方式,支持Windows/Linux/macOS(需CUDA支持以保证推理速度),以下为详细步骤:
1. 环境准备与安装
1.1 基础依赖安装
首先确保Python版本≥3.10,CUDA版本≥11.7(推荐12.0),然后执行以下命令安装核心依赖:
# 安装PyTorch与xformers(用于Transformer加速) pip install xformers torch>=2.0 torchvision # 克隆仓库并安装基础包 git clone https://github.com/ByteDance-Seed/depth-anything-3.git cd depth-anything-3 pip install -e . # 基础安装(支持模型推理)
1.2 可选依赖安装
根据需求安装额外依赖(如3D高斯生成、Web UI):
# 安装3D高斯头(用于3D高斯估计与新视角合成) pip install --no-build-isolation git+https://github.com/nerfstudio-project/gsplat.git@0b4dddf04cb687367602c01196913cde6a743d70 # 安装Web UI依赖(用于交互式可视化) pip install -e ".[app]" # 需Python≥3.10 # 安装全部依赖(含上述所有功能) pip install -e ".[all]"
1.3 模型下载
DA3的预训练模型托管在Hugging Face Hub,无需手动下载——代码会自动从Hugging Face拉取模型。若遇到网络问题,可设置HF镜像:
export HF_ENDPOINT=https://hf-mirror.com # 临时设置镜像(Linux/macOS) # Windows命令:set HF_ENDPOINT=https://hf-mirror.com
2. 基础使用示例
2.1 Python API:单/多视图深度与姿态估计
以下代码演示如何用API加载模型,输入图像并获取深度、姿态等结果:
import glob
import os
import torch
from depth_anything_3.api import DepthAnything3
# 1. 初始化设备(推荐GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 加载预训练模型(以嵌套模型为例,支持metric深度)
# 可选模型:depth-anything/DA3NESTED-GIANT-LARGE、depth-anything/DA3-LARGE等
model = DepthAnything3.from_pretrained("depth-anything/DA3NESTED-GIANT-LARGE")
model = model.to(device=device)
# 3. 准备输入图像(支持单张或多张,此处以文件夹内所有PNG为例)
example_path = "assets/examples/SOH" # 仓库自带示例图像路径
images = sorted(glob.glob(os.path.join(example_path, "*.png"))) # 按文件名排序
# 4. 模型推理(无相机姿态输入,自动估计)
prediction = model.inference(
images, # 输入图像列表
# 可选参数:intrinsics=None(相机内参,未知则自动估计)、conf_thr=0.5(置信度阈值)
)
# 5. 查看输出结果(关键输出解析)
print("处理后图像形状(N:图像数量,H:高度,W:宽度,3:RGB):", prediction.processed_images.shape)
print("深度图形状(N,H,W):", prediction.depth.shape) # 单位:米(嵌套模型)
print("置信度图形状(N,H,W):", prediction.conf.shape) # 每个像素的深度置信度
print("相机外参形状(N,3,4):", prediction.extrinsics.shape) # 3×4旋转平移矩阵(OpenCV格式)
print("相机内参形状(N,3,3):", prediction.intrinsics.shape) # 3×3内参矩阵(焦距、主点)
# 6. 导出结果(以glb格式为例,支持3D模型查看)
prediction.export(
export_dir="output/soh_3d", # 导出目录
export_format="glb", # 导出格式:glb/npz/ply/3dgs_video等
save_depth=True # 是否同时保存深度图(PNG格式)
)2.2 CLI工具:批量处理与视频处理
DA3的CLI工具支持批量处理图像文件夹、视频文件,以下为常用命令示例:
示例1:批量处理图像并导出3D模型
# 定义模型目录与输出目录 export MODEL_DIR=depth-anything/DA3NESTED-GIANT-LARGE export OUTPUT_DIR=output/batch_process # 创建输出目录 mkdir -p $OUTPUT_DIR # 批量处理图像文件夹,导出glb格式3D模型 da3 auto assets/examples/SOH \ --model-dir $MODEL_DIR \ --export-dir $OUTPUT_DIR \ --export-format glb \ --save-conf # 同时保存置信度图
示例2:处理视频并生成深度可视化视频
# 处理视频(15 FPS),导出深度可视化视频与glb模型 da3 video assets/examples/robot_unitree.mp4 \ --model-dir $MODEL_DIR \ --export-dir output/video_depth \ --fps 15 \ # 提取视频帧的FPS --export-format glb-feat_vis \ # 导出glb+特征可视化视频 --feat-vis-fps 15 \ # 特征可视化视频的FPS --process-res-method lower_bound_resize \ # 分辨率调整方式 --export-feat "11,21,31" # 可视化Transformer的第11、21、31层特征
示例3:启动Web UI交互式可视化
# 启动Gradio Web UI,支持上传图像、实时查看结果 da3 app \ --model-dir $MODEL_DIR \ --port 7860 # Web UI端口
启动后,打开浏览器访问http://localhost:7860即可使用交互式界面。
3. 模型自定义配置
若需修改模型架构(如替换主干网络、调整输出维度),可通过YAML配置文件实现。以下为自定义配置文件示例(configs/custom_da3.yaml):
__object__: path: depth_anything_3.model.da3 name: DepthAnything3Net args: net: __object__: path: depth_anything_3.model.dinov2.dinov2 name: DinoV2 args: name: vitl # 替换主干为DINOv2-Large(原默认vitb) out_layers: [6, 8, 10, 12] # 输出特征的Transformer层 alt_start: 4 qknorm_start: 4 rope_start: 4 cat_token: True head: __object__: path: depth_anything_3.model.dualdpt name: DualDPT args: dim_in: 1024 # 输入特征维度(vitl为1024,vitb为768) output_dim: 2 features: 128 out_channels: [96, 192, 384, 768]
然后通过以下代码加载自定义模型:
from depth_anything_3.cfg import create_object, load_config
# 加载自定义配置
config = load_config("configs/custom_da3.yaml")
# 创建模型
custom_model = create_object(config)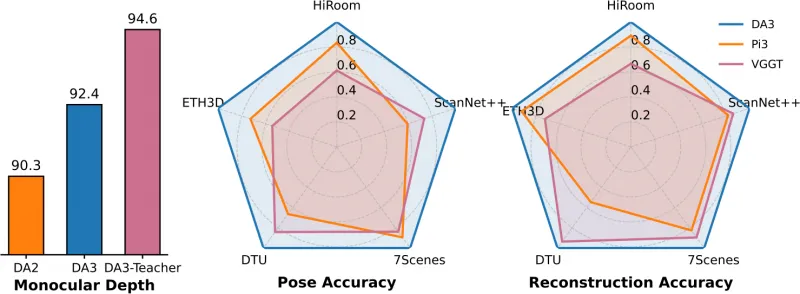
六、常见问题解答(FAQ)
1. 如何从DA3获取“metric深度”(真实世界单位,如米)?
若使用DA3METRIC-LARGE模型(单目metric深度专用模型),需通过焦距计算:
metric_depth = focal * net_output / 300.,其中focal为相机内参矩阵K中fx与fy的平均值(可从prediction.intrinsics获取);若使用DA3NESTED系列模型(如DA3NESTED-GIANT-LARGE),模型输出的
prediction.depth已直接是米单位,无需额外计算。
2. 旧GPU(如GTX 1060)不支持XFormers,如何解决?
XFormers是用于Transformer推理加速的库,若GPU不支持(如算力<7.0),可按以下步骤禁用XFormers:
卸载已安装的xformers:
pip uninstall xformers -y;修改模型加载代码,添加
use_xformers=False:model = DepthAnything3.from_pretrained( "depth-anything/DA3-LARGE", use_xformers=False # 禁用XFormers )
更多细节可参考GitHub仓库的Issue #11(https://github.com/ByteDance-Seed/depth-anything-3/issues/11)。
3. DA3支持哪些输出格式?各格式适合什么场景?
| 输出格式 | 用途 | 支持工具/软件 |
|---|---|---|
| glb | 3D模型通用格式,支持几何与纹理 | Blender、Unity、MeshLab、浏览器(Three.js) |
| npz | 存储深度图、置信度图、内外参的压缩格式 | Python(numpy.load读取) |
| ply | 点云格式,支持稠密点云存储 | CloudCompare、MeshLab |
| 3dgs_video | 3D高斯新视角合成视频 | 普通视频播放器(如VLC) |
| depth_image | 深度图可视化PNG(近黑远白) | 任意图像查看器 |
4. 不同模型系列如何选择?
根据具体任务需求选择,核心区别如下:
DA3 Main系列(DA3-Giant/Large/Base/Small):适合多任务场景(如同时需要多视图深度+姿态估计),Giant版性能最强,Small版速度最快;
DA3 Metric系列(DA3METRIC-LARGE):仅用于单目场景,需获取真实世界尺度(米)的深度,如医疗、工业测量;
DA3 Monocular系列(DA3MONO-LARGE):仅用于单目相对深度估计(无需真实尺度),如AR贴纸定位、图像景深增强;
DA3 Nested系列(DA3NESTED-GIANT-LARGE):适合需要“多任务+metric深度”的场景(如自动驾驶、3D重建),集成了Main系列与Metric系列的能力。
5. 模型推理需要多少显存?
不同模型的显存需求如下(推理单张1024×1024图像):
DA3-Small:约2GB;
DA3-Base/Large:约4-6GB;
DA3-Giant/DA3NESTED-GIANT-LARGE:约8-10GB。 若显存不足,可通过
--process-res-method lower_bound_resize降低输入图像分辨率(如 resize 到512×512)。
七、相关链接
| 链接类型 | 地址 | 说明 |
|---|---|---|
| GitHub仓库 | https://github.com/ByteDance-Seed/depth-anything-3 | 官方代码库、安装指南、使用示例 |
| 项目主页 | https://depth-anything-3.github.io/ | 论文可视化结果、demo视频、模型介绍 |
| Hugging Face模型库 | https://huggingface.co/depth-anything | 预训练模型下载(支持自动拉取) |
| arXiv论文 | https://arxiv.org/abs/2511.10647 | 官方论文(详细技术细节与实验结果) |
| 社区项目集合 | https://github.com/ByteDance-Seed/depth-anything-3#awesome-da3-projects | 基于DA3的第三方项目(Blender插件、ROS2封装等) |
八、总结
Depth Anything 3(DA3)是字节跳动Seed团队开源的3D视觉领域里程碑项目,以“极简架构实现全场景3D几何重建”为核心目标,通过“单Transformer主干+Depth-Ray统一表示”的设计,摒弃传统多任务模型的复杂模块堆叠,统一覆盖单目深度估计、多视图融合、相机姿态估计、3D高斯生成等6大核心任务。在性能上,DA3相机姿态精度平均超越前代SOTA模型VGGT 35.7%,几何重建精度提升23.6%,同时单目深度估计效果优于前作DA2,且轻量化模型推理速度可达160 FPS,兼顾精度与效率。工程化方面,DA3提供Web UI、CLI工具、多格式导出等完善支持,降低使用门槛,可广泛应用于自动驾驶、AR/VR、机器人导航、医疗辅助、工业数字化等领域。作为开源项目,DA3不仅为3D视觉研究提供了“极简建模”的新范式,也为工业场景提供了开箱即用的3D空间感知解决方案,其无私有数据依赖、模块化可扩展的特性,进一步推动了3D视觉技术的普及与落地。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/depth-anything-3.html





