EvoQuality:字节跳动开源的无参考图像质量评估模型,零标注实现 IQA 性能突破
一、EvoQuality 是什么
EvoQuality 是字节跳动与香港城市大学联合推出的自进化视觉语言模型框架,专注于无参考图像质量评估(No-Reference Image Quality Assessment,NR-IQA)。
所谓“无参考”,是指模型在评估一张图像的质量时,不需要对应的“完美图像”作为参照,仅凭图像本身即可判断其视觉质量——这与人类的主观感知方式高度一致。
EvoQuality 的核心突破在于:它完全无需人工标注的质量分数或失真标签,仅通过模型自身的成对比较与多数投票生成伪排名标签,再借助 GRPO 强化学习算法实现多轮迭代自进化。
传统的视觉语言模型后训练方法通常依赖于监督微调或强化学习,这两种方法都离不开大量昂贵的人工标注数据。而 EvoQuality 将自一致性(self-consistency)的原理创造性地应用到图像质量评估的排名特性上,开辟了一条完全自监督的技术路线。
通俗理解:EvoQuality 就像一位不需要老师评分的“自学者”——它让模型反复比较两张图像的相对质量,对多次比较结果进行“多数投票”形成共识,再用这个共识反过来优化自己,形成一个“越学越强”的正反馈闭环。
二、功能特色
✨ 核心功能一览
单图质量评分:对单张图像输出 0–100 的连续质量分数,支持多种失真类型,包括合成失真、真实失真及 AI 生成失真。
图像对质量对比:通过成对比较判断两张图像的相对质量优劣,并生成可解释的质量描述文本,让评估结果不仅“准”而且“看得懂”。
自进化迭代训练:在离线阶段通过多数投票生成高置信度伪标签,在线阶段通过 GRPO 优化策略,形成闭环自我提升。
零样本跨域评估:无需针对新数据集重新训练或对齐感知尺度,天然支持跨数据集的零样本评估。
⭐ 核心优势
零标注成本:完全无需人工主观评分或失真标签,仅通过模型自身成对比较与多数投票即可生成训练信号。
性能超越监督模型:在 7 个 IQA 基准中的 5 个上超越当前最先进的监督 VLM-based IQA 方法,零样本 PLCC 平均提升 31.8%。
自进化闭环能力:通过多轮迭代形成“生成伪标签→训练模型→模型更强→生成更好标签”的正反馈循环,持续突破性能上限。
跨数据集强泛化:天然支持零样本跨域评估,无需针对新数据集重新对齐感知尺度或重新训练。

三、技术细节
🔧 技术架构
EvoQuality 构建于 Qwen2.5-VL-7B 视觉语言模型之上,其核心技术创新体现在以下三个层面:
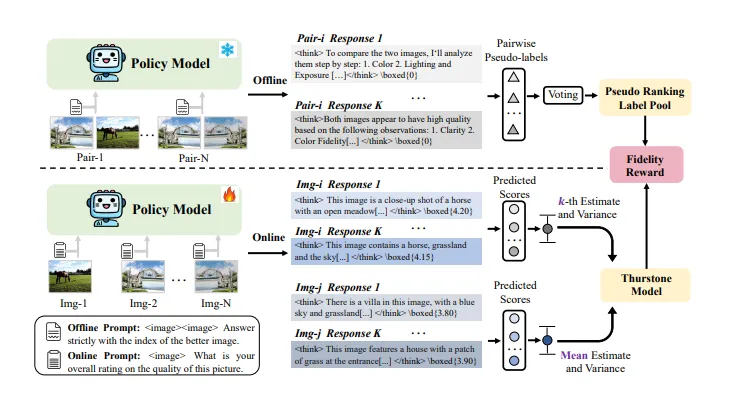
1. 离线伪标签生成
对未标注的图像对进行多次查询,让当前 VLM 反复判断“哪张图像质量更好”。
通过成对多数投票(Pairwise Majority Voting) 建立相对质量共识,生成伪排名标签,完全替代人工 MOS(Mean Opinion Score)标注。
用 Thurstone Case V 心理测量模型将离散比较结果转化为连续的质量分数分布,生成可优化的保真度奖励信号。
2. 在线策略进化
采用 GRPO(Group Relative Policy Optimization) 算法将伪标签转化为奖励信号,更新 VLM 策略。
通过组内样本的相对奖励估计优势函数,大幅降低训练内存与计算开销。
策略模型针对同一批图像对生成多个回答,根据伪标签计算的奖励进行梯度更新。
3. 迭代进化机制
多轮迭代形成正反馈闭环: 模型能力提升 → 生成更高质量伪标签 → 模型进一步进化 → 重复循环
实验表明,经过多轮自进化后,零样本 PLCC(Pearson Linear Correlation Coefficient)平均提升 **31.8%**。更值得注意的是,尽管完全自监督,EvoQuality 在 7 个主流 IQA 基准测试中的 5 个上超越了现有的监督式 VLM-based IQA 模型。
四、应用场景
EvoQuality 在以下场景中具有广泛的应用价值:
1. AI 生成内容质量审核
AI 生图模型(如 Stable Diffusion、Midjourney、DALL·E 等)生成的海量图像需要自动化的质量把关。EvoQuality 能够对 AIGC 生成的图像进行批量质量评估,筛选出低质量图像,提升内容审核效率。
2. 图像压缩与转码质量评估
在图像压缩、格式转换、分辨率调整等处理流程中,EvoQuality 可作为后处理的质量检测工具,自动评估处理前后图像的视觉质量变化,辅助优化算法选择。
3. 用户生成内容质量排序
社交平台、电商平台等需要处理海量用户上传的图片内容。EvoQuality 可对用户生成内容进行质量排序,优先展示高质量图片,提升用户体验。
4. 数据清洗与数据集构建
在构建大规模图像数据集时,EvoQuality 可自动筛选低质量图片、模糊图片或存在明显失真的图片,提升数据集的整体质量水平。
5. 图像质量监测
在视频流媒体、安防监控等需要实时监测图像质量的场景中,EvoQuality 可作为质量监测模块,及时发现异常画面(如黑屏、花屏、过度模糊等)。
五、使用方法
🛠️ 环境准备
Python 3.8+
PyTorch(建议 2.0 以上版本)
Transformers 库(Hugging Face)
GPU 环境(推荐,可显著加速推理)
📦 安装依赖
pip install torch transformers accelerate pillow
🤗 模型加载
通过 Hugging Face transformers 库加载模型权重和处理器:
from transformers import AutoModelForCausalLM, AutoProcessor from PIL import Image import torch # 加载模型和处理器 model_name = "ByteDance/EvoQuality" processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( model_name, device_map="auto", torch_dtype=torch.bfloat16 )
🖼️ 单图质量评分
# 读取待评估图像
image = Image.open("your_image_path.jpg")
# 构造提示词
prompt = "Please rate the quality of this image from 0 to 100."
# 处理输入并生成输出
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(output[0], skip_special_tokens=True)
print(response) # 输出连续质量分数及质量缺陷/优势描述文本
模型输出示例格式:"The quality score of this image is 85. The image shows good clarity and natural colors, but there is slight noise in the shadow areas."
↔️ 图像对质量对比
# 准备两张待对比图像
image_a = Image.open("image_a.jpg")
image_b = Image.open("image_b.jpg")
# 构造对比提示词
prompt = "Which image has better quality? Explain why."
# 将两张图像组合输入
inputs = processor(
text=prompt,
images=[image_a, image_b],
return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(output[0], skip_special_tokens=True)
print(response) # 输出质量对比结果及理由📊 批量评估
def batch_evaluate(image_list, prompt):
for img_path in image_list:
image = Image.open(img_path)
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(output[0], skip_special_tokens=True)
print(f"{img_path}: {response}")🔄 自进化训练(进阶)
如需在自定义数据集上进一步提升模型性能,可通过生成的伪标签,利用 GRPO 算法对模型进行微调,启动新一轮迭代进化持续提升评估精度。
六、竞品对比
| 维度 | EvoQuality | VisualQuality-R1 | LIQE (Language-Image Quality Evaluator) |
|---|---|---|---|
| 开发方 | 字节跳动 + 香港城市大学 | 学术研究(推理型) | 学术研究 |
| 监督方式 | 完全自监督,零人工标注 | 需人工 MOS 标注作为 ground truth | 有监督(需质量评分标签) |
| 核心算法 | GRPO + 成对多数投票伪标签 + 多轮自进化 | GRPO + Thurstone 模型 + 连续保真度奖励 | CLIP 多任务学习(场景分类+质量评估) |
| 奖励来源 | 模型自身生成的伪排名标签(无需外部标注) | 基于人工 MOS 计算的连续 fidelity measure | 人工标注的 MOS |
| 模型基础 | Qwen2.5-VL-7B | 大模型 | CLIP |
| 可解释性 | 支持生成结构化质量描述文本 | 生成质量描述 | 提供质量分数 |
| 零样本能力 | ✅ 强(PLCC 提升 31.8%) | ✅ 有 | ⚠️ 一般 |
从对比中可以清晰地看到,EvoQuality 的核心差异化优势在于其完全自监督的训练范式。传统有监督模型(如 VisualQuality-R1 和 LIQE)都依赖昂贵的人工标注数据,而 EvoQuality 通过模型自身的成对比较与多数投票生成训练信号,大幅降低了数据成本。同时,在性能表现上,EvoQuality 在 5 个主流 IQA 基准上超越了现有监督 SOTA 模型,实现了“更省力且更出色”的技术突破。
七、常见问题解答
Q:EvoQuality 适合哪些类型的图像?
A:EvoQuality 支持多种失真类型的图像评估,包括合成失真(如压缩噪声、模糊)、真实失真(拍摄过程中的自然退化)、以及 AI 生成图像(如 Stable Diffusion、Midjourney 输出的图片)。无论是自然照片、CG 渲染图还是 AIGC 作品,EvoQuality 都能进行有效的质量评估。
Q:模型是否开箱即用?需要多少显存?
A:是的,模型可直接通过 Hugging Face Transformers 库加载使用,无需额外配置。EvoQuality 基于 Qwen2.5-VL-7B 构建,建议使用至少 16GB 显存的 GPU(如 A10、V100、RTX 4090 等)以获得良好的推理速度。
Q:EvoQuality 能否用于商业项目?
A:开源许可详情请以 Hugging Face 页面发布的具体授权协议为准。模型权重目前已公开提供,可用于研究和应用开发。
Q:零样本评估的准确性如何?用户场景是否需要重新训练?
A:实验表明,EvoQuality 在完全零样本的情况下,在 7 个主流 IQA 基准测试中的 5 个上超越了现有的监督 SOTA 模型,零样本 PLCC 平均提升 31.8%。对于大多数通用场景,开箱即用已足够。如遇特定领域图像(如医疗影像、遥感图像等),可通过自进化训练进一步微调。
Q:什么是 PLCC?31.8% 的提升意味着什么?
A:PLCC(Pearson Linear Correlation Coefficient,皮尔逊线性相关系数)是衡量模型预测质量分数与人类主观评分之间线性一致性的指标,取值范围 0–1,越接近 1 表示模型与人类感知越吻合。31.8% 的相对提升意味着 EvoQuality 的评估结果与人类主观感知的契合度显著高于基础模型。
Q:模型能同时评估几张图像?
A:EvoQuality 支持单图质量评分和图像对质量对比两种模式。在对比模式下可同时处理两张图像;批量评估场景下,可逐张输入或多进程并行处理。
Q:评估结果输出格式是什么?
A:输出包含两部分:连续质量分数(0–100)以及结构化的质量描述文本,包括质量优势和缺陷说明,便于人工审核或后续自动化处理。
Q:EvoQuality 与传统的 IQA 方法(如 NIQE、BRISQUE)有什么区别?
A:传统方法(如 NIQE)通常依赖自然场景统计特征,无需训练但性能有限,且与人眼主观感知的相关性不如深度学习模型。而 EvoQuality 基于视觉语言大模型,具有更强的语义理解能力和可解释性,能够生成质量描述文本,零样本评估性能显著优于传统无监督方法。
Q:代码和模型在哪里下载?
A:代码和模型权重将在 GitHub 仓库 https://github.com/bytedance/EvoQuality 发布,Hugging Face 模型页面为 https://huggingface.co/ByteDance/EvoQuality,技术论文可在 arXiv 获取。
Q:EvoQuality 是否支持中文?
A:模型基于 Qwen2.5-VL(通义千问视觉语言模型)构建,原生支持中英文双语。用户可使用中文提示词进行评估,如“请为这张图像的质量评分,范围0到100”。
八、相关链接
Hugging Face 模型库:https://huggingface.co/ByteDance/EvoQuality
arXiv 技术论文:https://arxiv.org/pdf/2509.25787
九、总结
EvoQuality 是字节跳动与香港城市大学联合推出的自进化视觉语言模型框架,在完全无需人工标注的情况下,通过成对多数投票生成伪排名标签、借助 GRPO 强化学习算法实现多轮迭代自进化,将基础 VLM 的零样本性能平均提升了 31.8%,并在 7 个主流 IQA 基准测试中的 5 个上超越了现有监督 SOTA 模型——这是图像质量评估领域从“依赖人工标注”迈向“机器自主进化”的一次重要技术突破。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/evoquality.html





