FlowAct-R1:字节跳动推出的开源实时交互式数字人视频生成框架
一、FlowAct-R1 是什么?
FlowAct-R1 是由字节跳动智能创作团队推出的开源实时交互式数字人视频生成框架,核心定位是“让数字人实现真正意义上的实时交互”——仅需一张人物参考图像,结合音频或文本指令,就能生成无限时长、动作自然、响应迅速的数字人视频,打破传统视频生成“录播式”的局限,实现“直播式”的流式输出。
简单来说,FlowAct-R1 解决了当前数字人视频生成领域的“不可能三角”:传统方法要么能生成高质量视频但延迟极高(无法交互),要么能实时输出但画质差、动作僵硬,要么支持长时长生成但会出现数字人“走形”。而 FlowAct-R1 首次实现了“流式无限时长+实时低延迟+高逼真度”三者的统一,让数字人能像真人一样自然地“说话、倾听、思考、反应”,为交互式数字人应用提供了核心技术支撑。
从技术归属来看,FlowAct-R1 属于扩散模型在视频生成领域的进阶应用,基于多模态扩散Transformer(MMDiT)架构改造,通过训练与推理双阶段的深度优化,适配实时交互场景的核心需求。其开源特性意味着开发者可自由获取代码、二次开发,大幅降低交互式数字人视频生成技术的应用门槛。

二、核心功能特色
FlowAct-R1 的功能特色围绕“交互式”核心展开,每一项功能都直指行业痛点,兼顾技术先进性与落地实用性:
1. 流式无限时长生成,打破时长枷锁
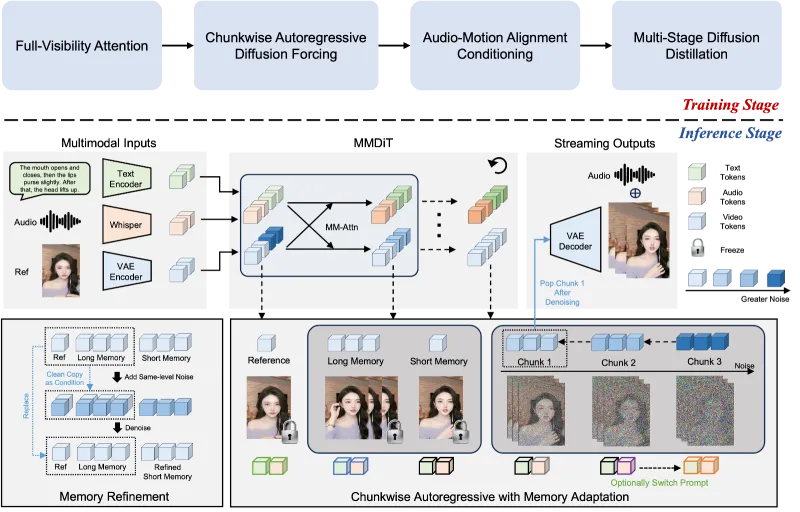
传统数字人视频生成工具多为“一次性生成固定时长视频”,如同“一次性写完一篇作文”,无法满足直播、长时间对话等交互场景需求。FlowAct-R1 采用“分块扩散强制策略”,将无限长视频拆分为0.5秒/块的独立单元(每块含13帧,适配25FPS),如同“流水线生产汽车”——无需等待所有内容准备完毕,每完成一个视频块就即时输出,理论上可实现无限时长数字人视频生成。
更关键的是,其通过“结构化记忆库”保证长时一致性:参考潜变量锚定数字人身份(避免“换脸”),长期记忆队列存储早期视频块(避免动作矛盾),短期记忆潜变量记录最新动作(保证局部流畅),彻底解决了“长时间生成数字人走形、动作断裂”的问题。
2. 实时低延迟响应,适配交互场景
交互式场景的核心需求是“低延迟”——用户发出指令后,数字人需快速响应,否则会破坏沉浸感。FlowAct-R1 通过“模型级蒸馏+系统级优化”双管齐下,实现了行业领先的实时性能:在480p分辨率下,稳定输出帧率达25FPS(人眼感知流畅的临界值),首帧生成时间(TTFF)仅约1.5秒,后续每0.5秒就输出一个视频块,完全满足直播、视频会议等实时交互场景的延迟要求。
对比传统方案(首帧延迟通常5秒以上,帧率不足10FPS),FlowAct-R1 实现了质的飞跃,让“数字人实时对话”从概念走向现实。
3. 高逼真度+强泛化,兼顾质感与适配性
(1)行为逼真度拉满
FlowAct-R1 支持数字人自然切换“说话、倾听、思考、空闲、手势”等多种行为状态,能精准捕捉唇形同步(Lip-Sync)、表情过渡、肢体联动等细微动作——比如说话时嘴角的弧度、倾听时的头部微侧、思考时的眼神游离,都与真人行为高度一致,彻底摆脱“提线木偶”式的僵硬感。
(2)泛化能力突出
无需为每个数字人角色单独训练模型,仅需一张参考图像,就能生成不同风格(写实、卡通、动漫)数字人的视频;同时支持多模态控制,无论是输入音频(让数字人对口型说话)还是文本指令(让数字人做特定动作),都能精准响应,适配不同场景的个性化需求。
4. 全流程可控,降低使用门槛
FlowAct-R1 提供细粒度的控制能力:支持调整视频分辨率(最高适配1080p)、帧率、动作强度等参数;内置多种预设动作模板(如“微笑说话”“挥手问候”“点头倾听”),新手开发者无需复杂调试就能快速生成符合需求的数字人视频;同时支持自定义动作指令,满足专业场景的深度定制需求。
三、技术细节:读懂FlowAct-R1的核心架构
FlowAct-R1 的技术突破源于“从底层重构视频生成逻辑”,其核心架构分为训练与推理双阶段,配合三大关键技术,实现“流式、实时、逼真”的核心目标。
1. 整体架构:训练与推理双阶段设计
FlowAct-R1 的架构设计围绕“适配流式交互”展开,训练阶段为推理阶段打基础,推理阶段通过优化实现实时输出,两者协同保障效果与性能。具体分工如下表所示:
| 阶段 | 核心目标 | 关键任务与技术细节 |
|---|---|---|
| 训练阶段 | 让模型具备“流式生成能力”与“抗误差能力” |
1. 分块自回归适应:将基础MMDiT模型改造为流式自回归模型,适配分块生成逻辑; 2. 音频-动作对齐训练:联合训练音频特征与动作特征,提升唇同步与肢体协调性; 3. Self-Forcing++策略:通过“加噪-去噪-混合训练”,让模型适应推理时的“生成帧输入”,避免误差累积; 4. 多阶段蒸馏:通过模型蒸馏压缩参数规模,在保证效果的同时提升推理速度(最终优化至3 NFEs,大幅降低计算成本)。 |
| 推理阶段 | 实现低延迟、无限时长、高连贯度输出 |
1. 结构化记忆库调度:动态管理参考潜变量、长期记忆、短期记忆、去噪流队列,保证块间连贯; 2. 流式缓冲区机制:每0.5秒循环一次,并行处理“生成-输出”,实现25FPS稳定输出; 3. 系统级优化:优化底层算力调度,减少数据传输延迟,进一步压缩首帧生成时间。 |
2. 三大关键技术:拆解核心突破点
(1)流式缓冲区:数字人视频生成的“智能流水线”
这是 FlowAct-R1 实现“流式输出”的核心,如同汽车生产流水线——无需等待所有零件就绪,每个工位各司其职,上游完成的半成品即时传递给下游,实现“边生产边输出”。其核心结构分为四个组件,分工明确:
| 组件 | 存储内容 | 核心作用 | 通俗比喻 |
|---|---|---|---|
| 参考潜变量 | 1张人物参考图像的特征编码 | 锚定数字人身份,确保全程“不换脸、不变形” | 身份证照片 |
| 长期记忆队列 | 最多3个早期生成的视频块特征 | 记住历史动作状态,避免长时生成的动作矛盾 | 电视剧“上一集回顾” |
| 短期记忆潜变量 | 最新生成的1个视频块特征 | 保证相邻块的动作平滑过渡,避免画面跳帧 | 写字时看刚写的几个字 |
| 去噪流队列 | 正在生成的3个视频块(共9帧) | 并行处理生成任务,提升输出效率 | 画家正在创作的画布 |
其工作流程可概括为“0.5秒循环”:t=0秒启动生成,t=1.5秒完成前3个块的预热(首帧输出),之后每0.5秒完成1个块的生成并即时输出,最终实现25FPS的流式输出效果。
(2)Self-Forcing++:解决“越生成越崩”的关键
传统自回归生成模型存在“训练与推理两张皮”的问题:训练时用“真实帧”作为输入,推理时用“生成帧”作为输入,误差会不断累积,导致长时间生成后数字人“走形”——如同学生平时只做标准题,考试遇到变式题就束手无策。
FlowAct-R1 提出的 Self-Forcing++ 策略,核心是“训练时就让模型适应不完美输入”,具体流程如下:
加噪:用中间模型对真实视频帧添加可控噪声,得到“带噪视频”;
去噪:对带噪视频进行去噪处理,得到“伪生成帧”(质量略低于真实帧,但接近推理时的生成帧);
混合训练:随机将“真实帧”与“伪生成帧”混合作为训练输入,让模型提前适应“有误差的输入”。
与原始 Self-Forcing 策略相比,Self-Forcing++ 大幅降低了计算成本(无需完整展开自回归),且训练稳定性更强,从根源上解决了“长时生成一致性崩塌”的问题。
(3)多阶段蒸馏:平衡效果与速度的“魔法”
扩散模型的通病是“生成质量高但速度慢”,FlowAct-R1 通过“多阶段蒸馏”技术,在不损失核心效果的前提下压缩模型规模、提升推理速度:
第一阶段:用大模型(高效果但慢)生成高质量数字人视频样本;
第二阶段:用小模型学习大模型的生成逻辑,同时优化网络结构,减少冗余参数;
第三阶段:针对“流式生成”场景微调小模型,重点优化块间过渡与实时响应速度。
最终,模型被压缩至仅需3个去噪步骤(NFEs=3)就能生成高质量数字人视频,为实时输出奠定了基础。
3. 多模态控制逻辑:精准响应指令
FlowAct-R1 支持音频、文本两种核心控制方式,其底层逻辑是“多模态特征对齐”:
音频控制:将音频信号转换为梅尔频谱特征,与数字人动作特征(尤其是唇形、面部表情特征)进行联合训练,确保唇形与发音精准同步;
文本控制:将文本指令转换为语义特征,映射为对应的动作序列(如“挥手”对应手臂抬起-摆动-放下的序列),同时结合参考图像的姿态特征,生成自然的全身动作。
两种控制方式可无缝切换,比如直播场景中,既能让数字人实时响应主播的音频(对口型),也能通过文本指令触发预设手势,提升交互丰富度。
四、应用场景:从技术到落地的全场景覆盖
FlowAct-R1 凭借“实时交互、无限时长、高逼真”的核心优势,已在多个领域具备明确的落地价值,无论是To B还是To C场景,都能发挥核心作用:
1. 直播领域:虚拟主播/数字人陪伴
核心应用:无需真人出镜,仅需一张数字人参考图,结合主播的音频(或文本脚本),就能生成无限时长的直播视频——数字人可自然说话、做手势、回应弹幕(通过文本指令触发);
优势:降低直播门槛(无需化妆、布景),支持24小时不间断直播(避免真人疲劳),可定制多种风格的数字人(卡通、写实、二次元),适配游戏、电商、知识分享等不同直播品类。
2. 视频会议/远程沟通:数字人参会人/交互代理
核心应用:在远程会议中,可生成“数字人参会人”替代真人出镜(如发言人无法实时参会时),通过音频同步实现唇形同步,通过文本指令控制数字人的坐姿、表情;也可作为“交互代理”,实时响应参会人的提问(结合NLP技术解析问题,生成对应的语音与动作);
优势:提升远程沟通的沉浸感,避免“黑屏发言”的尴尬,支持多语言实时转换(配合翻译工具,数字人可用不同语言发言并同步唇形)。
3. 在线教育:数字人讲师/互动助教
核心应用:生成数字人讲师视频,结合课程脚本实现“讲解+手势+表情”的自然教学;也可作为互动助教,实时响应学生的问题(如解析题目时,数字人用手势指向关键步骤);
优势:降低课程制作成本(无需反复拍摄真人讲师),支持个性化定制(如根据学科特点定制数字人风格:理科用严谨的“科研人员”形象,文科用亲和的“教师”形象)。
4. 娱乐/内容创作:短视频生成/虚拟偶像
核心应用:普通用户可通过“一张照片+一段音频”生成个性化数字人短视频(如让数字版自己唱一首歌);内容创作者可快速制作虚拟偶像的舞蹈、唱歌视频,支持无限时长输出;
优势:降低内容创作门槛,无需专业建模、动画技术,普通人也能制作高质量数字人内容。
5. 企业服务:数字人客服/数字员工
核心应用:生成数字人客服视频,实时响应客户的咨询(结合客服话术库,数字人用自然语言回答并同步表情、动作);也可作为数字员工,负责企业内部的流程讲解、培训等工作;
优势:提升客户体验(相比文字/语音客服,视频客服更具亲和力),降低企业人力成本(支持7×24小时服务)。

五、常见问题解答(FAQ)
1. 问题:生成的数字人视频出现人物“走形”或动作断裂,怎么办?
解答:核心原因是“记忆库配置不足”或“参考图像质量不佳”。解决方案:① 调整配置文件中memory_size参数(从3提升至5,增加长期记忆存储量);② 更换参考图像(确保人物清晰、无遮挡、姿态自然,避免模糊或侧脸照片);③ 若生成时长超过10分钟,建议定期“重置记忆库”(通过API调用reset_memory()函数)。
2. 问题:首帧生成时间超过1.5秒,甚至卡顿,如何优化?
解答:① 检查硬件配置:确保显卡支持CUDA加速,且显存≥12GB(显存不足会导致卡顿,可降低output_resolution至480p);② 关闭冗余程序:生成时关闭其他占用显卡/内存的程序(如游戏、视频编辑软件);③ 启用“快速模式”:在运行命令中添加--fast_mode参数,牺牲少量细节提升速度。
3. 问题:音频与唇形不同步,如何校准?
解答:① 检查音频文件:确保音频格式为MP3/WAV,采样率为16kHz(推荐官方标准格式);② 调整校准参数:在配置文件中添加lip_sync_offset: 0.05(单位:秒,可根据实际情况微调正负值);③ 重新训练对齐模型:若通用模型适配性差,可使用官方提供的train_lip_sync.py脚本,用自有音频-视频数据微调模型。
4. 问题:能否生成全身数字人视频?参考图像需要全身照吗?
解答:支持生成全身数字人视频,参考图像无需全身照——框架会基于面部特征自动补全身体姿态(默认生成上半身,若需全身可在配置文件中设置body_type: full_body)。建议参考图像包含人物肩部及以上,确保面部特征清晰,补全的身体姿态更自然。
5. 问题:FlowAct-R1 支持Windows系统吗?
解答:官方优先支持Linux/macOS系统,Windows系统可通过“WSL2(Windows子系统)”安装配置(具体步骤参考官方文档./docs/windows_install.md);直接在Windows原生环境下运行可能存在依赖库兼容问题,不推荐新手尝试。
六、相关链接
七、总结
FlowAct-R1 是字节跳动智能创作团队推出的开源实时交互式数字人视频生成框架,其核心突破在于通过流式缓冲区、Self-Forcing++、多阶段蒸馏三大关键技术,首次实现了“流式无限时长、25FPS低延迟、高逼真度”的三者统一,解决了传统数字人视频生成“时长受限、延迟高、动作僵硬”的核心痛点。该框架仅需一张参考图像即可生成多风格、多模态控制的数字人视频,兼顾专业性与易用性,适配直播、视频会议、在线教育、娱乐创作等多个落地场景,为开发者提供了高效、低成本的交互式数字人视频生成解决方案;其开源特性进一步降低了技术门槛,推动了交互式数字人技术在各行业的普及与应用。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/flowact-r1.html





