Kandinsky 5.0:ai-forever推出的开源视频/图像生成工具,轻量版性能居同类开源模型第一
一、Kandinsky 5.0是什么?
Kandinsky 5.0并非单一模型,而是由俄罗斯AI实验室ai-forever开源的扩散模型家族,核心定位是“高效支持视频与图像生成的AI工具集”。截至项目文档更新时,视频生成功能已完整开源,图像生成功能标注为“Coming Soon”(待上线),是当前开源文本到视频(T2V)领域的代表性项目之一。
从项目定位来看,Kandinsky 5.0的核心目标是“平衡性能与轻量化”——既避免大参数模型(如10B以上)的高显存门槛,又保证生成质量优于同类轻量模型。其已开源的核心子模型Kandinsky 5.0 T2V Lite(以下简称“T2V Lite”)仅2B参数,却在同类开源模型中排名#1,甚至能超越参数更大的Wan 2.1(14B)、Wan 2.2(5B)等模型;同时,它是开源生态中唯一具备“最佳俄语概念理解能力”的T2V模型,填补了多语言视频生成的空白(尤其针对俄语场景)。
从项目生态来看,Kandinsky 5.0提供了完整的开源资源:包括可直接运行的代码仓库、8个预训练模型 checkpoint(托管于Hugging Face)、详细的推理教程(含Python代码示例)、性能评估报告(如VBench评分、Side-by-Side对比),以及ComfyUI等第三方工具的集成方案,降低了开发者与研究者的使用门槛。
二、Kandinsky 5.0的核心功能特色
Kandinsky 5.0凭借“轻量高性能”“多场景适配”“灵活优化”三大核心优势,在开源T2V领域脱颖而出,具体功能特色可分为以下6点:
1. 轻量级架构,性能却居同类第一
T2V Lite模型仅2B参数,远低于主流大模型(如Wan 2.2的5B、Sora的百亿级参数),但性能表现突出:
排名优势:在同类开源T2V模型中排名#1,是轻量级(<5B参数)领域的标杆;
质量碾压:在视觉质量、动态一致性、prompt遵循度三大核心维度,全面优于Wan 2.1(14B)、Wan 2.2(5B)等大参数模型。例如在“视觉质量”维度的Side-by-Side对比中,T2V Lite的占比达73.3%,而Wan 2.1(14B)仅23.3%;
显存友好:通过Offloading优化后,全流水线可在24GB显存的GPU上运行(如NVIDIA A100、H100),无需超大规模显存硬件,降低了小团队与个人开发者的使用门槛。
2. 8个模型变体,精准适配不同需求
为满足“高画质”“快速度”“微调”等不同场景,T2V Lite提供8个细分变体,覆盖“时长”与“功能”两大维度,具体参数与用途可参考下表:
| 模型变体名称 | 视频时长 | NFE(扩散步骤) | 推理延迟(H100 GPU) | 核心优势 | 适用场景 | 配置文件路径 |
|---|---|---|---|---|---|---|
| T2V Lite SFT 5s | 5s | 100 | 139s | 最高生成质量 | 追求画质优先的场景(如广告片、创意短片) | configs/config5ssft.yaml |
| T2V Lite SFT 10s | 10s | 100 | 224s | 10秒长视频+高画质 | 需要较长时长且画质不妥协的场景(如产品演示) | configs/config10ssft.yaml |
| T2V Lite pretrain 5s | 5s | 100 | 139s | 适配微调需求 | 研究者微调模型(如适配医疗、工业场景) | configs/config5spretrain.yaml |
| T2V Lite pretrain 10s | 10s | 100 | 224s | 10秒视频+微调基础 | 长视频场景的模型微调 | configs/config10spretrain.yaml |
| T2V Lite no-CFG 5s | 5s | 50 | 77s | 平衡速度与质量 | 中等画质需求,需缩短等待时间(如社交媒体短视频) | configs/config5snocfg.yaml |
| T2V Lite no-CFG 10s | 10s | 50 | 124s | 10秒视频+速度优化 | 长视频场景的速度优先需求 | configs/config10snocfg.yaml |
| T2V Lite distill 5s | 5s | 16 | 35s | 极致低延迟(6×快) | 实时性需求(如直播素材生成、快速原型) | configs/config5sdistil.yaml |
| T2V Lite distill 10s | 10s | 16 | 61s | 10秒视频+最快速度 | 长视频实时生成场景(如动态广告弹窗) | configs/config10sdistil.yaml |
注:NFE(Number of Function Evaluations)即扩散步骤数,步骤越少,推理速度越快;延迟数据为第二次推理结果(第一次因编译会更慢),基于NVIDIA H100(80GB)、CUDA 12.8.1、PyTorch 2.8测试。
3. 强多语言理解,俄语支持领先
在开源T2V模型中,Kandinsky 5.0的语言理解能力具有独特优势:
俄语领先:是当前开源生态中“对俄语概念理解最佳”的模型,能精准识别俄语prompt中的细节(如“русская wieś зимой”(俄罗斯乡村的冬天),可生成符合地域特色的雪景、木屋等元素);
多语言兼容:基于Qwen2.5-VL与CLIP的文本嵌入技术,同时支持英语、中文等主流语言,prompt遵循度在多语言场景中均保持较高水平(如中文“戴红帽子的猫在草地上跳”,可准确生成对应元素)。
4. 三大推理优化,兼顾速度与显存
为解决“大模型推理慢、显存占用高”的痛点,Kandinsky 5.0提供三大优化方案:
Offloading显存优化:通过将部分模型层(如VAE、文本嵌入器)动态加载到CPU,全流水线显存占用可降至24GB,适配中端GPU(如NVIDIA A100、RTX 4090);
Magcache推理加速:针对SFT、no-CFG模型,通过缓存中间计算结果,进一步缩短推理时间,尤其适合高频次生成场景(如批量生成短视频);
分布式推理:支持多节点、多GPU部署(如1节点2GPU、4GPU),通过torch.distributed.launch分配资源,既能分摊显存压力,又能提升长视频生成速度。
5. 无缝集成第三方工具,降低使用门槛
Kandinsky 5.0已完成与主流AI工作流工具的集成,无需从零开发:
ComfyUI集成:项目提供专门的comfyui文件夹,包含节点配置与使用教程,支持通过可视化节点拖拽生成视频(无需编写代码),并新增SDPA支持(无需Flash Attention也可运行);
Hugging Face托管:所有模型checkpoint均托管于Hugging Face,通过download_models.py脚本可自动下载,无需手动处理大文件;
Jupyter示例:提供inference_example.ipynb笔记本,包含完整的Python推理代码与注释,新手可快速上手。
6. 完整的性能评估,结果透明可验证
项目团队公开了详细的性能评估报告,确保结果可追溯、可验证:
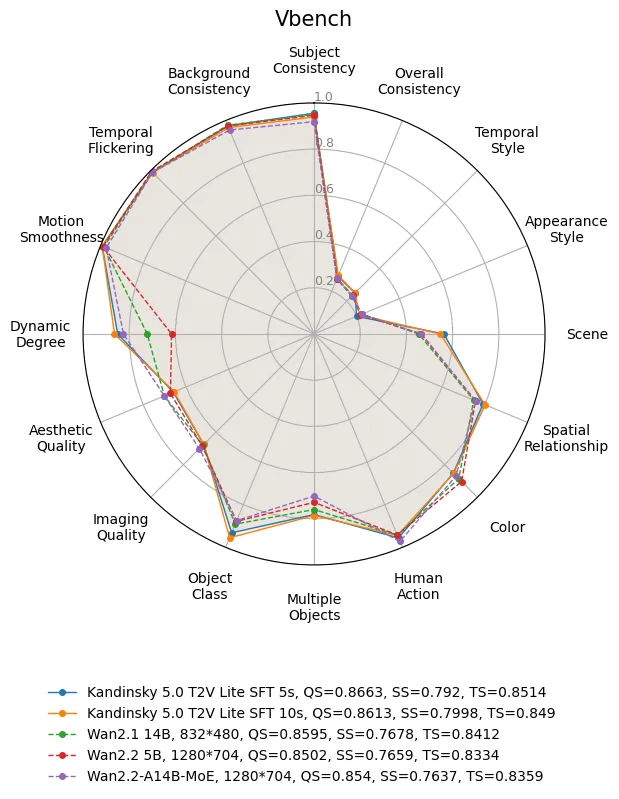
VBench评分:在视频生成领域权威评测集VBench中,T2V Lite SFT 5s的“质量分(QS)”达0.8663、“时序分(TS)”达0.8514,均高于Wan 2.1(14B)的0.8595(QS)、0.8412(TS);
Side-by-Side对比:基于Movie Gen基准的扩展prompt,公开了与Sora、Wan系列模型的对比数据(如与Sora相比,T2V Lite在“动态效果”维度占比达54.0%);
开源评测代码:benchmark文件夹包含评测脚本与数据集(如moviegen_bench.csv),用户可自行复现评估结果,验证模型性能。
三、Kandinsky 5.0的技术细节
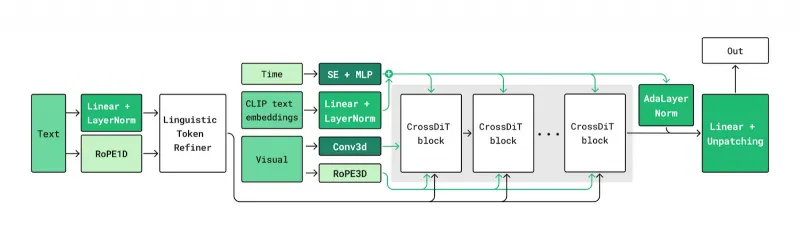
Kandinsky 5.0的视频生成能力依赖“潜在扩散+多模块协同”的技术架构,核心组件与工作流程清晰,以下从“技术流水线”“核心模块”“关键优化技术”三方面拆解:
1. 核心技术流水线:Flow Matching潜在扩散
Kandinsky 5.0采用“Latent Diffusion with Flow Matching”(带流匹配的潜在扩散)流水线,相比传统扩散模型,能减少生成过程中的噪声干扰,提升视频的时序一致性。其核心流程分为3步:
文本嵌入:输入的文本prompt(如“A dog in a red hat”)先由Qwen2.5-VL与CLIP联合处理,生成包含语义细节的文本嵌入向量(捕捉“狗”“红帽子”“场景氛围”等信息);
潜在空间生成:DiT(扩散Transformer)作为核心生成模块,以文本嵌入向量为条件,在HunyuanVideo 3D VAE定义的潜在空间中,通过Flow Matching算法逐步生成视频的潜在表示(避免直接在像素空间生成,减少计算量);
视频解码:HunyuanVideo 3D VAE将潜在表示解码为像素级视频帧,最终输出完整视频(支持5秒/10秒时长,默认分辨率768×512,可通过参数调整)。
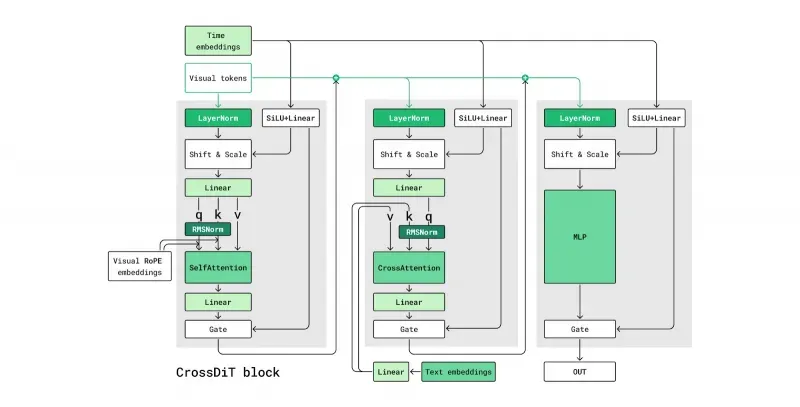
2. 关键核心模块解析
Kandinsky 5.0的性能依赖四大核心模块的协同,每个模块的功能与作用如下:
| 核心模块 | 技术类型 | 核心作用 | 优势说明 |
|---|---|---|---|
| Diffusion Transformer(DiT) | 生成骨干网络 | 基于文本嵌入,在潜在空间生成视频特征 | 采用CrossAttention机制,确保文本与视觉精准对齐;支持3D时序建模,提升视频流畅度 |
| Qwen2.5-VL + CLIP | 文本嵌入模型 | 将文本prompt转换为机器可理解的向量 | 双模型联合嵌入,兼顾语义准确性(Qwen2.5-VL)与跨模态对齐(CLIP),多语言支持更好 |
| HunyuanVideo 3D VAE | 视频编解码模型 | 将视频压缩到潜在空间(编码)/从潜在空间还原(解码) | 3D结构适配视频的时序维度,减少帧间信息损失,提升视频一致性 |
| NABLA算法 | 模型训练优化 | 用于10秒模型的训练,提升长视频生成速度 | 通过“邻域自适应块级注意力”,减少长视频训练的计算冗余,使10秒模型比5秒模型更快 |
3. 模型优化技术:蒸馏与无CFG设计
为实现“速度与质量的平衡”,Kandinsky 5.0采用两种关键优化技术:
蒸馏技术(Distillation):通过“知识蒸馏”将SFT模型(100步扩散)的能力迁移到少步骤模型中,最终实现16步扩散(扩散蒸馏),推理速度提升6×,同时质量损失最小(如distill模型与SFT模型在“视觉质量”维度的差距仅4.4%);
无CFG设计(no-CFG):去除传统扩散模型中的“Classifier-Free Guidance(CFG)”机制,减少计算量的同时避免过拟合,扩散步骤从100步降至50步,速度提升2×,适合对质量要求中等、速度要求较高的场景。
四、Kandinsky 5.0的应用场景
基于“轻量、多变体、多语言”的特点,Kandinsky 5.0可覆盖个人、企业、科研三大群体的需求,具体应用场景如下:
1. 个人创作者:短视频与创意内容生成
社交媒体素材:小红书、抖音、TikTok等平台创作者,可通过T2V Lite distill模型(35秒生成5秒视频)快速生成创意短片,如“穿搭展示”“美食制作过程”,仅需输入文本prompt(如“女生穿白色连衣裙在海边散步,日落背景”);
俄语内容创作:俄语地区创作者可精准生成符合本土文化的内容,如“俄罗斯传统节日场景”“俄语儿童动画片段”,无需担心语言理解偏差;
设计原型快速验证:设计师可通过SFT模型生成高画质视觉原型(如“未来科技感家居设计”),快速确认创意方向,减少手绘时间。
2. 企业与团队:低成本视频生产
中小商家广告:线下店铺、电商商家可通过no-CFG模型生成5-10秒产品广告(如“咖啡店拿铁制作过程,温馨氛围”),无需专业剪辑团队,降低营销成本;
内部培训素材:企业可生成教学视频片段(如“办公软件操作步骤”),通过预训练模型微调适配行业术语(如“医疗设备操作指南”);
动态内容自动化:互联网企业可通过分布式推理批量生成动态内容(如APP弹窗广告、游戏场景素材),Magcache优化可提升批量生成效率。
3. 科研与教育:模型研究与教学演示
T2V技术研究:高校或实验室研究者可基于pretrain模型进行微调,探索新的扩散技术(如改进Flow Matching算法),或适配特定领域(如“遥感视频生成”“医疗影像动态演示”);
AI教学演示:教师可通过Kandinsky 5.0的开源代码讲解扩散模型原理,或生成可视化案例(如“扩散步骤对视频质量的影响”),帮助学生理解技术细节;
多语言AI研究:研究者可基于其俄语理解优势,探索多语言T2V模型的优化方向(如如何提升小语种的prompt遵循度)。
五、Kandinsky 5.0的使用方法
Kandinsky 5.0提供“代码推理”“ComfyUI可视化”两种使用方式,以下详细介绍从环境准备到视频生成的完整流程(以代码推理为例,ComfyUI使用可参考项目comfyui文件夹说明):
1. 环境准备
(1)硬件要求
GPU:需NVIDIA GPU(支持CUDA),推荐配置:
基础配置:NVIDIA RTX 4090(24GB),支持Offloading优化;
推荐配置:NVIDIA H100(80GB),推理速度最快(如distill 5s模型仅35秒);
CPU与内存:无严格要求,建议CPU≥8核、内存≥32GB(避免数据加载卡顿);
存储:需预留至少50GB空间(用于存放模型checkpoint,单个模型约5-10GB)。
(2)软件要求
操作系统:Linux(推荐Ubuntu 20.04+,适配CUDA;Windows需额外配置CUDA环境);
CUDA版本:12.8.1(项目测试版本,低版本可能存在兼容性问题);
PyTorch版本:2.8(需与CUDA版本匹配,可通过官网命令安装);
其他依赖:Flash Attention 3(可选,用于H100 GPU提速)、ffmpeg(用于视频编码)。
2. 安装步骤
(1)克隆项目仓库
打开终端,执行以下命令克隆GitHub仓库:
git clone https://github.com/ai-forever/Kandinsky-5.git cd Kandinsky-5 # 进入项目根目录
(2)安装依赖包
通过pip安装项目所需依赖(建议使用虚拟环境,避免版本冲突):
# 创建并激活虚拟环境(可选但推荐) conda create -n kandinsky5 python=3.10 conda activate kandinsky5 # 安装依赖 pip install -r requirements.txt # 可选:安装Flash Attention 3(H100 GPU推荐,提升推理速度) pip install flash-attn==3.0.0
(3)下载模型Checkpoint
项目提供自动下载脚本,执行以下命令即可下载所有模型(或指定模型):
python download_models.py # 脚本会自动从Hugging Face下载8个模型checkpoint,默认存放在models文件夹
若仅需下载特定模型(如distill 5s),可修改脚本中的模型列表,或直接从Hugging Face手动下载(每个模型的Hugging Face链接在项目README的“Model Zoo”中,标注为“🤗 HF”)。
3. 基础推理:生成第一个视频
以“生成5秒‘戴红帽子的狗’视频”为例,不同模型变体的推理命令如下:
| 模型变体 | 推理命令 |
|---|---|
| SFT 5s(高画质) | python test.py --prompt "A dog in a red hat" --savepath "./sftdog.mp4" |
| distill 5s(快速度) | python test.py --config ./configs/config5sdistil.yaml --prompt "A dog in a red hat" --savepath "./distilldog.mp4" |
| no-CFG 5s(平衡) | python test.py --config ./configs/config5snocfg.yaml --prompt "A dog in a red hat" --savepath "./nocfgdog.mp4" |
命令参数说明:
--prompt:输入的文本描述,支持多语言(如中文“戴红帽子的狗”);--config:指定模型配置文件路径(默认使用SFT 5s的配置);--save_path:视频保存路径(默认存放在项目根目录,格式为mp4);--video_duration:视频时长(仅10秒模型需指定,如--video_duration 10)。
执行命令后,终端会显示推理进度(如“Step 10/100”),推理完成后,在指定路径可找到生成的视频文件。
4. 进阶推理:优化与定制
(1)启用Offloading(显存不足时)
若GPU显存不足(如24GB以下),可添加--offload参数启用显存优化:
python test.py --prompt "A dog in a red hat" --offload --save_path "./offload_dog.mp4"
启用后,模型会将部分层加载到CPU,显存占用可降至24GB以下。
(2)启用Magcache(加速推理)
针对SFT、no-CFG模型,可添加--magcache参数加速:
python test.py --config ./configs/config_5s_sft.yaml --prompt "A dog in a red hat" --magcache --save_path "./magcache_dog.mp4"
Magcache通过缓存中间结果,可缩短约20%的推理时间。
(3)Python代码自定义推理
若需灵活调整参数(如分辨率、种子),可使用项目提供的Python API,示例代码如下:
import torch
from IPython.display import Video # 用于Jupyter中展示视频
from kandinsky import get_T2V_pipeline
# 1. 配置设备(指定GPU/CPU)
device_map = {
"dit": torch.device('cuda:0'), # DiT模块用GPU 0
"vae": torch.device('cuda:0'), # VAE模块用GPU 0
"text_embedder": torch.device('cuda:0') # 文本嵌入器用GPU 0
}
# 2. 加载模型流水线(指定SFT 5s配置)
pipe = get_T2V_pipeline(device_map, conf_path="configs/config_5s_sft.yaml")
# 3. 生成视频(自定义参数)
video = pipe(
seed=42, # 随机种子,固定种子可生成相同视频
time_length=5, # 视频时长(秒)
width=768, # 视频宽度(像素)
height=512, # 视频高度(像素)
save_path="./custom_dog.mp4", # 保存路径
text="A dog in a red hat playing in the grass", # 详细文本描述
num_inference_steps=100 # 扩散步骤(与NFE一致,SFT模型默认100)
)
# 4. 展示视频(Jupyter环境中)
Video("./custom_dog.mp4")
通过修改width(宽度)、height(高度)、seed(种子)等参数,可定制视频的分辨率与内容一致性。
5. 分布式推理(多GPU部署)
若需使用多GPU加速长视频生成(如10秒视频),可执行以下命令(以1节点2GPU为例):
# 设置节点数与每节点GPU数 NUMBER_OF_NODES=1 NUMBER_OF_DEVICES_PER_NODE=2 # 启动分布式推理 python -m torch.distributed.launch --nnodes $NUMBER_OF_NODES --nproc-per-node $NUMBER_OF_DEVICES_PER_NODE test.py --config ./configs/config_10s_sft.yaml --prompt "A dog in a red hat" --save_path "./distributed_dog.mp4"
分布式推理会将模型拆分到多个GPU上,既降低单GPU显存压力,又提升推理速度(如2GPU生成10秒视频,延迟可从224s降至120s左右)。
六、常见问题解答(FAQ)
1. 运行模型时提示“CUDA out of memory”(显存不足),怎么办?
答:可通过以下3种方式解决:
启用Offloading:推理命令添加
--offload参数,将部分层加载到CPU,显存占用降至24GB以下;选择轻量模型:改用distill(16步)或no-CFG(50步)模型,如
--config ./configs/config_5s_distil.yaml,减少计算量;降低分辨率:在Python代码中减小
width和height(如从768×512改为512×384),显存需求会随分辨率平方降低。
2. 为什么第一次推理速度很慢,第二次却变快了?
答:第一次推理慢是因为模型编译——PyTorch会对模型进行首次编译优化(如算子融合),编译完成后,第二次及后续推理会复用优化结果,速度显著提升(如SFT 5s模型第一次推理可能需200s,第二次仅139s)。
3. 如何选择适合自己的模型变体?
答:根据“需求优先级”选择,参考下表:
| 需求优先级 | 推荐模型变体 | 理由 |
|---|---|---|
| 画质优先 | SFT 5s/10s | 100步扩散,生成质量最高,适合广告、创意场景 |
| 速度优先 | distill 5s/10s | 16步扩散,6×快,适合实时生成、批量处理 |
| 平衡速度与质量 | no-CFG 5s/10s | 50步扩散,2×快,适合社交媒体短视频 |
| 模型微调 | pretrain 5s/10s | 保留预训练特征,适配自定义数据集微调 |
4. 模型支持生成中文/俄语以外的语言吗?
答:支持。模型的文本嵌入依赖Qwen2.5-VL与CLIP,这两个模型均支持多语言(如日语、法语、西班牙语等)。实际测试中,中文、英语、俄语的prompt遵循度最高,小语种(如韩语)建议尽量使用简洁的描述,以提升生成准确性。
5. 如何在ComfyUI中使用Kandinsky 5.0?
答:步骤如下:
下载ComfyUI并安装(参考ComfyUI官网);
将Kandinsky 5.0项目中的
comfyui文件夹复制到ComfyUI的custom_nodes目录;启动ComfyUI,在节点面板中找到“Kandinsky 5.0 T2V”相关节点(如“Kandinsky T2V Pipeline”);
拖拽节点,连接“Text Prompt”“Model Checkpoint”“Video Save”等模块,点击“Queue Prompt”即可生成视频。
6. 生成的视频有闪烁或帧间不一致的问题,怎么解决?
答:可尝试以下方法:
改用SFT模型:SFT模型的时序一致性最好,帧间闪烁最少;
增加扩散步骤:在Python代码中提高
num_inference_steps(如从50步改为80步),但会增加推理时间;固定种子:设置
seed参数(如seed=42),避免随机噪声导致的帧间跳变。
七、相关链接
项目GitHub仓库:https://github.com/ai-forever/Kandinsky-5
参考论文(∇NABLA算法):https://arxiv.org/abs/2507.13546
HuggingFace模型库:https://huggingface.co/collections/ai-forever/kandinsky-50-t2v-lite-68d71892d2cc9b02177e5ae5
八、总结
Kandinsky 5.0是ai-forever团队开源的扩散模型家族,以“轻量高效、多场景适配、俄语理解领先”为核心亮点,其已开源的T2V Lite模型(2B参数)在同类开源模型中排名第一,既具备优于Wan 5B/14B的生成质量,又通过Offloading、Magcache等优化降低了显存与速度门槛;8个模型变体覆盖“高画质”“快速度”“微调”等需求,支持5秒/10秒视频生成,适配个人创作者、企业、科研者等不同群体;技术架构上采用Flow Matching潜在扩散流水线,结合DiT、Qwen2.5-VL、HunyuanVideo 3D VAE等模块,确保文本与视觉的精准对齐及视频时序一致性;同时提供完整的安装、推理教程与ComfyUI集成方案,文档透明、资源开源,是当前开源文本到视频领域中“性能与易用性平衡”的优质选择,尤其适合对俄语生成有需求或追求轻量级部署的用户。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/kandinsky-5.html





