VibeVoice:微软开源的 AI 语音合成工具,实现低延迟长音频与多语种语音生成
一、VibeVoice是什么
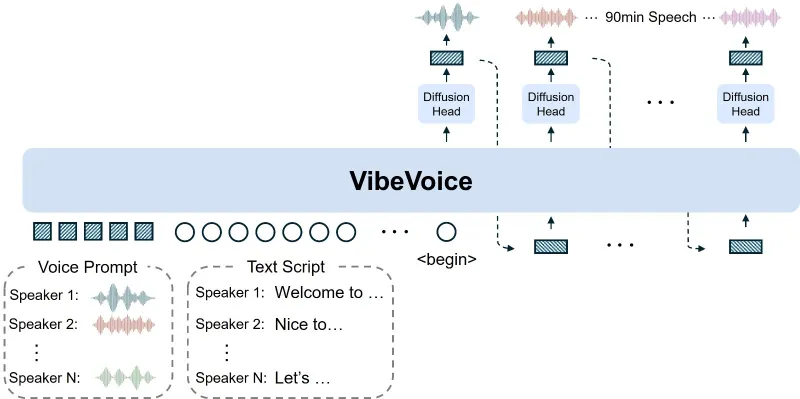
VibeVoice是微软开源的一款高性能语音AI研究框架,聚焦于解决传统文本转语音(TTS)系统在长文本处理、多说话人一致性及自然对话生成方面的技术痛点。该框架支持最长90分钟的多说话人对话音频合成、300毫秒级延迟的实时流式语音生成,同时覆盖中英双语及9种实验性语种,依托创新的连续语音tokenizer和next-token diffusion技术,兼顾了音频保真度与计算效率,为语音合成领域的研究与开发提供了高效、灵活的开源解决方案。
VibeVoice本质上是一款基于深度学习的端到端语音合成工具,其核心定位是“面向对话场景的高自然度语音生成平台”。不同于传统TTS工具仅聚焦单句或短文本的语音转换,VibeVoice专门针对长文本对话、多角色交互等复杂场景做了深度优化,既能生成长达90分钟的单说话人有声内容,也能实现4个不同说话人的自然对话切换,同时还推出了实时流式版本,满足低延迟语音生成需求。
作为微软在语音AI领域的重要开源成果,VibeVoice不仅整合了微软研究院在自然语言处理和音频生成领域的技术积累,还创新性地融合了大型语言模型(LLM)的上下文理解能力与扩散模型的声学细节生成能力,让语音生成不再局限于“文字到声音”的简单映射,而是能精准匹配文本的语义情感和对话逻辑,大幅提升了合成语音的自然度和表现力。
二、功能特色
VibeVoice的功能体系围绕“长、多、快、准”四大核心需求构建,既覆盖了科研场景的技术探索需求,也兼顾了部分实用场景的落地可能,其具体功能特色可分为以下五大模块,核心参数对比可参考下表:
| 功能模块 | VibeVoice长文本模型 | VibeVoice-Realtime-0.5B(实时模型) | 传统TTS模型(行业平均) |
|---|---|---|---|
| 最长合成时长 | 90分钟 | 10分钟(流式可扩展) | 5-10分钟 |
| 支持多说话人数量 | 4个 | 暂不支持 | 1-2个 |
| 初始生成延迟 | 无(非实时) | 约300ms(硬件影响) | 1000ms以上 |
| 支持语言 | 中英+9种实验性语种 | 中英 | 多为单一语种 |
| 上下文理解能力 | 依托LLM实现语义匹配 | 基础语义适配 | 无独立语义理解模块 |
1. 长文本语音合成能力
VibeVoice的长文本模型是其核心特色之一,突破了传统TTS模型的序列长度限制,可直接处理并生成长达90分钟的连续语音内容。这一能力得益于其低帧率的语音tokenizer设计,在保证音频保真度的前提下,大幅降低了长序列处理的计算压力,尤其适合有声书录制、播客节目制作、长篇新闻播报等场景。例如,用户只需输入一部数万字的小说文本,VibeVoice就能一次性生成完整的有声版本,且全程保持说话人音色、语速的一致性,无需分段合成和后期拼接。
2. 多说话人对话生成
针对对话类语音场景(如广播剧、客服对话模拟),VibeVoice支持最多4个不同说话人的音色切换,且切换过程无明显断层,能精准区分不同角色的语音特征。传统多说话人TTS模型往往需要大量的个性化训练数据,而VibeVoice通过轻量化的音色编码方案,可基于少量参考音频快速适配新的说话人音色,同时在对话流程中依托LLM的上下文理解能力,让不同说话人的语气、语调匹配对话场景的情感逻辑,例如在辩论场景中实现语气的对抗性,在闲聊场景中实现语气的轻松感。
3. 实时流式语音生成
为满足低延迟场景需求,VibeVoice推出了专门的实时版本VibeVoice-Realtime-0.5B,其初始可听语音的生成延迟仅为300毫秒左右(具体延迟取决于硬件配置),支持流式文本输入。这意味着用户可逐句输入文本,模型会同步生成语音,无需等待全部文本输入完成,适用于智能客服、实时语音助手、在线教育实时讲解等场景。该实时模型的上下文长度为8K,单次生成的语音时长可达10分钟,且能保持流式输出的稳定性和连贯性。
4. 多语种语音支持
VibeVoice不仅实现了英语和中文的高质量语音合成,还额外提供了9种语言的实验性说话人模型,包括德语、法语、意大利语、日语、韩语、荷兰语、波兰语、葡萄牙语、西班牙语。虽然这些语种目前处于实验阶段,合成效果略逊于中英双语,但为多语种语音合成的研究提供了重要的基础框架,开发者可基于现有模型进行针对性优化,拓展更多语种的适配能力。
5. 高保真与情感表现力
不同于部分开源TTS模型存在的“机械音”“断句生硬”等问题,VibeVoice通过融合LLM的语义理解能力,可精准识别文本中的情感倾向(如喜悦、悲伤、严肃)和标点逻辑(如逗号、句号、感叹号的停顿差异),并通过扩散模型生成对应的声学细节。例如,在处理感叹句时会自动提升语调,在处理疑问句时会添加尾音上扬的特征,同时保证音频的高保真度,采样率和音色还原度均达到行业先进水平。

三、技术细节
VibeVoice的技术架构可分为“文本理解层、语音编码层、扩散生成层、音频解码层”四大核心模块,其技术创新主要集中在语音tokenizer设计和next-token diffusion框架,以下从核心技术原理和整体架构两方面展开解析:
1. 核心技术原理
(1)连续语音tokenizer:低帧率高保真的编码方案
语音tokenizer是连接文本和音频的关键桥梁,传统TTS模型的tokenizer通常采用较高的帧率(如50Hz),虽然能保留更多声学细节,但会导致长序列的token数量激增,大幅提升计算成本。VibeVoice创新性地采用7.5Hz的超低帧率连续语音tokenizer,将声学特征和语义特征进行联合编码,在降低token数量的同时,通过多尺度特征融合技术保证音频保真度。
具体来说,该tokenizer分为声学tokenizer和语义tokenizer两个分支:声学tokenizer负责提取音频的频谱、基频等声学特征,语义tokenizer则依托预训练的语言模型提取文本的语义信息,两者通过交叉注意力机制实现特征对齐,最终生成兼具语义关联性和声学准确性的语音token序列。这种设计让模型在处理90分钟长音频时,token数量仅为传统高帧率模型的1/6左右,显著提升了长序列处理的效率。
(2)next-token diffusion框架:LLM驱动的生成逻辑
VibeVoice的语音生成核心采用了next-token diffusion框架(相关技术论文已发表于arXiv,论文编号2412.08635),该框架将语音生成拆解为“语义规划”和“声学生成”两个阶段,实现了LLM与扩散模型的高效协同:
语义规划阶段:由Qwen2.5 1.5B作为基础LLM,负责理解输入文本的上下文逻辑、情感倾向和对话结构,生成对应的语义token序列,同时为多说话人场景分配音色编码,确保语音生成符合文本的语义逻辑;
声学生成阶段:扩散模型作为“生成头”,基于语义token序列和音色编码,逐token生成高保真的声学特征,最终通过音频解码器转换为可听的语音信号。
相较于传统的自回归生成模型,next-token diffusion框架既保留了扩散模型生成内容的高多样性和保真度,又借助LLM的语义理解能力解决了语音生成的逻辑连贯性问题,实现了“语义准确+声学自然”的双重目标。
2. 整体技术架构
VibeVoice的端到端架构可分为以下四个层级,各层级的功能和技术实现如下:
文本预处理层:负责文本的清洗、分词、标点符号解析和情感标注,将原始文本转换为LLM可理解的结构化输入,同时为多说话人场景标记说话人切换指令;
语义理解与规划层:以Qwen2.5 1.5B为核心,完成文本上下文理解、情感倾向判断和说话人音色分配,生成包含语义和音色信息的中间token序列;
语音生成层:基于next-token diffusion框架,扩散模型接收中间token序列,逐帧生成声学特征,实时模型在此层级会额外启用流式生成逻辑,保证低延迟输出;
音频解码与后处理层:将声学特征转换为PCM格式的音频信号,同时进行降噪、音量均衡等后处理,提升音频的最终播放效果。
此外,VibeVoice还采用了Flash Attention技术优化模型的注意力计算效率,降低了大模型训练和推理的显存占用,让普通开发者也能在消费级GPU上完成基础的推理测试。
四、应用场景
VibeVoice的功能特性使其可适配科研和实用两大领域的多种场景,具体可分为以下六大类:
1. 学术研究场景
作为开源的语音合成框架,VibeVoice为科研人员提供了完整的技术验证平台:
长序列语音生成研究:其90分钟长文本合成能力,可用于探索长序列音频的一致性建模、注意力机制优化等前沿课题;
多说话人对话建模:4说话人支持和LLM语义规划能力,为多角色对话的情感匹配、音色切换等研究提供了数据和模型基础;
低延迟流式生成研究:实时版本的300ms延迟方案,可用于实时语音生成的延迟优化、流式解码算法改进等方向的实验。
2. 有声内容创作场景
对于内容创作者而言,VibeVoice可大幅降低有声内容的制作成本:
有声书录制:支持长篇小说、科普读物的一键语音合成,无需专业配音演员,且能保持全程音色一致,适合中小内容团队快速产出有声内容;
播客节目制作:可生成多主持人对话式播客,通过多说话人功能区分主播和嘉宾的音色,同时依托LLM的语义理解能力,让对话语气更符合节目风格;
新闻与资讯播报:能快速将新闻稿件转换为语音播报,支持批量处理多篇资讯,适用于音频资讯平台的内容生产。
3. 智能客服与助手场景
VibeVoice的实时流式模型可适配客服和助手类场景:
智能客服语音交互:对接客服系统后,可实时将文字回复转换为语音,300ms的低延迟保证了对话的流畅性,提升用户咨询体验;
智能语音助手:为智能家居、车载助手等设备提供自然语音生成能力,支持多轮对话的语气连贯性,让助手的语音交互更具人性化。
4. 广播剧与影视配音场景
在影视和广播剧领域,VibeVoice可辅助完成初期配音和角色试音:
广播剧角色配音:4个说话人支持可满足小型广播剧的角色需求,快速生成多角色对话片段,用于剧本试音和初期制作;
影视片花配音:可根据片花脚本生成旁白和角色台词,适配不同情感基调,降低片花制作的配音成本。
5. 多语种内容出海场景
针对跨境内容制作,VibeVoice的多语种支持能力可发挥作用:
多语种有声读物:将中文内容转换为英语、日语等多语种语音,拓展内容的海外传播渠道;
跨境客服语音支持:为跨境电商客服系统提供多语种语音回复,适配不同地区用户的语言需求(注:实验性语种需额外优化)。
6. 教育与培训场景
在教育领域,VibeVoice可用于教育音频的制作:
教材音频配套:将中小学教材、教辅资料转换为语音,帮助学生进行听力练习,支持中英文及多语种教材的适配;
培训课程录制:企业可将内部培训文档转换为语音课程,通过多说话人功能区分讲师和案例角色,提升培训内容的趣味性。
五、使用方法
VibeVoice的使用分为环境准备、模型安装和推理测试三大步骤,同时支持长文本模型和实时模型的不同调用方式,具体操作如下:
1. 环境准备
VibeVoice对硬件和软件环境有明确要求,推荐使用NVIDIA GPU以获得最佳性能:
(1)硬件要求
推理阶段:建议使用显存≥16GB的NVIDIA GPU(如RTX 3090、RTX 4090),实时模型可在8GB显存GPU上运行;
训练阶段:需显存≥40GB的专业GPU(如A100),支持多卡分布式训练。
(2)软件环境
VibeVoice推荐使用NVIDIA深度学习容器管理CUDA环境,具体环境配置步骤如下:
启动Docker容器 首先确保本地已安装Docker和NVIDIA Container Toolkit,然后执行以下命令启动支持的PyTorch容器:
sudo docker run --privileged --net=host --ipc=host --ulimit memlock=-1:-1 --ulimit stack=-1:-1 --gpus all --rm -it nvcr.io/nvidia/pytorch:24.07-py3
支持的容器版本包括24.07、24.10、24.12及更高版本,容器内已预装CUDA、PyTorch等核心依赖。
安装Flash Attention 若容器内未预装Flash Attention,需手动安装以优化注意力计算:
pip install flash-attn --no-build-isolation
2. 模型安装
完成环境准备后,可通过GitHub克隆项目并安装依赖:
克隆仓库
git clone https://github.com/microsoft/VibeVoice.git cd VibeVoice/
安装项目依赖 执行以下命令以可编辑模式安装项目,方便后续修改代码:
pip install -e .
下载预训练模型 预训练模型可通过项目官方提供的链接下载(具体链接见“六、相关官方链接”),下载后将模型文件放入
./models目录,即可开始推理。
3. 基础推理测试
VibeVoice提供了简单的推理脚本,支持长文本和实时两种模式的测试:
(1)长文本多说话人模式
创建long_text_demo.py脚本,输入以下代码(示例为双说话人对话生成):
from vibe_voice import VibeVoice
# 初始化模型
model = VibeVoice(model_path="./models/long_text_model")
# 定义多说话人文本,用[SpeakerX]标记说话人
text = """
[Speaker1] 你好,今天的天气真不错啊!
[Speaker2] 是啊,适合出去走走,要不要一起去公园?
[Speaker1] 好主意,那我们下午三点在小区门口集合吧!
[Speaker2] 没问题,我会提前准备好水和零食。
"""
# 生成语音
audio = model.generate(text, speaker_num=2, output_path="./dialogue.wav")
print("多说话人对话语音已生成至dialogue.wav")运行脚本后,即可在指定路径得到合成的对话音频。
(2)实时流式模式
创建realtime_demo.py脚本,测试实时流式生成:
from vibe_voice import VibeVoiceRealtime # 初始化实时模型 realtime_model = VibeVoiceRealtime(model_path="./models/realtime_model") # 流式输入文本并生成语音 text_chunks = [ "大家好,", "欢迎使用VibeVoice实时语音生成功能,", "本功能的初始延迟仅为300毫秒左右,", "适合各类实时语音交互场景。" ] for chunk in text_chunks: audio_chunk = realtime_model.stream_generate(chunk) # 播放或保存音频片段 realtime_model.play_audio(audio_chunk)
该脚本会逐段接收文本并同步生成语音,模拟实时交互的效果。
4. 注意事项
运行前需确保CUDA环境配置正确,否则会出现模型加载失败或推理速度极慢的问题;
预训练模型体积较大(通常为数十GB),需保证本地存储空间充足;
多语种实验性模型的合成效果存在差异,建议针对目标语种进行微调后再投入使用。
六、常见问题解答
1. 模型加载失败,提示显存不足怎么办?
答:可通过以下三种方式解决:
降低模型推理的batch size,将单次生成的文本长度拆分至更小的片段;
启用模型的量化模式,将模型权重转换为INT8或FP16格式,降低显存占用(会轻微损失音质);
升级GPU硬件,使用显存≥24GB的专业显卡,或采用多卡分布式推理。
2. 多说话人切换时出现音色混淆如何处理?
答:该问题通常由以下原因导致,可针对性优化:
说话人标记不清晰,需确保文本中[SpeakerX]标记准确且无遗漏;
参考音色的音频样本不足,可提供更多目标说话人的参考音频进行微调;
调整模型的音色编码权重,增强不同说话人之间的特征区分度。
3. 实时模型的延迟超过300ms,如何优化?
答:实时延迟受硬件和软件双重影响,优化方案包括:
关闭不必要的后台程序,释放GPU和CPU资源;
启用Flash Attention和TensorRT加速,提升模型推理速度;
降低输入文本的单chunk长度,减少单次处理的计算量;
升级至更高性能的GPU,如RTX 4090或专业计算卡。
4. 合成语音存在机械音或断句生硬的问题怎么办?
答:可通过后处理和模型微调解决:
使用项目自带的音频后处理工具,进行断句平滑和语调优化;
增加文本的标点符号标注,让模型更准确识别停顿逻辑;
用高质量的情感语音数据集对模型进行微调,提升语音的自然度。
5. 如何添加新的语种支持?
答:添加新语种需完成以下步骤:
收集目标语种的文本-音频平行数据集,建议数据量不少于100小时;
对VibeVoice的语义tokenizer进行跨语种微调,实现目标语种的语义编码;
训练目标语种的声学扩散模型,优化该语种的声学特征生成效果;
进行多轮效果验证,调整模型参数直至达到预期音质。
七、相关链接
GitHub仓库地址:https://github.com/microsoft/VibeVoice
模型地址:https://huggingface.co/collections/microsoft/vibevoice-68a2ef24a875c44be47b034f
八、总结
VibeVoice作为微软开源的语音AI研究框架,凭借创新的连续语音tokenizer和next-token diffusion技术,成功突破了传统TTS系统在长文本处理、多说话人交互和低延迟生成方面的技术瓶颈,其90分钟长文本合成、4说话人支持、300ms实时延迟等核心能力,既为语音合成领域的学术研究提供了完整的验证平台,也为有声内容创作、智能客服、教育音频等实用场景提供了高效的解决方案。该项目采用MIT开源协议,依托Python生态和NVIDIA GPU加速,降低了开发者的使用门槛,同时配套的完整文档和示例代码,让不同技术水平的用户都能快速上手。尽管其多语种模型仍处于实验阶段,且存在一定的硬件门槛,但整体而言,VibeVoice为语音合成的开源生态提供了重要的技术补充,是连接科研创新与场景落地的优质桥梁。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/vibevoice.html





