Z-Image:阿里通义开源的轻量级AI图像生成与编辑模型,支持亚秒级推理与中英双语精准渲染
一、Z-Image是什么?
Z-Image(中文名“造相”)是阿里巴巴通义实验室研发并开源的高效图像生成基础模型,定位为“轻量且高性能”的AI图像解决方案,核心参数规模仅6B,却能对标参数量20B以上的闭源旗舰模型。需特别注意的是,Z-Image与Linux系统中的“zImage”(压缩内核镜像)无任何关联——前者是专注于图像生成的AI模型,后者是嵌入式设备的系统引导文件,二者分属完全不同的技术领域。
从项目定位来看,Z-Image的核心目标是“打破算力壁垒”:通过底层架构创新与算法优化,让高质量AI图像生成从“依赖顶级GPU”走向“消费级硬件可用”。根据官方实测与第三方验证(如PConline太平洋科技测试),该模型在RTX 4090显卡上生成1024×1024像素图像仅需2.3秒,显存占用仅13GB;更入门的RTX 3060 6G版本(消费级主流显卡)也能流畅运行,最高显存控制在16GB以内,彻底解决了“独立创作者因硬件不足无法使用优质AI生图工具”的痛点。
目前Z-Image包含三个功能变体,覆盖“快速生成”“深度开发”“图像编辑”三大核心场景,具体信息如下表所示:
| 模型变体 | 定位 | 关键参数/特性 | 当前状态 | 核心能力 |
|---|---|---|---|---|
| Z-Image-Turbo | 高效推理版(蒸馏版) | 8步NFE、亚秒级延迟、≤16GB显存 | 已开源(多平台) | photorealistic 生成、中英文字渲染、低门槛使用 |
| Z-Image-Base | 基础开发版(非蒸馏) | 6B全参数、支持微调 | 待发布 | 社区二次开发、定制化训练(如垂直领域适配) |
| Z-Image-Edit | 图像编辑版(微调版) | 自然语言驱动、图像-图像转换 | 待发布 | 精准编辑(换背景、改元素)、创意修图 |
项目采用Apache 2.0开源许可,允许开发者自由使用、修改、二次分发(需保留版权声明),且无商业使用限制,极大降低了企业与个人的开发成本。

二、Z-Image的功能特色
Z-Image之所以能快速成为开源图像生成领域的焦点,核心源于其“效率、质量、易用性”三者的平衡,具体功能特色可分为五大维度:
1. 极致高效:少步采样+低显存+快延迟
作为Z-Image的核心开源变体,Z-Image-Turbo在“效率”上实现了三重突破:
8步采样达印刷级画质:传统图像生成模型需20-50步采样才能保证质量,而Z-Image-Turbo仅需8步(官方代码中
num_inference_steps设为9,实际仅执行8步DiT前向计算),即可生成细节达标、可用于印刷的图像,采样效率提升2-6倍;亚秒级推理延迟:在企业级H800 GPU上,生成1024×1024图像耗时可压缩至1秒以内(亚秒级),即使在消费级RTX 4090上也仅需2.3秒,远超同参数规模模型的速度;
超低显存占用:通过架构优化与内存管理,模型在生成过程中最高显存占用≤16GB,支持RTX 3060 6G、RTX 2060等老旧消费级显卡,无需顶级硬件即可启动。
2. 高质量生成: photorealistic 细节+电影级视觉
Z-Image在图像质量上达到开源模型第一梯队水平(据AI Arena Elo榜单,Z-Image-Turbo位列第4,开源模型第1),具体表现为:
** photorealistic 还原**:能精准呈现真实世界细节,如人物皮肤的毛孔纹理、玻璃材质的多层反射、金属表面的光影渐变,甚至雨雾天气下的逆光散射效果;
电影级景深与光影:自动优化画面层次感,支持“前景清晰+背景虚化”的景深效果,且光影过渡自然(如夜晚路灯下的人物投影、室内台灯的漫反射);
美学一致性:生成图像符合大众审美,避免“AI感”过重的扭曲(如比例失调的人体、色彩冲突的场景),可直接用于设计、插画、营销素材等正式场景。
3. 中英双语精准处理:告别“指令误解”与“文字鬼画符”
针对AI生图的两大痛点(指令理解弱、文字生成差),Z-Image做了专项优化:
超长嵌套指令理解:能处理包含多物体、多空间关系的复杂指令,例如“左手拿着珍珠奶茶、右手手机屏幕显示今日股市行情、背景是上海外滩夜景”,甚至矛盾修辞指令(如“夜晚的阳光”),并自动逻辑纠偏;
无“鬼画符”文字:彻底解决AI生图中文字模糊、错字、乱码的问题,无论是中文汉字(如“福”“登科后”诗句)还是英文字母(如“Winter Release”“VISUAL PORTFOLIO”),均能清晰、规整地融合在画面中,且字体风格与场景匹配(如古风诗句用楷体、现代标语用黑体)。
4. 灵活图像编辑:自然语言驱动的“一键改图”
待发布的Z-Image-Edit变体专注于图像编辑场景,核心优势是“无需专业工具,文字即可改图”:
零门槛操作:用户无需掌握PS、AI等设计软件,仅需输入自然语言指令(如“把图中猫咪的姿势改成侧卧,背景从沙发换成草坪”“将人物的红色汉服换成蓝色旗袍”),模型即可精准执行;
编辑保真性:修改过程中保持图像原有风格与细节(如人物肤色、物体材质),避免“改一处毁全图”的问题,例如“换背景”时会自动调整前景人物的光影以匹配新背景;
创意扩展:支持“基于原图的创意生成”,如“给原图中的小狗添加圣诞帽和围巾”“将白天场景改为星空夜景”,满足个性化创作需求。
5. 开源开放:多平台获取+社区友好
Z-Image在开源生态上表现开放,降低了开发者的使用与二次开发门槛:
多平台可获取:Z-Image-Turbo已在Hugging Face、ModelScope两大平台同步开源,提供Checkpoint(模型权重)与Online Demo(在线试用),无需下载即可体验;
支持社区微调:待发布的Z-Image-Base为全参数基础模型,允许开发者基于垂直领域数据(如医学图像、游戏美术、工业设计)进行微调,适配特定场景;
完善的文档支持:官方提供详细的技术报告(Z_Image_Report.pdf)、算法论文(Decoupled_DMD.pdf)、快速开始代码,以及艺术画廊(PDF+网页版),方便开发者学习与参考。

三、Z-Image的技术细节
Z-Image的性能突破源于底层架构与核心算法的创新,具体可拆解为“架构设计”“核心算法”“依赖组件”三大模块:
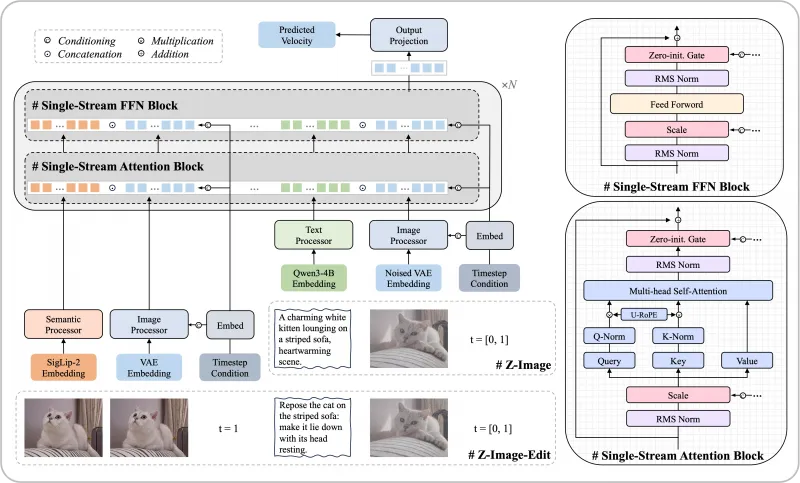
1. 架构:S3-DiT单流扩散Transformer
Z-Image采用Scalable Single-Stream DiT(S3-DiT) 架构,这是其“参数效率高、推理速度快”的核心原因,与传统“双流架构”(文本流+图像流分开处理)相比,优势显著:
统一输入流设计:将三类核心信息——文本语义(由Qwen3-4B处理)、视觉语义(由SigLip-2处理)、图像VAE令牌(图像编码后的数据)——在“序列级别”拼接为单一输入流,而非分开处理后再融合;
参数效率最大化:单流设计避免了双流架构中“重复参数”的浪费(如双流需分别维护文本与图像的注意力层),使得6B参数能发挥出接近20B双流模型的效果;
模块复用:文本、视觉、图像信息共享同一套Transformer注意力层与FFN(前馈网络),减少计算量,间接提升推理速度与降低显存占用。
S3-DiT的核心模块包括“单流注意力块”与“单流FFN块”,均加入了“Zero-init. Gate”(零初始化门控)与“RMS Norm”( Root Mean Square归一化),进一步优化训练稳定性与推理效率。
2. 核心算法:Decoupled-DMD与DMDR
Z-Image的“8步高效生成”与“质量提升”依赖两大核心算法:
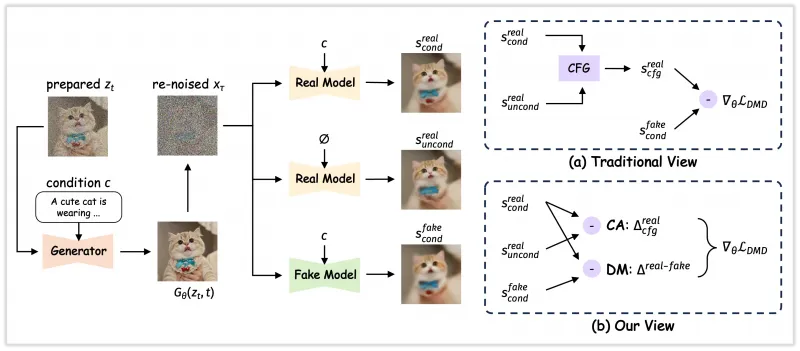
(1)Decoupled-DMD:少步蒸馏的“加速魔法”
Decoupled-DMD(解耦分布匹配蒸馏)是Z-Image-Turbo实现8步采样的关键,其核心思路是“拆解并优化传统DMD算法的两大机制”:
传统DMD的问题:传统分布匹配蒸馏(DMD)将“CFG增强”与“分布匹配”混为一谈,导致少步生成时质量与速度无法兼顾;
解耦优化:
CFG增强(CA):作为蒸馏的“主引擎”,通过类别条件引导(CFG)放大优质样本的特征,提升少步生成的质量,这一机制在传统研究中被忽视;
分布匹配(DM):作为“正则化器”,确保生成图像的分布与真实数据一致,避免出现扭曲、异常的画面;
效果:通过解耦,Z-Image-Turbo在8步采样下即可达到传统20步模型的质量,且训练效率提升30%。
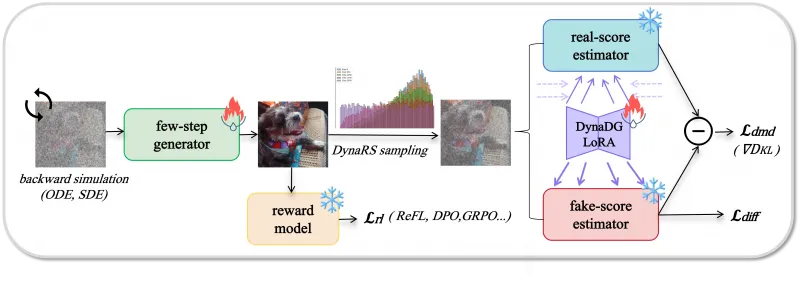
(2)DMDR:融合RL与DMD的“质量升级”
DMDR(DMD with Reinforcement Learning)是在Decoupled-DMD基础上的进一步优化,核心是“用强化学习(RL)提升性能,用DMD保证稳定”:
RL的作用:解锁DMD的潜力,提升图像的语义对齐(指令与画面匹配)、美学质量(色彩、构图)、结构 coherence(物体比例、空间关系),并增加高频细节(如纹理、光影);
DMD的作用:作为RL的“正则化器”,避免RL训练中出现的“极端优化”(如为了细节牺牲整体比例),确保生成稳定性;
协同效果:DMDR让Z-Image在8步采样下,不仅速度快,还能保持高质量,实现“速度与质量双赢”。
3. 依赖组件:文本+视觉+图像的“三方协同”
Z-Image的能力依赖三个核心组件的协同工作:
文本处理:Qwen3-4B:阿里通义自研的3.4B参数大语言模型,负责解析中英双语指令,将文本转换为机器可理解的语义向量,确保指令理解的准确性;
视觉语义处理:SigLip-2:谷歌开源的视觉-语言模型,负责提取图像的视觉语义特征(如物体类别、场景类型、色彩风格),让模型理解“画面内容是什么”;
图像编码:VAE:变分自编码器,负责将图像转换为低维度的VAE令牌(减少计算量),生成时再将令牌解码为像素图像,同时控制图像的分辨率与细节。
三者通过S3-DiT架构拼接为统一流,实现“文本指令→语义理解→图像生成”的端到端流程。
四、Z-Image的应用场景
基于“低门槛、高质量、易扩展”的特性,Z-Image可覆盖个人、企业、科研等多类场景:
1. 独立创作者:无硬件门槛的“设计助手”
独立创作者(插画师、设计师、自媒体人)往往缺乏顶级GPU,但Z-Image的低硬件要求使其成为理想工具:
场景示例1:插画与设计:汉服设计师用RTX 3060 6G显卡,输入指令“红色汉服, intricate刺绣,金色凤凰头饰,背景是西安大雁塔夜景”,2.3秒生成设计初稿,再微调细节;
场景示例2:自媒体配图:美食博主输入“红烧肉,青花瓷盘,背景是木质餐桌,暖光台灯, photorealistic 风格”,快速生成公众号封面图,无需等待专业摄影师拍摄;
场景示例3:文字类素材:书法博主需要“古风诗句‘春风得意马蹄疾’配图,背景是长安街景,文字用楷体”,模型可精准生成诗句+场景的融合图,无需后期加字。
2. 中小企业:低成本的“素材生产工具”
中小企业(电商、小微企业、线下门店)无需采购昂贵的设计服务,可通过Z-Image快速生成商业素材:
电商场景:服装卖家输入“蓝色牛仔裤,模特站姿,背景是白色简约布景,光线均匀”,批量生成商品主图,替换传统“摄影师+模特”的高成本方案;
营销场景:奶茶店输入“草莓奶茶,杯身贴‘冬季限定’标签,背景是暖黄色门店内饰”,生成朋友圈宣传图,当天设计当天使用;
办公场景:小公司输入“年终总结PPT封面,蓝色科技风,标题‘2025年度报告’,背景是数据图表元素”,无需设计岗也能做出专业封面。
3. 科研与教育:开源可研究的“图像生成范式”
高校、科研机构可基于Z-Image开展图像生成技术研究,或用于教学:
科研场景:研究人员基于Z-Image-Base(待发布)微调,探索“医学图像生成”(如CT影像模拟)、“工业检测图生成”(如零件缺陷样本),推动垂直领域技术落地;
教学场景:AI专业教师用Z-Image的S3-DiT架构讲解“扩散模型与Transformer的结合”,用Decoupled-DMD算法演示“模型蒸馏优化”,学生可直接运行代码验证原理。
4. 个性化编辑:普通人的“零门槛修图工具”
待发布的Z-Image-Edit可满足普通人的日常修图需求,无需专业技能:
场景示例1:照片改景:用户上传自己的自拍照,输入“将背景从办公室换成三亚海滩,保持人物光影与海滩匹配”,一键替换背景;
场景示例2:物体修改:用户上传宠物猫照片,输入“给猫咪添加圣诞帽,围巾是红色条纹款”,自动添加装饰元素;
场景示例3:风格转换:用户上传手机拍的风景照,输入“转换为宫崎骏动画风格,色彩鲜艳,线条柔和”,生成创意图像。
五、Z-Image的使用方法
以Z-Image-Turbo(已开源)为例,详细介绍从环境搭建到图像生成的完整流程,操作难度低,适合新手:
1. 环境准备:安装依赖库
Z-Image依赖Hugging Face的diffusers库,且需安装源码版(因官方已向diffusers提交2个PR并合并,需最新功能支持):
# 安装源码版diffusers(支持Z-Image) pip install git+https://github.com/huggingface/diffusers # 安装其他依赖(PyTorch、图像处理库等) pip install torch torchvision pillow accelerate
注意:需确保PyTorch版本≥2.0,且支持CUDA(Windows/Linux均支持,Mac暂不支持GPU加速);
验证:安装完成后,运行
python -c "from diffusers import ZImagePipeline; print('安装成功')",无报错即正常。
2. 加载模型:代码示例与参数说明
通过ZImagePipeline加载Z-Image-Turbo模型,核心代码如下(含详细注释):
import torch
from diffusers import ZImagePipeline
# 1. 加载模型(关键参数说明)
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo", # 模型在Hugging Face的路径
torch_dtype=torch.bfloat16, # 数据类型:bfloat16比float32更省显存,且支持多数GPU
low_cpu_mem_usage=False, # 关闭低CPU内存模式(提升加载速度,若CPU内存不足可设为True)
)
# 将模型移至GPU(若无GPU,可改为pipe.to("cpu"),但生成速度会极慢)
pipe.to("cuda")模型加载时间:首次加载需下载模型权重(约12GB,视网络速度而定),后续加载无需重复下载;
显存检查:加载完成后,GPU显存占用约4-6GB(未生成时),预留足够空间。
3. 优化配置:提升速度与降低显存(可选)
根据自身硬件情况,可开启以下优化选项:
# 选项1:启用Flash Attention(提升推理速度,需GPU支持,如RTX 30系及以上、A100等)
# Flash Attention 2:适用于较新GPU
pipe.transformer.set_attention_backend("flash")
# Flash Attention 3:适用于最新GPU(如RTX 40系、H100)
# pipe.transformer.set_attention_backend("_flash_3")
# 选项2:模型编译(提升速度,首次运行会耗时编译,后续复用)
# 注意:编译后显存占用会略增,若显存不足可跳过
pipe.transformer.compile()
# 选项3:CPU卸载(显存不足时启用,将部分模型移至CPU,牺牲少量速度)
# 适用于RTX 3060 6G等低显存显卡
# pipe.enable_model_cpu_offload()4. 生成图像:设置参数与执行
定义生成参数(如prompt、分辨率、采样步长),执行生成并保存结果:
# 定义生成指令(可替换为自己的需求,支持中英双语)
prompt = "Young Chinese woman in red Hanfu, intricate embroidery. Impeccable makeup, red floral forehead pattern. Elaborate high bun, golden phoenix headdress, red flowers, beads. Holds round folding fan with lady, trees, bird. Neon lightning-bolt lamp (⚡️), bright yellow glow, above extended left palm. Soft-lit outdoor night background, silhouetted tiered pagoda (西安大雁塔), blurred colorful distant lights."
# 2. 生成图像(关键参数说明)
image = pipe(
prompt=prompt, # 生成指令
height=1024, # 图像高度(建议1024,支持512/768/1024)
width=1024, # 图像宽度(与高度一致,避免拉伸)
num_inference_steps=9, # 采样步数:设为9,实际执行8步(Z-Image-Turbo优化)
guidance_scale=0.0, # 引导尺度:Turbo版必须设为0(无需额外引导)
generator=torch.Generator("cuda").manual_seed(42), # 随机种子:42,固定种子可生成相同图像
).images[0] # 获取生成的第一张图像(仅生成1张,可通过num_images_per_prompt设多张)
# 3. 保存图像
image.save("hanfu_example.png") # 保存为PNG格式,路径可自定义
print("图像生成完成,已保存为 hanfu_example.png")生成时间:RTX 4090约2.3秒,RTX 3060 6G约5-8秒;
参数调整:若需生成多张图,添加
num_images_per_prompt=3(生成3张);若需更高分辨率,可设height=1536, width=1536(需显存≥12GB)。
六、常见问题解答(FAQ)
1. Z-Image与Linux系统的“zImage”有什么区别?
二者完全无关:Z-Image是阿里通义研发的AI图像生成模型,用于生成图片、编辑图像;Linux的zImage是压缩内核镜像文件,用于嵌入式设备的系统引导(如路由器、开发板),二者技术领域、功能、用途均不同,无需混淆。
2. 我的GPU是RTX 3060 6G,为什么能运行Z-Image-Turbo?
因为Z-Image通过两大优化降低了显存需求:① S3-DiT架构减少参数冗余,降低内存占用;② 支持“CPU卸载”(pipe.enable_model_cpu_offload()),将部分非核心模块移至CPU,仅保留关键计算在GPU。实际测试中,RTX 3060 6G开启CPU卸载后,生成1024×1024图像显存占用约5-6GB,完全可运行。
3. 生成图像时文字还是模糊,怎么办?
可能有两个原因:① prompt不够具体,需补充文字细节(如“文字用楷体,字号24,颜色黑色,位于画面上方居中”);② 采样步数不足,可将num_inference_steps从9改为10(仍在高效范围内),提升文字清晰度。若问题依旧,可尝试更新diffusers库至最新版(pip install --upgrade git+https://github.com/huggingface/diffusers)。
4. Z-Image-Base和Z-Image-Edit什么时候发布?
根据官方GitHub仓库与通义实验室公告,二者目前处于“待发布”状态,暂无明确时间。建议关注项目GitHub(https://github.com/Tongyi-MAI/Z-Image)或ModelScope页面,官方会第一时间更新发布信息。
5. 支持Windows系统吗?可以用CPU生成吗?
系统支持:Windows、Linux均支持,需安装对应版本的PyTorch(Windows需安装带CUDA的PyTorch);
CPU生成:支持(
pipe.to("cpu")),但生成速度极慢(1024×1024图像可能需30分钟以上),仅建议无GPU时临时测试,不推荐日常使用。
6. 可以基于Z-Image-Turbo微调自己的数据集吗?
不建议。Z-Image-Turbo是蒸馏后的高效模型,参数经过压缩,微调效果有限;若需微调,建议等待Z-Image-Base发布(非蒸馏基础模型),其全参数设计更适合二次开发。目前官方暂未提供微调教程,后续可能会在GitHub补充。
七、相关链接
| 资源类型 | 链接 | 说明 |
|---|---|---|
| GitHub仓库 | https://github.com/Tongyi-MAI/Z-Image | 项目主仓库,含源码、文档、论文、报告 |
| Hugging Face |
Checkpoint:https://huggingface.co/Tongyi-MAI/Z-Image-Turbo Demo:https://huggingface.co/spaces/Tongyi-MAI/Z-Image-Turbo | Turbo版模型权重与在线演示 |
| ModelScope |
Checkpoint:https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo Demo:https://www.modelscope.cn/aigc/imageGeneration?tab=advanced&modelType=Checkpoint&sdVersion=Z_IMAGE_TURBO | 国内平台,支持中文环境,下载速度快 |
| 技术报告 | https://github.com/Tongyi-MAI/Z-Image/blob/main/Z_Image_Report.pdf | Z-Image技术细节全解析 |
| Decoupled-DMD论文 | https://github.com/Tongyi-MAI/Z-Image/blob/main/Decoupled_DMD.pdf | 核心蒸馏算法论文 |
| DMDR论文 | https://arxiv.org/abs/2511.13649 | RL与DMD融合算法论文(arXiv链接) |
八、总结
Z-Image是阿里巴巴通义实验室为解决“AI生图硬件门槛高、质量与速度难平衡”问题而研发的开源图像生成模型,以6B参数实现了“8步采样、亚秒级推理、≤16GB显存”的高效特性,同时兼具 photorealistic 细节、中英双语精准处理、自然语言编辑能力,在开源模型中处于第一梯队。其核心创新在于S3-DiT单流架构(提升参数效率)、Decoupled-DMD蒸馏(实现少步生成)、DMDR算法(融合RL与DMD提升质量),且通过多平台开源(GitHub、Hugging Face、ModelScope)与Apache 2.0许可,降低了个人与企业的使用成本。无论是独立创作者用消费级GPU生成设计素材,还是中小企业批量生产商业图像,亦或是科研机构研究图像生成技术,Z-Image都能提供实用、高效的解决方案,是开源AI图像领域的重要突破。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/z-image.html





