Kronos:开源金融 K 线基础模型,赋能多场景量化预测与可视化分析
一、Kronos是什么?
Kronos是全球首个开源的金融K线序列专用基础模型,专注于解决金融数据高噪声、多维度的核心痛点,训练数据覆盖全球45+交易所。该模型采用“K线令牌化+自回归Transformer”两阶段框架,将连续的OHLCV(开盘价、最高价、最低价、收盘价、成交量)数据转化为离散令牌后进行预训练,可作为统一模型支撑加密货币、股票、期货等多场景量化任务。
其核心定位是:以“金融K线语言”为训练目标,构建能直接理解、处理、预测K线数据的AI模型,成为量化交易、市场分析、策略回测等任务的“通用底座”。
Kronos的核心特点可概括为三点:
数据覆盖广:训练数据来自全球45+交易所,涵盖加密货币、股票、期货等多类资产,具备跨市场适配能力;
设计针对性强:区别于通用TSFMs,专门优化金融数据的高噪声特性,通过令牌化降低数据波动对模型的干扰;
使用门槛低:提供从数据预处理到预测可视化的全流程工具,即使非专业算法工程师也能快速上手。

二、Kronos的功能特色
Kronos围绕“易用性、灵活性、实用性”设计,核心功能覆盖模型调用、微调、可视化全链路,具体特色如下:
1. 多规模模型家族,适配不同计算需求
Kronos提供4个版本的预训练模型,参数规模从4.1M到499.2M不等,可根据硬件资源(如个人电脑、服务器)和任务精度需求选择,其中3个版本完全开源,可直接从Hugging Face Hub获取。
表1:Kronos模型家族参数对比
| 模型名称 | 配套令牌化器 | 最大上下文长度 | 参数规模 | 开源状态 | Hugging Face仓库地址 | 适用场景 |
|---|---|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4.1M | ✅ 完全开源 | NeoQuasar/Kronos-mini | 轻量场景、CPU运行、快速测试 |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24.7M | ✅ 完全开源 | NeoQuasar/Kronos-small | 中等精度需求、PC端GPU运行 |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102.3M | ✅ 完全开源 | NeoQuasar/Kronos-base | 高精度需求、服务器GPU运行 |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499.2M | ❌ 未开源 | - | 企业级高复杂度任务 |
注:“最大上下文长度”指模型可处理的历史K线序列长度(如512表示可输入512个时间步的K线数据),上下文越长,模型可参考的历史信息越丰富。
2. 端到端预测工具,3行代码实现从数据到结果
Kronos封装了KronosPredictor类,整合数据预处理(归一化、格式校验)、模型推理、结果逆归一化(还原真实价格尺度)三大步骤,用户无需手动处理数据格式转换,仅需传入原始K线数据和时间戳,即可生成预测结果。
例如,传统量化模型需手动编写数据归一化函数、处理序列截断逻辑,而KronosPredictor会自动:
检查输入数据是否包含必填的
open/high/low/close列;对价格、成交量数据进行归一化(避免量纲差异影响模型);
当输入序列长度超过模型
max_context时,自动截断为最大长度;预测后将结果逆归一化,直接输出真实价格范围的预测值(如“10000 USDT”而非归一化后的“0.5”)。
3. 完整微调 pipeline,支持自定义数据适配
针对特定市场(如A股、美股)或资产(如某只股票、期货合约),Kronos提供完整的微调工具链,支持用户基于自有数据优化模型,具体包括:
数据处理适配:兼容Qlib(量化领域常用数据框架),可直接读取Qlib格式的股票/期货数据,无需手动转换;
微调脚本:提供
finetune.py脚本,支持设置微调轮次、学习率、批次大小等参数;回测评估:内置回测工具,可对比微调前后模型的预测精度(如MAE、RMSE)和策略收益(如夏普比率),验证微调效果。
4. 可视化Web UI,零代码实现预测与分析
为降低非技术用户的使用门槛,Kronos开发了基于Flask的Web界面,支持通过浏览器完成“数据上传→模型选择→参数调整→结果可视化”全流程,核心功能模块包括:
数据导入:支持CSV、Feather等格式的K线数据上传,自动解析列名;
模型配置:下拉选择模型版本(mini/small/base)、设置预测长度(如未来24小时)、调整概率预测参数(如温度T);
结果展示:同步显示“历史K线+预测K线”对比图、成交量预测趋势图,支持鼠标hover查看具体时间点的价格;
设备切换:可选择CPU、CUDA(NVIDIA显卡)、MPS(苹果芯片)作为计算设备,适配不同硬件。
5. 支持概率预测,应对金融市场不确定性
金融市场存在高度不确定性,单一预测值难以反映风险,Kronos支持通过“多路径采样”生成概率预测结果:
用户可设置
sample_count(采样次数,如10),模型会生成10条不同的预测路径;通过
T(温度参数,控制随机性,如T=1.0表示中等随机性)和top_p(核采样概率,如0.9表示仅从概率前90%的令牌中采样)调整预测的不确定性;最终可输出预测结果的均值、标准差,帮助用户判断预测的置信度(如标准差小表示预测更稳定)。
6. 多设备兼容,灵活部署
Kronos支持主流计算设备,无需修改代码即可切换:
CPU:适合Kronos-mini/small模型,个人电脑即可运行;
CUDA:支持NVIDIA显卡加速,Kronos-base模型推理速度可提升5-10倍;
MPS:适配苹果M系列芯片(如M1/M2),利用Metal框架加速,满足Mac用户需求。
三、Kronos的技术细节
Kronos的核心竞争力源于其“K线令牌化+自回归Transformer”的两阶段技术框架,该框架专门针对金融K线数据的特性设计,以下从技术原理、数据处理、模型结构三方面拆解:
1. 核心技术框架:两阶段处理流程
Kronos的技术核心是“先将连续K线数据转化为离散令牌,再用Transformer学习令牌序列规律”,解决了传统模型难以处理金融数据高噪声、多维度的问题,具体流程如下:
阶段1:K线令牌化(Tokenizer)——把“连续数据”变成“模型能懂的语言”
金融K线数据是连续的数值序列(如开盘价10000 USDT、收盘价10200 USDT),直接输入Transformer会导致模型难以捕捉规律(噪声干扰大)。Kronos的专用令牌化器通过“量化+分层令牌”设计,将连续数据转化为离散令牌,具体步骤:
输入数据定义:令牌化器的输入是多维度K线数据,包含必填的OHLCV(开盘价、最高价、最低价、收盘价、成交量)和可选的
amount(成交额);量化处理:采用BSQ(Bit-Sliced Quantization)技术,将每个维度的连续数值量化为二进制编码,降低数据波动带来的噪声;
分层令牌生成:将量化后的信息拆分为3类令牌,形成“头部-粗粒度-细粒度”的分层结构,既保留核心趋势,又不丢失细节:
Header(头部令牌):1个令牌,记录该K线的时间戳、数据维度等元信息;
Coarse-grained Subtoken(粗粒度子令牌):
k_c位,反映K线的核心趋势(如价格涨/跌、成交量大/小);Fine-grained Subtoken(细粒度子令牌):
k_f位,记录K线的细节信息(如涨跌幅度、成交量具体数值范围);
令牌输出:最终每个K线时间步会生成
1 + k_c + k_f位的令牌序列,作为Transformer的输入。
令牌化的核心价值:将高噪声的连续金融数据转化为结构化的离散令牌,减少噪声干扰,同时让模型能像处理自然语言(如英文单词序列)一样处理K线序列,提升学习效率。
阶段2:自回归Transformer预训练——学习“K线序列的规律”
令牌化后的序列会输入自回归Transformer进行预训练,模型通过学习历史K线令牌序列,掌握价格波动、成交量变化的规律,具备“根据过去预测未来”的能力。Transformer的结构设计有三大亮点:
Causal Transformer Block 堆叠:模型由N个Causal Transformer Block组成(N根据模型规模调整,如base模型N=12),每个Block包含“多头注意力层+前馈神经网络层”,确保模型能捕捉长序列依赖(如过去100个K线对未来的影响);
注意力机制优化:采用“交叉注意力(Cross-Attention)+块内注意力(Intra-Block Attention)”组合,既关注不同K线维度(如价格与成交量)的关联,又关注同一维度内的序列规律:
Cross-Attention:让模型学习OHLCV各维度之间的关系(如成交量增大是否伴随价格上涨);
Intra-Block Attention:让模型学习同一维度内的历史规律(如过去5个K线的收盘价趋势);
参数共享设计:Transformer的Query、Key、Value层采用部分参数共享,减少模型参数量(如base模型仅102.3M参数),同时提升训练效率;
自回归预测逻辑:预训练任务是“根据前t个K线的令牌序列,预测第t+1个K线的令牌序列”,与金融市场“历史影响未来”的逻辑一致,确保模型能直接用于预测任务。
2. 数据处理关键细节
Kronos在数据处理环节做了大量优化,确保模型输入的一致性和有效性,核心细节包括:
(1)数据归一化与逆归一化
为避免不同维度数据的量纲差异(如价格单位是USDT、成交量单位是BTC)影响模型,KronosPredictor会自动:
归一化:将输入的OHLCV数据映射到[0,1]区间,公式为
(x - min_x) / (max_x - min_x)(minx、maxx为历史数据的最小值、最大值);逆归一化:预测完成后,将模型输出的[0,1]区间结果还原为真实价格/成交量尺度,确保用户得到直观的预测值(如“10500 USDT”而非“0.6”)。
(2)上下文长度处理
每个Kronos模型有固定的max_context(最大上下文长度,如small/base模型512),当用户输入的历史数据长度(lookback)超过max_context时,KronosPredictor会自动截断:保留最近的max_context个时间步的K线数据,确保模型能正常处理(避免序列过长导致内存溢出或推理缓慢)。
(3)概率预测的实现逻辑
Kronos的概率预测通过“多路径采样”实现,具体逻辑:
当用户设置
sample_count=10时,模型会基于同一历史数据,生成10条不同的未来令牌序列(通过调整采样时的随机性实现);对每条令牌序列进行逆归一化,得到10条预测路径;
最终输出10条路径的均值(作为核心预测值)和标准差(作为不确定性指标),帮助用户评估风险。
3. 模型推理的关键参数
在使用Kronos进行预测时,有几个核心参数直接影响结果,需根据任务需求设置,具体说明如下:
表2:Kronos预测核心参数说明
| 参数名称 | 作用 | 取值范围/建议值 | 影响说明 |
|---|---|---|---|
lookback | 输入的历史K线序列长度 |
≤模型max_context | 越长越好(需≤max_context),参考历史信息多 |
pred_len | 预测的未来K线序列长度 | 1-240(建议) | 越长预测不确定性越高(如预测24小时比1小时波动大) |
T(温度) | 控制预测的随机性 | 0.1-2.0 | T=0.1(确定性高,波动小);T=1.0(中等随机性) |
top_p | 核采样概率,控制采样范围 | 0.7-0.95 | top_p=0.9(仅从概率前90%的令牌采样,平衡精度与多样性) |
sample_count | 生成的预测路径数量 | 1-20 | 越多越能反映不确定性(建议10次以上) |
四、Kronos的应用场景
Kronos作为金融K线专用基础模型,可适配加密货币、股票、期货等多类资产的量化任务,具体应用场景如下:
1. 加密货币价格预测(文档核心示例场景)
加密货币市场波动大、24小时交易,传统模型难以捕捉规律。Kronos基于45+全球交易所的加密货币数据训练,支持主流交易对(如BTC/USDT、ETH/USDT)的短期预测:
应用方式:使用Live Demo(文档提供的可视化页面)直接查看BTC/USDT未来24小时的价格预测;或通过KronosPredictor输入历史K线数据,生成自定义交易对的预测;
核心价值:帮助加密货币交易者判断短期趋势(如未来6小时是否会涨),辅助制定止盈止损策略。
2. 股票市场量化分析(A股/美股等)
Kronos支持股票市场的K线数据(如A股的5分钟线、日线),可用于量化分析:
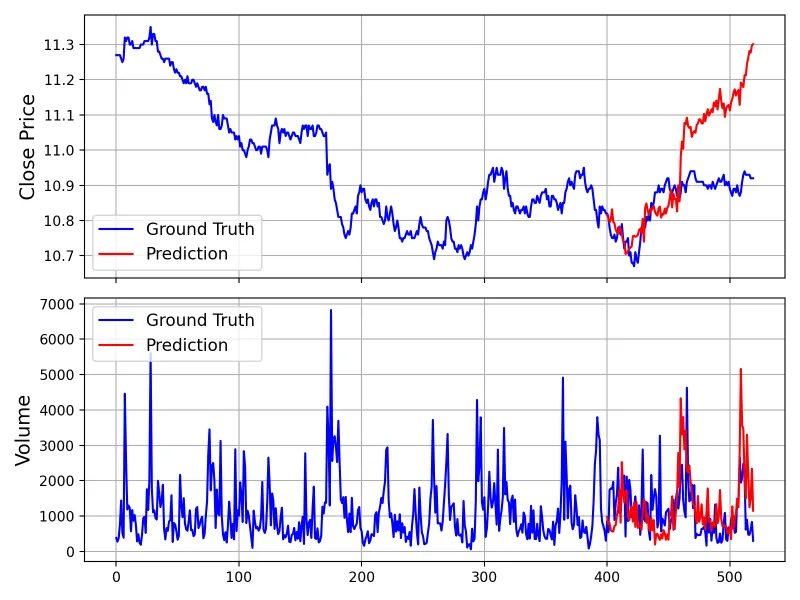
应用方式:通过Qlib加载A股数据(如文档示例中的XSHG5min600977.csv,600977为A股股票代码),微调Kronos-base模型,预测股票未来120个时间步(如5分钟线的10小时)的价格;
核心价值:为股票量化策略提供价格预测输入(如基于预测结果设计“低买高卖”策略),或用于风险评估(如预测下跌概率)。
3. 期货市场趋势判断
期货市场受宏观经济、供需关系影响大,Kronos的多维度数据处理能力(OHLCV+amount)可捕捉期货价格与成交量的关联:
应用方式:输入期货合约(如原油期货、黄金期货)的历史K线数据,设置
pred_len=24(预测未来24小时),生成价格与成交量的联合预测;核心价值:帮助期货交易者判断趋势强度(如价格上涨时成交量是否同步增加,验证趋势的有效性)。
4. 多市场跨资产分析
Kronos的训练数据覆盖全球45+交易所,支持跨市场、跨资产的联合分析:
应用方式:同时输入加密货币(BTC/USDT)、股票(A股600977)、期货(原油)的历史数据,微调模型后分析不同资产的价格联动性(如BTC上涨是否会带动股票市场相关板块上涨);
核心价值:为跨资产配置策略提供支持(如根据预测调整不同资产的持仓比例)。
5. 量化策略回测与优化
Kronos的微调与回测工具可用于量化策略的验证与优化:
应用方式:基于历史数据微调模型,将模型预测结果作为策略的信号(如预测上涨则买入、预测下跌则卖出),通过内置回测工具计算策略的年化收益、夏普比率、最大回撤;
核心价值:对比不同模型版本(如mini vs base)、不同参数(如lookback=200 vs 400)的策略表现,优化策略参数。
五、Kronos的使用方法
Kronos提供“代码调用”和“Web UI”两种使用方式,覆盖技术与非技术用户,以下分步骤详细说明:
1. 环境准备(通用步骤)
无论使用哪种方式,都需先完成环境搭建,具体步骤:
(1)硬件要求
轻量使用(Kronos-mini):个人电脑(CPU即可,建议8GB以上内存);
中等精度(Kronos-small):PC端GPU(如NVIDIA GTX 1060 6GB以上);
高精度(Kronos-base):服务器GPU(如NVIDIA Tesla V100 16GB以上);
苹果用户:支持M1/M2芯片(通过MPS加速)。
(2)软件依赖安装
安装Python:要求Python 3.10及以上版本(推荐3.10或3.11,避免版本兼容问题);
克隆仓库:打开终端,执行命令克隆GitHub仓库到本地:
git clone https://github.com/shiyu-coder/Kronos.git cd Kronos # 进入仓库目录
安装依赖:执行命令安装项目所需的Python库(如pandas、transformers、flask等):
pip install -r requirements.txt
若遇到依赖冲突(如某库版本不兼容),可创建虚拟环境后重新安装:
# 创建虚拟环境(Python 3.10为例) python -m venv kronos_env # 激活虚拟环境(Windows) kronos_env\Scripts\activate # 激活虚拟环境(Mac/Linux) source kronos_env/bin/activate # 重新安装依赖 pip install -r requirements.txt
2. 基础预测流程(代码调用,以Kronos-small为例)
通过代码调用KronosPredictor,实现从原始数据到预测结果的全流程,适合技术用户,具体步骤:
步骤1:加载令牌化器和模型
从Hugging Face Hub加载预训练的令牌化器和模型(需确保网络可访问Hugging Face):
# 导入必要的类
from model import Kronos, KronosTokenizer, KronosPredictor
# 加载令牌化器(Kronos-small对应base版本令牌化器)
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
# 加载Kronos-small模型
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")步骤2:实例化KronosPredictor
创建预测器实例,指定计算设备(如CUDA、CPU)和最大上下文长度:
# 实例化预测器:使用CUDA(若没有GPU,改为device="cpu";苹果M系列改为device="mps") predictor = KronosPredictor( model=model, tokenizer=tokenizer, device="cuda:0", # cuda:0表示第1块GPU,无GPU则写"cpu" max_context=512 # Kronos-small的max_context为512,需与模型匹配 )
步骤3:准备输入数据
输入数据需满足格式要求:pandas DataFrame(含OHLCV列)+ 时间戳Series,具体:
数据格式要求:
必须包含的列:
open(开盘价)、high(最高价)、low(最低价)、close(收盘价);可选列:
volume(成交量)、amount(成交额);时间戳:pandas Datetime格式,需与K线数据一一对应。
示例代码(加载A股5分钟线数据):
import pandas as pd
# 加载本地K线数据(CSV文件,示例为A股600977的5分钟线数据)
df = pd.read_csv("./data/XSHG_5min_600977.csv") # 数据路径需根据实际情况修改
# 将时间戳列转换为Datetime格式
df['timestamps'] = pd.to_datetime(df['timestamps'])
# 定义上下文窗口(lookback)和预测长度(pred_len)
lookback = 400 # 输入400个历史K线时间步(≤max_context=512)
pred_len = 120 # 预测未来120个时间步(如5分钟线的10小时)
# 准备输入数据:历史数据(x_df)、历史时间戳(x_timestamp)、未来时间戳(y_timestamp)
x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']] # 历史K线数据
x_timestamp = df.loc[:lookback-1, 'timestamps'] # 历史时间戳
y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps'] # 未来时间戳(需与预测长度匹配)步骤4:生成预测结果
调用predict方法生成预测,设置概率预测参数:
# 生成预测
pred_df = predictor.predict(
df=x_df, # 历史K线数据
x_timestamp=x_timestamp, # 历史时间戳
y_timestamp=y_timestamp, # 未来时间戳
pred_len=pred_len, # 预测长度(需与y_timestamp长度一致)
T=1.0, # 温度参数(中等随机性)
top_p=0.9, # 核采样概率
sample_count=1 # 采样次数(1次为确定性预测,多次为概率预测)
)
# 查看预测结果(前5行)
print("预测结果前5行:")
print(pred_df.head())步骤5:结果可视化
运行examples文件夹中的示例脚本,生成“历史数据+预测结果”的对比图:
# 运行预测示例脚本(含可视化) python examples/prediction_example.py
运行后会生成两张图:价格对比图(历史收盘价vs预测收盘价)、成交量对比图(历史成交量vs预测成交量),图片保存路径为./figures/prediction_result.png。
3. Web UI使用流程(零代码,适合非技术用户)
若不想写代码,可通过Web UI完成预测,步骤:
启动Web UI:在仓库根目录执行启动脚本(Windows用start.bat,Mac/Linux用start.sh):
# Mac/Linux sh webui/start.sh # Windows webui\start.bat
访问界面:脚本运行成功后,终端会显示“Running on http://127.0.0.1:5000/”,打开浏览器访问该地址,进入Web界面。
上传数据:点击“数据上传”模块,选择本地CSV/Feather格式的K线数据,系统会自动解析列名(需确保含open/high/low/close)。
配置模型:在“模型配置”模块:
选择模型版本(如Kronos-small);
设置预测长度(如24,对应未来24个时间步);
调整概率参数(T=1.0,top_p=0.9);
选择计算设备(如CPU、CUDA)。
生成预测:点击“开始预测”按钮,系统会自动处理数据并生成结果,等待几秒后(取决于模型规模),在“结果展示”模块查看“历史K线+预测K线”对比图,支持下载预测结果为CSV文件。
4. 微调流程(针对自定义数据,以A股为例)
若需适配特定市场(如A股),可对模型进行微调,步骤:
数据准备:使用Qlib加载A股数据,或手动将数据转换为Qlib格式(参考Qlib官方文档);
运行微调脚本:在仓库根目录执行微调脚本,设置微调参数(如学习率、轮次):
python finetune.py \ --model_name NeoQuasar/Kronos-base \ --tokenizer_name NeoQuasar/Kronos-Tokenizer-base \ --data_path ./data/qlib_a股数据 \ --lr 1e-4 \ # 学习率 --epochs 10 \ # 微调轮次 --batch_size 32 \ # 批次大小 --device cuda:0
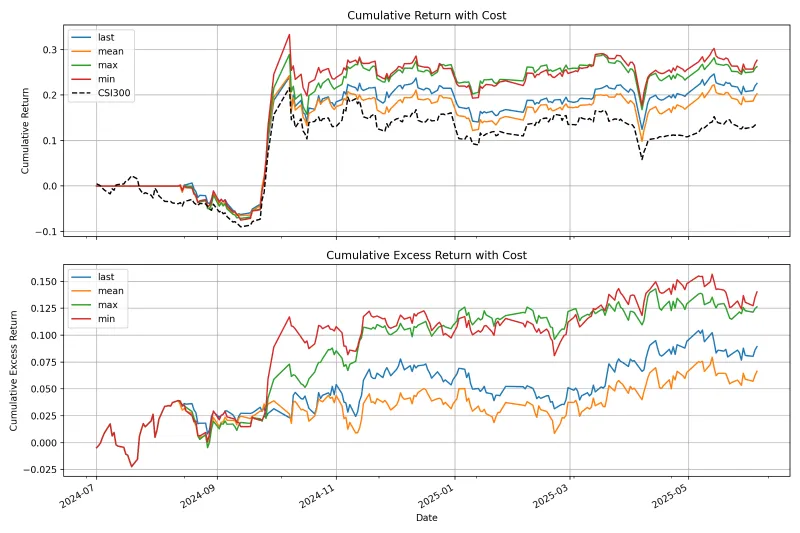
回测评估:微调完成后,运行回测脚本评估模型性能:
python backtest.py \ --finetuned_model_path ./output/finetuned_kronos_base \ # 微调后模型路径 --tokenizer_name NeoQuasar/Kronos-Tokenizer-base \ --data_path ./data/qlib_a股数据 \ --device cuda:0
查看回测结果:回测完成后,终端会输出策略的年化收益、夏普比率、最大回撤等指标,也可生成回测报告(HTML格式)保存在
./backtest_reports/目录。
六、常见问题解答(FAQ)
1. 环境依赖安装失败,提示“某库版本冲突”?
原因:系统中已安装的库版本与Kronos要求的版本不兼容(如transformers版本过低)。
解决方案:
创建独立虚拟环境(参考“环境准备”步骤),避免与其他项目的依赖冲突;
若仍失败,手动指定冲突库的版本,例如:
pip install transformers==4.30.2 pandas==2.0.3 # 根据requirements.txt中的版本指定
2. 加载模型时提示“Could not load model from Hugging Face Hub”?
原因:网络无法访问Hugging Face Hub,或模型名输入错误。
解决方案:
检查网络:确保能访问https://huggingface.co/,若无法访问,可配置代理;
核对模型名:参考表1中的Hugging Face仓库地址,确保模型名正确(如“NeoQuasar/Kronos-small”而非“kronos-small”);
手动下载:若网络受限,可从Hugging Face手动下载模型文件,放入
./model_cache/目录,再通过本地路径加载:
model = Kronos.from_pretrained("./model_cache/Kronos-small")3. 输入数据后提示“Missing required columns: open/high/low/close”?
原因:输入的DataFrame缺少Kronos必需的OHLCV列(开盘价、最高价、最低价、收盘价),或列名拼写错误(如“Open”首字母大写,Kronos要求小写)。
解决方案:
检查数据列名,确保包含小写的
open、high、low、close;若列名是大写(如“OPEN”),可通过代码修改列名:
df.rename(columns={"OPEN": "open", "HIGH": "high", "LOW": "low", "CLOSE": "close"}, inplace=True)4. 预测结果与实际数据偏差很大,怎么办?
原因:可能是lookback设置过小(历史信息不足)、sample_count过少(概率预测随机性大),或模型版本不匹配场景(如用mini模型预测高波动市场)。
解决方案:
增大
lookback(不超过模型max_context,如Kronos-small设为400-512);增加
sample_count(如设为10,取均值作为预测结果);换用更大规模的模型(如从mini升级到base);
对模型进行微调(针对当前市场数据),提升适配性。
5. Web UI启动后,访问http://127.0.0.1:5000/ 提示“端口被占用”?
原因:5000端口已被其他程序(如其他Flask服务)占用。
解决方案:
修改Web UI的端口号:打开
webui/app.py,找到app.run(port=5000),将5000改为其他未占用端口(如5001);或关闭占用5000端口的程序(Windows用
netstat -ano | findstr 5000找到进程ID,再用任务管理器结束;Mac/Linux用lsof -i :5000 | grep LISTEN找到进程,再用kill -9 进程ID结束)。
6. 微调后模型性能反而下降,是什么原因?
原因:微调数据量过少(模型过拟合)、学习率过高(模型震荡)、微调轮次过多(过拟合)。
解决方案:
增加微调数据量(建议至少包含10000个以上K线时间步);
降低学习率(如从1e-3改为1e-4);
减少微调轮次(如从20改为10);
在微调脚本中加入正则化(如权重衰减
--weight_decay 1e-5),避免过拟合。
七、相关链接
为方便用户获取更多信息,以下整理Kronos的官方资源链接:
Hugging Face模型库:
Kronos-mini:https://huggingface.co/NeoQuasar/Kronos-mini
Kronos-small:https://huggingface.co/NeoQuasar/Kronos-small
Kronos-base:https://huggingface.co/NeoQuasar/Kronos-base
八、总结
Kronos是全球首个针对金融K线序列的开源基础模型,通过“K线令牌化+自回归Transformer”的两阶段框架,解决了传统模型难以处理金融数据高噪声、多维度的核心痛点,训练数据覆盖全球45+交易所,提供从mini到base的多规模开源模型,适配不同计算需求。其核心优势在于:封装了端到端的预测工具(KronosPredictor),降低技术门槛;提供完整的微调与回测 pipeline,支持自定义市场适配;开发了可视化Web UI,覆盖非技术用户;支持CPU/CUDA/MPS多设备,部署灵活。无论是加密货币价格预测、股票量化分析,还是期货趋势判断、跨资产配置,Kronos都能提供有效的模型支撑,且遵循MIT许可证开源,允许自由使用、修改和商用。尽管Kronos-large模型尚未开源,但现有开源版本已能满足大部分量化场景的需求,为金融AI领域提供了一个“专用、易用、高效”的基础工具,有助于降低金融量化与AI结合的门槛,推动量化技术在更多场景的应用。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/kronos.html