LightOnOCR-2-1B:LightOnAI开源的10 亿参数开源端到端 OCR 模型
一、LightOnOCR-2-1B 是什么
LightOnOCR-2-1B是一款由LightOnAI团队开发的开源端到端多语言视觉-语言模型(VLM),专为文档光学字符识别(OCR)任务设计,是LightOnOCR系列的旗舰级模型,也是该系列目前性能最佳的OCR模型。其核心定位是“轻量高效且高精度”,通过仅10亿的参数量,打破了“大参数才有效”的行业认知,在权威OCR基准测试中超越了参数量是其9倍的同类模型。
与传统OCR工具不同,LightOnOCR-2-1B采用端到端架构,无需经过布局分析、文本检测、字符识别等多阶段复杂流水线,可直接接收PDF文档或图像输入,输出结构化、标准化的文本内容(默认Markdown格式)。其设计初衷是解决传统OCR流水线组件耦合紧密、适配新文档类型成本高、推理效率低等痛点,同时兼顾复杂场景下的识别精度,让中小企业、开发者及科研人员都能低成本使用高性能OCR技术。
目前,LightOnOCR-2-1B的模型权重(基于Apache 2.0许可)、训练数据集(lightonai/LightOnOCR-mix-0126)及专属边界框评估基准(LightOnOCR-bbox-bench)均已公开,支持开发者自由下载、使用及二次开发,相关资源可通过Hugging Face等官方渠道获取。

二、功能特色
LightOnOCR-2-1B凭借创新设计与优化训练,具备多项核心功能特色,覆盖性能、效率、兼容性、扩展性等多个维度,具体如下:
2.1 越级性能:小参数实现SOTA效果
仅10亿参数量的LightOnOCR-2-1B,在权威的OlmOCR-Bench基准测试中取得83.2±0.9的高分,实现当前最先进(SOTA)的性能表现,超越了众多参数量更大的模型(如90亿参数的Chandra模型)。其优势在复杂场景中尤为突出:在arXiv学术论文(多栏布局)、旧扫描件(模糊、褪色)、含大量数学公式的文档及表格密集型文档中,识别准确率远超同级别模型,甚至媲美部分超大参数模型。
2.2 极致高效:低成本+高速推理
效率是LightOnOCR-2-1B的核心优势之一,完美适配大规模文档处理场景。在硬件适配方面,该模型在单张NVIDIA H100 80GB GPU(配合vLLM推理框架)上,吞吐量可达5.71页/秒,推理速度是Chandra模型的3.36倍、olmOCR-2模型的1.74倍。在成本控制上,处理1000页文档的电费+算力成本不到0.01美元(约合人民币7分钱),相较于传统大参数OCR模型,成本降低一个数量级,极大降低了企业级应用的门槛。
2.3 结构化输出:标准化Markdown格式
不同于传统OCR工具输出的无序文本,LightOnOCR-2-1B可直接输出带有标题层级、列表、代码块、表格结构的标准Markdown文本,无需额外进行格式整理。例如,识别学术论文时,会自动区分标题、摘要、正文、参考文献等层级;识别表格时,能精准还原表格行列结构;识别代码片段时,会保留缩进与语法格式,输出内容可直接用于文档编辑、数据入库等场景。
2.4 复杂元素精准识别
针对OCR领域的难点场景,LightOnOCR-2-1B进行了专项优化:
数学公式:完美识别LaTeX/KaTeX格式公式,通过专属的KaTeX奖励机制优化渲染效果,确保输出公式可直接复制使用;
多栏布局:自动识别报纸、学术论文的分栏结构,按正常阅读顺序输出文本,避免出现内容错乱;
表格内容:精准还原复杂统计表格的行列关系,包括合并单元格、嵌套表格等特殊结构,识别后可直接转换为Excel等格式;
嵌入式图像:新增边界框预测功能,可输出文档中插图的标准化坐标,实现图文精准对齐,方便后续图文分离与切片处理。
2.5 强多语言适配能力
LightOnOCR-2-1B具备优秀的多语言识别能力,尤其优化了法语及其他欧洲语言的支持,可精准识别这些语言中的特殊字符、重音符号等。同时,其对英语、德语等主流拉丁脚本语言的识别准确率接近100%,满足跨国企业、多语言文档归档等场景的需求。
2.6 轻量化优化:支持词汇剪枝
为进一步提升推理效率,该模型支持词汇表剪枝功能,可将原始15万规模的词汇表剪枝至3.2万,在不显著损失性能的前提下(保留96%的基础性能,拉丁脚本语言),推理速度再提升11.6%,适配低配置硬件环境(如普通GPU、CPU)的部署需求。
三、技术细节
LightOnOCR-2-1B的优秀表现源于其合理的架构设计、优化的训练策略及创新的技术方案,具体技术细节如下:
3.1 核心架构设计
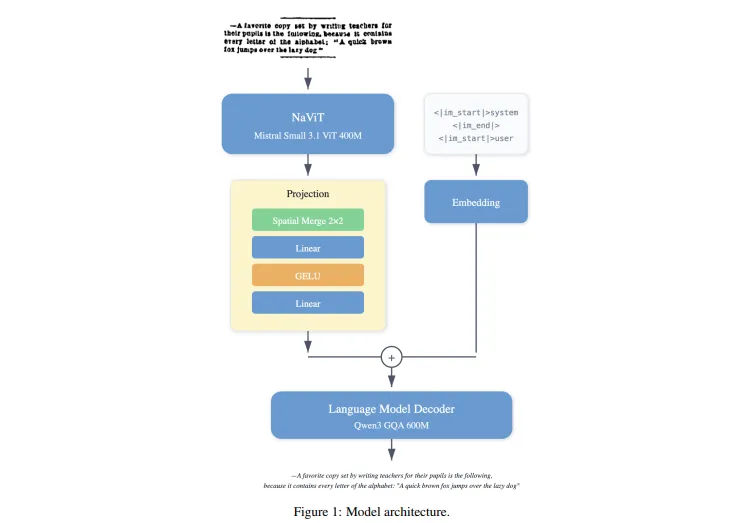
模型整体由“视觉编码器+多模态投影器+语言解码器”三部分组成,各模块分工明确且高效协同:
| 模块名称 | 核心组件 | 参数规模 | 核心作用 |
|---|---|---|---|
| 视觉编码器 | 基于Mistral-Small-3.1的ViT(视觉Transformer) | 40亿参数 | 将输入图像(或PDF页面)转换为视觉特征令牌,采用2×2空间合并策略减少令牌数量,兼顾高分辨率输入与计算效率 |
| 多模态投影器 | 两层MLP(多层感知机) | 集成于整体架构 | 实现视觉特征与语言特征的精准对齐,解决跨模态信息融合的核心问题 |
| 语言解码器 | 基于Qwen3的GQA(分组查询注意力)架构 | 60亿参数 | 将对齐后的多模态特征转换为结构化文本输出,支持Markdown格式生成与多语言解码 |
此外,模型初始化时复用了Mistral-Small-3.1和Qwen3的预训练权重,不仅降低了训练成本,还继承了两款模型强大的视觉表征能力和多语言处理能力。
3.2 训练策略优化(相较于LightOnOCR-1)
LightOnOCR-2-1B在训练数据、配置及优化方法上进行了全方位升级,具体如下:
3.2.1 训练数据升级
训练数据规模从1700万页扩展至4300万页(增长2.5倍),重点强化了复杂场景数据的覆盖:新增大量扫描件、含复杂公式的科学PDF、法语文档及多栏布局文档。数据标注方面,采用更强的教师模型Qwen3-VL-235B-A22B-Instruct生成标注,并通过nvpdftex驱动的arXiv文档解析技术实现像素级对齐标注,确保标注精度;同时优化LaTeX格式归一化,提升公式识别的一致性。
3.2.2 训练配置优化
将最大图像长边分辨率从1024px提升至1540px,有效提升小文本、密集公式及模糊扫描件的识别精度;引入多样化数据增强策略,包括位图损坏、随机旋转、仿射变换等,增强模型的鲁棒性;同时加入空白页样本训练,减少模型出现循环生成、文本幻觉等问题。
3.2.3 强化学习优化(RLVR)
创新引入基于验证反馈的强化学习(RLVR)技术,针对OCR常见失效模式设计专属奖励机制:一是KaTeX奖励,专门评估数学公式的渲染有效性,引导模型输出规范可渲染的LaTeX代码;二是压缩奖励,惩罚模型的重复生成行为,使重复率降低50%以上,解决小模型易陷入死循环的通病;三是IoU导向奖励,针对边界框预测任务,以交并比(IoU)为核心评估指标,提升图像定位精度。
3.2.4 模型融合技术
采用checkpoint平均和任务算术合并(Task-Arithmetic Merging)两种融合技术,在OCR识别质量与边界框检测精度之间实现可控权衡。无需额外训练,即可根据实际需求(如侧重识别精度或侧重定位精度)调整模型性能,提升模型的适配性。
3.3 关键技术亮点
端到端架构:跳过传统OCR的多阶段流程,直接实现“像素→结构化文本”的映射,减少组件耦合带来的误差累积;
空间合并策略:通过2×2补丁合并减少视觉令牌数量,在输入分辨率提升至1540px的同时,控制计算量增长,平衡精度与效率;
词汇剪枝技术:在保留核心词汇的前提下精简词汇表,实现推理速度与性能的平衡,适配低算力环境;
专属评估基准:构建LightOnOCR-bbox-bench边界框评估基准,填补端到端OCR模型图像定位评估的行业空白。
四、应用场景
LightOnOCR-2-1B凭借高精度、高效率、低成本及强兼容性的优势,可广泛应用于多个行业及场景,具体如下:
4.1 学术科研领域
适配场景:arXiv等平台学术论文的数字化处理、科研文献库构建、公式提取与整理;
核心价值:精准识别多栏布局、复杂数学公式,输出标准化Markdown文本,方便科研人员快速提取文献核心内容、整理公式库,提升文献阅读与研究效率。例如,科研团队可批量处理领域内的旧论文扫描件,快速构建可检索的文献数据库。
4.2 企业办公场景
适配场景:企业合同、发票、报表等文档的归档与检索、财务票据识别、员工手册数字化;
核心价值:高速处理大规模文档(5.71页/秒),低成本实现文档结构化归档,支持表格内容精准提取(可直接导入Excel),提升办公自动化水平。例如,财务部门可批量识别发票信息,自动提取金额、税率等关键数据,减少手动录入误差。
4.3 图书与出版行业
适配场景:古籍、旧书的数字化修复与归档、图书转码(纸质书→电子文档)、多语言书籍翻译前的文本提取;
核心价值:精准识别模糊、褪色的扫描件,支持多语言文本识别,输出结构化文本,降低图书数字化的成本与周期。例如,图书馆可利用该模型批量处理馆藏旧书,快速构建数字图书馆资源。
4.4 教育与培训行业
适配场景:教材、教辅资料的数字化、试题库构建、学生作业(印刷体)的自动批改预处理;
核心价值:精准识别教材中的公式、表格、知识点层级,输出结构化文本,方便教师快速构建试题库、整理教学资料,提升教学效率。
4.5 开发者与二次开发
适配场景:OCR相关应用开发(如文档管理工具、扫描APP)、企业定制化OCR解决方案搭建;
核心价值:开源免费的模型权重与清晰的API接口,支持开发者快速集成OCR功能,结合自身需求进行二次优化(如适配特定行业文档、新增语言支持),降低开发成本。
五、使用方法
LightOnOCR-2-1B提供多种使用方式,包括在线Demo体验、Python代码调用(原生Transformers库)及vLLM加速部署,满足不同用户的需求,具体操作步骤如下:
5.1 在线Demo体验(零代码,快速验证)
官方在Hugging Face平台提供了可直接使用的在线Demo,无需安装任何软件,上传文件即可体验:
访问Demo地址:https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo;
点击“上传文件”按钮,选择需要识别的PDF文档或图像文件(支持JPG、PNG等格式);
等待几秒后,页面将显示识别结果(默认Markdown格式),可直接复制、编辑或下载。
5.2 Python代码调用(基础部署,适用于小规模任务)
通过Hugging Face Transformers库调用模型,需先安装相关依赖,具体步骤如下:
5.2.1 环境准备
安装必要的Python库(建议使用Python 3.8及以上版本):
uv pip install git+https://github.com/huggingface/transformers uv pip install pillow pypdfium2 torch
说明:transformers用于加载模型与处理器,pillow用于图像处理,pypdfium2用于PDF文件解析,torch为PyTorch深度学习框架(需根据硬件配置安装对应版本,支持CPU、GPU、MPS)。
5.2.2 核心代码示例
import torch
from transformers import LightOnOcrForConditionalGeneration, LightOnOcrProcessor
# 设备选择:优先使用MPS(Apple Silicon),其次GPU(CUDA),最后CPU
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float32 if device == "mps" else torch.bfloat16 # 数据类型适配
# 加载模型与处理器(从Hugging Face自动下载)
model = LightOnOcrForConditionalGeneration.from_pretrained(
"lightonai/LightOnOCR-2-1B",
torch_dtype=dtype
).to(device)
processor = LightOnOcrProcessor.from_pretrained("lightonai/LightOnOCR-2-1B")
# 输入配置(支持本地图像、在线图像URL、PDF页面)
# 示例1:处理在线图像
url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_ocr/resolve/main/SROIE-receipt.jpeg"
conversation = (
{"role": "user", "content": ({"type": "image", "url": url})}
)
# 示例2:处理本地PDF(需先通过pypdfium2转换为图像,此处省略转换步骤)
# pdf_path = "your_local_pdf.pdf"
# 转换PDF页面为图像后,替换上述conversation中的image内容
# 预处理输入
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
)
# 设备与数据类型适配
inputs = {k: v.to(device=device, dtype=dtype) if v.is_floating_point() else v.to(device) for k, v in inputs.items()}
# 生成识别结果(可调整max_new_tokens控制输出长度)
output_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids = output_ids[0, inputs["input_ids"].shape[1]:] # 截取生成部分
output_text = processor.decode(generated_ids, skip_special_tokens=True)
# 打印结果(Markdown格式)
print("识别结果:")
print(output_text)5.3 vLLM加速部署(大规模任务,极致效率)
对于大规模文档处理场景,建议使用vLLM推理框架部署,进一步提升吞吐量,具体步骤如下:
5.3.1 环境准备
安装vLLM及相关依赖:
pip install vllm transformers pillow pypdfium2
5.3.2 启动vLLM服务
vllm serve lightonai/LightOnOCR-2-1B \
--limit-mm-per-prompt '{"image": 1}' \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching5.3.3 代码调用服务
import base64
import requests
import pypdfium2 as pdfium
import io
# 服务端点与模型名称
ENDPOINT = "http://localhost:8000/v1/chat/completions"
MODEL = "lightonai/LightOnOCR-2-1B"
# 本地PDF文件转换为图像(示例:转换第1页)
pdf_path = "your_large_document.pdf"
pdf = pdfium.PdfDocument(pdf_path)
page = pdf[0] # 选择第1页
img = page.render(scale=2.0).to_pil() # 渲染为PIL图像
# 图像编码为base64(vLLM服务要求格式)
buffer = io.BytesIO()
img.save(buffer, format="PNG")
img_base64 = base64.b64encode(buffer.getvalue()).decode("utf-8")
# 构建请求体
payload = {
"model": MODEL,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"}
}
]
}
],
"max_tokens": 2048,
"temperature": 0.2,
"top_p": 0.9
}
# 发送请求并获取结果
response = requests.post(ENDPOINT, json=payload)
result = response.json()
output_text = result["choices"][0]["message"]["content"]
# 打印或保存结果
print("识别结果:")
print(output_text)5.4 输出格式说明
默认输出为标准Markdown格式,核心元素的输出规则如下:
标题:自动识别文档标题层级(H1-H6),对应Markdown的
#-######;表格:还原表格结构,输出
| 列1 | 列2 |格式的Markdown表格;数学公式:行内公式用
$...$包裹,块级公式用$$...$$包裹(支持KaTeX渲染);嵌入式图像:输出
x1,y1,x2,y2格式,其中x1,y1,x2,y2为标准化坐标(范围0-1000);代码块:保留代码缩进与语法,用
包裹并标注语言类型(如python)。

六、常见问题解答(FAQ)
6.1 模型支持哪些输入格式?
支持PDF文档(.pdf)、图像文件(.jpg、.png、.jpeg、.tiff),其中PDF文件会自动转换为图像进行处理;支持单页及多页PDF,多页文件需逐页处理(可通过循环遍历实现批量识别)。
6.2 非拉丁脚本语言(如中文、阿拉伯语)识别效果如何?
模型训练数据以拉丁脚本语言(英语、法语、德语等)为主,非拉丁脚本语言(如中文、阿拉伯语、日语)的识别精度会有所下降,且词汇剪枝后可能出现令牌数量膨胀问题。若需处理非拉丁脚本文档,建议使用未剪枝的完整词汇表模型(151k词汇),并自行补充对应语言的训练数据进行微调。
6.3 模型是否支持手写体识别?
不支持。LightOnOCR-2-1B的训练数据以印刷体、排版文本为主,未针对手写体进行优化,手写文本(尤其是草书、自由手写体)的识别准确率极低,不建议用于手写体场景。
6.4 如何提升低质量扫描件的识别精度?
可通过以下方式优化:
预处理图像:提升扫描分辨率(建议≥300 DPI)、去除噪声(如通过PS或OpenCV进行二值化、去模糊处理);
调整推理参数:增大
scale渲染系数(如vLLM部署时scale=2.0),提升图像清晰度;禁用词汇剪枝:使用完整词汇表模型,避免低质量文本因令牌缺失导致识别误差。
6.5 模型部署需要什么硬件配置?
最小配置:CPU(8核以上)+ 16GB内存(支持小规模测试,单页处理时间约10-20秒);
推荐配置:GPU(NVIDIA RTX 3090/4090或A10G,≥24GB显存),单页处理时间≤1秒;
大规模部署:NVIDIA H100 80GB GPU,吞吐量达5.71页/秒,适合百万级文档处理。
6.6 如何自定义输出格式(如JSON、Excel)?
模型默认输出Markdown格式,可通过以下方式转换为其他格式:
借助第三方库(如
markdown-it-py)解析Markdown,提取标题、表格、公式等结构化数据;表格数据可通过
pandas库的read_markdown函数直接转换为DataFrame,再导出为Excel/Csv;二次开发:基于模型输出的Markdown,编写格式转换脚本,适配自定义JSON结构。
6.7 模型是否支持批量处理多页PDF?
支持。需通过代码实现批量处理逻辑:遍历PDF的每一页,逐页转换为图像并调用模型识别,最后合并所有页面的输出结果。示例代码可参考6.3.3节,通过循环遍历pdf对象的所有页面实现。
七、相关链接
模型权重(Hugging Face):https://huggingface.co/lightonai/LightOnOCR-2-1B
在线Demo:https://huggingface.co/spaces/lightonai/LightOnOCR-1B-Demo
八、总结
LightOnOCR-2-1B作为一款10亿参数的开源端到端OCR模型,通过创新的架构设计、优化的训练策略及高效的推理方案,在精度、效率与成本之间实现了完美平衡,不仅在权威基准测试中取得SOTA性能,超越了众多大参数模型,还具备结构化输出、复杂元素识别、多语言适配等实用功能,同时支持轻量化部署与二次开发。其开源的模型权重、数据集及评估基准,为开发者和企业提供了低成本、高性能的OCR解决方案,可广泛应用于学术、办公、出版、教育等多个领域,有效解决传统OCR工具流程复杂、成本高昂、适配性差等痛点,成为大规模文档数字化与结构化处理的优选工具。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/lightonocr-2-1b.html





