LongCat-Audio-Codec:美团开源音频编解码方案,为 Speech LLM 提供超低比特率高保真令牌生成与解码
一、LongCat-Audio-Codec是什么?
LongCat-Audio-Codec是由美团LongCat团队开发并开源的音频处理工具,核心定位是为语音大语言模型(Speech LLM) 提供端到端的“编码-解码”支持,本质是一套“音频令牌生成与还原”系统。
它的核心工作逻辑是:将输入音频拆解为两类关键信息——语义令牌(描述音频的核心含义,如语音中的文字内容、情感倾向)和声学令牌(描述音频的物理特征,如音调、音色、节奏),两类令牌并行生成后,可用于Speech LLM的输入处理(如语音理解、语音生成任务);后续通过解码器,又能从这两类令牌中重建出高质量音频,且整个过程能在超低比特率(比特率越低,数据传输/存储成本越低)下实现“高保真”(音频清晰度、可懂度接近原始音频)。
从开发背景来看,当前Speech LLM在处理音频时,常面临“高音质与低资源消耗”的矛盾——若保留高音质,需传输/处理大量音频数据,增加带宽与算力成本;若压缩数据(降低比特率),又会导致音质劣化。LongCat-Audio-Codec正是为解决这一矛盾而生,同时通过“低延迟”“超分辨率”等设计,进一步拓展了在实际场景中的适用性。
二、核心功能特色
LongCat-Audio-Codec的功能设计围绕“适配Speech LLM”“平衡质量与成本”“提升实际场景可用性”三个核心目标展开,具体包含四大特色:
1. 超低比特率下的高保真音频重建
这是该方案最核心的优势之一。作为音频编码器,它能在“极低比特率”(文档未明确具体数值,但通过对比演示可知远低于传统音频编码格式如MP3)下,依然实现“高可懂度”的音频重建——即便是压缩后的音频,听众仍能清晰识别语音内容、情感,且无明显杂音或失真。
这一特性的价值在于:大幅降低Speech LLM处理音频时的数据传输与存储成本。例如,在远程语音交互场景中,使用该方案编码的音频,可在5G/4G甚至物联网(IoT)的低带宽网络下快速传输,同时保证Speech LLM能准确解析语音含义,且重建后的音频质量不影响用户体验。
2. 低帧率并行提取语义与声学令牌
传统音频令牌生成工具常需较高帧率(如每秒数十帧),导致计算量较大;而LongCat-Audio-Codec以16.6Hz的低帧率(即每秒仅生成约17组令牌),并行完成“语义令牌”与“声学令牌”的提取——两类令牌同步生成,无需先后等待,既降低了计算延迟,也减少了算力消耗。
更灵活的是,它支持声学码本配置自定义:开发者可根据下游任务需求,调整声学码本的数量(如1个、3个)——码本数量越多,声学细节保留越丰富(音质越好),但比特率与计算成本也越高;反之则成本更低,适合对音质要求不高的轻量化场景(如语音指令识别)。
3. 低延迟流式解码器
针对实时语音交互场景(如智能音箱、在线会议),该方案配备了专门设计的流式解码器——与传统“需等待完整音频数据才能解码”的模式不同,它仅需“少量未来信息”(即无需等到音频结束,接收部分数据即可开始解码),就能实时输出高质量音频,延迟极低。
例如,在在线会议中,当发言人说完一句话的前半段时,解码器已能基于已接收的音频片段开始解码,听众几乎无需等待就能听到重建后的语音,避免了“说话后卡顿1-2秒才出声音”的问题,提升实时交互体验。
4. 集成音频超分辨率能力
LongCat-Audio-Codec的解码器内置音频超分辨率处理模块——即能生成“采样率高于原始输入”的音频。例如,若输入的是16kHz(常见语音采样率)的低质量音频,解码器可输出24kHz(更高清晰度,接近音乐级采样率)的音频,且音质细节(如语音中的呼吸声、背景音层次感)会显著提升。
这一特性尤其适合“旧音频优化”场景:例如,将早期录制的16kHz语音数据(如历史会议录音、旧语音文件)输入该方案,通过超分辨率处理后,可得到更高质量的音频,再用于Speech LLM的训练或推理,能提升模型对语音细节的识别精度。
为更直观展示功能特色与应用场景的对应关系,下表整理了核心功能、优势及典型用途:
| 核心功能 | 核心优势 | 典型应用场景 |
|---|---|---|
| 超低比特率高保真重建 | 降低数据传输/存储成本,保留音频核心质量 | 低带宽远程语音交互、IoT设备语音传输 |
| 低帧率并行令牌提取 | 减少计算延迟与算力消耗,支持灵活配置 | Speech LLM实时输入处理、轻量化语音任务 |
| 低延迟流式解码 | 无需等待完整音频,实时输出重建结果 | 智能音箱、在线会议、实时语音翻译 |
| 音频超分辨率 | 提升原始音频采样率与音质细节 | 旧音频优化、高质量语音生成 |

三、关键技术细节
要理解LongCat-Audio-Codec的实现逻辑,需从“核心组件”“技术参数”“关键技术”三个维度拆解:
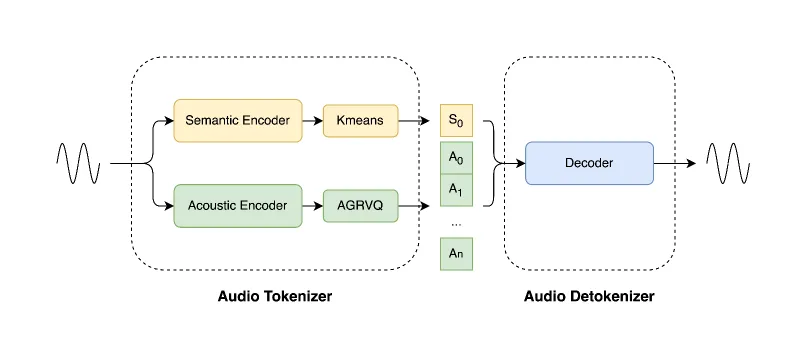
1. 核心组件构成
该方案的技术架构围绕“编码-解码”两大环节展开,包含四大核心组件,各组件功能与技术亮点如下表所示:
| 核心组件 | 功能描述 | 技术亮点 |
|---|---|---|
| 语义编码器(Semantic Encoder) | 提取音频中的语义令牌,反映语音核心含义 | 需配合CMVN(倒谱均值方差归一化)系数使用,提升语义提取准确性;采用Kmeans量化技术优化令牌生成效率 |
| 声学编码器(Acoustic Encoder) | 提取音频中的声学令牌,反映音调、音色等特征 | 支持多码本配置(1-3个),可灵活平衡音质与成本 |
| 流式解码器(Streaming Detokenizer) | 将语义+声学令牌重建为音频,支持实时输出 | 仅需少量未来信息,延迟低;适配16k/24k两种采样率 |
| 超分辨率模块(Super-Resolution Module) | 提升重建音频的采样率与音质细节 | 集成于解码器中,无需额外调用独立工具;支持从16k提升至24k |
2. 关键技术参数
技术参数决定了方案的硬件适配性与场景兼容性,核心参数如下:
令牌帧率:固定16.6Hz,每秒生成约17组令牌;
支持采样率:编码器输入支持16kHz/24kHz音频,解码器可输出对应或更高采样率(如16k输入→24k输出);
码本配置:语义码本固定1个(核心语义不可删减),声学码本可配置1-3个(根据需求选择);
音频长度限制:当前版本仅支持单通道音频,且输入音频长度需≤30秒(超过需手动分割为30秒内片段);
硬件依赖:基于PyTorch框架开发,支持CPU/GPU运行(GPU需适配PyTorch的CUDA版本,CPU适合轻量化场景)。
3. 核心技术亮点
CMVN归一化:语义编码器需加载专门的CMVN系数文件(LongCatAudioCodecencodercmvn.npy),通过对音频倒谱特征进行“均值-方差归一化”,减少环境噪音、设备差异对语义提取的干扰,让语义令牌更稳定。
并行令牌生成:语义与声学编码器独立且同步运行,避免传统“先语义后声学”的串行延迟,提升整体处理速度,更适配Speech LLM的实时推理需求。
多采样率解码器设计:提供两类解码器(16k专用、24k专用),且24k解码器细分“2码本”“4码本”版本——2码本版本(1语义+1声学)适合超低比特率场景,4码本版本(1语义+3声学)适合高质量场景,覆盖不同需求。
四、典型应用场景
基于上述功能与技术特性,LongCat-Audio-Codec的应用场景主要围绕“Speech LLM生态”及“音频质量优化”展开,具体可分为四大类:
1. Speech LLM后端支持
这是该方案的核心目标场景。Speech LLM的核心任务包括“语音理解”(如将语音转为文本、识别意图)与“语音生成”(如基于文本生成语音),而LongCat-Audio-Codec可在两个环节发挥作用:
语音理解环节:将输入语音编码为“语义+声学令牌”,令牌数据量远小于原始音频,可快速输入Speech LLM,减少模型的输入处理压力;同时,声学令牌能提供语音的情感、音色信息,辅助LLM更精准理解语义(如区分“开心的‘好的’”与“不耐烦的‘好的’”)。
语音生成环节:Speech LLM生成文本或语义指令后,解码器可基于这些信息(结合声学令牌配置),快速重建出高保真语音,且支持实时流式输出(如LLM生成一句语音的指令,解码器可边接收指令边输出声音,无需等待完整指令)。
例如,在“智能客服Speech LLM”中,用户的语音通过该方案编码为令牌后,快速传输给LLM;LLM解析意图并生成回复指令,再通过解码器实时生成客服语音,整个过程延迟低、带宽消耗小,且语音质量清晰。
2. 低带宽音频传输
在网络带宽有限的场景(如偏远地区的IoT设备、低资费移动网络),传统音频格式(如MP3、WAV)传输速度慢、易卡顿,而LongCat-Audio-Codec的“超低比特率”特性可解决这一问题:
编码后的音频令牌数据量极小,能在低带宽下快速传输;
接收端通过解码器重建音频,虽比特率低,但音质仍能满足“可懂度”需求(如远程监控设备的语音传输、物联网传感器的语音报警)。
例如,农业物联网中的“语音监控设备”,可通过该方案将现场语音(如农机故障报警、人员喊话)编码后,通过低带宽网络传输至后台,后台解码后清晰识别语音内容,无需担心卡顿或音质丢失。
3. 音频质量优化与修复
针对低质量音频(如旧录音、低采样率语音文件),该方案的“超分辨率能力”可实现质量提升:
将16kHz的低质量音频输入编码器,解码器可输出24kHz的音频,采样率提升的同时,音质细节(如背景噪音过滤、语音层次感)也会优化;
对于“说话人未在训练集中”的音频(如小众方言使用者的语音),4码本版本的24k解码器(LongCatAudioCodecdecoder24k4codebooks)仍能保持较好的重建质量(2码本版本可能因训练数据限制导致质量下降)。
例如,档案馆的“历史语音档案”(多为16kHz低采样率),通过该方案处理后,可转化为24kHz的高清音频,便于长期保存与后续研究使用。
4. 批量音频令牌提取
文档中提到的“Batch Token Extraction API”支持对批量音频文件进行令牌提取,适合“大规模音频数据预处理”场景:
开发者可通过调用API,一次性对成百上千个音频文件(如语音数据集、用户语音记录)进行编码,生成语义+声学令牌;
生成的令牌可用于Speech LLM的训练数据预处理(减少训练数据量,提升训练效率),或用于音频数据库的索引建立(基于令牌快速检索相似音频)。
例如,AI公司在训练“方言Speech LLM”时,可通过该API批量处理方言语音数据集,生成令牌后用于模型训练,既减少数据存储成本,也提升训练时的数据读取速度。
五、使用方法
LongCat-Audio-Codec的使用流程分为“环境安装→模型准备→运行演示→自定义配置”四步,文档提供了完整的脚本与参数说明,即使是非专业开发者也能快速上手。
1. 环境安装(Windows/macOS/Linux通用)
该方案基于Python与PyTorch开发,需先配置运行环境,步骤如下:
步骤1:创建conda环境
conda是Python的环境管理工具,可避免依赖版本冲突。打开终端(Windows用Anaconda Prompt,macOS/Linux用终端),执行以下命令:
# 创建名为LongCat-Audio-Codec的环境,指定Python版本为3.10(文档推荐版本) conda create -n LongCat-Audio-Codec python=3.10 # 激活该环境(后续所有操作均需在激活状态下执行) conda activate LongCat-Audio-Codec
步骤2:安装PyTorch与torchaudio
PyTorch是深度学习框架,torchaudio用于音频处理。文档提供的版本为示例,需根据硬件配置调整(如GPU用户需安装支持CUDA的版本):
# 示例:安装PyTorch 2.7.1与对应torchaudio(CPU版本,适合无GPU设备) pip install torch==2.7.1 torchaudio==2.7.1 # GPU用户需替换为CUDA版本(如CUDA 12.4,需参考PyTorch官网:https://pytorch.org/) # pip3 install torch==2.7.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu124
步骤3:安装其他依赖
项目的依赖清单已整理在requirements.txt中,执行以下命令一键安装:
pip install -r requirements.txt
2. 模型准备(核心步骤,需下载预训练模型)
该方案需加载预训练的“编码器”“解码器”模型才能运行,模型需从Hugging Face下载,具体步骤如下:
步骤1:下载模型文件
文档提供了5类核心模型,涵盖编码器、解码器及归一化系数,下载链接与用途如下表所示:
| 模型名称 | 下载链接 | 用途说明 |
|---|---|---|
| LongCatAudioCodec_encoder | Hugging Face | 编码器权重,包含语义编码器与声学编码器 |
| LongCatAudioCodecencodercmvn | Hugging Face | CMVN系数文件,语义编码器必需 |
| LongCatAudioCodecdecoder16k4codebooks | Hugging Face | 16k采样率解码器,支持1语义+3声学码本 |
| LongCatAudioCodecdecoder24k2codebooks | Hugging Face | 24k采样率解码器,支持1语义+1声学码本(仅适配部分说话人) |
| LongCatAudioCodecdecoder24k4codebooks | Hugging Face | 24k采样率解码器,支持1语义+3声学码本(通用高音质) |
注:Hugging Face链接需访问项目仓库(https://github.com/meituan-longcat/LongCat-Audio-Codec)中的“Model Preparation”部分获取,或直接搜索“meituan-longcat/LongCat-Audio-Codec”进入Hugging Face项目页面下载。
步骤2:配置模型路径
下载后的模型文件(.pt格式,CMVN为.npy格式)需放在指定路径,否则脚本无法识别,有两种配置方式:
方式1:默认路径(推荐,适合新手)
将所有下载的模型文件放入项目根目录下的ckpts文件夹中(若没有ckpts文件夹,需手动创建)。最终项目结构需严格如下(缺一不可):
LongCat-Audio-Codec/ # 项目根目录 ├── ckpts/ # 模型文件夹 │ ├── LongCatAudioCodec_decoder_16k_4codebooks.pt │ ├── LongCatAudioCodec_decoder_24k_2codebooks.pt │ ├── LongCatAudioCodec_decoder_24k_4codebooks.pt │ ├── LongCatAudioCodec_encoder.pt │ └── LongCatAudioCodec_encoder_cmvn.npy ├── configs/ # 配置文件夹(项目自带,无需修改) │ ├── LongCatAudioCodec_decoder_16k_4codebooks.yaml │ └── ...(其他配置文件) ├── inference.py # 核心推理脚本(项目自带) └── run_inference.sh # 演示脚本(项目自带)
方式2:自定义路径(适合进阶用户)
若需将模型放在其他文件夹(如/home/user/models/),需修改configs文件夹中的对应.yaml配置文件,将ckpt_path参数改为自定义路径。例如,修改24k_2codebooks解码器的配置文件:
# 原始配置(默认路径) ckpt_path: 'ckpts/LongCatAudioCodec_decoder_24k_2codebooks.pt' # 修改后配置(自定义路径) ckpt_path: '/home/user/models/LongCatAudioCodec_decoder_24k_2codebooks.pt'
3. 运行演示(一键体验核心功能)
项目提供run_inference.sh脚本,可一键执行“音频编码-解码”演示,步骤如下:
步骤1:执行演示脚本
在项目根目录下,激活conda环境后,执行以下命令:
bash ./run_inference.sh
步骤2:查看演示结果
脚本会自动处理demos/org文件夹中的预设音频文件(项目自带,包含不同情感、场景的语音),并将重建后的音频输出到demo_audio_output/文件夹中。输出文件命名规则如下:
xxx_reconstructed_16k.wav:用16k解码器重建的音频;xxx_reconstructed_24k.wav:用24k解码器重建的音频。
通过对比原始音频(demos/org)与重建音频(demo_audio_output),可直观感受该方案的音质保留效果。
步骤3:理解演示的两大功能
该脚本实际演示了LongCat-Audio-Codec的两个核心能力:
多速率合成:同一组令牌(由编码器生成),可通过16k/24k两种解码器生成不同采样率的音频,展示“令牌复用性”;
批量令牌提取:脚本底层调用了“批量令牌提取API”,可一次性处理多个音频文件,展示“大规模处理能力”。
4. 自定义配置(根据需求调整参数)
若需处理自己的音频文件,或调整码本数量、输出路径等,可通过两种方式自定义:
方式1:修改演示脚本(run_inference.sh)
用文本编辑器打开run_inference.sh,修改以下关键参数:
AUDIO_FILES:指定自己的音频文件路径,多个文件用空格分隔,例如:
AUDIO_FILES="path/to/your/audio1.wav \ path/to/your/audio2.wav"
NACOUSTICCODEBOOKS:调整声学码本数量(1-3),例如:
# 用2个声学码本(总码本数=2+1=3),平衡质量与成本 N_ACOUSTIC_CODEBOOKS=2
修改后保存,再次执行bash ./run_inference.sh即可。
方式2:直接调用inference.py(全自定义)
inference.py是核心推理脚本,支持更多参数配置。通过--help查看所有参数:
python inference.py --help
常见自定义命令示例(处理单个音频,用4码本24k解码器,输出到自定义文件夹):
python inference.py \ --encoder_config "configs/LongCatAudioCodec_encoder.yaml" \ --decoder16k_config "configs/LongCatAudioCodec_decoder_16k_4codebooks.yaml" \ --decoder24k_config "configs/LongCatAudioCodec_decoder_24k_4codebooks.yaml" \ --output_dir "my_custom_output" \ # 自定义输出文件夹 --n_acoustic_codebooks 3 \ # 3个声学码本(高音质) --audio_files "path/to/my_audio.wav" # 自己的音频文件
注:调用inference.py时,需确保所有--xxx_config参数指向正确的.yaml文件,且--audio_files指向的音频为“单通道、≤30秒、16k/24k采样率”(否则会报错)。
六、常见问题解答(FAQ)
Q1:安装PyTorch时提示“版本不兼容”或“无法找到指定版本”?
A1:文档中的PyTorch版本(2.7.1)仅为示例,需根据Python版本、操作系统、硬件(是否有GPU)调整。解决方案:
访问PyTorch官网(https://pytorch.org/),根据页面提示选择“OS”“Package”“CUDA版本”,生成对应安装命令;
例如,Python 3.10、Windows 10、无GPU的安装命令为:
pip3 install torch==2.7.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cpu。
Q2:执行pip install -r requirements.txt时提示“依赖包安装失败”?
A2:可能是网络问题或Python版本不匹配(需3.10)。解决方案:
更换国内PyPI源,如使用阿里云源:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/;若仍失败,可手动安装失败的包,例如
pip install 包名==版本号(版本号参考requirements.txt中的记录)。
Q3:运行脚本时提示“找不到ckpt文件”或“ModelNotFoundError”?
A3:模型路径配置错误,解决方案:
确认模型文件已下载完整(5类模型缺一不可,且后缀为.pt或.npy);
若用默认路径,检查
ckpts文件夹是否在项目根目录下,且文件名与配置文件(.yaml)中的ckpt_path完全一致(区分大小写,如“decoder_24k”不能写成“decoder24k”);若用自定义路径,确认.yaml文件中的
ckpt_path已改为实际路径,且路径中无中文或特殊字符(如空格、括号)。
Q4:使用LongCatAudioCodecdecoder24k2codebooks时,重建音频质量差(有杂音、失真)?
A4:该解码器是在“有限说话人数据集”上微调的,对“未包含在训练集中的说话人”音频,质量会下降。解决方案:
更换为LongCatAudioCodecdecoder24k4codebooks(通用高音质版本);
若需超低比特率,可尝试调整声学码本数量(如NACOUSTICCODEBOOKS=1),但音质可能仍不如4码本版本。
Q5:输入音频超过30秒,脚本报错“Audio length exceeds 30s”?
A5:当前版本限制音频长度≤30秒,解决方案:
用音频处理工具(如Audacity、FFmpeg)将长音频分割为≤30秒的片段;
分割时需保持“单通道、16k/24k采样率”,否则分割后的音频仍无法处理。
Q6:重建后的音频没有声音,或声音极小?
A6:可能是输入音频格式错误或参数配置问题,解决方案:
检查输入音频是否为“单通道”(当前版本不支持立体声),可通过FFmpeg转换:
ffmpeg -i input.wav -ac 1 output.wav;确认
n_acoustic_codebooks参数设置正确(1-3,不能为0);检查输入音频的采样率是否为16k/24k,非该采样率需转换(如FFmpeg命令:
ffmpeg -i input.wav -ar 16000 output_16k.wav)。
七、相关链接
八、总结
LongCat-Audio-Codec是美团LongCat团队针对“Speech LLM音频处理需求”开源的优质方案,核心价值在于平衡“超低比特率”与“高保真音频”,同时通过低延迟流式解码、超分辨率等设计,提升了在实时交互、低带宽、音频优化等场景的实用性。其技术架构清晰(编码-解码分离,支持灵活配置),使用流程简单(提供一键演示脚本、详细参数说明),且基于MIT许可证开放,降低了开发者的使用门槛。尽管当前版本存在“单通道限制”“30秒音频长度限制”等不足,但已能满足Speech LLM后端支持、低带宽传输、批量音频处理等核心场景需求,适合AI开发者、语音技术研究人员、需要音频编解码工具的企业用于技术研发或产品落地。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/longcat-audio-codec.html





