MiniMind:个人可部署的超轻量开源大语言模型训练与部署工具
一、MiniMind是什么?
MiniMind是一个旨在拉低大语言模型(LLM)学习与实践门槛的开源项目,核心目标是让普通用户通过“3元GPU服务器成本+2小时单卡训练”,从0构建并部署仅25.8M参数的超轻量LLM。项目开源了全流程技术栈,包括模型结构(Dense+MoE)、分词器训练、预训练(Pretrain)、监督微调(SFT)、LoRA、DPO强化学习、模型蒸馏的PyTorch原生代码,无依赖第三方抽象接口,同时兼容transformers、llama.cpp、vllm等主流框架,支持单机单卡/多卡训练与轻量化部署。此外,项目还扩展了视觉多模态能力(MiniMind-V)与推理模型(蒸馏DeepSeek-R1),既是LLM初学者理解底层原理的教程,也是个人开发者快速实现轻量AI应用的工具。
MiniMind诞生的核心背景是“打破LLM的‘黑盒子’门槛”——传统大模型(如GPT-3、Qwen)动辄数百亿参数,需高配置硬件才能训练;第三方框架(如transformers+trl)虽简化流程,却封装了底层实现,导致开发者难以理解核心逻辑;同时互联网上优质LLM入门资源稀缺,付费课程常存在内容漏洞。
为解决这些问题,MiniMind以“大道至简”为理念,聚焦“超轻量、低成本、全透明”三大核心:
超轻量:最小模型仅25.8M参数(0.02B),体积为GPT-3的1/7000,普通个人GPU(如RTX 3090)即可轻松训练与部署;
低成本:单卡RTX 3090训练基础对话模型(MiniMind-Zero)仅需2小时,GPU服务器租用成本约3元人民币;
全透明:所有核心算法(如LoRA、DPO、蒸馏)均基于PyTorch原生重构,不依赖第三方库抽象接口,代码可逐行追溯,帮助开发者理解LLM从“数据输入”到“模型输出”的完整逻辑。
截至2025年4月,MiniMind已迭代至V2系列,完成多个型号模型的预训练(如26M的MiniMind2-small、145M的MiniMind2-MoE),并扩展至视觉多模态领域(MiniMind-V),同时开源了训练所需的全量数据集,避免用户重复预处理工作。
二、MiniMind的功能特色
MiniMind的核心价值在于“低门槛+全流程+强兼容”,具体功能特色可分为以下5点:
1. 极致轻量,低成本易上手
参数规模可控:模型参数从26M到145M不等,最小模型推理仅占用0.5GB内存,适配笔记本GPU(如RTX 3060)、个人台式机GPU(如RTX 3090);
训练成本极低:基于单卡RTX 3090,训练基础对话模型(MiniMind-Zero)仅需2.1小时,成本2.73元;完整训练MiniMind2-small(26M)约38小时,成本不足50元;若用8卡RTX 4090,训练时间可压缩至10分钟内,成本基本不变;
无硬件门槛:无需企业级服务器,个人用户通过租用云GPU(如1.3元/小时的RTX 3090实例)即可完成训练。
2. 全流程技术覆盖,从“0到1”掌握LLM
项目提供LLM开发全阶段的代码与数据,覆盖“模型设计-训练-微调-部署-推理”全链路,具体包括:
模型结构:Decoder-Only架构(兼容Llama3.1设计)、混合专家模型(MoE)扩展;
训练环节:预训练(Pretrain,学知识)、监督微调(SFT,学对话)、RLHF-DPO(优化偏好)、模型蒸馏(小模型学大模型能力)、LoRA(高效参数微调);
工具链:自定义分词器训练、wandb训练可视化、OpenAI API兼容服务端、streamlit WebUI;
数据集:开源预训练(HQ高质量)、SFT(多长度适配)、RLHF(偏好数据)、推理蒸馏(DeepSeek-R1)数据集,均已清洗去重,无需用户二次处理。
3. PyTorch原生实现,理解底层无障碍
区别于依赖transformers、peft等第三方库的项目,MiniMind的核心算法(如LoRA、DPO、RoPE位置嵌入)均用PyTorch原生代码编写,无抽象接口封装。例如:
LoRA微调不依赖peft库,直接实现低秩矩阵分解与参数更新逻辑;
DPO强化学习原生计算偏好损失,无需额外奖励模型;
模型蒸馏(白盒)直接对齐教师模型与学生模型的神经元输出,而非仅学习硬标签。
这种“裸写”方式让开发者能逐行查看LLM的核心逻辑(如注意力计算、层归一化),尤其适合初学者理解“大模型为什么能工作”。
4. 强兼容性,无缝对接主流生态
MiniMind兼容当前LLM领域的主流框架与工具,降低部署与集成成本:
训练框架:支持单机单卡、单机多卡(DDP、DeepSpeed),适配wandb可视化;
推理引擎:兼容llama.cpp(C++轻量推理)、vllm(高性能部署)、ollama(本地快速运行);
模型格式:支持PyTorch原生权重(.pth)与transformers格式(可直接上传Hugging Face);
应用集成:实现OpenAI API协议服务端,可直接接入FastGPT、Open-WebUI、Dify等第三方ChatUI。
5. 多模态与推理扩展,能力边界持续拓宽
项目在基础LLM之外,还扩展了两类核心能力:
视觉多模态(MiniMind-V):推出孪生项目支持图文交互,具体可参考MiniMind-V仓库;
推理模型(MiniMind-Reason):通过蒸馏DeepSeek-R1的数据集,实现基础数学推理与逻辑分析能力,适配“思考过程+最终回答”的回复模板。

三、MiniMind的技术细节
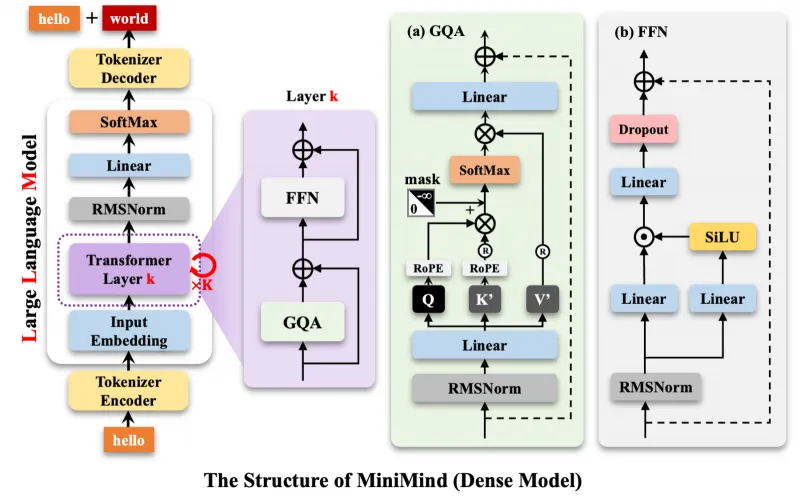
1. 模型结构设计
MiniMind提供两种核心模型结构(Dense与MoE),均基于Transformer Decoder-Only架构,关键设计细节如下:
| 结构类型 | 核心特点 | 代表模型 | 参数规模 | 推理占用 |
|---|---|---|---|---|
| MiniMind-Dense | 经典Transformer Decoder层,预标准化(RMSNorm)、RoPE位置嵌入、SwiGLU激活 | MiniMind2-small | 26M | 0.5GB |
| MiniMind2 | 104M | 1.0GB | ||
| MiniMind-MoE | 基于DeepSeek-V2 MixFFN,细粒度专家分割+共享专家隔离,优化负载均衡 | MiniMind2-MoE | 145M | 1.0GB |
关键技术点解析:
预标准化(RMSNorm):在每个Transformer子层的输入端做归一化(而非输出端),提升训练稳定性,减少梯度消失问题;
旋转位置嵌入(RoPE):替代传统绝对位置嵌入,支持上下文长度外推(如训练时用512长度,推理时可扩展至2048);
SwiGLU激活函数:比ReLU更平滑,缓解梯度稀疏问题,提升模型表达能力;
MoE混合专家:MiniMind2-MoE采用“1个共享专家+4个路由专家”(share+route=1+4),通过Router选择激活的专家,在参数增加不多的情况下提升模型容量。
2. 分词器设计
为控制模型整体参数规模,MiniMind未使用第三方分词器(如Llama3、Qwen的大词表),而是自定义了6400词表的minimind_tokenizer,核心设计逻辑如下:
| 分词器类型 | 词表大小 | 编解码效率 | 优势 | 劣势 |
|---|---|---|---|---|
| minimind_tokenizer | 6400 | 中等 | 轻量(减少embedding层参数),避免“头重脚轻” | 对长文本压缩率低于大词表分词器 |
| 第三方分词器(如Qwen2) | 151643 | 高 | 压缩率高,生僻词覆盖全 | 词表过大,增加小模型参数负担 |
设计原因:LLM的embedding层参数=词表大小×模型维度(d_model),若使用15万词表+512维度,仅embedding层就需76.8M参数,远超MiniMind2-small的26M总参数。自定义6400词表可将embedding层参数控制在3.2M(6400×512),确保模型“轻量且均衡”。
实际测试中,minimind_tokenizer未出现生僻词解码失败问题,可满足中文日常对话需求,训练数据来自“匠数大模型数据集”,代码位于./scripts/train_tokenizer.py。
3. 训练流程与核心算法
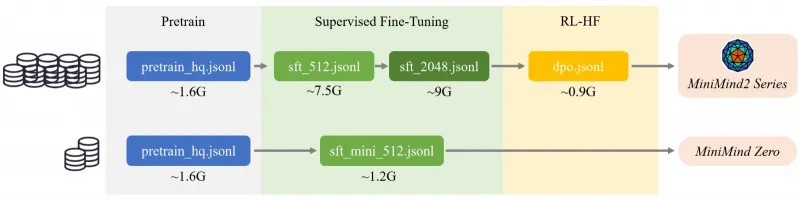
MiniMind的训练流程分为5个核心环节,每个环节的目标、数据与输出如下表所示:
| 训练环节 | 核心目标 | 输入数据 | 输出产物 | 关键算法亮点 |
|---|---|---|---|---|
| 预训练(Pretrain) | 让模型学习通用知识(如词语接龙) | pretrain_hq.jsonl(1.6GB中文语料) | pretrain_*.pth(权重文件) | 无监督学习,基于Next Token预测 |
| 监督微调(SFT) | 让模型学习对话格式(指令跟随) | sftmini512.jsonl(1.2GB对话) | fullsft*.pth | 全参数微调,适配多轮对话模板 |
| LoRA微调 | 高效适配垂域知识(不损失通用能力) | lora_medical.jsonl(医疗问答) | loraxxx*.pth | 原生实现低秩矩阵,仅更新1%参数 |
| RLHF-DPO | 优化模型回复偏好(符合人类习惯) | dpo.jsonl(0.9GB偏好数据) | rlhf_*.pth | 离线计算偏好损失,无需奖励模型 |
| 模型蒸馏 | 让小模型学习大模型能力 | r1mix1024.jsonl(DeepSeek-R1) | reason_*.pth | 白盒蒸馏(对齐神经元输出) |
关键算法细节:
LoRA原生实现:在Transformer注意力层的Q/K/V权重中插入低秩矩阵(A×B,A为dmodel×r,B为r×dmodel,r为秩,默认8),仅更新A和B的参数,大幅减少计算量;
DPO(直接偏好优化):通过“偏好回复(chosen)”与“拒绝回复(rejected)”的对比,计算损失函数,无需训练单独的奖励模型(RM),节省显存与训练时间;
模型蒸馏:分“黑盒”与“白盒”两种——黑盒蒸馏(如SFT用Qwen2数据)仅学习大模型输出的文本;白盒蒸馏(代码位于
train_distillation.py)则对齐教师模型的中间层输出,效果更优。
4. 数据集设计
项目开源了全阶段训练所需的数据集,均已预处理为JSONL格式,用户可根据需求选择组合,核心数据集列表如下:
| 数据集文件名 | 数据规模 | 适用环节 | 数据来源 | 核心特点 |
|---|---|---|---|---|
| pretrain_hq.jsonl | 1.6GB | 预训练 | 匠数大模型数据集(中文) | 筛选字符<512,高质量无监督文本 |
| sftmini512.jsonl | 1.2GB | SFT(快速训练) | 匠数+Qwen2.5蒸馏数据 | 中文占比高,字符<512,适合Zero模型 |
| sft_512.jsonl | 7.5GB | SFT(完整训练) | 匠数大模型SFT数据集 | 10M条中文对话,字符<512 |
| sft_1024.jsonl | 5.6GB | SFT(长文本) | Qwen2.5蒸馏数据 | 字符<1024,适配长对话需求 |
| sft_2048.jsonl | 9.0GB | SFT(超长文本) | Qwen2.5蒸馏数据 | 字符<2048,需配合RoPE外推 |
| dpo.jsonl | 0.9GB | RLHF-DPO | Magpie-DPO数据集(英文) | 200k条偏好数据,含chosen/rejected |
| r1mix1024.jsonl | 340MB | 推理蒸馏 | DeepSeek-R1相关数据集 | 字符<1024,含“思考过程”模板 |
| lora_medical.jsonl | 34MB | LoRA微调 | 医疗问答数据集 | 垂域知识,适配医疗场景 |
| lora_identity.jsonl | 22.8KB | LoRA微调 | 自定义自我认知数据 | 回答“你是谁”等身份问题 |
数据集使用建议:
快速入门(Zero模型):选择
pretrain_hq.jsonl + sft_mini_512.jsonl,单卡3090约2小时完成训练;完整效果(MiniMind2-small):选择
pretrain_hq.jsonl + sft_512.jsonl + sft_2048.jsonl + dpo.jsonl,约38小时;垂域定制(医疗模型):基础模型训练后,用
lora_medical.jsonl做LoRA微调,无需全量训练。
5. 训练优化技术
为适配个人GPU的有限资源,MiniMind做了多项训练优化:
动态启停与权重保存:默认每100步保存一次权重(覆盖旧文件),支持中断后从最近步数恢复,避免训练崩溃导致前功尽弃;
显存优化:SFT阶段截断对话长度至512,预训练用CSV格式而非BIN格式(轻微牺牲速度,保证文本完整性);
多卡分布式训练:支持DDP(分布式数据并行)与DeepSpeed,8卡4090可将训练时间压缩至10分钟内;
可视化监控:集成wandb,可实时查看损失曲线、学习率变化、显存占用,便于调参优化。
四、MiniMind的应用场景
MiniMind的低门槛与轻量特性,使其适合以下5类核心场景:
1. LLM初学者学习实践
适用人群:刚接触大模型的学生、开发者,想理解LLM底层原理但无高配置硬件;
核心价值:
原生代码无封装,可逐行查看注意力计算、层归一化、LoRA等核心逻辑,避免“调参侠”困境;
低成本试错,3元成本即可体验“从0训练模型”的全流程,无需担心硬件浪费;
配套数据集与文档完善,减少“找数据、排BUG”的时间成本。
2. 个人开发者轻量模型部署
适用人群:需要在个人设备(如笔记本、小型服务器)部署LLM的开发者;
核心价值:
模型体积小,26M模型推理仅占0.5GB内存,笔记本GPU(如RTX 3050)即可运行;
兼容多推理引擎,llama.cpp支持CPU量化推理(无需GPU),ollama支持一键启动;
支持OpenAI API,可快速集成到个人项目(如本地聊天工具、小助手应用)。
3. 垂域模型快速定制
适用人群:需要开发特定领域小模型(如医疗问答、企业知识库)的团队或个人;
核心价值:
LoRA微调高效适配垂域数据,用34MB的
lora_medical.jsonl即可训练医疗模型,无需全量更新参数;支持私有数据集导入,只需按JSONL格式整理对话数据,即可快速迁移至垂域场景;
低成本验证,无需投入百万级算力,即可验证垂域模型的可行性。
4. 教学与科研演示
适用人群:AI相关课程的教师、做小模型研究的科研人员;
核心价值:
全流程代码可作为教学案例,演示LLM的训练、微调、部署全链路;
支持修改模型参数(如层数、维度、词表大小),便于研究“参数规模与模型性能”的关系(如验证MobileLLM的“深而窄”结论);
开源数据集可用于对比实验,如测试不同数据质量对模型效果的影响。
5. 低成本AI应用原型开发
适用人群:创业团队、独立开发者,需要快速验证AI应用想法;
核心价值:
2小时快速出原型,用MiniMind-Zero模型即可搭建基础对话功能,验证产品需求;
部署成本低,无需租用高配置云服务器,小型服务器(16GB内存+单卡3090)即可支撑小流量访问;
生态兼容,可无缝迁移至成熟框架(如后续需求升级,可替换为Qwen、Llama等大模型)。
五、MiniMind的使用方法
1. 环境准备
1.1 硬件要求
最低配置:单卡NVIDIA GPU(显存≥8GB,如RTX 3060),CPU≥4核,内存≥16GB;
推荐配置:单卡NVIDIA RTX 3090(24GB显存),CPU≥8核(如i9-10980XE),内存≥32GB;
备注:“2小时训练”基于单卡RTX 3090,3元成本为GPU服务器租用价(约1.3元/小时)。
1.2 软件安装
克隆仓库:
git clone https://github.com/jingyaogong/minimind.git cd minimind
创建虚拟环境(可选但推荐):
conda create -n minimind python=3.10 conda activate minimind
安装依赖库:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
验证PyTorch CUDA可用性:
运行以下Python代码,确保输出为True(若为False,需手动安装对应CUDA版本的PyTorch):
import torch print(torch.cuda.is_available())
2. 快速测试已有模型
无需训练,可直接下载预训练模型测试效果:
2.1 下载预训练模型
从Hugging Face或ModelScope下载模型权重:
# 从Hugging Face下载MiniMind2模型 git clone https://huggingface.co/jingyaogong/MiniMind2
2.2 三种测试方式
命令行问答:
# load=1表示加载transformers格式模型,model_mode=2表示测试RLHF模型(0=预训练,1=SFT,2=RLHF,3=推理) python eval_model.py --load 1 --model_mode 2
启动WebUI:
# 安装streamlit(若未安装) pip install streamlit # 进入scripts目录启动WebUI cd scripts streamlit run web_demo.py
启动后访问终端输出的URL(如http://localhost:8501),即可在浏览器中聊天。
第三方推理框架:
ollama(本地快速运行):
bash ollama run jingyaogong/minimind2vllm(高性能部署):
bash vllm serve ./MiniMind2/ --served-model-name "minimind"llama.cpp(CPU量化推理):
先转换模型为GGUF格式,再量化运行(参考项目“其它”章节的llama.cpp转换步骤)。
3. 从0开始训练模型
3.1 数据下载与放置
从以下链接下载所需数据集(推荐先下载快速入门组合):
Hugging Face数据集地址:https://huggingface.co/datasets/jingyaogong/minimind-dataset
ModelScope数据集地址:https://modelscope.cn/datasets/jingyaogong/minimind-dataset
在项目根目录创建
./dataset文件夹,将下载的JSONL文件放入其中(如pretrain_hq.jsonl、sft_mini_512.jsonl)。
3.2 核心训练步骤(以快速入门为例)
预训练(学知识):
进入trainer目录:
cd trainer执行预训练脚本:
python train_pretrain.py输出:在
./out/目录生成pretrain_512.pth(512为模型维度,默认值)。
监督微调(学对话):
执行SFT脚本:
python train_full_sft.py输出:在
./out/目录生成full_sft_512.pth。
测试训练效果:
执行测试脚本:
python eval_model.py --model_mode 1(model_mode=1表示测试SFT模型)输入问题(如“介绍一下自己”),查看模型回复。
3.3 进阶训练(可选)
LoRA微调:
python train_lora.py --lora_data ../dataset/lora_medical.jsonl(医疗垂域);RLHF-DPO:
python train_dpo.py(需先训练SFT模型);推理蒸馏:
python train_distill_reason.py(用r1_mix_1024.jsonl数据)。
3.4 多卡训练启动
若有多个GPU(如2卡3090),可通过DDP启动多卡训练:
# 2卡训练预训练脚本 torchrun --nproc_per_node 2 train_pretrain.py
六、常见问题解答(FAQ)
1. “2小时训练”和“3元成本”的前提是什么?
硬件前提:“2小时”基于单卡NVIDIA RTX 3090(24GB显存),训练数据集为
pretrain_hq.jsonl + sft_mini_512.jsonl(总数据量约2.8GB);成本前提:“3元”是GPU服务器租用成本(参考市场价1.3元/小时,2小时约2.6元,四舍五入为3元),若用自有GPU则无额外成本。
2. 为什么MiniMind不用现成的分词器(如Llama3、Qwen)?
核心原因是“控制模型参数规模”:第三方分词器词表多为10万+(如Qwen2为151643),embedding层参数=词表大小×模型维度,若用15万词表+512维度,仅embedding层就需76.8M参数,远超MiniMind2-small的26M总参数;
实际效果:自定义6400词表可满足中文日常对话需求,测试中未出现生僻词解码失败问题。
3. 训练时权重文件为什么会覆盖旧文件?
项目默认每100步保存一次权重(覆盖旧文件),目的是节省磁盘空间(避免大量小权重文件占用存储);
若需保留所有步数的权重,可修改训练脚本(如
train_pretrain.py)中的保存逻辑,将overwrite=True改为overwrite=False,并在文件名中加入步数后缀(如pretrain_512_step100.pth)。
4. RLHF(DPO)步骤是否必须?不做会有什么影响?
非必须步骤:RLHF的核心作用是优化模型回复的“人类偏好”(如更礼貌、更符合对话习惯),但不会提升模型的“知识量”或“推理能力”;
不做的影响:模型仍具备对话能力,但回复可能更简洁(甚至生硬),缺乏“讨好式”的补充说明;若仅用于学习或垂域场景(如医疗问答),可跳过此步骤。
5. 如何将MiniMind部署到第三方ChatUI(如FastGPT)?
启动OpenAI API兼容服务端:
python scripts/serve_openai_api.py;在FastGPT中添加“自定义模型”,API地址填写服务端地址(如
http://你的IP:8000/v1),模型名填写“minimind”,即可完成集成。
6. 模型推理时如何扩展上下文长度(如从512到2048)?
MiniMind使用RoPE位置嵌入,支持上下文长度外推,无需重新训练;
推理时修改生成脚本(如
eval_model.py)中的max_seq_len参数,将其从512改为2048,并启用RoPE线性差值(代码中已默认支持)。
7. 训练过程中出现“CUDA out of memory”(显存不足)怎么办?
降低batch size:修改训练脚本中的
batch_size参数(如从32改为16);截断更长文本:预训练时将文本长度从512改为256(需同步修改数据集预处理逻辑);
使用DeepSpeed:启动训练时添加
deepspeed命令(如deepspeed --num_gpus=1 train_pretrain.py),启用梯度检查点等显存优化功能。
8. MiniMind的模型性能如何?能否用于生产环境?
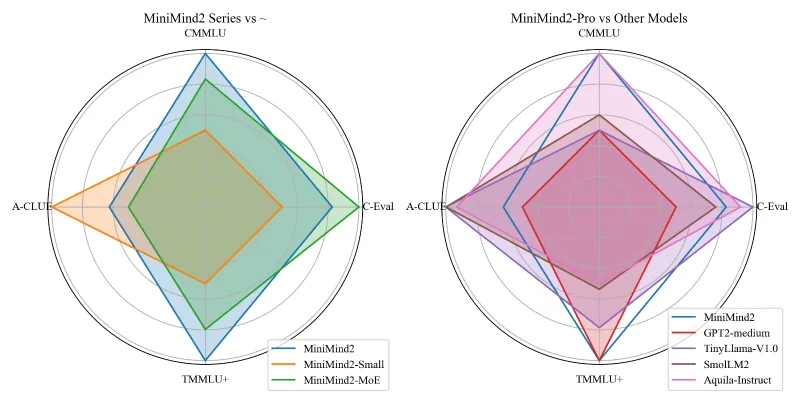
性能定位:MiniMind是“学习型轻量模型”,26M模型在C-Eval、CMMLU等榜单的正确率约25%(接近随机水平),适合学习与原型验证,不适合生产级场景(如企业客服、精准问答);
生产替代:若需生产级能力,可基于MiniMind的训练流程,用更大参数模型(如1B+)或更高质量数据集训练,项目代码可作为参考。
七、相关链接
Hugging Face模型库:https://huggingface.co/jingyaogong
ModelScope模型库:https://modelscope.cn/models/jingyaogong
八、总结
MiniMind是一个以“降低LLM门槛”为核心的开源项目,通过“超轻量参数、低成本训练、全流程原生代码”三大特色,让普通用户无需高配置硬件与深厚技术积累,即可体验“从0训练大模型”的完整流程。项目不仅开源了模型结构、训练算法、数据集,还兼容主流推理与部署工具,既是LLM初学者理解底层原理的“实战教程”,也是个人开发者快速实现轻量AI应用的“工具包”。尽管MiniMind的小模型性能有限(不适合生产环境),但其在“教育普及”与“技术透明”上的价值显著——它打破了大模型的“黑盒子”壁垒,让更多人能亲手触摸AI的核心逻辑,为AI社区的大众化发展提供了重要支撑。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/minimind.html





