Multimodal-Search-R1:字节跳动开源的端到端多模态搜索强化学习框架
一、Multimodal-Search-R1是什么
Multimodal-Search-R1(简称MMSearch-R1)是一款开源的端到端强化学习框架,核心定位是让多模态大语言模型(LMMs)具备按需、多轮、自主的真实世界多模态搜索能力,解决传统多模态模型依赖静态预训练数据、易产生事实幻觉、无法获取实时信息、检索调用冗余等行业痛点。
该项目由字节跳动与南洋理工大学S-Lab联合研发,属于R1系列检索增强推理框架的多模态延伸,区别于传统检索增强生成(RAG)、固定规则工具调用、无差别机械检索方案,通过强化学习激励模型学习“判断是否搜索、选择何种工具、生成精准查询、整合检索结果、迭代多轮推理”的完整决策链,让模型像人类一样“先判断、再检索、后推理”,在知识密集型、事实依赖型、跨模态理解任务中实现更高准确率与更低检索成本。
项目遵循Apache-2.0开源协议,完整开放训练代码、推理逻辑、模型权重、专用数据集与配置脚本,支持从基座多模态模型快速微调为具备自主搜索能力的智能体,同时兼容主流多模态基座、分布式训练架构与第三方搜索接口,降低多模态搜索智能体的研发与部署门槛。
从技术谱系来看,MMSearch-R1继承Search-R1文本检索强化学习思路,结合Qwen2.5-VL等多模态基座的视觉理解能力,拓展图像检索、跨模态查询、多轮工具交互能力,形成覆盖“文本+图像”双模态的全流程检索推理框架,是当前开源社区中少数同时支持多模态输入、多工具选择、多轮检索、端到端RL训练的完整方案。
二、功能特色
(一)核心能力总览
自主决策检索:模型根据输入图文内容与问题,自主判断是否需要调用外部搜索,避免无意义检索带来的延迟与成本消耗。
双模态工具支持:内置文本搜索工具与图像搜索工具,模型可根据任务需求选择单一工具或交替调用,覆盖文本事实查询、视觉实体识别、跨模态关联检索全场景。
多轮交互推理:支持自定义最大交互轮数,模型可基于上一轮检索结果补充查询、修正方向,逐步逼近标准答案,适配多跳、复杂、信息分散的检索任务。
强化学习激励优化:采用GRPO等算法设计多维奖励机制,从查询相关性、结果利用率、答案准确性、检索精简度四个维度引导模型优化行为,平衡检索深度与效率。
完整开源生态:配套MMSearch-R1-7B微调模型、FVQA(FactualVQA)专用数据集、预缓存图像检索结果、标准化训练/评估脚本,开箱即用。
高效工程实现:基于vLLM实现高吞吐推理,基于FSDP实现分布式训练,支持序列并行、参数Offload等优化,适配单卡与多卡集群环境。
(二)核心功能对比
为清晰体现项目优势,将MMSearch-R1与传统RAG、固定规则工具调用、纯基座模型三类方案对比,如下表:
| 方案类型 | 检索决策方式 | 模态支持 | 幻觉控制 | 检索成本 | 推理灵活性 |
|---|---|---|---|---|---|
| 纯基座多模态模型 | 无检索,依赖预训练数据 | 文本/图像 | 严重,易编造事实 | 无 | 低,无法更新知识 |
| 传统RAG方案 | 固定召回,无决策 | 以文本为主,多模态支持弱 | 中等,依赖库内数据 | 高,全量召回无筛选 | 低,固定链路无法迭代 |
| 固定规则工具调用 | 人工设定触发条件 | 单模态为主 | 中等,依赖规则覆盖度 | 较高,条件触发易冗余 | 中,规则固定无法自适应 |
| MMSearch-R1 | 强化学习自主决策 | 文本+图像双模态 | 低,基于真实检索结果推理 | 低,按需调用减少30%+请求 | 高,多轮迭代自适应调整 |
(三)特色功能细分
搜索工具流水线
文本搜索工具:整合SerpAPI网页检索、JINA Reader页面清洗、Qwen3-32B摘要生成,输出结构化摘要与来源链接,保障信息可追溯。
图像搜索工具:基于SerpAPI实现以图搜图,返回缩略图、网页标题、来源页面的交错序列,适配视觉实体识别、作品溯源、场景信息查询等场景。
数据与评估体系
提供FVQA数据集,包含搜索必需样本与无搜索样本的平衡子集,帮助模型学习区分“可内部回答”与“必需检索”任务。
支持InfoSeek、MMSearch、SimpleVQA、LiveVQA等多模态基准评估,覆盖常规视觉问答、实时信息查询、长尾知识问答等维度。
训练与部署灵活性
支持SFT监督微调与RL强化学习两级训练,先规范工具调用格式,再优化检索决策与推理质量。
配置化管理交互轮数、生成长度、损失掩码、评估日志,适配不同硬件与任务需求。
输出JSON格式评估结果,支持WandB可视化追踪,便于实验对比与效果分析。

三、技术细节
(一)整体技术架构
MMSearch-R1采用分层架构,自上而下分为交互层、决策层、工具层、训练层、工程层,各层解耦且协同工作:
交互层:接收用户图文输入,解析多模态内容,输出模型回答与检索过程日志。
决策层:基于强化学习策略网络,判断检索时机、选择工具类型、生成查询语句,是框架核心。
工具层:封装文本搜索、图像搜索标准化接口,对接第三方服务,返回清洗后结构化数据。
训练层:包含SFT微调、GRPO强化学习、奖励评分、价值评估模块,优化模型检索决策与推理能力。
工程层:基于veRL、vLLM、FSDP实现分布式训练、高吞吐推理、资源调度与日志管理。
(二)核心技术组件
基座模型
以Qwen2.5-VL-7B为默认基座,具备文本理解、图像编码、跨模态对齐能力,是检索决策与答案生成的基础;项目支持替换为其他开源多模态模型,仅需适配输入输出格式。强化学习算法
采用GRPO(Group Relative Policy Optimization)算法,相比PPO更稳定、计算效率更高,适配多模态序列数据与多轮交互场景;通过奖励塑形平衡“答案准确性”“检索相关性”“调用精简度”,避免模型过度检索或拒绝检索。多轮Rollout机制
支持自定义max_gen_round参数控制最大交互轮数,每轮执行“生成查询→调用工具→解析结果→整合推理”闭环,使用multi_turn_response_mask精准计算损失,避免不同轮次生成长度差异导致的梯度异常。分布式训练技术
基于FSDP(Fully Sharded Data Parallel)实现参数、优化器、梯度分片,降低单卡显存占用;ResourcePoolManager管理GPU资源池,分离Actor与Critic角色资源;支持Ulysses序列并行、参数Offload,提升多卡扩展效率。工具调用规范
定义标准化工具调用格式,包含工具名称、查询内容、参数配置、结果解析规则,模型生成符合格式的调用指令,框架自动解析并执行,降低格式错误率。
(三)检索与推理流程
标准执行流程分为6个步骤:
输入解析:接收图像+文本问题,提取视觉特征与文本语义。
决策判断:模型评估内部知识是否足够回答,不足则进入检索流程。
工具选择与查询生成:选择文本/图像搜索工具,生成高相关性查询语句。
工具执行与结果返回:调用第三方接口,获取清洗后的网页摘要或视觉检索结果。
信息整合推理:模型融合原始输入与检索结果,生成中间结论。
终止判断:判断结论是否完整,是则输出答案,否则启动下一轮检索。
(四)数据集与评估指标
FVQA数据集:半自动化构建的多模态检索VQA数据集,覆盖多样视觉与文本知识需求,包含平衡子集,兼顾必需检索与无需检索样本,是训练模型按需检索的核心数据。
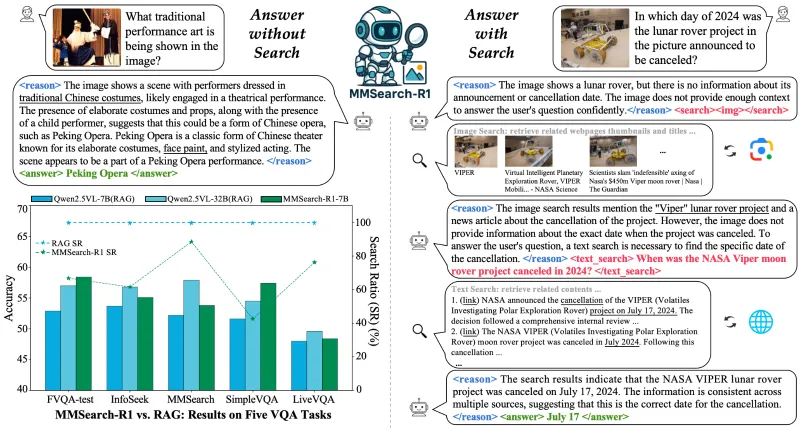
评估指标:以准确率(Acc)为核心,在FVQA-test、InfoSeek、MMSearch、SimpleVQA、LiveVQA等基准测试,同时统计检索调用次数、平均交互轮数、延迟等效率指标。
(五)关键技术创新
多模态奖励设计:针对图像检索结果相关性、文本摘要匹配度、答案事实一致性、检索步骤精简度设计多维奖励,引导模型形成高效检索习惯。
模态融合检索:打破文本与图像检索壁垒,支持图文混合查询、视觉引导文本检索、文本辅助视觉定位,适配真实世界复杂查询。
轻量化高效训练:在7B参数规模实现接近32B RAG模型的效果,同时减少30%以上检索请求,兼顾效果与成本。
四、应用场景
(一)知识密集型视觉问答
面向博物馆展品讲解、艺术品溯源、地标识别、动植物科普等场景,用户上传图片并提问,模型自主检索相关百科、文献、官方资料,输出准确、可溯源的回答,替代人工查询与静态知识库。
(二)实时信息跨模态检索
针对新闻事件、赛事结果、天气信息、财经数据等时效性内容,结合图像场景与文本问题,模型调用实时搜索工具,获取最新信息并整合回答,解决预训练模型知识滞后问题。
(三)行业多模态检索系统
在医疗影像辅助解读、工业设备故障识别、法律文书图文检索、教育图文答疑等行业场景,对接行业专属数据库与检索接口,训练专用检索智能体,提升专业信息获取效率。
(四)多模态智能助手与机器人
为智能音箱、车载助手、服务机器人、桌面端AI助手增加图文搜索能力,用户上传照片并语音提问,模型完成场景识别、信息检索、自然语言回答全流程,提升交互实用性。
(五)学术与工业研究平台
作为多模态工具调用、强化学习、检索增强推理的研究基准,支持研究者验证新算法、新奖励机制、新工具集成,推动多模态智能体技术迭代。
五、使用方法
(一)环境准备
项目依赖Conda、Python3.10、CUDA,建议使用Linux系统与NVIDIA显卡,最低配置单卡16GB显存,多卡可显著提升训练速度。
(二)仓库克隆与环境创建
递归克隆仓库与子模块
git clone --recurse-submodules https://github.com/EvolvingLMMs-Lab/multimodal-search-r1.git cd multimodal-search-r1
创建并激活Conda环境
conda create -n mmsearch_r1 python==3.10 -y conda activate mmsearch_r1
安装核心依赖
pip3 install -e ./verl pip3 install vllm==0.8.2 transformers==4.51.0 flash-attn==2.7.4.post1
可选安装WandB用于日志可视化
pip3 install wandb export WANDB_API_KEY="你的API密钥" wandb login $WANDB_API_KEY
(三)搜索工具配置
正式训练前需在mmsearch_r1/utils/tools/目录下配置搜索工具,填写SerpAPI等第三方密钥,实现文本与图像搜索的可用接口。
文本搜索:配置SerpAPI密钥、JINA Reader接口、摘要模型参数。
图像搜索:配置SerpAPI图像检索接口,设置返回结果数量与格式。
(四)数据准备
从HuggingFace下载FVQA数据集与预缓存图像搜索结果。
按veRL定义格式整理自定义数据,参考
mmsearch_r1/data示例文件,确保包含输入图文、工具调用标注、标准答案字段。划分训练集与验证集,配置文件路径。
(五)训练与评估执行
统一训练+评估脚本(推荐)
bash mmsearch_r1/scripts/run_mmsearch_r1_grpo.sh
关键配置说明
actor_rollout_ref.rollout.name:设置为vllm_multiturn_mmsearch启用多轮检索。actor_rollout_ref.actor.use_multi_turn_response_mask:设置为True启用多轮掩码,保障损失计算准确。actor_rollout_ref.rollout.max_gen_round:设置最大交互轮数,建议1-3轮兼顾效果与效率。data.max_response_length:设置单轮最大生成长度。
仅执行评估
修改脚本参数,开启纯评估模式:
trainer.val_files=验证集路径 \ trainer.val_only=True \ trainer.val_only_save_dir=结果保存路径 \ trainer.val_generations_to_log_to_wandb=64
评估结果以JSON格式保存,包含模型回答、检索过程、工具调用记录。
(六)模型导出与推理
训练完成后导出模型权重,基于vLLM搭建推理服务,加载MMSearch-R1-7B或自定义微调模型,配置工具接口,即可处理图文查询请求。项目后续将提供标准化推理脚本示例。
六、常见问题解答
1. 安装依赖时出现版本冲突、编译失败如何解决?
项目对transformers、vllm、flash-attn等核心库有严格版本限定,出现冲突的核心原因是手动升级库版本或系统环境不兼容。优先严格按照项目指定版本安装,不擅自修改版本号;flash-attn编译报错时,先检查CUDA版本与显卡驱动匹配度,推荐使用CUDA 11.8或12.1版本,同时安装gcc、cmake等基础编译工具,若依旧失败可尝试从flash-attn官方源码编译,或降低至兼容的次版本。verl子模块需通过递归克隆方式拉取,单独克隆主仓库会缺失依赖代码,导致导入报错,克隆时必须添加--recurse-submodules参数。
2. 环境配置完成后无法调用文本/图像搜索工具怎么办?
无法调用搜索工具几乎都是外部接口配置与网络问题导致。首先检查mmsearch_r1/utils/tools/目录下的工具配置文件,确认SerpAPI、JINA Reader的密钥已正确填写,且账号拥有对应接口调用权限;其次测试本地服务器网络能否正常访问外部服务,可使用curl命令单独调用SerpAPI接口验证连通性,云服务器需放行443等HTTPS端口,避免防火墙拦截请求。另外,工具调用流程依赖模型生成标准格式指令,若指令格式异常,框架也无法解析执行,可先通过单轮简单查询测试工具链路是否通畅。
3. 训练过程中出现显存溢出,该如何调整参数?
显存溢出是多模态大模型训练的常见问题,可从多维度调整参数缓解。首先降低批次大小、单轮最大生成长度,同时减少max_gen_round最大交互轮数,单卡16GB显存建议将最大轮数设为1,生成长度限制在512以内;其次开启FSDP分布式训练与参数Offload功能,将优化器状态、部分模型参数转移到CPU内存,减少显卡显存占用;多卡环境可增加GPU数量,利用ResourcePoolManager拆分Actor与Critic模型的资源占用,避免单卡负载过高。
4. 训练后模型出现拒绝调用工具、无意义频繁调用的情况怎么优化?
这类问题主要源于数据集分布失衡与奖励机制配置不当。训练集需保证必需搜索样本和无需搜索样本比例均衡,优先使用官方提供的FVQA平衡子集,避免单一类型样本过多导致模型决策偏向;训练流程需遵循先SFT监督微调、再GRPO强化学习的顺序,先用SFT规范工具调用格式与基础逻辑,再用RL优化决策行为;同时调整奖励函数权重,提高无意义调用的惩罚系数,降低冗余检索的奖励分值,引导模型学习按需调用的行为模式。
5. 本地复现评估结果低于论文报告值,原因是什么?
评估效果不达标的核心因素有三点,一是验证集与论文使用的版本不一致,需下载官方指定的FVQA测试集与预缓存搜索结果,避免自定义数据集带来的偏差;二是训练与评估参数未对齐论文配置,需严格匹配max_gen_round、生成长度、奖励系数等关键参数,不随意修改默认超参;三是本地搜索工具返回结果与论文缓存结果存在差异,实时网络检索会受接口、地域、时间影响,复现基准效果时建议使用官方预缓存的搜索结果,排除外部变量干扰。
6. 模型推理延迟过高,如何优化响应速度?
推理延迟主要来自模型生成本身与外部工具调用,优化可从两方面入手。模型端基于vLLM启用continuous batching批量推理,调整合适的并发数与批量大小,提升推理吞吐;交互端降低最大搜索轮数,日常使用设置1-2轮即可满足多数场景,减少多轮工具调用的耗时;同时搭建本地检索缓存,对高频查询、固定场景的搜索结果做缓存,直接复用历史结果,避免重复调用第三方接口。此外,确保服务器带宽充足,减少网页解析、摘要生成的网络等待时间。
7. 如何添加自定义数据集,适配自己的业务场景?
自定义数据集需严格遵循veRL框架定义的格式,包含图文输入内容、工具调用标注、标准答案、交互轮次标记四个核心字段,可参考mmsearch_r1/data目录下的示例文件结构调整数据。建议先使用小批量样本测试训练流程,确认数据读取、格式解析、损失计算无异常后,再扩展全量数据;数据标注需覆盖需要搜索、无需搜索、多轮搜索等多种类型,保证样本分布贴合实际业务场景,避免数据偏差导致模型泛化能力不足。
8. 能否替换默认的Qwen2.5-VL基座模型,需要做哪些适配?
项目支持替换其他开源多模态基座模型,更换后需完成三项适配工作,一是修改图像编码、多模态输入处理逻辑,保证新模型的图文输入格式与框架兼容;二是对齐工具调用指令的输出格式,确保模型生成的调用语句能被框架正常解析;三是调整模型加载代码,适配新模型的权重结构与transformers接口。更换后先在小样本集上测试单轮推理与SFT微调,确认流程通畅后再启动强化学习训练,不建议直接替换后进行全量RL训练。
七、相关链接
Multimodal-Search-R1 项目GitHub主仓库:https://github.com/EvolvingLMMs-Lab/multimodal-search-r1
项目配套技术论文(arXiv):https://arxiv.org/pdf/2506.20670v1.pdf
MMSearch-R1-7B 模型权重(Hugging Face):https://huggingface.co/lmms-lab/MMSearch-R1-7B
FVQA数据集及预缓存搜索结果(Hugging Face):https://huggingface.co/datasets/lmms-lab/FVQA
项目依赖veRL强化学习框架仓库:https://github.com/cfpark00/verl
八、总结
Multimodal-Search-R1是面向多模态大模型的端到端强化学习检索框架,通过自主决策、双模态工具、多轮交互、奖励优化的完整方案,解决传统多模态模型幻觉、知识滞后、检索冗余问题,配套模型、数据集、代码的全栈开源资源降低研发门槛,在7B参数规模实现高精度、低成本的多模态检索推理,可直接应用于视觉问答、实时检索、智能助手、行业系统等场景,同时为多模态工具调用与强化学习研究提供标准化基准与可扩展架构,是当前多模态智能体领域的高实用性开源方案。
版权及免责申明:本文由@人工智能研究所原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/multimodal-search-r1.html