OpenSpec:开源的 AI 编程辅助工具,用规范文档解决需求模糊问题
一、OpenSpec 是什么?
OpenSpec 是 Fission-AI 开源的 AI 编程辅助工具,核心靠“结构化规范文档”解决 AI 编程中“需求藏在聊天记录里导致模糊、返工”的痛点。它无需 API 密钥,通过轻量级工作流让人类与 AI 编程助手在写代码前,先在规范文档里明确“要做什么”,确保需求对齐。工具支持存量项目迭代,能追踪每一次需求变更的全流程(提案→验证→实现→归档),兼容 Claude Code、Cursor、GitHub Copilot 等主流 AI 编程助手,遵循 MIT 许可,适合个人开发者和团队协作,让 AI 编程从“凭感觉写”变成“按规范来”。
用一句话说:OpenSpec 是帮你和 AI 编程助手“先把需求写清楚”的工具——通过规范文档把模糊的想法(比如“加个登录功能”)变成具体的规则(比如“登录要支持手机号+验证码,验证码6位、有效期5分钟”),再让 AI 照着文档写代码,避免反复改需求。
平时用 AI 编程,你肯定遇到过这些麻烦:
跟 AI 聊了半天“要做用户筛选”,最后发现漏说“要按部门筛选”,AI 写的代码白做;
隔了一周想改之前的功能,完全记不清当时跟 AI 说的“筛选规则”是什么,只能重新聊;
团队里有人用 Claude、有人用 Copilot,每个人跟 AI 的需求沟通不一样,代码合并时全是冲突。
这些问题的根源,都是“需求没有固定下来”——聊天记录翻起来麻烦,还容易漏信息。而 OpenSpec 的核心解法,就是把需求放进“规范文档”里:不管是初始需求、中间修改,还是最终落地,所有信息都存在项目文件夹里的 Markdown 文档中,你和 AI 都盯着同一个“需求标准”干活。
从本质上看,OpenSpec 是“规范驱动开发(Spec-driven Development)”在 AI 编程场景的落地工具,它有三个核心目标:
让需求“看得见”:把聊天里的模糊想法,变成结构化的规范文档(比如
proposal.md写目的、tasks.md写步骤、spec.md写规则);让变更“可追溯”:每一次需求修改都存档,以后想查“为什么加这个功能”,直接看归档的规范文档就行;
让使用“零门槛”:不用 API 密钥,不用学复杂语法,装个 CLI 工具就能用,兼容你现有的 AI 编程助手。
举个实际例子:你想给项目加“订单导出Excel”功能,用 OpenSpec 不会直接让 AI 写代码,而是先让 AI 生成一份规范文档——里面写清楚“导出要包含订单号、金额、日期三个字段”“点击导出按钮后10秒内生成文件”“支持筛选近30天订单”,你确认文档没问题了,AI 再照着文档写代码。整个过程,需求从“口头说”变成“白纸黑字”,模糊感直接消失。

二、OpenSpec 的功能特色:靠规范文档解决 AI 编程的5大痛点
OpenSpec 的功能不复杂,但每一个都精准针对“需求模糊”的问题,总结下来有5个核心特色:
1. 轻量级:不用 API 密钥,10分钟就能上手
这是最直观的优势——用 OpenSpec 不用申请任何 API 权限,不用部署额外服务,甚至不用改你项目的现有代码。
它只需要两个基础条件:
电脑装了 Node.js(≥20.19.0 版本,用
node --version能查,不够的话去官网下一个,一路点“下一步”就能装);装个 OpenSpec 的 CLI 工具(终端输一行命令
npm install -g @fission-ai/openspec@latest)。
初始化项目时,它会自动帮你生成规范文档的文件夹结构(比如 openspec/specs/ 存现有需求、openspec/changes/ 存新需求),还会根据你选的 AI 工具(比如 Claude Code)配置好命令,不用你手动改任何配置。哪怕你是新手,跟着终端提示点几下,10分钟就能开始用规范文档管理需求。
2. 专为存量项目设计:改旧功能不怕“忘了老需求”
很多 AI 辅助工具只适合“从0开始的新项目”,但实际开发中,我们80%的工作是改已有项目(比如给老项目加新功能、修旧逻辑)——这就是 OpenSpec 的强项,它靠“双文件夹机制”完美适配存量项目,核心就是规范文档的分开管理:
openspec/specs/:存“现有需求规范”——比如你项目里已经有“用户登录”功能,这里就有specs/auth/spec.md,写着“当前登录只支持密码验证,密码长度≥8位”,相当于项目的“需求字典”,不用再翻旧代码找规则;openspec/changes/:存“新需求规范”——比如你想给登录加短信验证,就会在changes/add-sms-login/里生成新的规范文档,写着“要加手机号验证,验证码6位、有效期5分钟”,新需求和老需求分开,不会混在一起。
比如你要改“老项目的支付流程”,不用再花半天读旧代码,直接看 specs/payment/spec.md 就知道现有规则;新需求的规范文档单独放在 changes/ 里,改哪里、为什么改,一目了然,AI 也不会因为不了解老需求而改错代码。
3. 变更全追踪:每一次需求修改,规范文档都存档
用 AI 写代码,最怕过了半个月想不起“当时为什么要加这个逻辑”——OpenSpec 把每一次需求变更的全流程都用规范文档存档,从“提议”到“落地”,每一步都有记录。
比如你要加“短信登录”功能,OpenSpec 会生成一个独立的变更文件夹 openspec/changes/add-sms-login/,里面的规范文档分工明确:
proposal.md:写“为什么要加这个功能”(比如“用户反馈密码登录不安全”)和“要改哪些规则”(比如“登录页面加手机号输入框”);tasks.md:写“怎么实现”的步骤清单(比如“1. 加短信发送接口;2. 改登录接口支持验证码;3. 加验证码输入框UI”),完成一个就标✓;specs/auth/spec.md:写“改后的规则补丁”(比如在原有登录规范里加“短信验证的场景”),不是重写整个文档,只看这个就知道改了什么。
等功能做完,你执行 openspec archive 命令,这个变更文件夹会自动移到 changes/archive/ 里存档,同时把新规则合并到 specs/auth/spec.md 里。以后想查“当时为什么加短信登录”,直接打开 archive/add-sms-login/proposal.md 就行,不用翻聊天记录。
4. 兼容主流 AI 编程助手:你用的 AI,基本都能搭
不用为了用 OpenSpec 换 AI 工具——它支持市面上大部分热门的 AI 编程助手,而且分两种简单的兼容方式,怎么方便怎么来:
第一种是“原生命令支持”:这些 AI 工具直接内置了 OpenSpec 的命令,你输个“/openspec”就能调出功能,规范文档的生成、修改都能靠命令快速触发,比如:
Claude Code:用
\openspec:proposal生成需求提案文档、\openspec:archive归档变更文档;Cursor、OpenCode:用
\openspec-proposal生成提案、\openspec-archive归档;GitHub Copilot:命令存在
.github/prompts/文件夹里,直接调用就能生成规范文档。
第二种是“AGENTS.md 兼容”:有些 AI 工具(比如 Gemini CLI、Amp)没有原生命令,但能读项目根目录的 AGENTS.md 文件——OpenSpec 初始化时会自动生成这个文档,里面写好了“怎么用规范文档工作”的步骤(比如“第一步:创建需求提案文档;第二步:验证文档格式;第三步:实现;第四步:归档”)。你只要跟 AI 说“照着 AGENTS.md 里的 OpenSpec 流程,帮我生成需求规范文档”,AI 就知道该怎么做。
不管你用的是哪个 AI,只要能读 Markdown 文档,就能用 OpenSpec 管理需求。
5. 对比同类工具:规范文档管理更灵活
可能你会问“跟 spec-kit、Kiro 这些工具比,OpenSpec 好在哪?”——核心差别在“规范文档的管理方式”,更适合实际开发中的需求变更。用表格对比一下,一眼就能看明白:
| 对比维度 | OpenSpec | spec-kit | Kiro.dev |
|---|---|---|---|
| 核心解决痛点 | 需求模糊、变更难追溯(靠规范文档存档) | 新功能需求不明确(靠初始 spec 文档) | 新功能需求碎片化(靠分散 spec 文档) |
| 规范文档管理方式 | 双文件夹(specs 存现有、changes 存新需求) | 单文件夹(所有 spec 混在一起) | 多文件夹(按功能分散存 spec) |
| 存量项目适配 | 直接初始化,不用重构旧需求文档 | 需重新整理旧功能为 spec 文档 | 需重新整理旧功能为 spec 文档 |
| 跨需求变更支持 | 强(同一变更可改多个规范文档) | 弱(需手动关联多个 spec 文档) | 弱(需手动定位多个 spec 文档) |
| API 密钥依赖 | 无(纯本地规范文档管理) | 部分功能需要 | 部分功能需要 |
简单说:如果你的需求经常变、要改旧项目,或者需要跨多个功能模块改需求,OpenSpec 的规范文档管理方式更灵活;如果只是做从0开始的新项目,spec-kit 和 Kiro 也能用,但后续需求变更时,规范文档的追踪会麻烦很多。
三、技术细节:OpenSpec 是怎么靠规范文档工作的?
虽然用起来简单,但 OpenSpec 的技术设计都是围绕“让规范文档好用、好管”展开的,主要看3个方面:技术栈、目录结构、规范文档格式。
1. 技术栈:轻量但稳定,都是你熟悉的工具
OpenSpec 的技术栈没有冷门工具,前端/全栈开发者一看就懂,维护和二次开发都方便:
运行环境:Node.js ≥20.19.0(必须满足,低版本可能有兼容问题,用
node --version能查自己的版本);开发语言:TypeScript(强类型,减少代码错误,项目里的
src/文件夹全是 TS 代码,规范文档的格式验证逻辑也靠 TS 实现);包管理:pnpm(比 npm、yarn 更快,依赖管理更严格,项目里的
pnpm-lock.yaml会锁定依赖版本,避免“别人能用我不能用”的问题);CLI 框架:Commander.js(行业常用的 CLI 开发框架,负责解析
openspec list、openspec archive这些命令,帮你快速操作规范文档);测试工具:vitest(轻量的测试框架,项目里的
test/文件夹是测试代码,确保规范文档的格式验证、归档等功能不会出 bug);构建工具:自定义
build.js(把 TS 代码编译成 JS,供 CLI 调用,确保不同系统都能正常运行)。
另外,项目支持跨平台(Windows、Mac、Linux),不管你用什么电脑,初始化和管理规范文档的过程都不会出问题——这是靠“跨平台 CI 矩阵测试”保证的,代码提交前会在不同系统上跑一遍,确保规范文档的生成、修改、归档功能都正常。
2. 核心目录结构:规范文档放在哪,一看就懂
OpenSpec 在你项目里生成的文件夹结构很固定,不用死记硬背,重点就是“规范文档的分类存放”:
你的项目/ ├── openspec/ # OpenSpec 核心文件夹,初始化后自动生成(所有规范文档都在这) │ ├── specs/ # 「现有需求规范库」:存项目已经实现的需求规则(比如“当前登录只支持密码”) │ │ └── [功能模块]/ # 按功能分文件夹,比如 auth(登录)、order(订单)、profile(个人资料) │ │ └── spec.md # 具体的需求规范文档(Markdown 格式,比如写“登录密码长度≥8位”) │ ├── changes/ # 「新需求规范库」:存待实现、正在实现的需求变更(比如“要加短信登录”) │ │ ├── [变更名称]/ # 按变更分文件夹,比如 add-sms-login(加短信登录)、add-order-export(加订单导出) │ │ │ ├── proposal.md # 需求提案文档:为什么改、改什么(比如“用户反馈密码登录不安全,要加短信验证”) │ │ │ ├── tasks.md # 实现任务文档:步骤清单(比如“1. 加短信接口;2. 改登录UI”) │ │ │ ├── design.md # 技术设计文档(可选,复杂需求用,比如“短信接口用阿里云SDK”) │ │ │ └── specs/ # 新需求的规范补丁:只写改了什么(比如在 auth/spec.md 里加“短信验证规则”) │ │ └── archive/ # 「已归档需求库」:完成的需求变更都移到这,存档用(比如 2025-10-15-add-sms-login) │ └── AGENTS.md # AI 工具指南文档:告诉 AI 怎么用规范文档工作(自动生成,不用手动写) └── package.json # 项目依赖:OpenSpec 会把自己加进 devDependencies,方便团队共享
重点说两个跟规范文档相关的核心文件夹:
specs/:这是项目的“需求真理库”,比如你项目有登录功能,就有specs/auth/spec.md,里面写的都是已经落地的规则,AI 改旧功能时会先看这个文档,不会偏离现有需求;changes/[变更名称]/specs/:这是“需求补丁库”,比如你要加短信登录,这里的auth/spec.md只写“要加短信验证”的新规则,不是重写整个登录规范——这样对比旧需求时,只看这个文件就知道改了什么,不用翻完整文档,效率很高。
3. 规范文档格式:怎么写,AI 才会懂?
OpenSpec 的规范文档用 Markdown 写,语法很简单,但有几个“必须遵守”的规则——不然 AI 可能读不懂,或者 openspec validate 命令会报错(验证文档格式的命令),核心是“让需求规则清晰、无歧义”。
(1)Delta 格式:明确“改了什么”
所有新需求的规范补丁(changes/[变更名称]/specs/[模块]/spec.md)必须用“Delta 格式”,也就是明确标注“新增、修改、删除”了哪些规则,避免 AI 不知道是加功能还是删功能。比如:
## ADDED Requirements:新增的规则(比如“登录支持短信验证”);## MODIFIED Requirements:修改的规则(比如把“密码长度≥6位”改成“≥8位”,要写完整的修改后内容,不能只写“改长度”);## REMOVED Requirements:删除的规则(比如“登录支持微信登录”,要说明删除原因,比如“用户用得少,维护成本高”)。
这样 AI 一看就知道“要做什么操作”,不会把“改规则”当成“加规则”。
(2)每个规则必须有“场景”:避免需求模糊
不能只写“要支持短信验证”,必须加“场景(Scenario)”,说明“什么时候触发这个规则、会有什么结果”——不然 AI 可能会随便写逻辑(比如不知道验证码有效期多久)。比如:
### Requirement: 登录支持短信验证 系统必须在用户选择“短信登录”时,发送6位验证码到用户手机,且验证码有效期为5分钟。 #### Scenario: 用户发起短信登录 - WHEN 用户点击“短信登录”并输入正确的11位手机号 - THEN 系统发送6位数字验证码到该手机号 - AND 按钮显示“60秒后重发”,60秒内不能再次点击 - AND 验证码输入框只能输入数字,最多输6位
这样 AI 就知道“具体要实现哪些细节”,不会漏做“60秒重发限制”“输入框校验”这些功能。
(3)用“MUST/SHALL”明确强制性:避免 AI 偷工减料
规则里要用特定词汇表强制程度,AI 能快速理解“哪些是必须做的,哪些是可选的”:
“MUST”:必须实现,不实现就不符合规范(比如“验证码必须是6位数字”,AI 不能写成4位);
“SHALL”:应该实现,特殊情况可调整(比如“验证码应该用短信发送,没有短信服务时可用邮件”);
“SHOULD”:建议实现,不是强制(比如“登录页面应该加‘获取验证码’的图标,提升用户体验”)。
这些词汇是行业通用的,你和 AI 都不会有理解偏差。
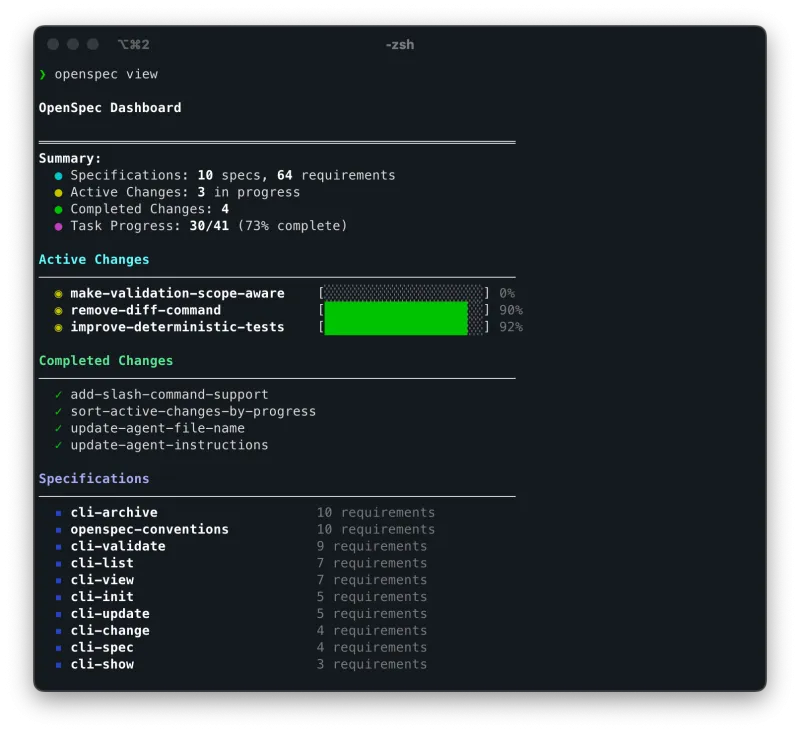
四、应用场景:哪些时候用 OpenSpec 最爽?
不是所有 AI 编程场景都需要 OpenSpec,但这4种场景用它,能彻底解决“需求模糊”的问题,效率直接翻倍:
1. 存量项目迭代:改旧功能不用翻旧代码找需求
比如你接手一个3年前的老项目,要给“订单管理”加“按物流状态筛选”功能——旧项目没有文档,你不知道“现有筛选逻辑是怎么写的”“有没有特殊规则(比如‘已取消订单不能筛选’)”,直接让 AI 写代码,很可能改崩旧功能。
这时候用 OpenSpec,靠规范文档就能解决:
先让 AI 生成
openspec/specs/order/spec.md,把现有订单筛选的规则整理出来(比如“当前支持按订单号、下单日期筛选,筛选结果按日期倒序排列”);再创建新需求的规范文档
changes/add-logistics-filter/,写清楚“要加物流状态筛选(待发货/已发货/已签收)”“筛选后要显示物流单号和预计送达时间”“已取消订单不显示在筛选结果里”;确认规范文档没问题后,AI 会照着文档改代码——它知道现有规则是什么,不会把“按日期筛选”的功能删掉,也不会漏加“已取消订单过滤”的逻辑。
不用再花半天读旧代码找需求,规范文档直接帮你理清“现有是什么、要改什么”。
2. 跨多个功能的需求:改一处牵多处,不用记
比如你要做“用户等级体系”,这个需求会影响3个地方:
个人资料页:显示用户等级(比如“VIP1/VIP2”);
订单折扣:VIP 用户下单打9折,VIP2 打8.5折;
权限管理:VIP2 以上能看专属优惠活动。
如果直接让 AI 写代码,很容易漏改某个地方(比如只改了个人资料页,没改订单折扣)——因为需求散在聊天里,AI 记不住所有关联点。用 OpenSpec 的规范文档,就能把关联需求整合起来:
你创建变更文件夹
changes/add-user-level/,在proposal.md里写清楚“这个需求会影响个人资料、订单、权限3个模块”;在
tasks.md里分3部分列任务(“1. 个人资料页加等级显示;2. 订单系统加折扣逻辑;3. 权限系统加 VIP2 规则”),每个任务都对应一个子规范文档;在
changes/add-user-level/specs/里,分别放3个模块的规范补丁(profile/spec.md、order/spec.md、permission/spec.md),每个补丁写清楚该模块要改的规则。
AI 会照着任务清单一个个做,做完一个标✓(比如“Task 1.1 ✓ 个人资料页等级图标添加完成”),不会漏任何一个模块——因为所有关联需求都在规范文档里,它不用“记”,只要“看”就行。
3. 团队协作:多人用不同 AI,需求不打架
比如你们团队3个人:A 用 Claude Code,B 用 Cursor,C 用 GitHub Copilot,要一起做“支付退款”功能。没有 OpenSpec 的话,A 跟 Claude 说“退款要24小时到账”,B 跟 Cursor 说“退款要实时到账”,C 跟 Copilot 说“退款要手动审核”,最后代码合并时全是冲突,还要花时间扯皮“到底按谁的需求来”。
用 OpenSpec 的规范文档,就能统一需求标准:
团队一起初始化项目,生成
AGENTS.md和specs/payment/spec.md;开会确定“退款规则”后,一起写
changes/add-refund-function/proposal.md,里面明确“退款默认24小时到账,VIP 用户实时到账,金额≥1000元需手动审核”;不管谁用什么 AI,都照着这个规范文档做:A 写退款接口,B 写退款页面,C 写审核流程,每个人的代码都符合同一个需求标准。
不用再同步“你跟 AI 说了什么”,规范文档就是唯一的需求依据,协作效率直接拉满。
4. 需要审计的场景:要留痕,能追溯
比如你在做企业项目,客户要求“每一个功能变更都要有记录,能查是谁改的、为什么改”——这时候 OpenSpec 的规范文档归档功能就派上用场了。
每个需求完成后,你执行 openspec archive 命令,它会做两件事:
把变更文件夹移到
changes/archive/,并在文件名里加归档日期(比如2025-10-15-add-refund/),里面的proposal.md、tasks.md都保留,谁写的、什么时候改的,Git 记录里都能查;把改后的规则合并到
specs/里,确保specs里的文档永远是最新的需求标准。
客户要查“2025年10月加的退款功能为什么要24小时到账”,你直接打开 archive/2025-10-15-add-refund/proposal.md,里面写着“客户要求‘避免瞬时大额退款导致账户波动’”,一目了然——不用翻聊天记录或会议纪要,规范文档就是最好的审计证据。
五、使用方法
说了这么多,到底怎么用 OpenSpec 生成、管理规范文档?其实就5步:准备环境→装 CLI→初始化→做需求变更→归档。全程不用写复杂代码,跟着做就行,以“给项目加‘短信登录’功能”为例:
1. 第一步:准备环境(5分钟)
OpenSpec 依赖 Node.js,所以先确认你电脑上有 Node.js,而且版本≥20.19.0:
打开终端(Windows 用 CMD 或 PowerShell,Mac 用终端);
输入
node --version,如果显示v20.19.0或更高版本,就没问题;如果版本不够,去 Node.js 官网(https://nodejs.org/)下载 20.19.0 以上的 LTS 版本,安装时一路点“下一步”就行(不用改任何默认设置)。
不用装其他依赖,Node.js 自带 npm(包管理工具),后续装 OpenSpec CLI 要用。
2. 第二步:安装 OpenSpec CLI(1分钟)
CLI 是“命令行工具”,你所有操作(比如生成规范文档、归档需求)都靠它。安装很简单,终端里输一行命令:
npm install -g @fission-ai/openspec@latest
“-g”表示“全局安装”,以后不管在哪个项目里,都能调用
openspec命令;“@latest”表示装最新版本,避免用旧版有 bug(比如规范文档格式验证出错)。
安装完后,输 openspec --version 验证一下,如果显示版本号(比如 0.8.1),就说明装好了。
3. 第三步:初始化项目(2分钟)
打开你要加 OpenSpec 的项目(比如你的项目叫 my-project),先进入项目目录:
cd my-project # 把“my-project”换成你的项目路径,比如“C:\Users\XXX\my-project”
然后执行初始化命令:
openspec init
接下来会弹出两个简单的提示,跟着选就行,核心是“让 OpenSpec 知道你用什么 AI 工具,方便后续生成规范文档”:
提示1:“Pick natively supported AI tools”(选你常用的 AI 工具)——比如你用 Claude Code 和 GitHub Copilot,就按空格选中这两个,然后按回车;
提示2:“Do you want to create a project.md?”(要不要创建项目文档)——选“Y”(默认就是 Y),它会生成
openspec/project.md,记录项目技术栈、负责人这些信息(比如“项目用 React + Node.js,负责人 XXX”),方便 AI 理解项目背景,生成更精准的规范文档。
初始化完成后,你会看到项目里多了 openspec/ 文件夹和根目录的 AGENTS.md 文件——这就表示成功了,以后所有规范文档都放在 openspec/ 里。
4. 第四步:创建第一个需求变更(核心步骤,10分钟)
这一步是重点——用规范文档明确“要加短信登录”的需求,再让 AI 照着文档写代码。
(1)起草需求提案文档
打开你的 AI 工具(比如 Claude Code),输入指令:
帮我创建 OpenSpec 变更提案,功能是给登录加短信验证,需求细节:1. 手机号必须是11位;2. 验证码6位,有效期5分钟;3. 发送验证码后60秒内不能重发;4. 验证码错误要提示“验证码不正确,请重新输入”。
如果你的 AI 支持原生命令,直接输 \openspec:proposal 加短信登录,再补充上面的需求细节——AI 会自动生成变更文件夹 openspec/changes/add-sms-login/,里面包含3个核心规范文档:
proposal.md:写清楚“为什么加这个功能”(比如“用户反馈密码登录不安全,提升账号安全性”)和“要改的需求”;tasks.md:生成实现步骤(比如“1. 加短信发送接口;2. 改登录页面 UI;3. 加验证码验证逻辑”);specs/auth/spec.md:短信登录的规范补丁(比如“新增‘短信登录’的规则和场景”)。
(2)验证规范文档格式
终端里输命令,检查 AI 生成的规范文档有没有格式错误(比如漏了 Scenario、没标 ADDED/MODIFIED):
openspec validate add-sms-login
如果显示“Validation passed”,说明文档格式没问题,AI 能读懂;
如果报错(比如“Missing Scenario for Requirement: 短信登录”),就跟 AI 说“修复 openspec/changes/add-sms-login/specs/auth/spec.md 的格式错误,给‘短信登录’的 Requirement 加一个 Scenario,包含 WHEN/THEN 逻辑”,AI 会自动修改文档。
(3)查看并细化规范文档
想看看 AI 生成的规范文档具体是什么样,输命令:
openspec show add-sms-login
终端会显示 proposal.md、tasks.md 和 specs 的内容,你可以根据实际需求细化:
如果觉得任务漏了(比如 AI 没写“加验证码错误提示的 UI”),跟 AI 说“在 openspec/changes/add-sms-login/tasks.md 里加‘4. 登录页面加验证码错误提示,红色字体’”;
如果规范不对(比如 AI 写“验证码有效期10分钟”,你要5分钟),跟 AI 说“把 openspec/changes/add-sms-login/specs/auth/spec.md 里的验证码有效期改成5分钟”。
反复细化,直到你觉得“这就是我要的需求”——规范文档越详细,AI 写的代码越精准,不用后续返工。
(4)让 AI 照着规范文档实现功能
规范文档确认没问题后,跟 AI 说:
按照 openspec/changes/add-sms-login/tasks.md 里的步骤实现短信登录功能,完成一个任务就标上✓,遇到不清楚的地方看 specs/auth/spec.md 里的规范。
如果 AI 支持原生命令,直接输 \openspec:apply add-sms-login——AI 会自动读取 tasks.md 和 specs 里的文档,一步步写代码:
先做“1. 加短信发送接口”,用你项目的技术栈(比如 Node.js + Express)写接口,写完标“Task 1.1 ✓”;
再做“2. 改登录页面 UI”,加手机号输入框、验证码输入框和发送按钮,写完标“Task 2.1 ✓”;
最后做“3. 加验证码验证逻辑”,判断验证码是否正确、是否过期,写完标“Task 3.1 ✓”。
过程中如果 AI 不知道某个细节(比如“短信接口用哪个 SDK”),你只要补充说明(比如“用阿里云短信 SDK,密钥存在 .env 文件里”),AI 会调整代码——所有调整都基于规范文档,不会偏离需求。
5. 第五步:归档需求变更(1分钟)
功能实现完,测试没问题后,就可以归档了——把新需求的规范文档合并到“现有需求库”,并存档留痕。
终端里输命令:
openspec archive add-sms-login --yes
“--yes”表示“不用再确认,直接归档”,省得弹提示;
归档完成后,
openspec/changes/add-sms-login/会移到openspec/changes/archive/(存档用,以后能查),specs/auth/spec.md会更新为“支持密码+短信登录”的最新规范文档。
至此,整个“加短信登录”的流程就完成了——所有需求都在规范文档里,下次改登录功能,直接看 specs/auth/spec.md 就行。
常用 CLI 命令汇总(规范文档操作必备)
记不住命令没关系,这里整理了最常用的几个,存起来备用——每个命令都和规范文档的操作相关:
| 命令 | 作用 | 例子 |
|---|---|---|
openspec --version | 查看 OpenSpec 版本(确认是否安装成功) | - |
openspec init | 初始化项目,生成规范文档的文件夹结构 | - |
openspec list | 查看所有正在进行的需求变更(看有哪些未归档的规范文档) | - |
openspec show <变更名> | 查看某个变更的规范文档内容(提案+任务+补丁) | openspec show add-sms-login |
openspec validate <变更名> | 验证某个变更的规范文档格式是否正确 | openspec validate add-sms-login |
openspec archive <变更名> --yes | 归档完成的变更,合并规范文档到 specs | openspec archive add-sms-login --yes |
openspec view | 打开交互式面板,可视化查看所有规范文档和变更 | - |
六、常见问题解答(FAQ)
1. AI 工具不显示 OpenSpec 的命令(比如 Claude 不显示 \openspec:proposal)?
这是最常见的问题,原因是“AI 工具启动时没加载 OpenSpec 的命令配置”——解决方法很简单:
关掉 AI 工具(比如关掉 Claude Code 的窗口、重启 Cursor);
重新打开工具,再输“\openspec”,命令就会出来了——此时生成规范文档的命令就能正常用。
2. 初始化项目时选了错误的 AI 工具,能改吗?
可以改,不用重新初始化,只要两步:
终端里进入项目目录,输
openspec update——这个命令会重新生成AGENTS.md和 AI 工具的命令配置;重新选你要的 AI 工具,按回车确认——配置更新后,新选的 AI 工具就能正常生成、读取规范文档了。
3. 规范文档写错了,能改吗?
当然能,直接改就行,改完验证一下格式:
找到要改的规范文档(比如
openspec/changes/add-sms-login/proposal.md);用记事本、VS Code 等工具编辑内容(比如把“验证码有效期5分钟”改成“10分钟”);
终端输
openspec validate add-sms-login,确认格式没问题——改完后 AI 会读最新的文档内容,不会用旧需求。
4. 归档后的规范文档,还能查看吗?
能,归档不是删除,只是把变更文件夹移到了 openspec/changes/archive/ 里:
直接打开项目里的
openspec/changes/archive/[变更名]/文件夹,里面的proposal.md、tasks.md、specs都还在,用记事本打开就能看;或者用终端命令:
openspec show changes/archive/[变更名](比如openspec show changes/archive/add-sms-login),也能查看文档内容。
5. 我的 AI 工具不在支持列表里,能用法 OpenSpec 吗?
可以,只要这个 AI 能读 Markdown 文档,靠 AGENTS.md 就行:
初始化项目后,打开根目录的
AGENTS.md——里面写好了“用规范文档工作”的步骤(比如“第一步:创建需求提案文档;第二步:验证格式;第三步:实现;第四步:归档”);跟 AI 说“照着 AGENTS.md 里的 OpenSpec 流程,帮我生成‘加订单导出’的需求规范文档”——AI 会按照文档里的步骤生成
proposal.md、tasks.md,不用原生命令也能用。
6. 执行 openspec init 时,报错“Node.js 版本不够”怎么办?
OpenSpec 要求 Node.js ≥20.19.0,低于这个版本会报错,解决方法:
去 Node.js 官网(https://nodejs.org/)下载 20.19.0 或更高的 LTS 版本;
安装时选择“覆盖旧版本”(不用卸载旧版本,安装程序会自动替换);
重启终端,输
node --version确认版本,然后重新执行openspec init。
7. 多人协作时,两个人同时改同一个规范文档,会冲突吗?
会,但有办法避免,跟代码冲突的解决方式一样:
改规范文档前,先拉取最新代码(比如用 Git 的
git pull),确保你拿到的是团队最新的文档;如果两个人都改了同一个文档(比如
specs/auth/spec.md),Git 会提示冲突,打开冲突文件,对照两个人的修改内容,合并成统一的规范(比如 A 加了“短信登录”,B 加了“密码重置”,就把两个规则都保留);合并后,执行
openspec validate确认格式没问题,再提交代码——这样团队的规范文档就统一了。
8. 规范文档太复杂,AI 读不懂怎么办?
简化文档内容,突出核心需求,比如:
把长句子拆成短句(比如“登录页面要加手机号输入框和验证码输入框,验证码输入框后面要加发送按钮”改成“1. 登录页面加手机号输入框;2. 加验证码输入框;3. 验证码输入框后加‘发送验证码’按钮”);
去掉无关细节(比如暂时不用写“按钮的颜色是蓝色”,先让 AI 实现功能,后续再优化 UI);
用列表代替大段文字——改完后再让 AI 读,基本都能懂。
七、相关链接
GitHub 仓库:https://github.com/Fission-AI/OpenSpec
八、总结
OpenSpec 是一款专为 AI 编程设计的开源辅助工具,核心靠“结构化规范文档”解决“需求模糊、变更难追溯”的痛点。它无需 API 密钥,通过轻量级工作流让人类与 AI 编程助手在写代码前对齐需求,支持存量项目迭代,能追踪每一次需求变更的全流程(提案→验证→实现→归档),兼容主流 AI 编程助手。技术栈基于 TypeScript 和 Node.js,上手简单,规范文档用 Markdown 编写,格式灵活且易于理解。无论是个人开发者改旧功能,还是团队协作做跨模块需求,OpenSpec 都能通过规范文档减少返工、提升效率,且遵循 MIT 许可,可免费用于个人和企业项目,是 AI 编程场景下解决需求管理问题的实用工具。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/openspec.html





