PlanningBench:腾讯混元开源大模型规划能力评测与训练框架
一、PlanningBench是什么
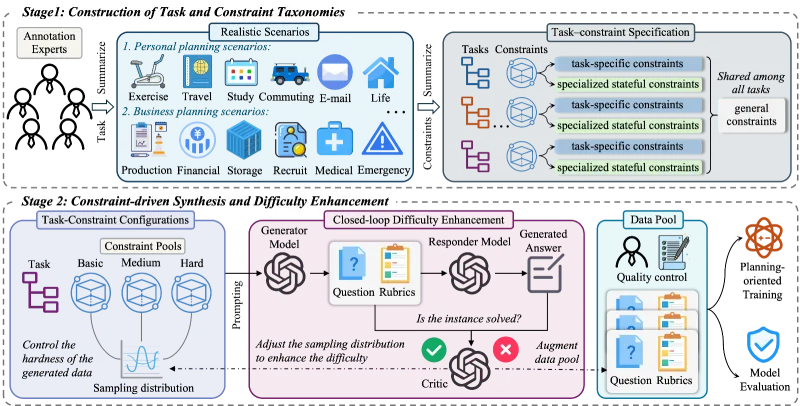
PlanningBench 是由腾讯混元(Tencent-Hunyuan)联合中国人民大学高瓴人工智能学院共同研发并开源的一套面向大语言模型(LLM)的规划能力评测、数据集生成与模型优化一体化框架,项目托管于 GitHub 开源社区,配套学术论文同步发布于 arXiv。
在大模型落地过程中,复杂逻辑规划、多约束条件任务拆解、资源调度、流程编排是衡量模型实用能力的核心指标。传统评测数据集大多场景单一、约束简单、缺乏自动化校验能力,无法真实反映大模型在真实业务中的规划水平。针对这一行业痛点,PlanningBench 打造了可扩展、可自动化验证的规划任务体系,既可以作为标准评测基准横向对比各类大模型的规划能力,也能生成高质量标注数据用于大模型微调、专项能力训练,填补了大模型规划方向标准化开源工具的空白。
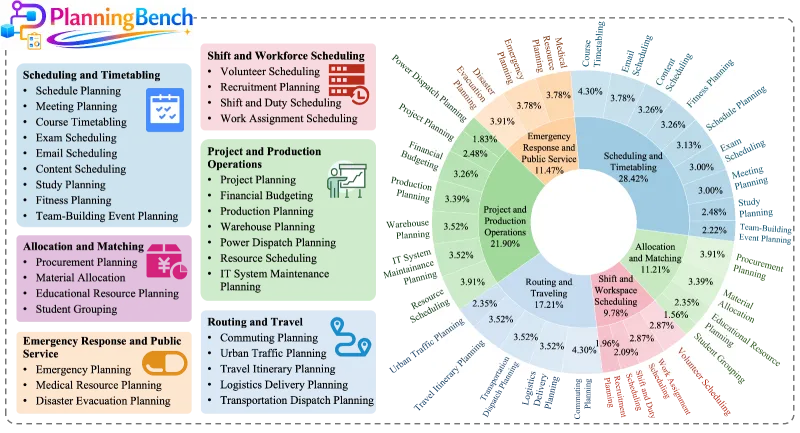
该框架内置多场景规划任务模板、动态难度调节机制与自动化结果校验模块,附带 467 条高质量原生评测样本,覆盖日常办公、生产调度、应急处置、路径规划等全维度真实场景,是科研人员、算法工程师、AI 应用开发者评估、训练、优化大模型规划能力的核心开源工具。
二、功能特色
PlanningBench 围绕数据生成、模型评测、结果校验、模型训练四大核心环节设计功能,整体具备高实用性、高扩展性、强自动化三大核心特质,具体特色如下:
全品类规划任务覆盖
框架归纳现实世界主流规划场景,划分六大核心任务大类,延伸出 30 余种细分任务类型,彻底摆脱传统评测数据集场景单一的问题。任务包含日程排布、人力排班、资源分配、路径调度、生产运营、应急服务六大方向,完全贴合企业办公、工业生产、公共服务等真实业务需求。动态难度自适应调控
区别于仅通过增加文本长度提升难度的传统方案,PlanningBench 从任务结构、约束层级、资源紧张度、逻辑关联度四个维度动态调整任务难度。开发者可根据测试需求,一键生成简单入门、中等复杂度、高难度极限挑战三类规划任务,适配不同能力层级大模型的评测场景。自动化结果校验体系
内置标准化约束校验清单(Checklist),可自动检测大模型输出的规划方案是否满足全部前置约束、资源上限、流程顺序、目标要求,能够精准识别“局部合理、整体无法落地”的无效方案,规避人工审核效率低、标准不统一的问题。评测+训练闭环能力
框架不仅支持模型能力打分、指标量化评测,还可批量生成结构化、高多样性的规划类标注数据集。生成的数据可直接用于大模型微调、专项能力蒸馏,实现“问题诊断—数据生产—模型优化”的完整技术闭环。轻量化易部署设计
项目代码结构清晰、依赖组件精简,支持本地单机部署与小规模集群运行,无需高端算力集群即可完成常规评测与数据生成工作,降低个人开发者、小型团队的使用门槛。原生开源可拓展
代码完全开源开放,支持开发者自定义新增任务模板、补充行业专属约束规则、对接自研大模型,可快速适配金融、物流、政务、制造等垂直行业的定制化规划评测需求。

三、技术细节
3.1 整体架构
PlanningBench 采用分层模块化架构,整体分为五层,模块之间低耦合、高内聚,便于单独迭代与二次开发:
交互接入层:负责对接各类大模型 API、本地部署模型、推理服务,统一请求与返回格式,兼容主流开源模型与商用大模型。
任务生成层:核心模块,基于预设场景模板、规则引擎、随机变量生成多样化规划任务,同时完成难度参数配置。
任务执行层:向接入的大模型下发规划任务,收集模型输出结果,统一格式预处理。
规则校验层:加载约束清单、逻辑规则、资源阈值,自动化校验方案合法性、可行性、最优性,并输出量化得分。
数据输出层:汇总评测报告、错误案例、生成的训练数据集,支持本地文件导出、日志记录、可视化统计。
3.2 核心技术模块解析
3.2.1 任务生成引擎
任务生成引擎是框架的核心组件,基于规则模板+随机变量组合实现海量差异化任务生成:
预先为 6 大类别、30 余种细分任务搭建标准化场景模板,固定任务主体、基础规则;
引入动态变量:人员数量、物资总量、时间窗口、限制条件、优先级规则等,随机组合生成不重复任务;
难度参数接口:通过代码参数调整约束数量、资源稀缺程度、流程嵌套层数,实现难度分级。
3.2.2 自动化校验引擎
校验引擎采用规则匹配+逻辑推理双机制工作:
硬规则匹配:校验资源总量、时间区间、人员权限等硬性限制,判断方案是否违反基础条件;
软逻辑推理:校验流程先后顺序、任务优先级、全局最优性,识别逻辑矛盾、流程错乱等问题;
量化打分机制:按照约束满足率、方案可行性、执行效率三个维度计算综合得分,输出标准化评测指标。
3.2.3 数据格式与存储
框架生成的评测任务、训练数据统一使用 JSON 格式存储,字段规范统一,可直接适配主流大模型训练框架(Transformers、LLaMA Factory 等)。核心字段包含:任务描述、约束条件、标准答案/校验规则、难度标签、场景分类。
3.3 环境依赖与运行要求
基础运行环境:Python 3.8 及以上版本;
核心依赖库:
torch、transformers、json、argparse、logging等通用 AI 工具库;硬件要求:常规 CPU 即可完成任务生成与评测;对接大模型推理时,硬件配置跟随对应模型需求。
3.4 核心代码结构简述
项目根目录划分清晰,关键目录与文件作用如下:
PlanningBench/ ├── benchmarks/ # 所有规划任务模板、规则文件、校验清单 ├── data/ # 原生评测样本、生成数据集默认存储目录 ├── engine/ # 任务生成引擎、校验引擎核心代码 ├── models/ # 大模型对接适配代码 ├── utils/ # 工具函数、日志、格式转换工具 ├── config.py # 全局配置文件(难度、路径、模型接口) ├── run_eval.py # 一键启动模型评测主程序 └── run_data_gen.py # 一键启动数据集生成主程序
四、应用场景
PlanningBench 面向AI 科研、大模型研发、行业落地、教学实训四大方向,覆盖多类使用人群,具体应用场景如下:
大模型能力横向评测
企业、科研机构可使用框架作为统一基准,对比多款开源/商用大模型在规划、调度、流程拆解方面的能力差异,为模型选型、版本迭代提供客观数据支撑。大模型专项能力训练与微调
针对规划能力薄弱的大模型,利用框架批量生成垂直场景标注数据,开展专项微调、指令对齐,提升模型在复杂任务下的逻辑编排能力。垂直行业 AI 方案测试
物流路径规划、工厂生产排班、企业人事调度、政务应急指挥、会议日程安排等行业,可基于框架自定义行业规则,测试行业专属 AI 应用的规划可靠性。AI 算法科研与学术研究
高校、实验室可基于该框架开展大模型规划能力、推理能力、复杂问题求解方向的学术实验,框架自带标准化数据集与评测指标,可直接用于论文实验。技术教学与实训
AI 相关专业教学、开发者实训场景中,可借助可视化的规划任务、校验结果,讲解大模型逻辑推理、任务拆解的原理与缺陷。
五、使用方法
5.1 环境准备
克隆项目代码,打开终端执行拉取命令:
git clone https://github.com/Tencent-Hunyuan/PlanningBench.git cd PlanningBench
安装项目依赖包:
pip install -r requirements.txt
根据自身 Python 版本、系统环境,完成基础环境校验,确保无依赖报错。
5.2 基础配置
打开项目内 config.py 配置文件,完成核心参数设置:
配置大模型对接方式:本地模型路径或商用模型 API 地址、密钥;
设置任务难度等级、单次生成任务数量、数据存储路径;
选择需要启用的任务场景分类。
5.3 运行模型评测
执行评测脚本,对接入的大模型进行规划能力全量测试:
python run_eval.py
程序自动加载内置 467 条标准样本,下发任务、收集结果、自动化校验,最终在 output/ 目录生成评测报告、得分明细、错误案例汇总。
5.4 批量生成训练数据集
如需制作规划领域训练数据,执行数据生成脚本:
python run_data_gen.py
可通过脚本入参指定任务类型、难度、数据量,生成的 JSON 格式数据集自动保存至 data/ 目录,可直接用于模型训练。
5.5 自定义拓展任务模板
进入
benchmarks/目录,参照现有模板格式新建场景文件;编写自定义任务描述、约束规则、校验逻辑;
在配置文件中注册新模板,重启程序即可使用自定义规划任务。
六、竞品对比
选取当前大模型规划/推理领域主流开源评测框架 BigCodeEval、ReasoningBench 与 PlanningBench 进行横向对比,从定位、核心能力、场景、校验机制、拓展性等维度区分差异。
| 对比维度 | PlanningBench | BigCodeEval | ReasoningBench |
|---|---|---|---|
| 项目定位 | 专注通用+行业规划任务评测与数据生成 | 专注代码编写、代码逻辑任务评测框架 | 专注数学推理、逻辑计算题评测基准 |
| 核心场景 | 排班、调度、资源分配、路径规划、应急流程 | 代码生成、代码纠错、工程逻辑编写 | 数学题、逻辑推理、数理证明 |
| 自动化校验 | 内置规则引擎,全自动校验方案可行性 | 运行代码执行结果校验,语法+功能双重校验 | 答案匹配+步骤推理校验,偏向标准答案比对 |
| 难度调控 | 支持约束、资源、嵌套多层级动态调优 | 依靠代码复杂度、工程规模调整难度 | 依靠题目计算量、逻辑步骤提升难度 |
| 数据生成能力 | 原生支持批量生成规划类训练数据 | 仅评测,无原生数据生成模块 | 仅评测,不支持自定义数据集生成 |
| 行业适配性 | 适配物流、制造、政务、人力等实体行业 | 仅面向编程、开发领域 | 仅面向数理推理场景 |
| 开源主体 | 腾讯混元 & 中国人民大学 | 社区联合开源 | 学术团队开源 |
总结差异:三款工具定位完全区分,PlanningBench 是目前少有的聚焦真实世界规划调度的一体化框架,兼具评测与数据生产能力;另外两款分别深耕代码、数理推理赛道,场景互不重叠。
七、常见问题解答
1. PlanningBench 支持本地部署的开源大模型吗?
支持。框架预留了通用模型对接接口,主流开源大模型均可通过本地推理方式接入,仅需在配置文件中填写模型本地路径与推理参数即可正常使用。
2. 项目内置的 467 条评测样本可以商用吗?
该项目整体为开源项目,内置原生评测样本遵循项目开源协议,在遵守协议条款的前提下,可用于企业内部评测、产品测试等商用场景。
3. 运行程序时报依赖库缺失该如何解决?
优先执行 pip install -r requirements.txt 完整安装依赖;若仍出现版本冲突,可创建独立 Python 虚拟环境,隔离系统原有环境后重新安装依赖运行。
4. 能否基于该框架定制物流、工厂等行业专属规划任务?
可以。项目模块化设计支持自定义任务模板与约束规则,开发者可根据行业业务逻辑编写专属任务与校验规则,快速改造为行业定制版评测工具。
5. 框架对服务器算力要求高吗?
仅运行任务生成、结果校验功能时,普通 CPU 电脑即可满足需求;算力消耗主要来自对接的大模型推理环节,算力配置以所使用的大模型要求为准。
6. 生成的数据集可以直接用于大模型微调吗?
可以。生成数据为标准 JSON 格式,字段规范、标注完整,兼容 Transformers、LLaMA Factory、Axolotl 等主流大模型微调框架,无需二次格式转换。
7. 框架是否支持批量批量多模型同时评测?
原生版本默认单模型评测,代码预留多模型扩展接口,具备开发能力的用户可基于现有代码改造,实现多款模型并行对比测试。
八、相关链接
项目配套学术论文(arXiv):https://arxiv.org/abs/2605.20873
HuggingFace模型库:https://huggingface.co/datasets/tencent/PlanningBench
九、总结
PlanningBench 是腾讯混元联合高校推出的一款聚焦大模型规划能力的开源一体化框架,集任务生成、自动化评测、结果校验、训练数据产出等功能于一体,弥补了传统大模型评测工具在真实场景规划、调度任务领域的短板。框架覆盖多类生活化、工业化规划场景,配备动态难度调节与智能校验能力,部署简单、拓展性强,既能够帮助企业和科研人员客观评估大模型的复杂任务编排能力,也能为大模型专项优化提供高质量训练数据。该项目面向 AI 研发人员、科研工作者、行业 AI 应用开发者打造,凭借清晰的架构、完善的功能与开源特性,成为大模型规划能力方向极具实用价值的标准化工具。
版权及免责申明:本文由@dotaai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/planningbench.html





