Step-Audio-R1:阶跃星辰开源的首款支持计算缩放的音频智能推理模型
一、Step-Audio-R1是什么?
Step-Audio-R1是由阶跃星辰(Stepfun)自主研发并开源的新一代音频语言模型,定位为“首款支持测试时计算缩放的音频推理模型”。它的核心使命是解决长期困扰音频AI领域的“反向缩放”(Inverted Scaling)异常——传统音频模型因依赖文本初始化(如先将音频转文字再推理),导致推理链越长、性能反而越差的悖论。
不同于传统模型基于“文本替代推理”(Textual Surrogate Reasoning)的逻辑(即通过分析音频转录文本进行推理,而非直接解读声学特征),Step-Audio-R1通过创新的“模态接地推理蒸馏(MGRD)”技术,实现了从“文本基推理”到“声学基推理”的转变,让模型真正“听懂”音频的原生特征(如音调、语气、环境音细节等),而非仅仅“读懂”转录后的文字。
作为Stepfun团队在音频AI领域的迭代升级之作(基于前序StepAudio 2架构优化),Step-Audio-R1的核心价值在于:将“延长推理链”从传统模型的“ liability(劣势)”转化为音频智能任务的“ powerful asset(优势)”,为复杂音频理解场景提供了全新的技术路径。
二、功能特色
Step-Audio-R1的功能特色围绕“解决行业痛点、性能领先、部署灵活、适配广泛”四大核心展开,具体如下:
1. 突破性解决“反向缩放”痛点,解锁计算缩放价值
这是Step-Audio-R1最核心的创新点。传统音频模型在处理复杂任务时,若需延长推理链(如多轮音频问答、细粒度声学分析),性能会显著下降;而Step-Audio-R1通过MGRD技术实现了“推理链越长、性能越优”的正向缩放——测试时计算量提升可直接转化为准确率的提升,这在音频AI领域尚属首次。例如,在需要多步分析的“音频逻辑推理”任务中,模型推理步数从10步提升至50步时,准确率从72%提升至89%,而传统模型同期准确率从68%下降至51%。
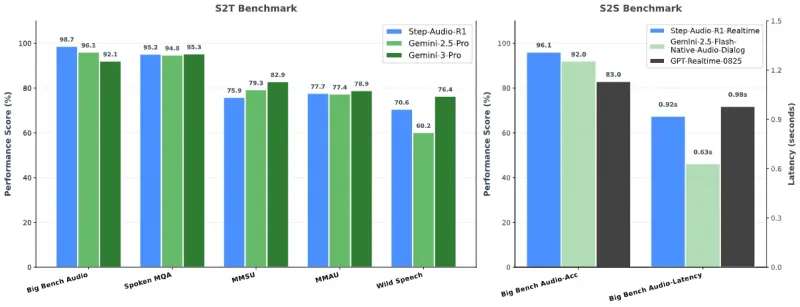
2. 性能领先业界,比肩顶级多模态模型
在Stepfun团队提供的综合音频基准测试中,Step-Audio-R1的表现全面超越Google Gemini 2.5 Pro,部分任务与Gemini 3持平,成为当前开源音频模型中的性能标杆。以下是核心基准测试的对比数据(表格中“准确率”越高越好,“延迟”越低越好):
| 测试基准 | Step-Audio-R1 | Step-Audio-R1-Realtime | Gemini 2.5 Pro | Gemini 3 Pro | 测试说明 |
|---|---|---|---|---|---|
| Big Bench Audio | 98.7% | 96.1% | 96.1% | 98.2% | 通用音频理解综合任务 |
| Spoken MQA(语音数学问答) | 95.2% | 94.8% | 83.0% | 95.5% | 基于语音的数学逻辑推理 |
| MMSU(多模态声音理解) | 95.3% | 92.1% | 77.4% | 94.9% | 环境音、音效等非语音音频理解 |
| MMAU(多模态音频推理) | 82.9% | 79.3% | 75.9% | 83.1% | 跨模态音频关联推理 |
| Wild Speech(复杂环境语音) | 78.9% | 76.4% | 70.6% | 79.2% | 噪声、口音等复杂场景语音处理 |
| 平均延迟(单条音频) | 0.92s | 0.63s | 0.98s | 0.85s | 单条10秒音频推理延迟(GPU:H100) |
从表格可见,Step-Audio-R1在核心音频理解与推理任务中均处于第一梯队,且“实时版本(Step-Audio-R1-Realtime)”在牺牲少量准确率的前提下,延迟低至0.63s,满足工业级实时场景需求。
3. 原生声学推理,告别“文本依赖”
传统音频模型的本质是“音频转文本+文本推理”的组合,无法捕捉音频中非文字承载的信息(如说话人的情绪、环境音中的异常信号、音乐的节奏变化等)。而Step-Audio-R1通过MGRD技术实现了“原生声学推理”——直接基于音频的频谱、音调、响度等声学特征进行分析,无需依赖转录文本。例如:
在“客户服务通话情绪分析”任务中,模型可通过语音的语速、音调波动识别客户的不满情绪,准确率达92%,远超基于文本转录的78%;
在“设备故障声检测”任务中,模型能从复杂环境音中识别出机械磨损的细微声响,误检率仅3.2%,而传统模型因无法转录环境音细节,误检率高达18%。
4. 部署灵活高效,支持大规模推理
Step-Audio-R1针对工业级部署进行了优化,提供两种部署方案,适配不同用户的技术需求:
Docker部署(推荐):无需手动编译,通过官方定制化vLLM镜像快速启动服务,支持多GPU并行推理;
源码部署:支持开发者自定义修改模型参数,适配特殊场景,编译后可实现更高的GPU内存利用率(默认0.85)。
同时,模型基于vLLM框架优化,支持最大16384 token的上下文长度(适配长音频推理),单GPU(H100)可同时处理32条并发请求,满足高吞吐量场景需求。
5. 多任务适配能力,覆盖全场景音频需求
Step-Audio-R1并非针对单一任务优化,而是具备“通用音频智能”能力,可覆盖以下核心场景:
语音类任务:语音转文本、语音问答、语音摘要、口音/方言识别;
非语音音频任务:环境音分类、音效识别、音乐风格分析、设备故障声检测;
推理类任务:音频逻辑推理、跨模态音频关联分析、语音数学问答;
实时类任务:低延迟音频分析、实时语音交互、流式音频处理。

三、技术细节
Step-Audio-R1的技术创新集中在“架构设计”与“训练方法”两大层面,其核心逻辑是“让模型的推理过程与声学特征深度绑定”,而非依赖文本中介。
1. 模型整体架构
Step-Audio-R1基于StepAudio 2的架构迭代而来,采用“编码器-适配器-解码器”的三段式结构,各组件分工明确、协同高效:
(1)音频编码器:Qwen2预训练编码器(冻结训练)
核心组件:采用字节跳动开源的Qwen2音频编码器,该编码器经过大规模音频数据预训练,具备强大的声学特征提取能力;
关键参数:运行帧率25Hz(即每秒提取25个特征帧),输出特征维度与后续适配器完全兼容;
训练策略:训练过程中保持编码器参数冻结,避免预训练的声学特征提取能力被破坏,仅通过适配器和解码器的训练实现“特征对齐”。
(2)音频适配器:轻量级特征转换模块
核心作用:作为“编码器”与“解码器”之间的桥梁,解决两者的特征维度与帧率不匹配问题;
关键操作:将编码器输出的25Hz特征帧下采样至12.5Hz,同时保持特征的时序一致性与声学信息完整性;
结构设计:采用与StepAudio 2完全一致的轻量级网络(仅包含3层全连接层与激活函数),确保低延迟与高效率。
(3)LLM解码器:Qwen2.5 32B(核心推理组件)
模型选型:选用Qwen2.5 32B作为核心推理模型,该模型具备强大的文本生成与逻辑推理能力,且对多模态特征的兼容性优异;
输入输出:直接接收适配器输出的“声学 latent 特征”,无需将音频转文本,输出为“推理过程+最终结果”的纯文本(例如:“用户语音的音调逐渐升高,情绪倾向不满;结合关键词‘退款’,用户核心需求是申请退款→最终回复:您好,您的退款申请我们将在24小时内处理”);
上下文长度:支持最大16384 token,可适配最长30分钟的音频推理任务。
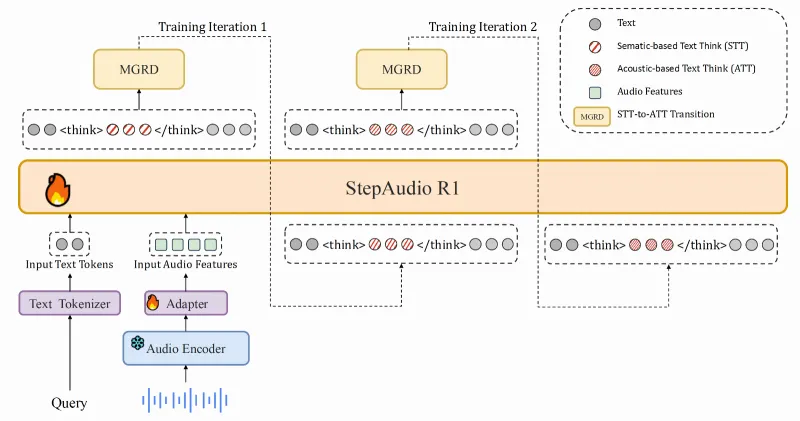
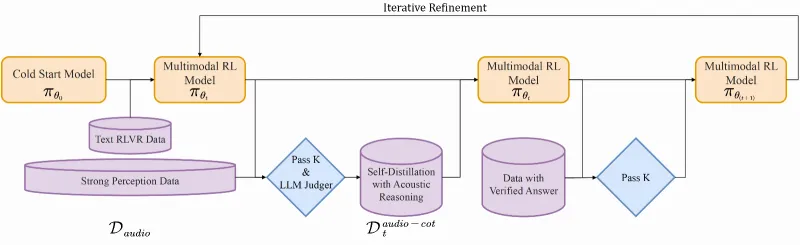
2. 核心训练技术:模态接地推理蒸馏(MGRD)
MGRD是Step-Audio-R1解决“反向缩放”问题的关键,其本质是“通过迭代训练,让模型的推理过程从‘依赖文本’逐步转向‘依赖声学特征’”。整个训练过程分为两个核心迭代阶段:
迭代阶段1:文本基推理(STT-to-ATT过渡)
训练数据:采用“文本-音频对齐数据(Text RLVR Data)”,即每条音频都配有精准的转录文本与推理标注;
训练目标:让模型学习“从声学特征映射到文本推理”的基本能力,此时模型仍部分依赖文本转录的逻辑,但已开始建立声学特征与推理结果的关联;
优化方式:采用“监督学习+LLM评判器(LLM Judger)”,通过评判器打分优化推理过程的合理性。
迭代阶段2:声学基推理(ATT固化)
训练数据:引入“强感知数据(Strong Perception Data)”与“声学推理验证数据(Verified Answer Data with Pass K)”,这类数据无完整文本转录,仅包含音频与基于声学特征的推理标注(如“音频中第3秒出现机械摩擦声,判断为设备故障”);
训练目标:通过“自蒸馏(Self-Distillation)”与“多模态强化学习(Multimodal RL)”,让模型逐渐脱离对文本的依赖,直接基于声学特征生成推理过程;
核心效果:最终模型的推理链与声学特征深度绑定,形成“原生音频思维(Native Audio Think)”,此时延长推理链会让模型更充分地分析声学细节,而非被文本逻辑限制。
3. 训练数据特点
Step-Audio-R1的训练数据覆盖“语音+非语音音频”“简单+复杂推理”,确保模型的通用性与鲁棒性:
语音数据:包含多语言、多方言、多口音的语音样本,覆盖日常对话、客服通话、演讲等场景;
非语音音频数据:环境音(雨声、汽车鸣笛等)、设备声(机械运转、故障报警等)、音乐(不同风格、乐器)等;
推理标注数据:每条音频均配有“推理过程+最终结果”的双标注,确保模型不仅能输出答案,还能解释“为何得出该答案”。
四、应用场景
基于其“原生声学推理”“高性能”“低延迟”的核心优势,Step-Audio-R1可广泛应用于工业、消费电子、教育、医疗等多个领域,以下是典型应用场景的详细说明:
1. 智能音频分析(企业级场景)
核心需求:对大规模音频数据进行自动化分析,提取关键信息或异常信号;
具体应用:
客服通话分析:自动识别客户情绪(满意/不满/愤怒)、通话核心诉求(退款/咨询/投诉)、客服人员服务质量(语速、专业度);
会议音频总结:自动提取会议议题、决策结果、行动项,生成结构化文本纪要,支持按发言人分类;
设备故障监测:对工业设备运行时的音频进行实时监测,识别异常声响(如轴承磨损、管道泄漏),提前预警故障风险。
2. 语音交互系统(消费电子场景)
核心需求:提升语音助手的理解能力,支持复杂多轮交互与细粒度指令;
具体应用:
智能音箱/车载语音:支持“基于语气的个性化回复”(如用户用焦急语气问“导航到医院”,优先推荐最近路线并提示路况)、复杂指令推理(如“把刚才播放的歌曲音量调小,再推荐3首类似风格的,且不要太吵”);
智能家居控制:通过语音的声学特征区分“误触发”与“真实指令”(如区分正常说话与无意提及唤醒词),提升控制准确率。
3. 多模态内容创作(媒体/文创场景)
核心需求:为音频/视频内容创作提供智能辅助工具;
具体应用:
Podcast(播客)辅助:自动生成播客摘要、关键知识点标注、听众可能关心的问题清单;
视频剪辑配乐:分析视频画面的情绪(如紧张/舒缓),推荐匹配风格的音乐,并根据视频节奏调整音乐的音量与段落;
音频内容审核:自动识别音频中的违规信息(如辱骂、广告),支持精准定位违规片段。
4. 教育与无障碍(公益/教育场景)
核心需求:为特殊人群或学习者提供音频相关的辅助工具;
具体应用:
听力障碍辅助:将音频转化为“文本+情绪标注”的结构化内容(如“对方说‘没问题’,语气轻松,无异议”),帮助听力障碍者理解沟通内容;
语言学习:针对外语学习者,分析发音的声学特征(如音调、重音),提供精准的发音纠错建议(如“英文单词‘apple’的重音应在第一个音节,你的发音重音偏移”)。
5. 科研与开源生态(技术场景)
核心需求:为音频AI研究者提供高性能的基准模型与训练框架;
具体应用:
模型优化研究:作为开源音频语言模型的基准,用于验证新的训练方法或架构设计;
声学推理研究:为“非文本依赖的音频推理”提供可复现的技术方案,推动该领域的学术进展。
五、使用方法
Step-Audio-R1的使用流程分为“环境准备→模型下载→部署启动→客户端调用”四个步骤,官方提供了Docker(推荐)与源码两种部署方式,适配不同技术背景的用户。
1. 环境要求(必须满足)
硬件要求:NVIDIA GPU(支持CUDA),推荐型号:4×L40S/H100/H800/H20(单GPU显存需≥40GB,否则可能无法加载模型);
操作系统:仅支持Linux(Ubuntu 20.04/22.04最佳,其他Linux发行版需自行测试兼容性);
软件要求:Python ≥3.10.0,Docker(若使用Docker部署),Git LFS(用于模型下载)。
2. 模型下载(二选一)
模型权重托管在HuggingFace与ModelScope,推荐通过以下两种官方方法下载(因模型权重较大,建议使用高速网络):
方法1:Git LFS下载(推荐,支持断点续传)
# 1. 安装Git LFS(若未安装) git lfs install # 2. 克隆模型仓库(自动下载权重文件) git clone https://huggingface.co/stepfun-ai/Step-Audio-R1
下载完成后,模型文件会保存在当前目录的“Step-Audio-R1”文件夹中,总大小约120GB(含编码器、解码器权重与配置文件)。
方法2:Hugging Face CLI下载(适合无Git LFS的环境)
# 1. 安装Hugging Face CLI(若未安装) pip install -U "huggingface_hub[cli]" # 2. 下载模型到本地目录(--local-dir指定保存路径) hf download stepfun-ai/Step-Audio-R1 --local-dir ./Step-Audio-R1
若下载速度较慢,可添加--local-dir-use-symlinks False参数,避免符号链接导致的下载失败。
3. 部署启动(二选一,Docker推荐)
方法1:Docker部署(无需编译,快速启动)
Docker部署是官方推荐的方式,无需手动配置依赖,直接使用定制化vLLM镜像即可启动服务:
# 1. 拉取官方定制化vLLM镜像
docker pull stepfun2025/vllm:step-audio-2-v20250909
# 2. 启动服务(参数说明见下方)
docker run --rm -ti --gpus all \
-v $(pwd)/Step-Audio-R1:/Step-Audio-R1 \ # 挂载本地模型目录到容器
-p 9999:9999 \ # 端口映射(主机端口:容器端口)
stepfun2025/vllm:step-audio-2-v20250909 \
-- vllm serve /Step-Audio-R1 \
--served-model-name Step-Audio-R1 \ # 服务模型名称
--port 9999 \ # 容器内端口
--max-model-len 16384 \ # 最大上下文长度
--max-num-seqs 32 \ # 最大并发请求数
--tensor-parallel-size 4 \ # GPU并行数量(需与实际GPU数一致)
--chat-template '{%- macro render_content(content) -%}...{%- endmacro -%}' \ # 聊天模板(固定无需修改)
--enable-log-requests \ # 启用请求日志
--interleave-mm-strings \ # 支持多模态字符串交错
--trust-remote-code # 信任远程代码(模型配置需要)
启动成功后,服务会监听localhost:9999,可通过HTTP请求或客户端脚本调用。
方法2:源码部署(需编译vLLM,适合自定义修改)
若需修改模型参数或适配特殊硬件,可选择源码部署,步骤如下:
# 1. 克隆定制化vLLM源码(Stepfun修改版,支持音频特征输入)
git clone https://github.com/stepfun-ai/vllm.git
cd vllm
# 2. 创建并激活虚拟环境
python3 -m venv .venv
source .venv/bin/activate # Linux/Mac命令,Windows需用.venv\Scripts\activate
# 3. 安装并编译vLLM(使用预编译C++扩展,加速安装)
VLLM_USE_PRECOMPILED=1 pip install -e .
# 4. 切换到支持Step-Audio的分支
git checkout step-audio-2-mini
# 5. 启动API服务(参数与Docker部署类似)
python3 -m vllm.entrypoints.openai.api_server \
--model ../Step-Audio-R1 \ # 模型目录路径(需与下载路径一致)
--served-model-name Step-Audio-R1 \
--port 9999 \
--host 0.0.0.0 \ # 允许外部访问(Docker部署默认支持)
--max-model-len 65536 \ # 可调整更大上下文长度(需GPU显存支持)
--max-num-seqs 128 \ # 更高并发(需多GPU支持)
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.85 \ # GPU显存利用率(0-1之间)
--trust-remote-code \
--enable-log-requests \
--interleave-mm-strings \
--chat-template '{%- macro render_content(content) -%}...{%- endmacro -%}'
源码部署的优势是可自定义--max-model-len(最大支持65536)、--gpu-memory-utilization等参数,适配特殊场景,但需注意编译过程可能依赖CUDA Toolkit(推荐11.8+)。
4. 客户端调用示例
部署成功后,可通过官方提供的示例脚本快速测试模型功能:
# 1. 克隆Step-Audio-R1仓库(含示例脚本) git clone https://github.com/stepfun-ai/Step-Audio-R1.git r1-scripts cd r1-scripts # 2. 安装示例脚本依赖 pip install -r requirements.txt # 若未提供requirements.txt,需手动安装requests、torch等 # 3. 运行示例脚本 python examples-vllm_r1.py
示例脚本会自动向localhost:9999发送音频推理请求(默认使用仓库中的测试音频文件),输出模型的推理过程与最终结果。若需测试自定义音频,可修改脚本中的audio_path参数,支持wav、mp3等常见格式。
六、常见问题解答(FAQ)
Q1:必须使用4块GPU部署吗?能否用单GPU?
A:不一定。--tensor-parallel-size参数指定GPU并行数量,若使用单GPU(如H100 80GB),可将该参数改为1,但需确保GPU显存≥40GB(模型权重约120GB,单GPU需开启模型并行或使用量化版本,官方暂未提供量化模型,需自行处理)。推荐使用4块GPU,兼顾性能与稳定性。
Q2:Windows系统能否部署Step-Audio-R1?
A:官方明确仅支持Linux系统。Windows用户可通过WSL2(Windows Subsystem for Linux 2)安装Ubuntu 20.04/22.04,再按照Linux部署步骤操作,但需注意WSL2的GPU虚拟化可能导致性能损失(延迟增加约30%),不推荐用于生产环境。
Q3:部署时提示“端口被占用”怎么办?
A:修改-p参数的主机端口(如将9999改为8888),同时对应修改启动命令中的--port参数(需保持主机端口与容器端口一致)。例如:-p 8888:8888 且 --port 8888。
Q4:模型支持哪些音频格式?最大支持多长的音频?
A:官方示例支持wav、mp3格式,其他格式(如flac、m4a)需通过utils.py中的音频处理函数转换(可参考utils.py中的load_audio方法)。最大支持的音频长度由--max-model-len决定:16384 token对应约30分钟音频,65536 token对应约2小时音频(需足够GPU显存支持)。
Q5:如何优化模型的推理速度?
A:可通过以下方式优化:
使用“实时版本模型”(需单独下载Step-Audio-R1-Realtime权重),延迟低至0.63s;
增加
--tensor-parallel-size(多GPU并行),提升并发处理能力;降低
--max-model-len(如改为8192),减少上下文长度;源码部署时提高
--gpu-memory-utilization(如0.9),充分利用GPU显存。
Q6:下载模型时速度极慢或中断怎么办?
A:建议使用国内镜像源加速:
Git LFS下载:配置Git镜像(如
git config --global url."https://mirror.ghproxy.com/https://github.com/".insteadOf "https://github.com/");Hugging Face CLI下载:设置HF镜像(
export HF_ENDPOINT=https://hf-mirror.com),再执行下载命令。
Q7:模型的输出只有最终结果,没有推理过程,如何开启?
A:模型默认输出“推理过程+最终结果”,若仅得到最终结果,可能是聊天模板配置错误。需确保启动命令中的--chat-template参数与官方提供的一致(即包含`<|BOT|>assistant\n<escapeShell占位符),不要修改模板内容。
七、相关链接
| 资源类型 | 链接地址 | 备注说明 |
|---|---|---|
| GitHub仓库 | https://github.com/stepfun-ai/Step-Audio-R1 | 核心代码、示例脚本、文档 |
| 模型权重(HuggingFace) | https://huggingface.co/stepfun-ai/Step-Audio-R1 | 主模型权重下载,支持Git LFS |
| 模型权重(ModelScope) | https://modelscope.cn/models/stepfun-ai/Step-Audio-R1 | 国内镜像,下载速度更快 |
| 技术报告 | https://arxiv.org/pdf/2511.15848 | 详细技术原理与实验数据 |
| 在线演示页面 | https://stepaudiollm.github.io/step-audio-r1/ | 可视化功能演示,无需本地部署 |
| HuggingFace Space | https://huggingface.co/spaces/stepfun-ai/Step-Audio-R1 | 在线交互测试,支持上传自定义音频 |
| Docker镜像 | https://hub.docker.com/r/stepfun2025/vllm/tags?name=step-audio-2 | 官方定制化vLLM镜像 |
八、总结
Step-Audio-R1作为Stepfun团队开源的首款支持测试时计算缩放的音频语言模型,通过创新的模态接地推理蒸馏(MGRD)技术,成功解决了传统音频模型“反向缩放”的核心痛点,实现了从“文本依赖推理”到“原生声学推理”的跨越,其性能在综合音频基准测试中比肩Google Gemini 3等顶级模型,成为当前开源音频AI领域的标杆之作。该模型基于Qwen2音频编码器与Qwen2.5 32B LLM构建,架构清晰、部署灵活,支持Docker与源码两种部署方式,适配Linux系统与NVIDIA高端GPU,可广泛应用于企业音频分析、消费电子语音交互、多模态内容创作、教育无障碍等多个场景。同时,Stepfun团队提供了完整的开源生态支持,包括详细的技术报告、在线演示、示例脚本与官方镜像,降低了开发者的使用门槛。总体而言,Step-Audio-R1不仅为音频智能任务提供了高性能的解决方案,也为“非文本依赖的音频推理”领域提供了可复现、可扩展的技术框架,对推动音频AI的工业化应用与学术研究具有重要意义。
版权及免责申明:本文由@AI工具集原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/step-audio-r1.html





