TANGO:CyberAgent AI Lab开源的语音同步手势视频生成框架
1. TANGO是什么
TANGO是由CyberAgent AI Lab开发的一个开源项目,旨在根据输入的音频和参考人物视频,自动生成该人物的全身动作视频,且动作与音频节奏、内容同步。简单来说,TANGO能够让计算机"听到"一段声音,然后生成一个人(基于参考视频中的人物)做出与声音同步的动作的视频。这不仅包括面部表情和嘴型的同步,还涵盖了全身的姿态和手势。
2. 功能特色
TANGO的核心功能是语音驱动的全身动作生成,其主要特色包括:
2.1 高精度的音频-动作同步
多尺度音频特征分析:从音频中提取多种尺度的特征,包括短期的音素特征和长期的韵律特征
分层动作表示:将人体动作分解为全局姿态和局部手势,分别与不同层次的音频特征匹配
动态时间规整:通过动态规划技术,优化音频与动作序列之间的时间对齐
2.2 自然流畅的动作生成
扩散插值技术:使用扩散模型进行动作序列的平滑插值,减少"帧跳跃"现象
物理约束优化:考虑人体运动学约束,确保生成的动作符合物理规律
多样性生成:支持生成多种风格的动作,适应不同的表达需求
2.3 灵活的输入输出选项
多模态输入支持:不仅支持纯音频输入,还可以结合文本、表情等多种输入
可定制的输出风格:可以根据参考视频调整生成动作的风格特征
多分辨率输出:支持不同分辨率的视频生成,满足不同应用场景需求
2.4 易用的交互界面
Gradio可视化界面:提供直观的网页界面,无需编程即可体验TANGO的功能
丰富的示例素材:内置多个示例音频和视频,便于快速测试
详细的参数控制:允许高级用户调整各种生成参数,获得最佳效果

3. 技术细节
TANGO的技术实现融合了多种先进的机器学习和计算机视觉技术,下面是其核心技术架构的详细解析。
3.1 系统总体架构
TANGO系统主要由以下几个核心模块组成:
音频特征提取模块:从输入音频中提取多层次的声学特征
动作特征提取模块:从参考视频中提取人体姿态和动作特征
音动嵌入模块:将音频特征和动作特征映射到统一的嵌入空间
动作生成模块:基于音动嵌入和扩散模型生成动作序列
视频合成模块:将生成的动作序列与参考人物外观合成最终视频
3.2 分层音动嵌入(Hierarchical Audio-Motion Embedding)
这是TANGO的核心创新点之一,其目标是建立音频和动作之间的精准对应关系。
| 嵌入层次 | 音频特征 | 动作特征 | 对应关系 |
|---|---|---|---|
| 高层(语义级) | 韵律特征、情感特征 | 全局姿态、身体朝向 | 表达意图、情感状态 |
| 中层(短语级) | 音素序列、重音模式 | 手臂动作、手势类型 | 语言结构、强调重点 |
| 低层(音素级) | 频谱特征、能量变化 | 面部表情、嘴型动作 | 精确的发音同步 |
这种分层嵌入方式能够同时捕捉音频和动作在不同时间尺度上的对应关系,从而实现更自然、更精确的动作生成。
3.3 扩散插值(Diffusion Interpolation)
TANGO采用了基于扩散模型的动作插值技术,解决了传统方法中动作不连贯的问题。
扩散插值的工作原理:
首先在动作空间中随机采样一个噪声序列
通过迭代的去噪过程,逐步将噪声序列转化为符合目标分布的动作序列
在生成过程中,利用注意力机制将音频特征注入到动作生成过程中
最终得到平滑、自然的动作序列
这种方法的优势在于:
生成的动作序列具有内在的时间连贯性
能够处理长序列的动作生成
对动作风格的控制更加精细
3.4 图搜索机制
TANGO引入了动作图(Motion Graph)的概念,用于高效地检索和匹配动作序列。
图搜索的工作流程:
首先构建一个动作图,其中每个节点代表一个短动作片段
边表示两个动作片段之间的过渡可能性
基于音频特征,通过动态规划在图中搜索最优的动作路径
将搜索到的动作路径作为扩散模型的初始条件
这种方法结合了检索式生成和生成式生成的优点,既能保证动作的真实性,又能确保与音频的精确同步。
4. 应用场景
TANGO的技术特性使其在多个领域具有广泛的应用前景:
4.1 虚拟主播与数字人
自动生成虚拟主播的动作:根据主播的语音内容自动生成同步的面部表情和手势
降低制作成本:减少对动作捕捉设备和专业演员的需求
提升内容生产效率:快速生成大量高质量的虚拟主播视频内容
4.2 影视动画制作
辅助动画师工作:自动生成初步的角色动作,动画师只需进行微调
提高制作效率:大幅减少关键帧动画的制作时间
实现个性化角色动作:根据配音自动生成符合角色性格的动作
4.3 教育培训
创建虚拟讲师:为在线课程创建能够做出自然动作的虚拟讲师
增强学习体验:通过丰富的肢体语言提高学生的注意力和理解力
多语言教学支持:同一课程内容可以快速适配不同语言的配音
4.4 社交娱乐
视频聊天增强:在视频通话中添加虚拟形象,根据语音生成表情和动作
内容创作工具:帮助创作者快速生成有趣的短视频内容
虚拟偶像互动:实现虚拟偶像与粉丝的实时互动,根据粉丝留言生成回应动作
4.5 人机交互
情感化界面:为AI助手创建能够表达情感的虚拟形象
增强远程协作:在远程会议中提供更丰富的非语言交流方式
无障碍技术:为语言障碍人士提供可视化的动作表达
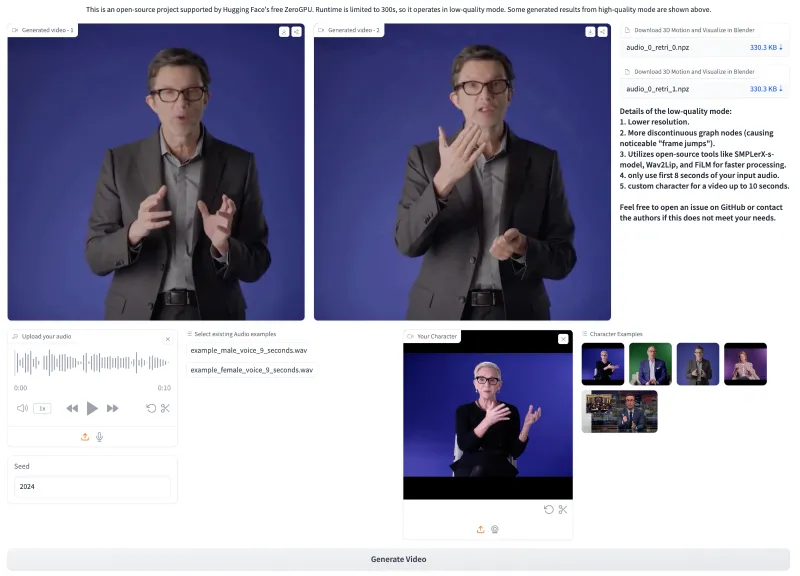
5. 使用方法
5.1 环境准备
TANGO的运行需要以下环境:
Python 3.10.16
CUDA 11.8(推荐使用NVIDIA GPU)
至少16GB内存
足够的存储空间(模型文件和数据可能需要数十GB)
5.2 安装步骤
克隆仓库
git clone https://github.com/CyberAgentAILab/TANGO.git cd TANGO
创建并激活虚拟环境
python -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate
安装依赖
pip install -r pre-requirements.txt pip install -r requirements.txt
下载预训练模型
# 具体下载指令请参考项目README中的模型下载链接
5.3 基本使用
命令行推理:
python inference.py --audio_path path/to/your/audio.wav --character_name path/to/reference/video.mp4
使用Gradio界面:
python app.py
运行后,打开浏览器访问显示的本地地址即可使用图形界面进行操作。
5.4 高级配置
TANGO提供了丰富的配置选项,可以通过修改配置文件或命令行参数来调整生成效果:
| 参数类别 | 常用参数 | 说明 |
|---|---|---|
| 音频处理 | --audio_feature_type | 选择音频特征提取方法 |
| 动作生成 | --motion_style_strength | 控制生成动作的风格强度 |
| 视频合成 | --output_resolution | 设置输出视频的分辨率 |
| 性能优化 | --batch_size | 调整批处理大小以平衡速度和质量 |
| 风格控制 | --emotion_factor | 控制生成动作的情感强度 |
5.5 训练模型(高级用户)
如果你有自己的数据集,可以训练自定义模型:
准备训练数据
收集包含音频和对应动作的视频数据
预处理数据,提取动作特征
配置训练参数
修改
configs/目录下的配置文件设置数据集路径、训练轮数等参数
启动训练
torchrun --nproc_per_node=1 train_high_env0.py --config path/to/config.yaml
6. 常见问题解答
问:TANGO必须使用GPU吗?
答:虽然可以在CPU上运行,但强烈建议使用NVIDIA GPU(至少6GB显存)以获得合理的性能。
问:音频和参考视频有什么格式要求?
答:音频支持常见格式如WAV、MP3,视频支持MP4、MOV等常见格式。建议使用高质量的输入以获得最佳结果。
问:生成的视频质量与什么因素有关?
答:主要受以下因素影响:输入质量、参考视频的多样性、生成参数设置、硬件性能等。
问:TANGO的使用有什么限制?
答:TANGO采用CC BY-NC 4.0许可证,仅允许非商业用途(研究或教育),禁止商业使用或再分发。
问:运行中遇到内存不足错误怎么办?
答:可以尝试降低批处理大小、减小输出分辨率或使用更小的模型配置。
问:生成的动作与音频同步性不好怎么办?
答:可以尝试调整音频特征提取参数、增加动作图搜索的约束条件,或使用更高质量的参考视频。
7. 相关链接
项目GitHub仓库:https://github.com/CyberAgentAILab/TANGO
Hugging Face空间:https://huggingface.co/spaces/H-Liu1997/TANGO
8. 总结
TANGO是一个创新的开源项目,通过分层音动嵌入和扩散插值技术,实现了高质量的语音驱动全身动作生成。它不仅在技术上融合了多种先进的机器学习方法,还提供了易于使用的接口,使研究人员和开发者能够方便地应用这一技术。TANGO在虚拟主播、动画制作、教育培训等领域具有广泛的应用前景,其开源性质也为进一步的研究和改进提供了基础。无论是作为研究工具还是实际应用,TANGO都展示了人工智能在动作生成领域的前沿水平。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/tango.html