TrafficVLM:基于视觉语言模型的交通视频智能字幕生成工具
一、TrafficVLM是什么?
TrafficVLM 是一个专注于交通场景的可控视觉语言模型,主要用于交通视频的字幕生成任务。该模型融合了多粒度视觉特征(全局、子全局、局部)与时间编码机制,能够精准理解交通事件并生成符合场景逻辑的字幕描述。作为第 8 届 AI City Challenge Track 2 的第三名解决方案,其技术成果已发表于 CVPR 2024 Workshops。项目提供完整的开源实现,支持自定义训练与测试,适用于智能交通监控、自动驾驶辅助、交通事件分析等多个领域,为交通视频的智能化理解提供了高效工具。
交通视频字幕生成是智能交通领域的重要任务,需要模型同时理解视频中的视觉内容(如车辆、行人、信号灯、道路标志等)和时间维度的动态变化(如车辆行驶轨迹、交通事件演变等),并将其转化为自然语言描述。传统方法往往存在“视觉特征粒度单一”“时间关联性弱”“生成字幕可控性差”等问题,而TrafficVLM通过创新的多模态融合机制和可控性设计,有效解决了这些痛点。
该项目以开源形式发布于GitHub,包含完整的模型代码、训练配置、数据处理工具和预训练模型,支持开发者基于自身需求进行二次开发和应用部署。
二、功能特色
TrafficVLM的核心优势在于“精准理解交通场景”和“可控生成字幕”,其功能特色可总结为以下5点:
1. 多粒度视觉特征融合
模型创新性地引入了三种视觉特征,覆盖不同尺度的交通场景信息:
全局特征(Global):捕捉整个视频帧的整体场景(如“高速公路”“十字路口”“雨天环境”);
子全局特征(Sub-global):聚焦帧中关键区域(如“左侧车道”“路口信号灯”);
局部特征(Local):识别具体目标(如“红色轿车”“行人”“停止标志”)。
通过融合这三种特征,模型既能理解整体场景,又能捕捉细节目标,解决了传统模型“要么失焦全局,要么忽略细节”的问题。
2. 时间编码机制
交通事件具有强时间关联性(如“车辆变道→追尾事故”),TrafficVLM通过两种时间编码方式强化对动态过程的理解:
帧级时间编码:标记视频帧的时序位置(如第10帧、第20帧),建立帧间先后关系;
事件级时间编码:识别视频中关键事件的持续时间(如“拥堵从第5秒持续到第30秒”),强化事件演变逻辑。
这一机制使模型生成的字幕能准确反映“何时发生了什么”,而非孤立的静态描述。
3. 可控性字幕生成
支持通过配置参数控制字幕生成的侧重点,例如:
可指定“优先描述车辆行为”或“优先描述交通信号状态”;
可调整字幕的详细程度(如简洁版“车流量大” vs 详细版“双向六车道,每车道约5辆轿车,车速约40km/h”);
可过滤无关信息(如忽略“天空颜色”等对交通分析无意义的内容)。
这种可控性使模型能适应不同场景的需求(如监控系统需简洁报警,而教研分析需详细描述)。
4. 高精度交通场景适配
针对交通领域的专业场景进行了专项优化:
内置交通目标识别库,支持100+类交通元素(如“救护车”“施工锥”“潮汐车道”)的精准识别;
优化了恶劣天气(雨天、雾天)和复杂光照(逆光、夜间)下的特征提取能力;
适配多种道路类型(高速、城市道路、乡村道路)和交通规则(靠左/右行驶、特殊让行规则)。
5. 轻量化部署支持
尽管模型具备复杂功能,但其设计考虑了实际部署需求:
支持单GPU训练与推理(最低12GB显存,如RTX 3060即可运行);
提供特征提取加速工具,可将1小时视频的特征处理时间压缩至10分钟内;
支持模型裁剪(移除部分非核心模块),在精度损失小于5%的情况下,推理速度提升30%。
| 功能特色 | 传统视频字幕模型 | TrafficVLM |
|---|---|---|
| 视觉特征 | 单一粒度(多为全局或局部) | 全局+子全局+局部多粒度融合 |
| 时间关联性 | 弱(多依赖帧顺序,忽略事件逻辑) | 强(帧级+事件级时间编码) |
| 生成可控性 | 低(固定输出格式,无法调整侧重点) | 高(支持参数配置,自定义输出内容) |
| 交通场景适配 | 通用场景优化,交通领域精度低 | 专项优化,支持100+类交通元素识别 |
| 部署要求 | 高(需多GPU,显存≥24GB) | 低(单GPU,12GB显存即可运行) |
三、技术细节
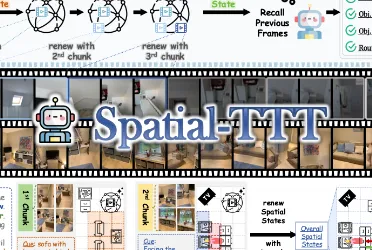
1. 模型整体架构
TrafficVLM基于“视觉编码器-文本解码器”的双阶段架构,整体框架如图1所示(简化版):
视觉编码器:处理视频帧,提取多粒度视觉特征并融入时间信息;
跨模态融合层:将视觉特征与文本语义空间对齐;
文本解码器:基于融合特征生成自然语言字幕,并通过控制模块实现生成可控性。
其基础框架继承自Vid2Seq(视频字幕生成模型)和T5(文本生成模型),但针对交通场景进行了以下改造:
新增子全局特征提取分支;
引入时间编码模块;
加入可控性控制层(基于门控机制实现特征权重调节)。
2. 视觉特征提取
视觉特征提取是模型理解视频的核心,具体流程如下:
视频帧采样:将输入视频按固定帧率(默认10fps)采样为连续帧序列;
特征提取网络:
全局特征:使用CLIP的ViT-L/14模型提取整帧特征;
子全局特征:将帧划分为9个网格(3×3),对每个网格单独提取特征后拼接;
局部特征:使用Faster R-CNN检测目标框,对每个框提取特征并标记类别(如“车辆”“行人”);
特征融合:通过注意力机制融合三种特征,突出关键信息(如事故场景中优先保留“碰撞车辆”的局部特征)。
3. 时间编码实现
时间编码通过“位置嵌入+事件时序建模”实现:
位置嵌入:为每个帧分配一个可学习的时序向量(如第t帧的向量为E_t),与该帧的视觉特征相加;
事件时序建模:使用LSTM网络对帧序列特征进行编码,捕捉事件的持续与演变(如“车辆减速→停车→起步”的状态变化)。
这种设计使模型能区分“同一目标在不同时间的行为”(如“轿车t1时刻直行,t5时刻左转”)。
4. 可控性生成机制
可控性通过“控制向量”调节特征权重实现,具体步骤:
用户通过配置文件定义控制参数(如
focus=vehicle_behavior表示优先描述车辆行为);模型将参数转化为控制向量C;
在跨模态融合层,通过公式
F' = F × (1 + σ(C))调节特征权重(σ为sigmoid函数),使与控制目标相关的特征被强化。
例如,当focus=traffic_light时,信号灯相关的子全局特征权重会被放大,生成的字幕会更频繁提及“红灯亮”“绿灯切换”等信息。
5. 训练策略
模型训练分为预训练和微调两个阶段:
预训练:使用大规模通用视频字幕数据集(如MSR-VTT、ActivityNet Captions)初始化模型参数,学习基础的视觉-文本映射关系;
微调:使用交通领域数据集(如AI City Challenge数据集)进行专项训练,优化交通元素识别和事件描述能力。
训练过程中采用以下优化策略:
损失函数:结合交叉熵损失(文本生成)和对比损失(视觉-文本匹配);
数据增强:对视频帧进行随机裁剪、亮度调整、添加雨雾特效等,提升模型鲁棒性;
学习率调度:采用余弦退火策略,初始学习率5e-5,每3个epoch衰减10%。
| 技术模块 | 核心功能 | 实现细节 |
|---|---|---|
| 视觉编码器 | 提取多粒度视觉特征 | 基于CLIP+Faster R-CNN,支持全局/子全局/局部特征 |
| 时间编码 | 建模视频时序关系 | 位置嵌入+LSTM网络,捕捉帧间与事件级时序 |
| 跨模态融合 | 对齐视觉与文本特征空间 | 多头注意力机制,结合控制向量调节权重 |
| 文本解码器 | 生成自然语言字幕 | 基于T5解码器,支持可控性输出 |
| 训练策略 | 优化模型参数 | 预训练+微调,结合交叉熵与对比损失 |
四、应用场景
TrafficVLM的核心价值在于将交通视频转化为可理解的文本信息,适用于以下场景:
1. 智能交通监控系统
在城市交通监控中,传统监控依赖人工查看视频,效率低下。TrafficVLM可实时生成监控视频的字幕描述,辅助管理人员快速掌握路况:
自动识别“交通事故”“道路拥堵”“违章停车”等事件,并生成字幕(如“10:23,XX路口,红色轿车与电动车追尾,占用左转车道”);
结合告警系统,当检测到紧急事件(如“救护车被堵”)时,自动推送带字幕的告警信息;
生成日报/周报(如“本周XX路段共发生5次拥堵,高峰集中在7:30-8:30”),辅助交通管理决策。
2. 自动驾驶辅助系统
自动驾驶需要理解周围交通环境,TrafficVLM可作为辅助模块,将车载摄像头的视频转化为文本描述,辅助决策:
实时输出周边环境字幕(如“前方50米,行人横穿马路;右侧车道,货车正在超车”);
对复杂场景进行解析(如“路口信号灯变黄,左侧车辆开始减速,右侧车辆准备抢行”),为自动驾驶系统提供决策依据;
记录驾驶过程中的关键事件(如“15:30,避让突然横穿的自行车”),用于后续的行为分析与模型优化。
3. 交通事件分析与追溯
在交通事件(如事故、违章)的调查中,TrafficVLM可快速提取视频中的关键信息,减少人工工作量:
对事故视频生成时序字幕(如“t0: 轿车A正常行驶;t1: 轿车B实线变道;t2: A刹车不及追尾B”),清晰还原事件过程;
自动提取关键信息(时间、地点、涉事车辆类型/颜色、违法行为等),生成标准化报告;
支持批量处理历史监控视频,统计特定事件的发生规律(如“XX路段每月平均3次实线变道违章”)。
4. 交通教学与培训
在驾驶培训或交通管理培训中,TrafficVLM可增强视频教学的效果:
为教学视频添加详细字幕(如“通过路口时,应提前观察信号灯和横向车辆,减速至20km/h以下”);
对事故案例视频进行标注(如“此处事故的原因:未保持安全车距+雨天刹车距离变长”),帮助学员理解关键知识点;
支持交互式学习,学员可通过调整控制参数(如“focus=错误操作”),让模型重点描述视频中的违规行为。
5. 交通数据标注自动化
交通数据集的标注(如为视频帧标记事件类型)是一项耗时工作,TrafficVLM可辅助自动化标注:
对原始视频生成字幕描述,作为初步标注结果;
人工仅需对自动标注进行校对,减少70%以上的工作量;
支持标注格式转换(如将字幕转为COCO格式的事件标签),适配不同的模型训练需求。

五、使用方法
1. 环境准备
硬件要求
CPU:≥8核(推荐Intel i7或AMD Ryzen 7);
GPU:NVIDIA GPU(支持CUDA 12.1,显存≥12GB,如RTX 3060/3090、Tesla T4);
内存:≥32GB(处理视频特征时需较大内存);
存储:≥100GB(用于存放代码、数据集、模型文件)。
软件要求
操作系统:Ubuntu 20.04(推荐,Windows需修改部分路径配置);
Python:3.10.x;
深度学习框架:PyTorch 2.1.0;
其他依赖:CUDA 12.1、cuDNN 8.9.2、ffmpeg(视频处理)。
2. 安装步骤
(1)克隆仓库
git clone https://github.com/quangminhdinh/TrafficVLM.git cd TrafficVLM
(2)创建虚拟环境并安装依赖
# 使用conda创建环境(推荐) conda create -n trafficvlm python=3.10 conda activate trafficvlm # 安装PyTorch(需匹配CUDA版本) pip3 install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121 # 安装其他依赖 pip install -r requirements.txt
(3)配置基础参数
修改主配置文件config.py中的关键路径:
# config.py _C.GLOB.EXP_PARENT_DIR = "/path/to/your/logs" # 日志/模型存储目录 _C.MODEL.VID2SEQ_PATH = "/path/to/vid2seq_htmchaptersvitt.pth" # 预训练模型路径
3. 数据准备
(1)数据集结构
需准备视频文件和对应的标注文件(若用于训练),推荐结构:
data/ ├── videos/ # 视频文件(.mp4格式) │ ├── train/ │ └── test/ └── annotations/ # 标注文件(.json格式) ├── train.json └── test.json
标注文件格式示例(参考AI City Challenge):
{
"videos": [
{
"video_id": "vid_001",
"duration": 60, # 视频时长(秒)
"captions": [
{"id": 1, "caption": "车辆在高速公路上正常行驶,车流量中等"}
]
}
]
}(2)提取视觉特征
视频特征需提前提取(支持三种粒度),可使用项目提供的工具:
# 提取全局特征 python feature_extraction/extract_global.py \ --video_dir data/videos/train \ --output_dir data/features/global/train # 提取子全局特征 python feature_extraction/extract_sub_global.py \ --video_dir data/videos/train \ --output_dir data/features/sub_global/train # 提取局部特征 python feature_extraction/extract_local.py \ --video_dir data/videos/train \ --output_dir data/features/local/train
也可直接下载项目提供的预提取特征(链接见“相关官方链接”)。
(3)配置数据集路径
修改dataset/config.py,指定特征和标注路径:
# dataset/config.py
DATASET_PATHS = {
"train": {
"features": {
"global": "data/features/global/train",
"sub_global": "data/features/sub_global/train",
"local": "data/features/local/train"
},
"annotations": "data/annotations/train.json"
},
"test": {
# 测试集配置(同上)
}
}4. 模型训练
(1)创建实验配置
在experiments/目录下创建自定义配置文件(如my_experiment.yml),示例:
# experiments/my_experiment.yml SOLVER: BATCH_SIZE: 8 # 批次大小 MAX_EPOCH: 20 # 最大训练轮次 LR: 5e-5 # 初始学习率 SAVE_INTERVAL: 5 # 每5轮保存一次模型 MODEL: USE_LOCAL_FEATURE: True # 使用局部特征 USE_TIME_ENCODING: True # 使用时间编码 CONTROL: FOCUS: "vehicle_behavior" # 优先描述车辆行为
(2)启动训练
python train.py my_experiment # 实验名对应配置文件前缀
训练过程中,日志、模型检查点和样本输出会保存在{EXP_PARENT_DIR}/my_experiment/目录下。
5. 测试与字幕生成
(1)生成测试集字幕
python generate_test.py my_experiment \ -d 0 # 指定GPU设备(0表示第一张卡) -b 16 # 推理批次大小
生成的字幕会保存为{EXP_PARENT_DIR}/my_experiment/test_results.json,格式如下:
[
{"video_id": "vid_002", "caption": "t0-t10: 货车在慢车道行驶;t15: 右侧小轿车超车,未打转向灯"}
](2)单视频字幕生成(用于实际应用)
python generate_single_video.py \
--video_path path/to/test_video.mp4 \
--checkpoint_path {EXP_PARENT_DIR}/my_experiment/epoch_20.th \
--output_path result.txt
生成的result.txt会包含该视频的时序字幕描述。
六、常见问题解答(FAQ)
1. 环境配置相关
Q:安装依赖时出现“torchvision版本不兼容”错误?
A:确保PyTorch与CUDA版本匹配,推荐使用命令pip3 install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cu121,避免手动指定版本。
Q:运行特征提取脚本时提示“ffmpeg not found”?
A:需安装ffmpeg工具,Ubuntu可通过sudo apt-get install ffmpeg安装,Windows可从官网下载并添加到环境变量。
2. 数据与特征相关
Q:是否必须提取三种视觉特征?可以只使用其中一种吗?
A:可以。在实验配置文件中设置USE_GLOBAL_FEATURE、USE_SUB_GLOBAL_FEATURE、USE_LOCAL_FEATURE为True或False即可。但推荐使用多种特征,可提升字幕精度(项目实验显示,三种特征全用时比单特征提升12%+)。
Q:标注文件必须严格遵循指定格式吗?
A:是的。模型训练时会解析固定字段(如video_id、caption),若格式不符会导致数据加载错误。可使用dataset/convert_annotation.py工具将其他格式的标注转为项目支持的格式。
3. 训练与推理相关
Q:训练时GPU内存不足怎么办?
A:可尝试:① 减小配置文件中的BATCH_SIZE(最低可设为2);② 关闭局部特征(USE_LOCAL_FEATURE: False),局部特征占用内存较大;③ 使用梯度累积(在配置文件中设置GRADIENT_ACCUMULATION_STEPS: 2,等效增大批次大小)。
Q:生成的字幕存在“重复描述”或“逻辑混乱”问题?
A:可能是训练轮次不足或数据量太少导致。建议:① 增加训练轮次(MAX_EPOCH调至30);② 加入更多交通领域的标注数据;③ 在配置文件中设置DECODING.BEAM_SIZE: 5(增大beam search的宽度,提升生成多样性)。
Q:预训练模型在哪里下载?下载后如何配置?
A:Vid2Seq预训练模型可从官方仓库下载,推荐vid2seq_htmchaptersvitt.pth。下载后将路径填入config.py的_C.MODEL.VID2SEQ_PATH即可。
4. 功能与应用相关
Q:如何调整字幕的详细程度?
A:在配置文件的CONTROL部分设置DETAIL_LEVEL(1-3,1为最简洁,3为最详细),例如:CONTROL: {DETAIL_LEVEL: 2}。
Q:模型支持实时处理摄像头流吗?
A:目前版本主要针对离线视频处理。若需实时处理,可通过以下优化:① 降低视频帧率(如5fps);② 关闭局部特征;③ 使用模型裁剪(MODEL.CROP: True),牺牲部分精度换取速度。
七、相关链接
八、总结
TrafficVLM是一个针对交通场景优化的可控视觉语言模型,通过多粒度视觉特征融合、时间编码机制和可控性生成设计,实现了交通视频字幕的精准生成。作为AI City Challenge的获奖解决方案,其技术已在CVPR 2024 Workshops得到认可,并以开源形式提供完整实现,支持从训练到部署的全流程应用。该模型在智能交通监控、自动驾驶辅助、交通事件分析等领域具有实际应用价值,为交通视频的智能化理解提供了高效、可定制的工具,同时其开源特性也为开发者和研究者提供了二次创新的基础。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/trafficvlm.html