VitaBench:美团联合 Sierra Research 推出的 LLM 智能体生活服务场景基准测试框架
一、VitaBench是什么?
VitaBench是一款由美团与Sierra Research联合开发的开源基准测试框架,专为评估大型语言模型(LLM)智能体在真实生活服务场景中的综合能力而设计。该框架通过模拟外卖、到店消费、在线旅游等贴近日常的任务场景,结合66个API工具与大规模真实数据,从跨时空推理、工具使用、用户意图跟踪等多维度衡量LLM智能体的实际表现。其灵活的扩展机制与科学的评估体系,为开发者、研究人员提供了可靠的LLM智能体测试方案,推动生活服务类AI应用的技术迭代。
在人工智能技术快速发展的背景下,大型语言模型(LLM)智能体逐渐向“落地实用”迈进,尤其在生活服务领域(如外卖点单、酒店预订、到店消费等),对智能体的“真实场景适应能力”提出了极高要求。然而,现有LLM基准测试工具多聚焦于文本生成、逻辑推理等单一能力,难以模拟复杂的现实交互场景——例如,用户说“明天中午想在公司附近吃点辣的,预算50元以内,最好能开发票”,智能体需要同时处理时间(明天中午)、空间(公司附近)、偏好(辣)、预算(50元内)、附加需求(开发票)等多维度信息,并调用商家查询、距离计算、发票政策查询等工具,才能给出准确回复。
VitaBench正是为解决这一问题而生:它是一款以“生活服务场景”为核心的LLM智能体基准测试框架,名称源自拉丁语“Vita”(意为“生活”),直接体现了对真实生活场景的聚焦,通过构建贴近实际的任务环境、提供丰富的工具接口、设计科学的评估机制,全方位衡量LLM智能体在“真实世界交互”中的核心能力,填补了现有基准测试在“生活服务场景适应性”上的空白。

二、功能特色
VitaBench的核心优势在于“贴近真实、维度全面、灵活扩展”,具体功能特色如下:
1. 覆盖三大核心生活服务场景,任务设计贴近实际需求
VitaBench聚焦与大众日常紧密相关的三大领域,所有任务均基于真实生活服务场景设计,避免“理想化假设”:
外卖场景:模拟用户点单、修改地址、催单、退换餐等任务,例如“帮我点一份昨天晚上吃的麻辣烫,地址改成公司,不要香菜”(需要智能体调用历史订单查询、地址修改、菜品备注工具)。
到店场景:涵盖餐厅预订、排号查询、优惠活动核销等任务,例如“今晚6点想在朝阳区找一家能容纳8人的川菜馆,要有包间和免费停车”(需要智能体调用区域筛选、容量查询、设施筛选工具)。
在线旅游场景:包含酒店预订、机票比价、景点门票购买等任务,例如“下周三从北京去上海,想住离外滩步行10分钟内的酒店,价格在800元/晚以下,含早餐”(需要智能体调用日期筛选、地理位置计算、价格过滤工具)。
为全面评估智能体的“单一场景深耕能力”与“跨场景协同能力”,VitaBench设计了两类任务集,具体分布如下表:
| 任务类型 | 覆盖场景 | 任务数量 | 核心评估目标 |
|---|---|---|---|
| 单场景任务 | 外卖、到店、在线旅游(各100个) | 300个 | 特定领域内的工具使用、意图理解能力 |
| 跨场景任务 | 融合两个及以上领域(如“先订酒店再点外卖”) | 100个 | 跨领域信息关联、多工具协同调用能力 |
2. 66个API工具全覆盖,模拟真实服务交互流程
在真实生活服务场景中,LLM智能体需通过调用工具(如查询商家信息、计算距离、提交订单)完成任务,工具使用能力是核心评估维度。VitaBench提供了66个细分API工具,按功能分为三类,覆盖从“信息查询”到“操作执行”的全流程:
读工具(信息查询类):共32个,用于获取场景数据,例如
takeaway_shop_search(外卖商家搜索)、hotel_price_check(酒店价格查询)、instore_coupon_list(到店优惠券列表)等。写工具(操作执行类):共18个,用于执行具体操作,例如
takeaway_order_submit(提交外卖订单)、hotel_reservation(酒店预订)、ticket_refund(门票退款)等。通用工具(辅助功能类):共16个,用于处理跨场景的基础需求,例如
distance_calculator(经纬度距离计算)、weather_query(天气查询)、holiday_check(节假日判断)等(例如用户说“周末去郊游”,智能体需先通过holiday_check确认“周末是否为工作日”,再推荐营业时间)。
3. 大规模真实数据支撑,场景模拟更具说服力
为避免“虚拟数据导致的评估偏差”,VitaBench基于真实生活服务场景构建了大规模数据集,涵盖服务提供商、产品、交易等核心实体,确保任务环境的真实性:
1,324个服务提供商(如餐厅、酒店、景点),包含名称、地址、营业时间等基础信息;
6,946个产品(如菜品、房型、门票),包含价格、规格、优惠政策等细节;
447笔历史交易记录,支持“基于历史行为的任务”(如“重复上周的订单”)。
4. 滑动窗口评估器:灵活应对多样化解决方案
真实场景中,同一任务可能有多种合理解决方案(例如“订酒店”可推荐A酒店或B酒店,只要符合用户需求均为有效)。传统“标准答案匹配”的评估方式会误判这类情况,而VitaBench的“滑动窗口评估器”通过以下逻辑实现更鲁棒的评估:
设定“核心需求维度”(如价格、位置、时间),只要智能体的解决方案满足所有核心维度,即判定为“有效”;
对“非核心需求”(如用户随口提的“希望装修好看”),采用“模糊匹配”,允许一定程度的偏差;
支持动态调整评估严格度(通过参数
strictness控制),适应不同测试目标(如快速筛选 vs 精细对比)。
5. 模块化设计,支持灵活扩展
VitaBench采用“注册机制”(基于Registry类)统一管理所有核心组件,方便用户扩展新场景、新工具或新任务:
新增场景:只需定义场景数据模型(如新增“生鲜配送”场景,定义“生鲜商品”“保鲜要求”等实体),并注册到
DomainRegistry;新增工具:通过
ToolRegistry注册工具名称、输入参数、输出格式,无需修改框架核心代码;新增任务:在
TaskRegistry中定义任务描述、核心需求、评估标准,即可加入测试集。
三、技术细节
VitaBench的技术架构围绕“场景模拟-工具调用-能力评估”的核心流程设计,包含五大核心模块,各模块职责清晰、协同工作:
1. 评估框架核心模块
VitaBench的评估流程由四大模块联动完成,具体如下:
| 模块名称 | 核心功能 | 技术实现 |
|---|---|---|
| 任务生成器 | 根据场景类型生成具体任务(如随机从“外卖场景任务库”中抽取任务) | 基于规则引擎与随机采样,支持按“难度等级”(简单/中等/复杂)筛选任务 |
| 环境模拟器 | 构建任务对应的场景环境(如加载外卖场景的商家、商品数据) | 采用轻量级数据库(SQLite)存储场景数据,通过API接口实时返回环境信息 |
| 智能体接口 | 接收LLM智能体的输出(如工具调用指令、用户回复),并转发给环境模拟器 | 标准化输入格式(JSON),支持同步/异步调用,兼容OpenAI API、自定义模型接口 |
| 滑动窗口评估器 | 对比智能体解决方案与核心需求,输出评估结果(分数、不足项) | 基于Python实现的评分算法,支持自定义评估维度与权重 |
2. 工具集技术设计
所有66个API工具均遵循统一的接口规范,确保LLM智能体可稳定调用:
输入格式:统一为
{"tool_name": "工具名", "parameters": {"参数1": "值1", ...}},例如调用外卖商家搜索工具:{"tool_name": "takeaway_shop_search", "parameters": {"location": "海淀区", "cuisine": "川菜", "price_range": "0-50"}}。输出格式:包含“状态码”(成功/失败)与“结果数据”,例如成功搜索后的输出:
{"status": "success", "data": [{"shop_id": "1001", "name": "川味小馆", "address": "海淀区XX路", ...}]}。错误处理:当参数缺失或格式错误时,返回明确的错误提示(如
{"status": "error", "message": "缺少参数'location'"}),模拟真实API的交互逻辑。
3. 数据模型设计
为支撑场景模拟,VitaBench定义了六大核心实体的数据结构,覆盖生活服务场景的关键要素:
店铺(Shop):包含
shop_id(唯一标识)、name(名称)、location(经纬度)、business_hours(营业时间)等字段;商品(Product):包含
product_id、name、price(价格)、attributes(属性,如“辣度”“房型”)等字段;用户(User):包含
user_id、history_orders(历史订单)、preferences(偏好,如“不吃香菜”)等字段;订单(Order):包含
order_id、shop_id、product_ids(商品列表)、status(状态,如“已支付”“已完成”)等字段;优惠券(Coupon):包含
coupon_id、validity(有效期)、discount(折扣规则)等字段;地址(Address):包含
address_id、detail(详细地址)、coordinates(经纬度)等字段(支持通过通用工具address_to_coords转换为经纬度用于距离计算)。
4. 与LLM的集成方式
VitaBench通过配置文件实现与不同LLM的灵活集成,无需修改框架代码:
配置文件:默认使用
models.yaml,支持定义多个模型,每个模型包含name(名称)、api_base(接口地址)、api_key(密钥)、temperature(温度系数,控制输出随机性)等参数;环境变量:通过
VITA_MODEL_CONFIG_PATH指定自定义配置文件路径(如export VITA_MODEL_CONFIG_PATH="./my_models.yaml");调用逻辑:框架通过
ModelClient类统一封装API调用,自动根据配置文件选择模型,返回智能体的思考过程(thought)、工具调用指令(action)或最终回复(response)。
四、应用场景
VitaBench的设计初衷是为LLM智能体在生活服务领域的落地提供“标准化测试工具”,其应用场景覆盖开发、研究、教学等多个领域:
1. LLM智能体开发者:测试模型实际落地能力
对于开发“生活服务类AI应用”(如外卖助手、旅游规划机器人)的团队,VitaBench可帮助快速验证模型在真实场景中的表现:
例如,开发“外卖智能助手”时,可通过VitaBench的100个外卖单场景任务,测试模型是否能准确处理“修改地址”“合并订单”等高频需求;
通过对比不同模型(如GPT-4、LLaMA 3)在任务中的得分,选择更适合的基础模型进行微调。
2. 研究机构:对比分析LLM智能体的能力边界
学术界可利用VitaBench的标准化场景与评估体系,开展LLM智能体能力的对比研究:
例如,分析“开源模型”与“闭源模型”在跨场景任务中的差距(如“订酒店+点外卖”的协同处理能力);
探索“工具使用策略”对任务完成率的影响(如“先调用距离工具再筛选商家”是否比“直接筛选”更高效)。
3. 企业:优化生活服务类AI产品体验
美团等生活服务平台可通过VitaBench持续测试自家AI产品(如智能客服、推荐系统),发现体验短板:
例如,若模型在“到店场景的优惠券核销”任务中得分低,可针对性优化“优惠券规则理解”与“核销流程调用”逻辑;
通过定期运行跨场景任务,确保产品在复杂用户需求下的稳定性(如“用户在预订酒店后临时修改行程,同时需要退订原外卖订单”)。
4. 教育领域:作为LLM智能体教学案例
高校或培训机构可将VitaBench作为“LLM智能体开发”课程的实践工具:
学生可通过扩展场景(如新增“生鲜配送”)理解智能体与环境交互的逻辑;
通过调试模型在任务中的表现,掌握“工具调用提示词设计”“多轮对话状态跟踪”等核心技能。
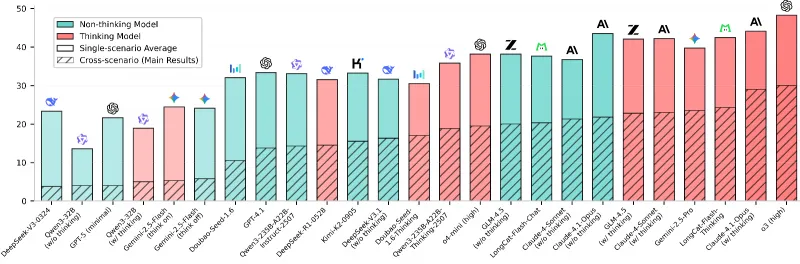
五、使用方法
VitaBench提供了简洁的命令行工具与Python API,方便用户快速上手,以下是完整使用流程:
1. 环境准备
系统要求:支持Linux、macOS、Windows(建议Linux/macOS,兼容性更好);
依赖环境:Python 3.8+,pip 20.0+;
可选依赖:若需可视化评估结果,需安装
matplotlib(pip install matplotlib)。
2. 安装框架
通过GitHub仓库克隆代码并安装:
# 克隆仓库 git clone https://github.com/meituan-longcat/vitabench.git cd vitabench # 安装框架( editable模式,方便修改代码) pip install -e . # 验证安装:执行后显示版本号即安装成功 vita --version
3. 配置LLM模型
VitaBench需通过配置文件指定待测试的LLM模型,步骤如下:
复制默认配置文件模板:
cp configs/models.yaml.example configs/models.yaml
编辑
configs/models.yaml,添加模型信息(以OpenAI API为例):
models: - name: gpt-4 api_base: https://api.openai.com/v1 api_key: "your_openai_api_key" # 替换为实际API密钥 temperature: 0.2 # 低温度,减少输出随机性 max_tokens: 1024 # 最大生成 tokens
(可选)通过环境变量指定自定义配置文件:
export VITA_MODEL_CONFIG_PATH="./my_custom_models.yaml"
4. 运行基准测试
VitaBench提供vita run命令运行测试,支持按场景、任务类型筛选任务,示例如下:
运行外卖场景的单场景任务:
vita run --domain takeaway --task-type single --model gpt-4 --num-tasks 10
(参数说明:--domain指定场景(takeaway/instores/travel);--task-type指定任务类型(single/cross);--model指定模型名;--num-tasks指定运行任务数量)
运行跨场景任务(随机10个):
vita run --task-type cross --model gpt-4 --num-tasks 10
5. 查看评估结果
测试完成后,结果会以JSON格式保存到results/目录,同时在控制台输出汇总信息,例如:
评估完成!模型:gpt-4,任务数量:10,平均得分:85.2/100 核心能力得分: - 工具调用准确性:90.5 - 跨时空推理:82.3 - 用户意图跟踪:88.1
若安装了matplotlib,可通过vita visualize命令生成可视化报告:
vita visualize --result-path results/20251023_gpt-4.json
6. 扩展新场景(进阶操作)
以新增“生鲜配送”场景为例,步骤如下:
定义场景数据模型(在
vitabench/domains/fresh/models.py中添加FreshShop、FreshProduct等实体类);注册场景到
DomainRegistry(在vitabench/domains/fresh/__init__.py中添加register_domain("fresh", FreshDomain));开发专属工具(如
fresh_stock_check库存查询工具),注册到ToolRegistry;编写任务集(在
vitabench/tasks/fresh/目录下添加任务JSON文件);运行测试:
vita run --domain fresh --task-type single --model gpt-4。
六、常见问题解答(FAQ)
1. VitaBench支持哪些LLM模型?
VitaBench兼容所有提供API接口的LLM模型,包括闭源模型(如GPT-4、Claude 3)和开源模型(如LLaMA 3、Mistral Large,需通过vLLM等工具部署API)。只需在models.yaml中配置模型的API地址、密钥等参数即可。
2. 如何判断任务的“难度等级”?
VitaBench的任务难度由以下指标综合判定:
涉及的工具数量(使用工具≥3个为“复杂”);
需求的模糊程度(如“随便找点吃的”比“找川菜馆”更模糊,难度更高);
是否跨场景(跨场景任务默认难度高于单场景)。
可通过vita list-tasks --domain takeaway --difficulty hard筛选高难度任务。
3. 评估得分的计算逻辑是什么?
得分满分为100分,由四大维度加权计算:
工具调用准确性(30%):是否调用了必要工具、参数是否正确;
需求满足度(40%):解决方案是否覆盖用户的核心需求(如价格、位置);
交互流畅度(20%):多轮对话中是否能持续跟踪用户意图,无需重复确认;
效率(10%):完成任务调用的工具次数(次数越少得分越高)。
4. 数据集中的商家、商品信息是真实的吗?
数据集中的服务提供商(如餐厅、酒店)名称、地址等基础信息基于真实场景脱敏处理,产品(如菜品、房型)参数为模拟数据(避免商业信息泄露),但整体分布与真实生活服务数据一致,不影响评估有效性。
5. VitaBench与其他LLM基准测试(如MT-Bench、AgentBench)有何区别?
场景聚焦:VitaBench专注于生活服务领域,而其他基准测试多覆盖通用场景(如代码生成、数学推理);
评估维度:更强调“跨时空推理”“真实工具调用”(而非模拟工具);
数据规模:生活服务领域的专用数据更丰富(1324个服务商、6946个产品)。
七、相关链接
GitHub仓库:https://github.com/meituan-longcat/vitabench
论文:https://arxiv.org/abs/2509.26490
官网:https://vitabench.github.io/
数据集:https://huggingface.co/datasets/meituan-longcat/VitaBench
排行榜:https://vitabench.github.io/#Leaderboard
八、总结
VitaBench作为聚焦生活服务场景的LLM智能体基准测试框架,通过模拟外卖、到店、在线旅游等真实场景,结合66个API工具与大规模数据,构建了科学、全面的评估体系,填补了现有工具在“生活服务场景适应性”测试上的空白。其模块化设计支持灵活扩展新场景与工具,滑动窗口评估器可准确衡量多样化解决方案的有效性,为开发者、研究人员提供了可靠的LLM智能体测试方案,推动生活服务类AI应用从“实验室”走向“真实场景”。
版权及免责申明:本文由@AI铺子原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/vitabench.html





