MiniCPM4 部署指南:Ubuntu 22.04 + CUDA 12.1 + RTX 3060 本地运行全流程
MiniCPM4 是 OpenBMB 推出的面向边缘场景的超高效 4B 级大模型,凭借 InfLLM v2 稀疏注意力、BitCPM 3-bit 极致量化、FP8 训练加速与 CPM.cu 轻量 CUDA 推理框架,在消费级硬件上实现了长文本理解与低延迟响应的突破性平衡。本文以真实开发环境为基准——Ubuntu 22.04.5 LTS + NVIDIA RTX 3060(12GB)+ CUDA 12.1.1——完整复现从基础镜像构建、Conda 环境隔离、依赖安装、ModelScope 模型下载到 Gradio Web 演示成功运行的端到端部署流程,每一步均标注常见报错与精准修复方案,专为中文开发者本地快速验证与二次开发而优化。
一、介绍
MiniCPM 4 是一个极其高效的边缘侧大型模型,经过了模型架构、学习算法、训练数据和推理系统四个维度的高效优化,实现了极致的效率提升。
🏗️ 高效的模型架构:
InfLLM v2 – 可训练的稀疏注意力机制:采用可训练的稀疏注意力机制架构,每个 token 只需要计算与 128K 长文本中不到 5% 的 token 的相关性,显著降低了长文本处理的计算开销
🧠 高效的算法学习:
Model Wind Tunnel 2.0 – 高效的可预测扩展:引入了下游任务性能的扩展预测方法,使得模型训练配置搜索更加精确
BitCPM – 极限三值量化:将模型参数位宽压缩至 3 个值,实现了 90% 的极端模型位宽减少
高效的训练工程优化:采用 FP8 低精度计算技术结合多 token 预测训练策略
📚 高质量的训练数据:
UltraClean – 高质量预训练数据过滤和生成:基于高效的数据验证构建迭代数据清洗策略,开源高质量的中文和英文预训练数据集 UltraFinweb
UltraChat v2 – 高质量监督微调数据生成:构建大规模高质量监督微调数据集,涵盖知识密集型数据、推理密集型数据、指令遵循数据、长文本理解数据及工具调用数据等多个维度
⚡ 高效的推理系统:
CPM.cu – 轻量级且高效的 CUDA 推理框架:集成稀疏注意力、模型量化和推测采样以实现高效的填充和解码
ArkInfer – 跨平台部署系统:支持在多个后端环境中的高效部署,提供灵活的跨平台适应能力
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.5 LTS |
| python | 3.10 |
| Cuda | 12.1.1 |
| NVIDIA Corporation | 3060 |
1、构建基础镜像
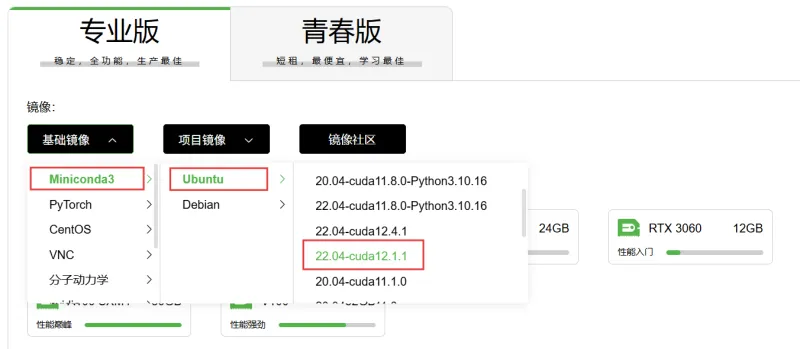
在算家云容器中心的租赁页面中,构建基础镜像 Miniconda-Ubuntu-22.04-cuda12.1.1
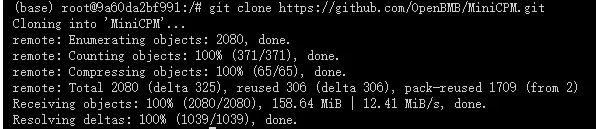
2、从 github 仓库 克隆项目:
# 克隆 MiniCPM4 项目(如果克隆速度过慢可以开启学术代理加速) git clone https://github.com/OpenBMB/MiniCPM.git
3、创建虚拟项目
# 创建一个名为 MiniCPM4 的新虚拟环境,并指定 Python 版本为 3.10 conda create -n MiniCPM4 python=3.10 -y
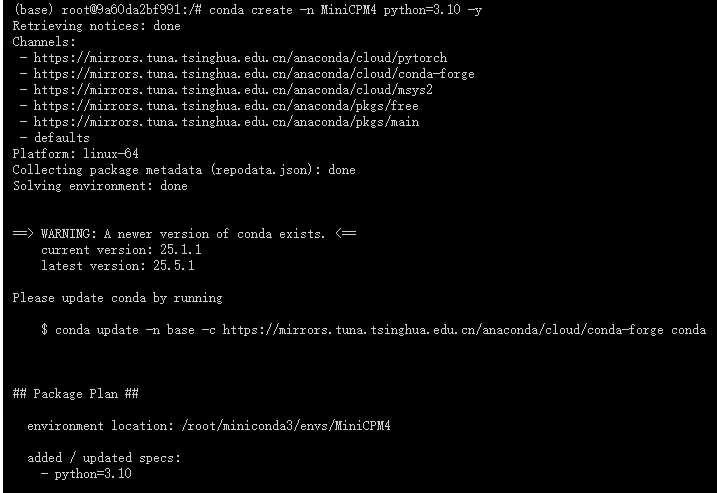
等待安装完成

4、安装模型依赖包
# 激活 MiniCPM4 虚拟环境 conda activate MiniCPM4 # 切换到项目工作目录 cd /MiniCPM # 在 MiniCPM4 环境中安装 requirements.txt 依赖 pip install -r requirements.txt

依赖安装成功如下图所示:

5、下载预训练模型
推荐下载方法:
1.安装 modelscope 依赖包。
pip install modelscope

2.创建一个 Python 下载脚本
vim modelscope_download.py
3.在创建的脚本中插入以下下载代码
# Python 代码下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('OpenBMB/MiniCPM3-4B', cache_dir='./', revision='master')保存文件:Esc --》Shift + :–》输入英文的 :–》输入:wq
如果你正在编辑文本,先按 Esc 键退出插入模式。
然后,直接按 Shift + :(不需要先按冒号,这个组合键已经包含了冒号的输入),屏幕上会出现一个冒号,提示你输入命令。
接着,输入 wq,表示你想要保存文件并退出。
最后,按 Enter 键执行命令。
4.执行 modelscope_download.py 文件进行模型下载
python modelscope_download.py

6、运行 hf_based_demo.py 文件
#切换到hf_based_demo.py 文件目录 cd demo/minicpm # 运行 hf_based_demo.py 文件 python hf_based_demo.py
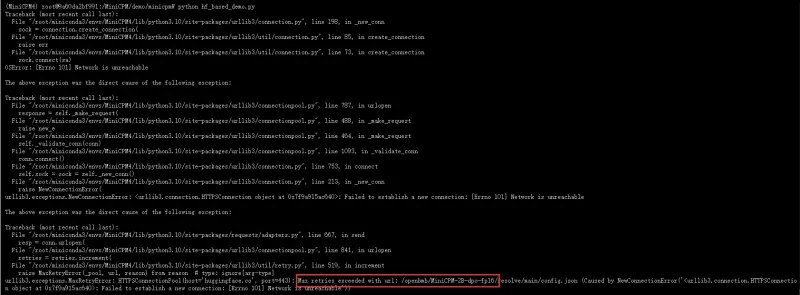
出现以上报错,需要修改模型路径
# 编辑 hf_based_demo.py 文件 vim hf_based_demo.py

将上方划红线的部分修改为刚刚下载模型的路径,并且修改模型的 gradio 页面 IP 和端口

第二次运行 hf_based_demo.py 文件
# 运行 hf_based_demo.py 文件 python hf_based_demo.py

出现以上结果,还需要继续安装 accelerate 依赖
pip install accelerate
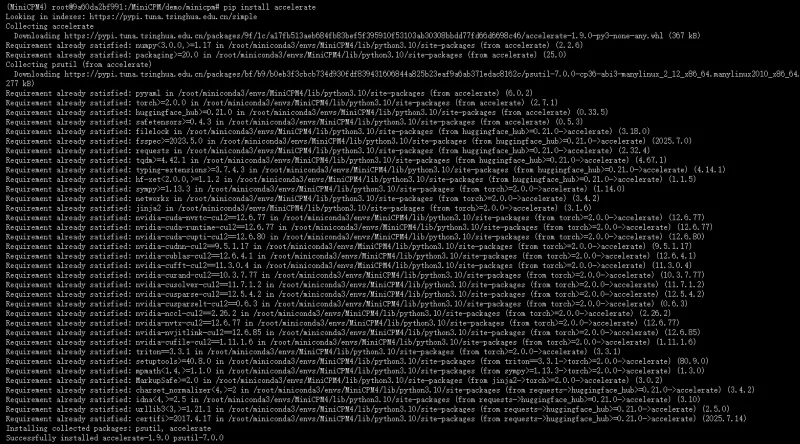
第三次运行 hf_based_demo.py 文件
# 运行 hf_based_demo.py 文件 python hf_based_demo.py
可以成功运行:

三、网页演示
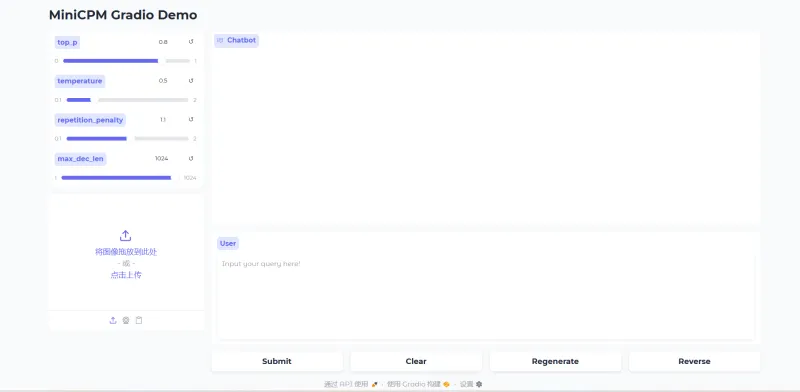
总结:
MiniCPM4 并非仅是参数规模的压缩,而是架构、算法、数据与系统四维协同优化的成果:它用不到 5% 的 token 关系计算支撑 128K 上下文,以 3-bit 量化实现 90% 参数存储缩减,并通过 CPM.cu + ArkInfer 实现跨平台高效推理。在 RTX 3060 这类无服务器条件的终端设备上完成全流程部署,不仅验证了其“边缘即开即用”的设计初衷,更标志着轻量大模型正从实验室走向真实产线。后续可基于此环境无缝接入工具调用、RAG 增强或 LoRA 微调,真正释放 MiniCPM4 在智能终端、离线办公与嵌入式 AI 场景中的落地潜力。
版权及免责申明:本文来源于#算家计算,由@AI工具箱整理发布。如若内容造成侵权/违法违规/事实不符,请联系本站客服处理!该文章观点仅代表作者本人,不代表本站立场。本站不承担相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/867.html





