过拟合是什么意思?造成过拟合现象的主要原因及解决方法详解
一、引言
在机器学习和深度学习的模型训练过程中,我们追求的目标是构建一个能够对未见过的数据(测试数据)做出准确预测或分类的模型。然而,在实际操作中,常常会遇到这样一种情况:模型在训练数据上表现得非常出色,几乎能够完美地拟合所有的训练样本,但在测试数据上的性能却大幅下降。这种现象就被称为过拟合(Overfitting)。过拟合严重影响了模型的泛化能力,使得模型无法在实际应用中发挥应有的作用。因此,深入理解过拟合的概念、原因以及掌握有效的解决方法具有重要的现实意义。
二、过拟合的概念
2.1 定义
过拟合是指模型在训练数据上学习得过于精细,将训练数据中的噪声、异常值等无关信息也当作了数据的真实特征进行学习,从而导致模型在训练数据上的误差很小,但在新的、未见过的测试数据上误差增大的现象。简单来说,就是模型“记住”了训练数据的细节,而没有学习到数据背后的普遍规律。
2.2 直观理解
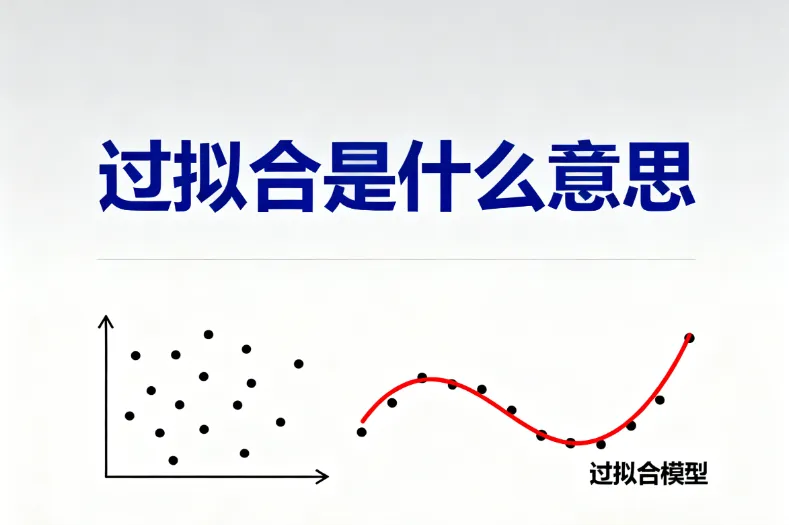
以一个简单的二分类问题为例,假设我们有一组二维空间中的数据点,这些数据点可以分为两类,分别用不同的颜色表示。我们的目标是找到一个决策边界来将这两类数据点分开。如果模型过于简单,比如一条直线,可能无法很好地将两类数据分开,出现欠拟合(Underfitting)的情况;而如果模型过于复杂,比如一个非常扭曲的曲线,虽然可以完美地将训练数据中的所有点分开,但当有新的数据点加入时,这个曲线可能无法正确地对它们进行分类,这就是过拟合的表现。如图1所示:
| 拟合情况 | 决策边界示例 | 特点 |
|---|---|---|
| 欠拟合 | 一条简单的直线,无法很好地分开两类数据 | 模型过于简单,对训练数据的拟合程度低,在训练数据和测试数据上的性能都较差 |
| 合适拟合 | 一条较为平滑的曲线,能够较好地分开两类数据 | 模型复杂度适中,既能学习到数据的主要特征,又不会过度拟合训练数据中的噪声,在训练数据和测试数据上都有较好的性能 |
| 过拟合 | 一条非常扭曲的曲线,完美分开训练数据中的所有点 | 模型过于复杂,过度拟合训练数据中的噪声和异常值,在训练数据上误差小,但在测试数据上误差大 |
三、造成过拟合现象的主要原因
3.1 数据层面
3.1.1 数据量过小
当训练数据的数量过少时,模型能够学习到的样本特征有限,很容易将训练数据中的一些特殊情况、噪声等当作普遍规律进行学习。例如,在一个图像分类任务中,如果训练集中只有几张包含某种特定物体的图像,而且这些图像的拍摄角度、光照条件等都非常相似,那么模型可能会过度关注这些特定的细节,而无法学习到该物体的普遍特征,从而导致过拟合。
3.1.2 数据噪声过多
数据中的噪声是指数据中存在的随机误差或无关信息。如果训练数据中包含大量的噪声,模型在学习过程中可能会将这些噪声也当作有用的特征进行学习,从而影响模型的泛化能力。例如,在传感器数据采集过程中,由于传感器的精度限制、环境干扰等因素,采集到的数据可能包含大量的噪声,如果直接使用这些数据进行模型训练,就容易导致过拟合。
3.1.3 数据分布不均衡
在分类问题中,如果不同类别的样本数量差异很大,即数据分布不均衡,模型可能会倾向于学习到样本数量较多的类别的特征,而对样本数量较少的类别学习不足。例如,在一个二分类问题中,正样本的数量远远多于负样本的数量,模型可能会为了降低整体误差而过度拟合正样本,从而在负样本上的预测性能较差。
3.2 模型复杂度层面
3.2.1 模型参数过多
当模型的参数数量过多时,模型的表达能力会变得非常强,能够拟合非常复杂的数据分布。然而,如果训练数据的数量有限,过多的参数会导致模型过度拟合训练数据中的细节和噪声。例如,在一个神经网络模型中,如果隐藏层的神经元数量过多,网络的层数过深,那么模型的参数数量会急剧增加,容易出现过拟合现象。
3.2.2 模型结构过于复杂
除了参数数量过多外,模型的结构过于复杂也会导致过拟合。例如,在一些决策树模型中,如果树的深度过大,分支过多,模型会过于细分训练数据,从而学习到一些过于具体的规则,这些规则在新的数据上可能不适用。
3.3 训练过程层面
3.3.1 训练迭代次数过多
在模型训练过程中,通常会使用迭代算法来不断优化模型的参数,以降低模型在训练数据上的误差。然而,如果训练迭代次数过多,模型会不断地拟合训练数据,逐渐学习到训练数据中的噪声和异常值,从而导致过拟合。例如,在使用梯度下降算法训练神经网络时,如果迭代次数设置得过大,模型的训练误差会不断下降,但测试误差可能会在某个点之后开始上升,这就是过拟合的表现。
3.3.2 缺乏有效的正则化
正则化是一种用于防止过拟合的技术,它通过在损失函数中添加一个正则化项来约束模型的参数,使得模型不会过于复杂。如果在训练过程中缺乏有效的正则化,模型可能会过于自由地调整参数,从而导致过拟合。常见的正则化方法包括L1正则化和L2正则化。
四、解决过拟合问题的方法
4.1 数据层面方法
4.1.1 数据增强
数据增强是通过对训练数据进行一系列的变换操作,生成更多的训练样本,从而增加数据的多样性和数量。在图像领域,常用的数据增强方法包括旋转、翻转、缩放、裁剪、添加噪声等。例如,对于一张图像,可以对其进行随机旋转一定角度、水平或垂直翻转、随机缩放等操作,生成多张不同的图像,将这些图像作为新的训练样本加入到训练集中。通过数据增强,可以有效地扩大训练数据的规模,减少过拟合的风险。表1展示了不同图像数据增强方法的效果示例:
| 数据增强方法 | 示例效果描述 |
|---|---|
| 旋转 | 将图像随机旋转一定角度,如顺时针或逆时针旋转10度、20度等,改变图像的方向信息 |
| 翻转 | 包括水平翻转和垂直翻转,水平翻转是将图像沿垂直中轴线进行左右翻转,垂直翻转是将图像沿水平中轴线进行上下翻转,改变图像的左右或上下结构 |
| 缩放 | 对图像进行随机缩放,可以放大或缩小图像,改变图像的尺寸信息 |
| 裁剪 | 从原始图像中随机裁剪出一部分区域作为新的图像,改变图像的视野范围 |
| 添加噪声 | 向图像中添加随机噪声,如高斯噪声、椒盐噪声等,增加图像的干扰信息 |
4.1.2 数据清洗
数据清洗是指对训练数据进行预处理,去除数据中的噪声、异常值和重复样本等。例如,在处理传感器数据时,可以通过设置合理的阈值来过滤掉那些明显超出正常范围的噪声数据;在处理文本数据时,可以去除停用词、标点符号等无关信息。通过数据清洗,可以提高训练数据的质量,减少模型学习到噪声和异常值的可能性。
4.1.3 重新平衡数据分布
对于数据分布不均衡的问题,可以采用一些方法来重新平衡数据分布。例如,过采样少数类样本,即对少数类样本进行重复采样或通过数据增强生成更多的少数类样本;欠采样多数类样本,即随机删除一部分多数类样本,使得不同类别的样本数量相对均衡。此外,还可以使用合成样本的方法,如SMOTE算法,通过在少数类样本之间进行插值来生成新的少数类样本。
4.2 模型层面方法
4.2.1 简化模型结构
如果模型的复杂度过高导致过拟合,可以考虑简化模型结构。例如,在神经网络中,可以减少隐藏层的神经元数量、降低网络的层数;在决策树中,可以限制树的深度、设置最小样本分割数等。通过简化模型结构,可以减少模型的参数数量,降低模型的表达能力,从而避免过度拟合训练数据。
4.2.2 使用正则化方法
L1正则化:L1正则化在损失函数中添加一个L1范数项,即模型参数的绝对值之和。L1正则化会使模型的一些参数变为0,从而实现特征选择的效果,减少模型的复杂度。例如,在一个线性回归模型中,损失函数可以表示为:
 ,其中
,其中 是正则化系数,
是正则化系数, 是模型的参数。
是模型的参数。L2正则化:L2正则化在损失函数中添加一个L2范数项,即模型参数的平方和。L2正则化会使模型的参数值变小,但不会使参数变为0,从而使得模型的曲线更加平滑,减少过拟合的风险。例如,在线性回归模型中,损失函数可以表示为:
 。
。
表2对L1正则化和L2正则化进行了对比:
| 正则化方法 | 特点 | 适用场景 |
|---|---|---|
| L1正则化 | 会使部分参数变为0,实现特征选择;得到的模型比较稀疏 | 特征维度较高,希望进行特征选择,减少特征数量的场景 |
| L2正则化 | 使参数值变小,模型曲线更平滑;不会使参数变为0 | 主要关注防止过拟合,对特征选择要求不高的场景 |
4.2.3 使用集成学习方法
集成学习是通过组合多个基学习器来构建一个更强大的学习器,从而提高模型的泛化能力。常见的集成学习方法包括Bagging、Boosting和Stacking等。
Bagging:Bagging方法通过自助采样(Bootstrap Sampling)从训练数据中生成多个子样本集,然后为每个子样本集训练一个基学习器,最后将所有基学习器的预测结果进行投票或平均,得到最终的预测结果。例如,随机森林(Random Forest)就是一种基于Bagging的集成学习方法,它通过构建多个决策树来进行分类或回归。
Boosting:Boosting方法是一种迭代算法,它通过依次训练多个基学习器,每个基学习器都专注于前一个学习器预测错误的样本,从而逐步提高模型的整体性能。常见的Boosting算法包括AdaBoost、Gradient Boosting和XGBoost等。
Stacking:Stacking方法通过训练一个元学习器来组合多个基学习器的预测结果。具体来说,首先使用训练数据训练多个基学习器,然后将这些基学习器在验证集上的预测结果作为新的特征,训练元学习器,最后使用元学习器对测试数据进行预测。
表3对几种常见的集成学习方法进行了对比:
| 集成学习方法 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| Bagging | 通过自助采样生成多个子样本集,训练多个基学习器,最后进行投票或平均 | 能够降低模型的方差,提高模型的稳定性;对基学习器的类型没有严格要求 | 对噪声数据比较敏感;当基学习器的性能较差时,集成后的模型性能提升有限 |
| Boosting | 迭代训练多个基学习器,每个基学习器专注于前一个学习器预测错误的样本 | 能够提高模型的准确率;对噪声数据有一定的鲁棒性 | 训练过程较为复杂,计算成本较高;容易过拟合训练数据 |
| Stacking | 训练一个元学习器来组合多个基学习器的预测结果 | 能够充分利用不同基学习器的优势,提高模型的泛化能力 | 训练过程复杂,需要划分训练集、验证集和测试集;元学习器的选择对模型性能影响较大 |
4.3 训练过程层面方法
4.3.1 早停法
早停法是一种在模型训练过程中防止过拟合的简单而有效的方法。它的基本思想是在训练过程中定期监控模型在验证集上的性能,当模型在验证集上的性能不再提升或开始下降时,停止训练,将此时模型在训练集上的参数作为最终的模型参数。通过早停法,可以避免模型过度训练,从而减少过拟合的风险。
4.3.2 交叉验证
交叉验证是一种用于评估模型性能和选择模型参数的方法。常见的交叉验证方法包括k折交叉验证(k-Fold Cross Validation)。在k折交叉验证中,将训练数据随机划分为k个子集,每次使用k - 1个子集进行训练,剩下的1个子集进行验证,重复进行k次,将k次的验证结果的平均值作为模型的性能评估指标。通过交叉验证,可以更准确地评估模型的泛化能力,选择合适的模型参数,从而减少过拟合的可能性。
五、结论
过拟合是机器学习和深度学习模型训练过程中常见的问题,它会严重影响模型的泛化能力,使得模型在实际应用中无法发挥应有的作用。造成过拟合的原因主要包括数据层面、模型复杂度层面和训练过程层面等因素。为了解决过拟合问题,可以从数据、模型和训练过程三个方面采取相应的措施,如数据增强、数据清洗、简化模型结构、使用正则化方法、采用集成学习、早停法和交叉验证等。在实际应用中,需要根据具体的问题和数据特点,选择合适的方法或组合多种方法来防止过拟合,提高模型的性能和泛化能力。
版权及免责申明:本文由@97ai原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-tutorial/what-does-overfitting-mean.html





