
万字长文:Prompt Engineering 完全指南 —— 从入门到专家的 30 个核心技巧
本文系统梳理Prompt Engineering(提示工程)从入门到专家的30个核心技巧,涵盖零样本/少样本提示、思维链(CoT)、自一致性、思维树(ToT)、RAG、CO-STAR框架等方法论,配...

本文系统梳理Prompt Engineering(提示工程)从入门到专家的30个核心技巧,涵盖零样本/少样本提示、思维链(CoT)、自一致性、思维树(ToT)、RAG、CO-STAR框架等方法论,配...

html-ppt-skill是专为AI Agent设计的开源HTML演示文稿创作工具集。它提供36个主题、15个完整模板、31种单页布局和47种动画效果(含20个Canvas电影级特效),支持专业演讲者...

Khala 是由中央音乐学院与清华大学联合团队研发、基于统一声学令牌架构打造的开源端到端AI歌曲生成模型,该项目主打全流程完整歌曲生成能力,区别于市面上多数仅能制作伴奏...

2026年Stable Diffusion 3.5与Midjourney v7全方位深度对比,从图像质量、生成速度、使用成本、可控性、版权商用五大维度拆解两大AI绘图工具的核心差异,助你精准选择最适合...

BigSet 是一款开源全自动数据集构建工具,基于多智能体架构开发,无需代码与爬虫配置,依靠自然语言即可完成数据采集、表结构生成、数据清洗、定时更新等操作,支持本地与D...
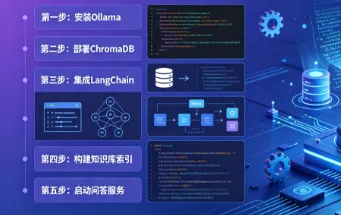
手把手教你使用 LangChain + Ollama + ChromaDB 搭建本地 RAG 知识库,无需联网、数据隐私安全,支持 PDF/Word/TXT 等多格式文档,零成本构建个人智能知识助手。从环境安装...

Manga Image Translator 是一款开源Python漫画图像翻译工具,整合OCR识别、AI翻译、图像修复与文字重绘技术,支持在线使用与本地离线部署,适配日漫、韩漫等多语种漫画,可...

2026年最新GPT-4o与Gemini 2.0 Flash全面对比:从幻觉率、生图能力、编程性能到成本效率,用实测数据帮你选出最适合的AI模型。含详细对比表格与场景化选型建议。
Open Code Review是阿里巴巴开源的轻量化AI代码审查CLI工具,采用规则+大模型双引擎架构,精准解析Git代码变更并实现行级问题定位,支持多编程语言、自定义规则与主流大模型...

JoyAI-Echo是京东智研Joy Future Academy于2026年6月3日正式全量开源的长音视频一体化生成开源框架,项目源代码、完整预训练权重全部对外开放,开源协议采用Apache 2.0,允...