可灵AI O1全量上线:统一多模态架构开启视频创作“一句话时代”
可灵AI公司今日正式宣布,其自主研发的全球首个统一多模态视频大模型O1于零时起面向公众全量开放。该模型凭借MVL(多模态视觉语言)统一交互架构与Chain-of-Thought推理链路两大核心技术突破,重新定义了视频生成工具的交互逻辑与创作效率,标志着AI视频技术迈入“一体化、智能化”新阶段。
统一交互架构:单一输入框实现跨模态创作
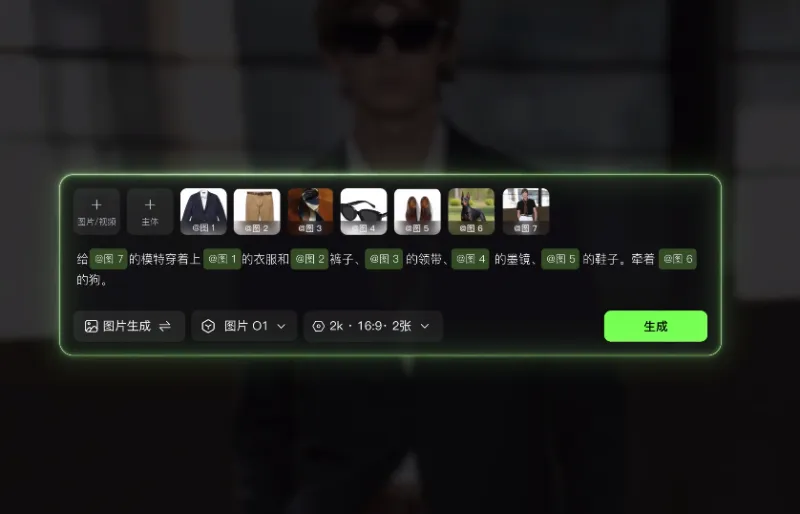
传统视频生成工具需分步处理文生视频、图生视频、局部编辑等任务,操作流程割裂且复杂。而O1模型通过MVL架构,在单一输入框内无缝融合文字、图像、视频三种指令,用户仅需输入一句话或上传素材,即可完成从内容生成到细节优化的全流程。例如,用户上传一段真人视频后,可通过对话指令直接实现局部元素增删、前后镜头智能延展、动作捕捉生成新画面等高级功能,彻底告别界面切换与多工具协作的繁琐。
行业分析师指出,这一设计直击传统工具“功能割裂、学习成本高”的痛点,尤其适合短视频创作者、广告团队及个人用户快速产出高质量内容。目前,O1已支持3-10秒视频自由设定时长,后续还将开放更长时间选项,进一步满足多样化叙事需求。

Chain-of-Thought技术:让AI视频“会思考”
O1模型首次引入的Chain-of-Thought推理链路,赋予其“常识推理”与“事件推演”能力。与传统模型依赖关键词匹配不同,O1能深度理解用户意图,并基于逻辑链条生成更符合现实的内容。例如,当用户要求“在雨天场景中添加一把红色雨伞”时,模型不仅会精准定位画面中的雨天元素,还能根据光照、人物动作等上下文信息,自然融入雨伞并调整阴影效果,避免出现“悬浮感”等违和问题。
可灵AI产品负责人表示,该技术通过模拟人类思维过程,显著提升了生成内容的连贯性与真实性,尤其适用于复杂叙事或品牌广告等对细节要求严苛的场景。
多视角主体构建技术:攻克“特征漂移”行业难题
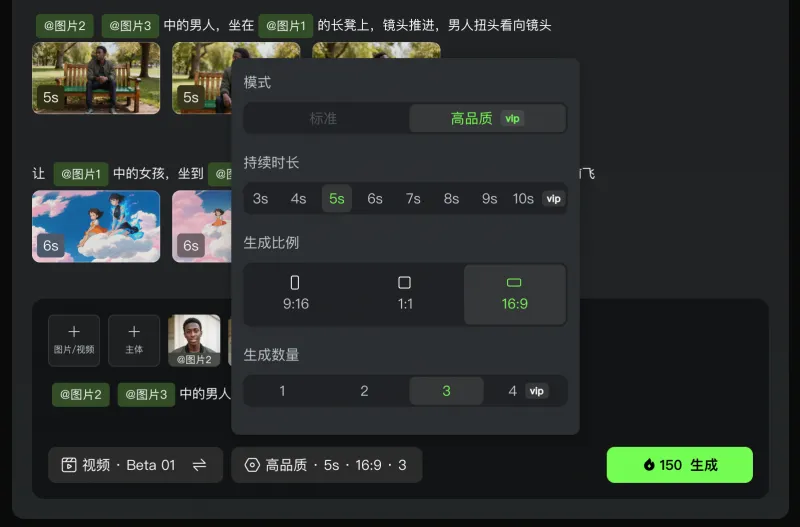
视频创作中,镜头切换时人物或物体特征丢失(即“特征漂移”)是长期困扰行业的痛点。O1模型通过多视角主体构建技术,在生成过程中动态锁定主体特征,确保多镜头画面中的同一人物或物体保持高度一致性。例如,在一段包含多个机位的舞蹈视频中,即使镜头频繁切换,舞者的服装细节、面部表情甚至发丝动态均能无缝衔接,彻底消除“跳戏感”。
技术测试数据显示,在涉及多主体互动的复杂场景中,O1的画面连贯性较传统模型提升超70%,为影视级内容生产提供了可靠的技术支撑。
开放生态与商业化布局:API接口即将上线
目前,用户已可通过可灵App及官网率先体验O1模型,平台同步提供免费试用额度与详细教程,降低新手用户上手门槛。公司透露,后续将开放API接口,支持第三方平台集成,进一步拓展其在电商、教育、娱乐等领域的应用场景。
行业分析师认为,O1的上线或推动AI视频制作从“专业级”向“消费级”普及,但其能否在生成质量、创作效率与成本控制之间取得平衡,仍需市场检验。可灵AI则表示,将持续优化模型性能,并探索订阅制、按需付费等多元化商业模式,加速技术商业化落地。
从“分步操作”到“一句话生成”,从“单一功能”到“多模态统一”,可灵AI O1的发布不仅为视频创作领域带来技术革命,更预示着AI工具正从“辅助生产”向“协同创作”进化。随着统一多模态架构成为行业新标准,视频生产的门槛或将被彻底重塑。
版权及免责申明:本文由@AI工具箱原创发布。该文章观点仅代表作者本人,不代表本站立场。本站不承担任何相关法律责任。
如若转载,请注明出处:https://www.aipuzi.cn/ai-news/502.html





